Hadoop MapReduce 深入理解!二次排序案例!
1. MapReduce 处理的数据类型
1.1 必须实现 org.apache.hadoop.io.Writable 接口。需要实现数据的序列化与反序列化,这样才能在多个节点之间传输数据!
示例:
public class IntWritable implements WritableComparable<IntWritable> ,
public interface WritableComparable<T> extends Writable, Comparable<T>Writable 接口定义如下:
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}在IntWritable中的实现如下:
@Override
public void readFields(DataInput in) throws IOException {
value = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(value);
}1.2 Key 必须实现WritableComparable
在MapReduce的过程中,需要对key进行排序,而key也需要在网络流中传输,因此需要实现WritableComparable,这是一个标志接口,实现了Writable, Comparable两个接口。
在IntWritable中的实现如下:
@Override
public boolean equals(Object o) {
if (!(o instanceof IntWritable))
return false;
IntWritable other = (IntWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return value;
}
/** Compares two IntWritables. */
@Override
public int compareTo(IntWritable o) {
int thisValue = this.value;
int thatValue = o.value;
return (thisValue1 : (thisValue==thatValue ? 0 : 1));
} 2 InputFormat
接口声明如下:
public interface InputFormat {
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
RecordReader getRecordReader(InputSplit split,
JobConf job,
Reporter reporter) throws IOException; InputFormat负责
1. 将输入文件进行逻辑切分(getSplits),每个分片形成一个InputSplit对象,每个InputSplit对象由一个Mapper对象(里面有我们自己需要实现的map方法)接收和处理,对应一个Map Task 任务。
2. 在一个Mapper对象处理一个InputSplit对象时,由getRecordReader方法提供更细致的切分,比如FileInputFormat是按行切分的,每行作为一个Mapper 的输入。
FileInputFormat的实现:
其中getSplits默认是按Block大小进行切分的。
getRecordReader仍然是个抽象函数。
默认情况下我们使用的是 public class TextInputFormat extends FileInputFormat
public RecordReader getRecordReader(
InputSplit genericSplit, JobConf job,
Reporter reporter)
throws IOException {
reporter.setStatus(genericSplit.toString());
String delimiter = job.get("textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter) {
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
}
return new LineRecordReader(job, (FileSplit) genericSplit,
recordDelimiterBytes);
} 可见,其先按行切分,然后按delimiter这个值切分得到一条条记录的。
3 Partitioner
3.1
经过InputFormat对数据的切分后,每个Mapper的输出结果是一系列的kv对,需要通过Patitioner把每条kv对标记为属于的某个Reducer,这样Reducer就可以拉取Mapper得到的结果。
接口定义如下:
public interface Partitioner extends JobConfigurable {
/**
* Get the paritition number for a given key (hence record) given the total
* number of partitions i.e. number of reduce-tasks for the job.
*
* Typically a hash function on a all or a subset of the key.
*
* @param key the key to be paritioned.
* @param value the entry value.
* @param numPartitions the total number of partitions.
* @return the partition number for the key.
