JavaWeb 解决JSP中文乱码最新
摘要
本文首先从六个方面给出了在使用JSP过程中可能出现中文乱码的情况,具体包括JSP页面中文乱码、JSP源文件中文乱码、GET 请求的请求参数为中文乱码 和 POST 请求的请求参数为中文乱码四种情形,并针对每种情形给出了相应的终极解决方案。
#查看服务器的编码方式
打开tomcat下的conf/server.xml文件,找到Connector,查看是否有URIEncoding属性设置编码格式,若没有,则为默认编码格式。
Tomcat8+ 默认编码格式是UTF-8;
Tomcat7- 默认编码格式都是ISO-8859-1
JavaWeb jsp开发过程中涉及到设置编码格式的几个地方:
- pageEncoding=”UTF-8”;
- contentType=”text/html;charset=UTF-8”;
- request.setCharacterEncoding(“UTF-8”) ;
- response.setCharacterEncoding(“UTF-8”)。
其它设置: - jsp页面乱码配置相关设置
- tomcat配置编码格式
简单粗暴解决办法(最简单的方法)
1、eclipse软件配置UTF-8编码格式,详细点击–>
2、出现涉及设置编码格式的都设置成utf-8格式。

详细目录
- 摘要
- #查看服务器的编码方式
- 简单粗暴解决办法(最简单的方法)
- 1.pageEncoding设置编码格式
- 2、 contentType=”text/html;charset=UTF-8”
- 3、POST请求的请求参数为中文情形request.setCharacterEncoding(“UTF-8”)
- 4、response.setCharacterEncoding(“UTF-8”)
- 5、GET 请求的请求参数为中文情形
- 5.1、URL传递参数中文乱码
- 5.2、表单提交
- 5.3、总结
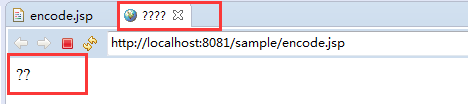
- 6、Eclipse中JSP文件中文乱码
- 7、修改tomcat默认的编码方式
1.pageEncoding设置编码格式
pageEncoding=”UTF-8” 的作用是设置JSP编译成Servlet时使用的编码。通常,在JSP内部定义的字符串(直接在JSP中定义,而不是从浏览器提交的数据)出现乱码时,很多都是由于该参数设置错误引起的。例如,你的 JSP文件中含有中文字符,而在JSP中却指定pageEncoding=”iso-8859-1”,就会导致中文字符显示异常。
看下面例子:
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="iso-8859-1"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>网上商城 </title>
</head>
<body>
中文 <br>
</body>
</html>
pageEncoding设置的是iso-8859-1编码格式,而jsp文件保存的utf-8格式。

运行结果:
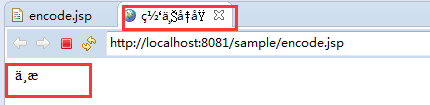
解决办法:
pageEncoding修改为utf-8格式。
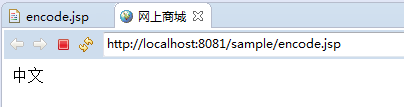
总结:
我们可以看到,由于pageEncoding被指定为”iso-8859-1”,导致其在由服务器将JSP文件编译成.java文件过程中,在使用 “iso-8859-1” 读取jsp并翻译成统一的UTF-8编码的JAVA源码时,所有的中文字符被转成乱码,并使得其呈现给用户的响应也包含乱码。
2、 contentType=”text/html;charset=UTF-8”
作用是将上述第二阶段所生成的UTF8形式的二进制码以charset的编码形式来输出到客户端,如果设置不当的话,会出现乱码。

