R语言读取超大csv格式文件太慢怎么办,换个函数读,秒秒钟读取!!!
秒秒钟读取csv大文件!!!
文章目录
- 秒秒钟读取`csv`大文件!!!
- 1. csv三剑客
- 1.1 read.csv()
- 2.2 readr::read_csv() + dplyr::mutate_if()
- 2.3 data.table::fread()
- 2. 华山论剑(纯速度比拼)
- 2.1 data01: 500行&561列
- 2.2 data02: 5000行&561列
- 2.3 data03: 42766行&561列
- 3. 总结
- 4. 拓展阅读
最近在做毕业设计,遇到一个问题,在使用R读取上市公司数据时,由于文件太大导致读取数据比较慢,如果把文件拆解成多个文件读取又比较繁琐,查了查资料发现有解决办法。
大家比较熟知R读取csv格式文件的函数是R内置的read.csv(),但除此之外还有其他的,比如readr包的read_csv()函数和data.table包的fread()函数。
1. csv三剑客
1.1 read.csv()
怎么用不详细说了就,说说弊病吧,最主要的是大文件读取速度慢,其次表头的留存问题和字符型数据乱码:
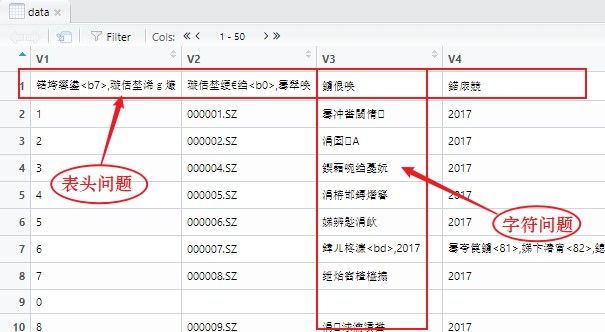
基本用法:
read.csv(file, header = TRUE, sep = ",", quote = "\"", dec = ".", fill = TRUE, comment.char = "", ...)
2.2 readr::read_csv() + dplyr::mutate_if()
read_csv()函数需要加载readr包,而用dplyr包的mutate_if()函数可以进行数据类型转换。
基本用法:
read_csv(file, col_names = TRUE, col_types = NULL,
locale = default_locale(), na = c("", "NA"), quoted_na = TRUE,
quote = "\"", comment = "", trim_ws = TRUE, skip = 0,
n_max = Inf, guess_max = min(1000, n_max),
progress = show_progress(), skip_empty_rows = TRUE)
例如读取mtcars数据集:
setwd("F://csv数据读取大比拼") #设置工作区间
#读取数据集
library(readr)
mtcars <- read_csv("mtcars.csv")
mtcars
#> # A tibble: 32 x 12
#> type mpg cyl disp hp drat wt qsec vs am gear carb
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Mazda RX4 21 6 160 110 3.9 2.62 16.5 0 1 4 4
#> 2 Mazda RX4 Wag 21 6 160 110 3.9 2.88 17.0 0 1 4 4
#> 3 Datsun 710 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
#> 4 Hornet 4 Drive 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
#> 5 Hornet Sportabout 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2
#> 6 Valiant 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1
#> 7 Duster 360 14.3 8 360 245 3.21 3.57 15.8 0 0 3 4
#> 8 Merc 240D 24.4 4 147. 62 3.69 3.19 20 1 0 4 2
#> 9 Merc 230 22.8 4 141. 95 3.92 3.15 22.9 1 0 4 2
#> 10 Merc 280 19.2 6 168. 123 3.92 3.44 18.3 1 0 4 4
#> # ... with 22 more rows
#变量类型转变
library(magrittr) #管道操作(简化代码),包含`%>%`
library(dplyr)
mtcars <- mtcars %>% mutate_if(is.character, factor) #%>%向右操作符
mtcars <- mtcars %>% mutate_if(is.double, factor)
mtcars
#> # A tibble: 32 x 12
#> type mpg cyl disp hp drat wt qsec vs am gear carb
#> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct>
#> 1 Mazda RX4 21 6 160 110 3.9 2.62 16.46 0 1 4 4
#> 2 Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4
#> 3 Datsun 710 22.8 4 108 93 3.85 2.32 18.61 1 1 4 1
#> 4 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
#> 5 Hornet Sportabout 18.7 8 360 175 3.15 3.44 17.02 0 0 3 2
#> 6 Valiant 18.1 6 225 105 2.76 3.46 20.22 1 0 3 1
#> 7 Duster 360 14.3 8 360 245 3.21 3.57 15.84 0 0 3 4
#> 8 Merc 240D 24.4 4 146.7 62 3.69 3.19 20 1 0 4 2
#> 9 Merc 230 22.8 4 140.8 95 3.92 3.15 22.9 1 0 4 2
#> 10 Merc 280 19.2 6 167.6 123 3.92 3.44 18.3 1 0 4 4
#> # ... with 22 more rows
2.3 data.table::fread()
使用fread()函数需要加载data.table包,用法在这里。
2. 华山论剑(纯速度比拼)
2.1 data01: 500行&561列
## read.scv()
system.time(data11 <- read.csv(file = "上市公司数据.500行.csv", header = F))
#> 用户 系统 流逝
#> 0.86 0.00 0.87
## read_csv()
library(readr)
system.time(data12 <- read_csv(file = "上市公司数据.500行.csv"))
#> 用户 系统 流逝
#> 0.21 0.01 0.27
## fread()
library(data.table)
system.time(data13 <- fread(input = "上市公司数据.500行.csv", stringsAsFactors = T, encoding = "UTF-8"))
#> 用户 系统 流逝
#> 0.04 0.00 0.09
read_csv()函数和fread()函数优势明显
2.2 data02: 5000行&561列
## read.scv()
system.time(data21 <- read.csv("上市公司数据.5000行.csv", header = F))
#> 用户 系统 流逝
#> 9.67 0.63 11.99
## read_csv()
library(readr)
system.time(data22 <- read_csv("上市公司数据.5000行.csv"))
#> 用户 系统 流逝
#> 0.73 0.00 0.73
## fread()
library(data.table)
system.time(data23 <- fread("上市公司数据.5000行.csv", stringsAsFactors = T, encoding = "UTF-8"))
#> 用户 系统 流逝
#> 0.22 0.03 0.20
read_csv()函数和fread()函数优势明显,read.csv()函数已经掉队
2.3 data03: 42766行&561列
## read.scv()
system.time(data31 <- read.csv("上市公司数据.csv", header = F))
#> 用户 系统 流逝
#> 96.13 1.08 99.22
## read_csv()
library(readr)
system.time(data32 <- read_csv("上市公司数据.csv"))
#> 用户 系统 流逝
#> 6.28 0.60 10.36
## fread()
library(data.table)
system.time(data33 <- fread("上市公司数据.csv", stringsAsFactors = T, encoding = "UTF-8"))
#> 用户 系统 流逝
#> 0.92 0.24 4.15
read.csv()函数已经废掉了,CPU都可以煮鸡蛋了!read_csv()函数和fread()函数优势明显,论速度fread()函数为本次华山论剑冠军!!!
3. 总结
如果文件较小,那就无所谓啦,但推荐read_csv()函数和fread()函数
如果文件非常大,就选fread()函数,杠杠的!
4. 拓展阅读
-
关于
readr和data.table::fread()的比较(readr包的作者) -
data.table和pandas的处理速度对比:grouping -
这里有一份类似的介绍