*/
int getPartition(K2 key, V2 value, int numPartitions);
} 默认情况下,我们使用的是HashPartitioner
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}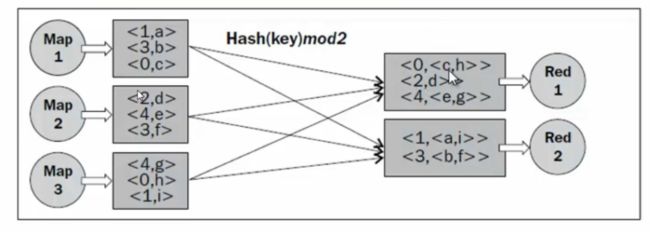
================================图3.1Partition过程================================
使用Hash的方式是所有的key的hashcode对reduce的数目取余数,因此虽然能够保证每个key相同的kv对会发送到同一个Reducer任务进行处理,但是当某个key对应的kv对数非常大,而其他却非常小时,这个Reducer节点就成了高负载节点,造成了计算资源的分配不均衡。
在Map阶段,可以使用job.setPartitionerClass设置的partition类进行自定义Partitioner
我们分析其过程:
job.java
public void setPartitionerClass(Classextends Partitioner> cls
) throws IllegalStateException {
ensureState(JobState.DEFINE);
conf.setClass(PARTITIONER_CLASS_ATTR, cls,
Partitioner.class);
}由以上设置过程中,可知,通过用户对job对象的属性设定,Partitioner的类入口被记录在了MRJobConfig.java的PARTITIONER_CLASS_ATTR中:这里PARTITIONER_CLASS_ATTR是一个key值,而 Partitioner.class是其对应的value值。
public static final String PARTITIONER_CLASS_ATTR = "mapreduce.job.partitioner.class";当要找到这个Partitioner类时:
JobContextImpl.java
//public class JobContextImpl implements JobContext
public Classextends Partitioner> getPartitionerClass()
throws ClassNotFoundException {
return (Classextends Partitioner>)
conf.getClass(PARTITIONER_CLASS_ATTR, HashPartitioner.class);
}可见默认的是HashPartitioner。
而对于Hadoop2.0 newPAI在JobConf.java中有PartitionerClass的set和get方法。
public void setPartitionerClass(Classextends Partitioner> theClass) {
setClass("mapred.partitioner.class", theClass, Partitioner.class);
}而获取Partitioner的类入口为
//JobConf.java
public Classextends Partitioner> getPartitionerClass() {
return getClass("mapred.partitioner.class",
HashPartitioner.class, Partitioner.class);
}可见默认的partitioner 仍然是HashPartitioner。
3.2 但是真的是这样吗?
我们思考,当Reducer的数量只有1个的时候,上述的HashPartition而的逻辑岂不是白费了!?
我们在HashPartition类内部做如下修改:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
int result = (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
System.out.printf("hase-partition:key\t%s,val\t%s,result:%n",key.toString(),value.toString(),result);
(new Exception()).printStackTrace();
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}这样在调用HashPartitioner的过程中就会打印异常栈了。
然而当Reducer只有一个的时候,上述异常并没有被触发!
再次查看3.1节的分析,我们只是从job类入手观察了用户设置的Partitioner的调用方法和实现,然而并没有查看具体的MapTask类内部是如何获取partitioner的。
下面我们从main函数开始捋程序,想要尽快理解二次排序的朋友可以跳到第4节了。
3.3 真正的程序入口
3.3.1 在YARN上提交任务
WordCount.java类的main函数的最后一句话是这么写的:
System.exit(job.waitForCompletion(true) ? 0 : 1);经过前面对job的配置,正是这句话触发了一个Job。
触发submit()
//job.java
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}submit()过程:
/**
* Submit the job to the cluster and return immediately.
* @throws IOException
*/
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
connect();
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
} 触发内部的提交过程的代码是:
return submitter.submitJobInternal(Job.this, cluster);这个内部提交完成了以下几件事情:
1.检查输入输出声明是否合法
2.计算InputSplit过程,代码如下:
InputFormat, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator()); 可见这里调用了InputFormat,得到了List splits,并进行了排序操作,且大块的split会优先处理。
3. DistributedCache 操作,就是把用户指定需要缓存的文件加载到各个节点上。
4. 任务jar包的拷贝分发和缓存,和3操作的原理一样。
5. 通过private ClientProtocol submitClient 真正的提交任务到集群,也就是前面的步骤还是一些准备工作。
//public interface ClientProtocol extends VersionedProtocol
/**
* Submit a Job for execution. Returns the latest profile for
* that job.