3、POST请求的请求参数为中文情形request.setCharacterEncoding(“UTF-8”)
request.setCharacterEncoding(“UTF-8”)用来指定对浏览器发送来的数据以特定的字符集进行重新编码,常用于对 POST 请求参数进行解码。
一般地,我们以POST形式提交请求,以表单形式进行并且 form 的 method 属性为 post。
实例:
收集参数的表单页input.jsp:
<%@ page contentType="text/html; charset=utf-8" language="java" pageEncoding="utf-8" errorPage=""%>
<head>
<title>收集参数的表单</title>
</head>
<body>
<form id="form" action="show.jsp" method="post">
姓名:
<br />
<input type="text" name="name">
<hr />
性别:
<br />
男:
<input type="radio" name="sex" value="男">
女:
<input type="radio" name="sex" value="女">
<br />
<input type="submit" value="提交">
<input type="reset" value="重置">
</form>
</body>
</html>
显示表单页(show.jsp):
<%@ page language="java" import="java.util.*,java.net.*" contentType="text/html; charset=utf-8" pageEncoding="utf-8" errorPage=""%>
<html>
<head>
<title>显示表单信息</title>
</head>
<body>
<%!private String rawQueryString = null;%>
<%
/* 对于post请求,该语句为避免中文参数乱码起到关键作用 */
request.setCharacterEncoding("utf-8");
String name = request.getParameter("name");
String sex = request.getParameter("sex");
%>
<%
out.print("---------------------方式一:直接打印请求参数-----------------------");
out.print("name: " + name + "");
out.print("sex: " + sex + "");
%>
<%
out.print("---------------------方式二:利用String进行转码-----------------------");
out.print("name: " + new String(name.getBytes("ISO-8859-1"), "utf-8") + "");
out.print("sex: " + new String(sex.getBytes("ISO-8859-1"), "utf-8") + "");
%>
</body>
</html>
访问结果:

对于POST请求,若其请求参数包含中文字符,那么我们只需在解析请求参数前加一句如下的代码即可。
request.setCharacterEncoding("utf-8");
需要注意的是,这种方式对 Get请求起不到任何作用。此外,由于我们对请求已经重新编码,所以已经不需要使用 String类 再进行转码,否则多此一举。
4、response.setCharacterEncoding(“UTF-8”)
该作用是:在服务器将响应返回到浏览器前,对响应使用指定字符集进行重新编码。一旦使用了该种方式,即使该响应页面指定了具体的 contentType,也将失效。
在jsp中设置如下:
<% response.setCharacterEncoding("UTF-8"); %>
设置完并且访问页面如下:
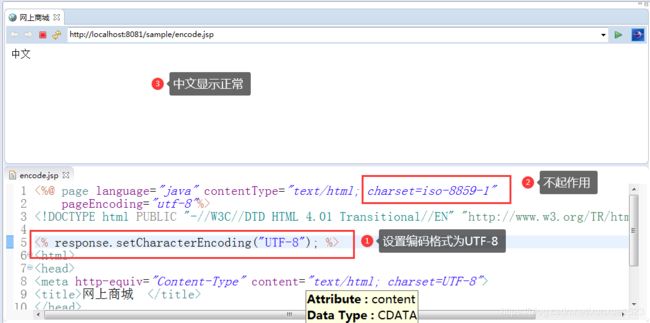
5、GET 请求的请求参数为中文情形
5.1、URL传递参数中文乱码
<!-- 请求URL示例:http://localhost:8081/sample/geturl.jsp?name=张三&sex=男 -->
<%@ page contentType="text/html; charset=utf-8" language="java"
pageEncoding="utf-8" errorPage="" import="java.net.*"%>
<head>
<title>URL传递参数中文乱码</title>
</head>
<body>
<%! private String rawQueryString = null; %>
<%
// 获取name请求参数的值
String name = request.getParameter("name");
// 获取sex请求参数的值
String sex = request.getParameter("sex");
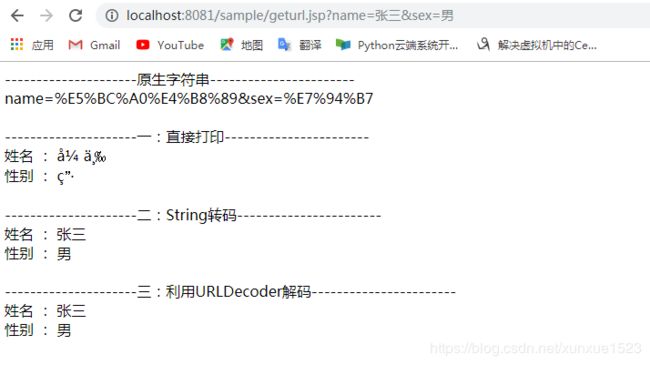
out.print("---------------------原生字符串-----------------------");
rawQueryString = request.getQueryString();
out.print(rawQueryString + "");
%>
<%
out.print("---------------------一:直接打印-----------------------");
out.print( "姓名 : " + name +"");
out.print( "性别 : " + sex + "");
%>
<%
out.print("---------------------二:String转码-----------------------");
out.print( "姓名 : " + new String(name.getBytes("iso-8859-1"),"utf-8") +"");
out.print( "性别 : " + new String(sex.getBytes("iso-8859-1"),"utf-8") +"");
%>
<%
out.print("---------------------三:利用URLDecoder解码-----------------------");
String queryString = URLDecoder.decode(rawQueryString, "utf-8");
String[] queryParams = queryString.split("&");
out.print( "姓名 : " + queryParams[0].split("=")[1] + "");
out.print( "性别 : " + queryParams[1].split("=")[1] +"");
%>
</body>
</html>
5.2、表单提交
getinput.jsp:
<%@ page contentType="text/html; charset=utf-8" language="java" pageEncoding="utf-8" errorPage=""%>
<head>
<title></title>
</head>
<body>
<form id="form" action="getshow.jsp" method="get">
用户名:
<br />
<input type="text" name="name">
<hr />
性别:
<br />
男:
<input type="radio" name="sex" value="男">
女:
<input type="radio" name="sex" value="女">
<hr />
<input type="submit" value="提交">
<input type="reset" value="重置">
</form>
</body>
</html>
getshow.jsp:
<%@ page language="java" import="java.util.*,java.net.*" contentType="text/html; charset=utf-8" pageEncoding="utf-8" errorPage=""%>
<html>
<head>
<title>表单提交中文乱码</title>
</head>
<body>
<%!private String rawQueryString = null;%>
<%
/* 对于get请求,该语句对避免中文参数乱码不起任何作用 */
request.setCharacterEncoding("utf-8");
String name = request.getParameter("name");
String sex = request.getParameter("sex");
out.print("---------------------原生字符串-----------------------");
rawQueryString = request.getQueryString();
if (rawQueryString != null)
out.print(rawQueryString + "");
%>
<%
out.print("---------------------一:直接打印-----------------------");
out.print("name: " + name + "");
out.print("sex: " + sex + "");
%>
<%
out.print("---------------------二:String转码-----------------------");
out.print("name: " + new String(name.getBytes("ISO-8859-1"), "utf-8") + "");
out.print("sex: " + new String(sex.getBytes("ISO-8859-1"), "utf-8") + "");
%>
<%
out.print("---------------------三:URLDecoder解码-----------------------");
if (rawQueryString != null) {
String queryString = URLDecoder.decode(rawQueryString, "utf-8");
out.print("解码后的字符串 : " + queryString);
String[] queryParams = queryString.split("&");
out.print(""+"name: " + queryParams[0].split("=")[1] + "");
out.print("sex: " + queryParams[1].split("=")[1] + "");
}
%>
</body>
</html>
运行结果:

5.3、总结
只要我们以GET形式提交请求,无论是以表单形式提交还是以URL形式提交,如果参数中存在中文字符,那么我们必须进行相应的转码(借助String类)或者解码(借助URLDecoder类)
1)request.getQueryString() 所返回的原生查询字符串只适用于 GET请求 ,若对 POST请求 使用,则返回 null;
2)利用 URLDecoder 进行解码时,必须先对原生查询字符串解码,而后获取各请求参数。如果先获取各个请求参数,再依次解码,则仍是乱码;
3)使用String进行 转码时,往往都是先从 ISO-8859-1 格式的字符串中取出字节内容,然后再用页面相应的编码格式重新构造一个新的字符串,像本示例(new String(country.getBytes(“ISO-8859-1”), “utf-8”))中的 一样。这样就可以支持中文字符的正常取值和显示;
4)利用 URLDecoder 进行解码时,所采用的解码字符集取决于浏览器(本文所有实验都是基于 Google Chrome 的)。对于中文环境而言,一般要么是 UTF-8,要么是 GBK ;
5)对于 GET请求,语句 request.setCharacterEncoding(“utf-8”); 对避免中文参数乱码起不到任何作用。
6、Eclipse中JSP文件中文乱码
Eclipse/MyEclipse编码格式设置 点击此处-------------------------------->
7、修改tomcat默认的编码方式
修改tomcat下的conf/server.xml文件
找到如下代码:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" />
上述代码规定了Tomcat监听HTTP请求的端口号等信息。
可以在这里添加一个属性:URIEncoding,将该属性值设置为UTF-8,即可让Tomcat(默认ISO-8859-1编码)以UTF-8的编码处理GET请求。
修改完成后:
<Connector port="8081" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8" />
修改完保存文件后重启服务器。