*/
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)
throws IOException, InterruptedException;ClientProtocol 有两个实现类,当我们做本地运行时是:
public class LocalJobRunner implements ClientProtocol而提交到YARN上时是:
public class YARNRunner implements ClientProtocol
不论是哪个个,最终都实现submitJob方法来执行程序。
在YARN中:
// private ResourceMgrDelegate resMgrDelegate;
// Construct necessary information to start the MR AM
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);
// Submit to ResourceManager
try {
ApplicationId applicationId =
resMgrDelegate.submitApplication(appContext);
ApplicationReport appMaster = resMgrDelegate
.getApplicationReport(applicationId);可见,ResourceMgrDelegate 是ResourceManager的一个代表类,负责将本app的上下文提交给appMaster 。
//ResourceMgrDelegate.java
protected YarnClient client;
@Override
public ApplicationId
submitApplication(ApplicationSubmissionContext appContext)
throws YarnException, IOException {
return client.submitApplication(appContext);
}而真正的提交任务又交给了YarnClient 这个类来处理。我们来看看YarnClient 这个类有什么用:
3.3.2 YarnClient
注: 本节可略过。
1 负责向ResourceManager提交任务。
* Submit a new application to YARN. It is a blocking call - it
* will not return {@link ApplicationId} until the submitted application is
* submitted successfully and accepted by the ResourceManager.我们发现了这样的一个设计模式!:
public class ResourceMgrDelegate extends YarnClient {
protected YarnClient client;
public ResourceMgrDelegate(YarnConfiguration conf) {
super(ResourceMgrDelegate.class.getName());
this.conf = conf;
this.client = YarnClient.createYarnClient();
init(conf);
start();
}
@Override
public ApplicationId
submitApplication(ApplicationSubmissionContext appContext)
throws YarnException, IOException {
return client.submitApplication(appContext);
}
}public abstract class YarnClient extends AbstractService {
/**
* Create a new instance of YarnClient.
*/
@Public
public static YarnClient createYarnClient() {
YarnClient client = new YarnClientImpl();
return client;
}在YarnClient 实现类YarnClientImpl的submitApplication方法中任务提交给了ApplicationClientProtocol :
//protected ApplicationClientProtocol rmClient;
rmClient.submitApplication(request);ApplicationClientProtocol 接口中submitApplication是clients 向ResourceManager提交新的应用请求操作。
The interface used by clients to submit a new application to the
* ResourceManager.我们来仔细分析一下ApplicationClientProtocol
1 这个类通过接收一个ApplicationId对象来提交新的applications
2 client 需要提供App的细节以启动ApplicationMaster
* The client is required to provide details such as queue,
* {@link Resource} required to run the ApplicationMaster,
* the equivalent of {@link ContainerLaunchContext} for launching
* the ApplicationMaster etc. via the
* {@link SubmitApplicationRequest}.
3 ….其他,总之,这个类充当了Client的角色,完成和ResourceManager的交互。
3.3.3 我们回顾MapReduce2.0的YARN架构:

可知,任务的最终执行是由一个个MapTask启动起来的。
因此为了深入挖掘Partitioner的调用,我们跳过ResourceManager和MRAppMaster,直接看MapTask类。
MapTask类中有两类run方法,我们直接看runNewMapper
private
void runNewMapper(final JobConf job...
..
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
} 可见当有Reducer接收Mapper的结果时,结果交给了NewOutputCollector对象来处理。
NewOutputCollector的定义如下:
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
collector = createSortingCollector(job, reporter);
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) {
partitioner = (org.apache.hadoop.mapreduce.Partitioner)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
} 从代码段:
else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
可以看出,当getNumReduceTasks的结果(Reducer的个数)小于等于1,其构造了一个匿名的partitioner 来做Partition过程,并没有走Hash过程。
3.3.1 在本地上提交任务
注:本节可略过
LocalJobRunner 通过多线程来模拟Mapper和Reducer
/** Implements MapReduce locally, in-process, for debugging. */
public class LocalJobRunner implements ClientProtocol {MapTaskRunnable 线程类模拟了Map过程
protected class MapTaskRunnable extends RunnableWithThrowable {在run方法中构造了MapTask对象,并调用其run方法来执行Mapper:
public void run() {
try {
...
MapTask map = new MapTask(systemJobFile.toString(), mapId, taskId,
info.getSplitIndex(), 1);
...
try {
map_tasks.getAndIncrement();
myMetrics.launchMap(mapId);
map.run(localConf, Job.this);
...MapTask对Partitioner的调用过程在3.3.3节已经分析过了。
4 Partition过程中的排序
由partition过程图可以看出其结果是按Key来排序的,那么key的排序是如何做到的呢?
在Map阶段,可以使用job.setSortComparatorClass设置的Comparator类进行自定义输出kv的key排序
//job.java
public void setSortComparatorClass(Classextends RawComparator> cls
) throws IllegalStateException {
ensureState(JobState.DEFINE);
conf.setOutputKeyComparatorClass(cls);
}那么哪里调用了这个Comparator类呢?
由以上设置过程中,可知,通过用户对job对象的属性设定,Comparator的类入口被记录在了conf对象中(protected final org.apache.hadoop.mapred.JobConf conf)。
而JobConf 类中通过
//JobConf.java
public void setOutputKeyComparatorClass(Classextends RawComparator> theClass) {
setClass(JobContext.KEY_COMPARATOR,
theClass, RawComparator.class);
}把Comparator类交给了JobContext.KEY_COMPARATOR来记录。
这个值的默认是:
//JobContext.java
public static final String KEY_COMPARATOR = "mapreduce.job.output.key.comparator.class";// JobConf.java
public RawComparator getOutputKeyComparator() {
Classextends RawComparator> theClass = getClass(
JobContext.KEY_COMPARATOR, null, RawComparator.class);
if (theClass != null)
return ReflectionUtils.newInstance(theClass, this);
return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this);
}可见,当我们没有配置Comparator类时,其返回的是
return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this);我们来仔细探究WritableComparator的这个get方法:
//public class WritableComparator implements RawComparator, Configurable {
//...
/** Get a comparator for a {@link WritableComparable} implementation. */
public static WritableComparator get(
Classextends WritableComparable> c, Configuration conf) {
WritableComparator comparator = comparators.get(c);
if (comparator == null) {
// force the static initializers to run
forceInit(c);
// look to see if it is defined now
comparator = comparators.get(c);
// if not, use the generic one
if (comparator == null) {
comparator = new WritableComparator(c, conf, true);
}
}
// Newly passed Configuration objects should be used.
ReflectionUtils.setConf(comparator, conf);
return comparator;
}找到传入其中的两个参数
第一个参数得到的是我们配置的OUTPUT_KEY_CLASS对应的class,也就是说是key的类型。
public Class getMapOutputKeyClass() {
Class retv = getClass(JobContext.MAP_OUTPUT_KEY_CLASS, null, Object.class);
if (retv == null) {
retv = getOutputKeyClass();
}
return retv;
}
public Class getOutputKeyClass() {
return getClass(JobContext.OUTPUT_KEY_CLASS,
LongWritable.class, Object.class);
}第二个参数是Configuration conf,也就是this。
从WritableComparator的get方法就可以知道,原来默认情况下SortComparatorClass的类就是Key对应的类。
5 Combiner
重点介绍Combiner调用机制,想看二次排序案例的朋友可以略过本节
6 GroupingComparator
在 hadoop-2.6.2-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples\SecondarySort.java 这个文件中,对GroupingComparator为:
/**
* Compare only the first part of the pair, so that reduce is called once
* for each value of the first part.
*/在job.java 中的定义如下:
/**
* Define the comparator that controls which keys are grouped together
* for a single call to
* {@link Reducer#reduce(Object, Iterable,
* org.apache.hadoop.mapreduce.Reducer.Context)}
* @param cls the raw comparator to use
* @throws IllegalStateException if the job is submitted
* @see #setCombinerKeyGroupingComparatorClass(Class)
*/
public void setGroupingComparatorClass(Class cls
) throws IllegalStateException {
ensureState(JobState.DEFINE);
conf.setOutputValueGroupingComparator(cls);
}由图3.1Partition过程可知,经过Partitioner的划分,每个Reducer Task节点都得到了一定量的kv对,每个相同的key后边都跟了一个val的列表,交给一个Reducer程序去处理(有点像倒排索引)。而实际上,在形成这样一个索引之前,kv的排列方式是一个挨着一个的kv对,只是key值经过SortComparatorClass的排序是有序的而已。
这里的这个GroupingComparator就是对key进行了第二次的处理,使得每个key后边可以挂一个val的列表。通过指定GroupingComparator我们可以实现这样的功能:
比如下面的kv列表:
baidu.A 1
baidu.A 1
baidu.B 1
baidu.B 1
google.A 1
google.A 1
google.B 1
google.B 1假设我的GroupingComparator只去比较Key的前3个字符,那么
baidu.A 1
baidu.A 1
baidu.B 1
baidu.B 1就可以分到一个列表中,形成如下的输入
{baidu.A :[1,1,1,1]}并被一个Reducer一次性处理。
接下来我们看看代码级别的实现:
//job.java
public void setGroupingComparatorClass(Classextends RawComparator> cls
) throws IllegalStateException {
ensureState(JobState.DEFINE);
conf.setOutputValueGroupingComparator(cls);
}//JobConf.java
public void setOutputValueGroupingComparator(
Classextends RawComparator> theClass) {
setClass(JobContext.GROUP_COMPARATOR_CLASS,
theClass, RawComparator.class);
}以上是设置方法,调用方法为:
public RawComparator getOutputValueGroupingComparator() {
Classextends RawComparator> theClass = getClass(
JobContext.GROUP_COMPARATOR_CLASS, null, RawComparator.class);
if (theClass == null) {
return getOutputKeyComparator();
}
return ReflectionUtils.newInstance(theClass, this);
}可见,默认情况下(当我们没有配置GroupingComparator时)是
return ReflectionUtils.newInstance(theClass, this);即还是这个对象本身实现的Compare接口。
那么如何自己定义这么一个GroupingComparator呢?
6.1 在SecondarySort.java中的示例如下:
/**
* Compare only the first part of the pair, so that reduce is called once
* for each value of the first part.
*/
public static class FirstGroupingComparator
implements RawComparator<IntPair> {
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return WritableComparator.compareBytes(b1, s1, Integer.SIZE/8,
b2, s2, Integer.SIZE/8);
}
@Override
public int compare( o1, IntPair o2) {
int l = o1.getFirst();
int r = o2.getFirst();
return l == r ? 0 : (l < r ? -1 : 1);
}
}可见我们只需要实现RawComparator接口即可。在实际的代码运行时发现, @Override
public int compare( o1, IntPair o2)方法并没有被调用,而第一个 @Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) 得到了调用。因此,实现的关键是这个方法。
//WritableComparator.java
/** Lexicographic order of binary data. */
public static int compareBytes(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
return FastByteComparisons.compareTo(b1, s1, l1, b2, s2, l2);
}// FastByteComparisons.java
/**
* Lexicographically compare two byte arrays.
*/
public static int compareTo(byte[] b1, int s1, int l1, byte[] b2, int s2,
int l2) {
return LexicographicalComparerHolder.BEST_COMPARER.compareTo(
b1, s1, l1, b2, s2, l2);
}LexicographicalComparerHolder.BEST_COMPARER.compareTo的最终的实现代码如下:
public int compareTo(byte[] buffer1, int offset1, int length1,
byte[] buffer2, int offset2, int length2) {
// Short circuit equal case
if (buffer1 == buffer2 &&
offset1 == offset2 &&
length1 == length2) {
return 0;
}
// Bring WritableComparator code local
int end1 = offset1 + length1;
int end2 = offset2 + length2;
for (int i = offset1, j = offset2; i < end1 && j < end2; i++, j++) {
int a = (buffer1[i] & 0xff);
int b = (buffer2[j] & 0xff);
if (a != b) {
return a - b;
}
}
return length1 - length2;
}
}这个方法是对两byte数组进行的比较,而byte数据是人不能理解的,我们很难做进一步定制,除非是特别简单的情况,像SecondarySort.java中的示例中,取length1和length2分别为Integer.SIZE/8这个固定长度,以使得后缀去掉。
这种比较方法十分难以控制,针对这种取两byte数组的前一部分做比较,取多长呢?
6.2 通过继承WritableComparator来实现
从getOutputValueGroupingComparator方法的返回值来看,返回的是RawComparator ,RawComparator 是一个接口,而WritableComparator是RawComparator 的一个实现类,因此我们可以继承一个WritableComparator类来定义FirstGroupingComparator 类:
// 自定义分组比较器
public static class IndexGroupingComparator extends WritableComparator {
protected IndexGroupingComparator() {
super(TwoFieldKey.class, true);
}
@Override
public int compare(WritableComparable o1, WritableComparable o2) {
int lIndex = ((TwoFieldKey) o1).getIndex();
int rIndex = ((TwoFieldKey) o2).getIndex();
return lIndex == rIndex ? 0 : (lIndex < rIndex ? -1 : 1);
}
}当然Reducer在执行比较的过程中,最终还是调用的
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)这个重载函数来进行比较的,但是WritableComparator已经对此函数做了很好的封装:
/** Optimization hook. Override this to make SequenceFile.Sorter's scream.
*
* The default implementation reads the data into two {@link
* WritableComparable}s (using {@link
* Writable#readFields(DataInput)}, then calls {@link
* #compare(WritableComparable,WritableComparable)}.
*/
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // compare them
}可见,compareBytes这种方法只是一种可选的优化机制,当我们不好控制时,只实现
public int compare(WritableComparable o1, WritableComparable o2) 方法就可以了,WritableComparator会为我们封装这个方法到compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) 中去。
7. 二次排序
SecondarySort.java示例中的程序使得二次排序能够实现。下面我们讲述二次排序的原理!
需求:
我们都知道mapreduce过程会对key进行排序输出,如果最终只有一个reduce程序那么key一定是有序的,即使有多个reduce程序并行,我们也可以通过设置每个reduce全局有序达到最终结果的有序。
而现在的需求是不但要key有序,value值也要有序。简单思路:
我们只需要在写reduce的过程中,对每个key对应的vaule列表进行排序即可(这里利用TreeSet排序集合)。代码如下:
public static class reducer
extends Reducer<LongWritable, Text, Text, LongWritable> {
private LongWritable result_key = new LongWritable ();
public void reduce(LongWritable itemid, Iterable values,
Context context
) throws IOException, InterruptedException {
result_key.set(itemid);
TreeSet queue = new TreeSet();
for (Text val : values) {
queue.add(new LongWritable(Long.valueOf(val.toString())));
}
}
for (LongWritable val : queue) {
System.out.println(result_key.toString() + "\t" + val.toString());
context.write(result_key, val);
}
}
} 然而,对于某个key,挂在它后边的values的数量达到了内存上限,这种方法就不行了。
SecondarySort.java 中的解决思路:
首先,构造了一个数据类型,这种数据类型同时保留了Key 和 Value的值
代码如下: key 值就是类IntPair 中的first,value就是类属性中的second。
public static class IntPair
implements WritableComparable {
private int first = 0;
private int second = 0;
/**
* Set the left and right values.
*/
public void set(int left, int right) {
first = left;
second = right;
}
public int getFirst() {
return first;
}
public int getSecond() {
return second;
}
/**
* Read the two integers.
* Encoded as: MIN_VALUE -> 0, 0 -> -MIN_VALUE, MAX_VALUE-> -1
*/
@Override
public void readFields(DataInput in) throws IOException {
first = in.readInt() + Integer.MIN_VALUE;
second = in.readInt() + Integer.MIN_VALUE;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(first - Integer.MIN_VALUE);
out.writeInt(second - Integer.MIN_VALUE);
}
@Override
public int hashCode() {
return first * 157 + second;
}
@Override
public boolean equals(Object right) {
if (right instanceof IntPair) {
IntPair r = (IntPair) right;
return r.first == first && r.second == second;
} else {
return false;
}
}
/** A Comparator that compares serialized IntPair. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(IntPair.class);
}
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
return compareBytes(b1, s1, l1, b2, s2, l2);
}
}
static { // register this comparator
WritableComparator.define(IntPair.class, new Comparator());
}
@Override
public int compareTo(IntPair o) {
if (first != o.first) {
return first < o.first ? -1 : 1;
} else if (second != o.second) {
return second < o.second ? -1 : 1;
} else {
return 0;
}
}
} 我们通过map生成IntPair和IntWritable这样的kv对:
/**
* Read two integers from each line and generate a key, value pair
* as ((left, right), right).
*/
public static class MapClass
extends Mapper<LongWritable, Text, IntPair, IntWritable> {
private final IntPair key = new IntPair();
private final IntWritable value = new IntWritable();
@Override
public void map(LongWritable inKey, Text inValue,
Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(inValue.toString());
int left = 0;
int right = 0;
if (itr.hasMoreTokens()) {
left = Integer.parseInt(itr.nextToken());
if (itr.hasMoreTokens()) {
right = Integer.parseInt(itr.nextToken());
}
key.set(left, right);
value.set(right);
context.write(key, value);
}
}
}此时,我们已经有了kv对的map列表了。接下来就是partitioner进行分区,指派到不同的reducer上执行reduce过程。
在这里,我们希望first属性相同的kv对partition到一个reducer上。因此我们不能再用默认的HashPartitioner了。
于是实现了根据key进行partition的代码:
/**
* Partition based on the first part of the pair.
*/
public static class FirstPartitioner extends Partitioner<IntPair,IntWritable>{
@Override
public int getPartition(IntPair key, IntWritable value,
int numPartitions) {
return Math.abs(key.getFirst() * 127) % numPartitions;
}
}由前文的分析,我们在Partitioner分区之后对每个区上的key的排序过程中,默认情况下是调用了IntPair的compareTo方法。
@Override
public int compareTo(IntPair o) {
if (first != o.first) {
return first < o.first ? -1 : 1;
} else if (second != o.second) {
return second < o.second ? -1 : 1;
} else {
return 0;
}
}就实现了对分区之后,每个区的IntPair的排序,先根据key排序,再根据val排序,这样就做到了即key有序,val也有序了。
在Reduce阶段之前,我们要把从Mapper拉过来的一系列的kv对,进行组合,即调用GroupingComparator进行转换,转换为 k:values的形式。
由前文分析可知,默认情况下,这个GroupingComparator还是IntPair实现的compareTo方法或者是Comparator 这类,这样的话就不能正确的得到分组,因此我们需要job.setGroupingComparatorClass(FirstGroupingComparator.class)来替代默认情况。
/**
* Compare only the first part of the pair, so that reduce is called once
* for each value of the first part.
*/
public static class FirstGroupingComparator
implements RawComparator<IntPair> {
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return WritableComparator.compareBytes(b1, s1, Integer.SIZE/8,
b2, s2, Integer.SIZE/8);
}
@Override
public int compare( o1, IntPair o2) {
int l = o1.getFirst();
int r = o2.getFirst();
return l == r ? 0 : (l < r ? -1 : 1);
}
}这样,一个Maper就能够得到正确的{k:values}组合了:
/**
* A reducer class that just emits the sum of the input values.
*/
public static class Reduce
extends Reducer<IntPair, IntWritable, Text, IntWritable> {
private static final Text SEPARATOR =
new Text("------------------------------------------------");
private final Text first = new Text();
@Override
public void reduce(IntPair key, Iterable values,
Context context
) throws IOException, InterruptedException {
context.write(SEPARATOR, null);
first.set(Integer.toString(key.getFirst()));
for(IntWritable value: values) {
context.write(first, value);
}
}
} 最后main函数的写法如下:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: secondarysort " );
System.exit(2);
}
Job job = new Job(conf, "secondary sort");
job.setJarByClass(SecondarySort.class);
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
// group and partition by the first int in the pair
job.setPartitionerClass(FirstPartitioner.class);
job.setGroupingComparatorClass(FirstGroupingComparator.class);
// the map output is IntPair, IntWritable
job.setMapOutputKeyClass(IntPair.class);
job.setMapOutputValueClass(IntWritable.class);
// the reduce output is Text, IntWritable
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}其他参考链接:
http://www.educity.cn/linux/1603517.html