PySpark GraphFrame图计算使用指南
PySpark GraphFrame图计算使用指南
GraphFrame是将Spark中的Graph算法统一到DataFrame接口的Graph操作接口,为Scala、Java和Python提供了统一的图处理API。
Graphframes是开源项目,源码工程如下:https://github.com/graphframes/graphframes
基本介绍
图结构是一个解决很多数据问题的直观的方法。无论是遍历社会网络,餐馆推荐,或者是飞行路径,都可以通过图结构的上下文来快速地理解所面临的问题: 顶点(Vertices)、边(edges)和属性(properties)。 例如,飞行数据的分析是一个经典的图论问题,机场用 vertices代表,飞行路线用 edges 来代表。同时,这里有很多属性与飞行路线有关,比如离港延误、飞机的类型和装载能力等等。
与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,但得益于DataFrame,因此GraphFrames与GraphX库相比有着下面几方面的优势:
-
统一的 API: 为Python、Java和Scala三种语言提供了统一的接口,这是Python和Java首次能够使用GraphX的全部算法。
-
强大的查询功能:GraphFrames使得用户可以构建与Spark SQL以及DataFrame类似的查询语句。
-
图的存储和读取:GraphFrames与DataFrame的数据源完全兼容,支持以Parquet、JSON以及CSV等格式完成图的存储或读取。
在GraphFrames中图的顶点(Vertex)和边(edge)都是以DataFrame形式存储的,所以一个图的所有信息都能够完整保存。
社交网络实例
假设我们有一个社交网络,用户之间通过关系建立联系,如下图。
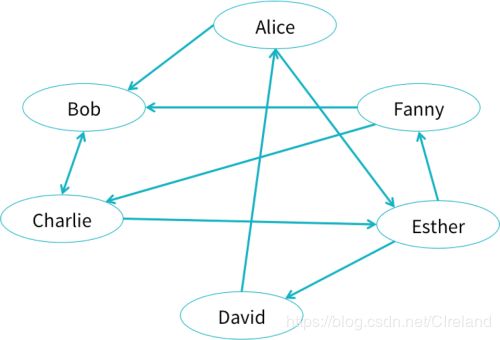
节点和边数据如下:

Spark上基本操作
1、配置环境
下载和spark版本对应的jar包:https://spark-packages.org/package/graphframes/graphframes
测试环境用的是:
Version: 0.7.0-spark2.3-s_2.11 ( f9e13a | zip | jar ) / Date: 2019-01-08 / License: Apache-2.0 / Scala version: 2.11
将jar包导入服务器,可以放在/home/pyspark/目录下,在spark-submit启动指令时添加jar包:
spark-submit --jars /home/pyspark/graphframes-0.7.0-spark2.3-s_2.11.jar
2、创建图
分别向GraphFrame中传入一个顶点数据集vertices和一个边数据集edges,两个都是DataFrame格式:
顶点的格式是:【id,name】
边的格式是【src,dst,”action”】
g = graphframe.GraphFrame(vertices,edges)
注:构建GraphFrame图时,导入的边源顶点命名为src,目标顶点命名为dst,不然会报错:ValueError: Source vertex ID column src missing from edge DataFrame…。
3、可调用的方法接口
outDegree() 所有节点的出度
inDegree() 所有节点的入度
vertices 打印出顶点
edges 打印出边
bsf() 广度优先搜索,查找节点的最短路径
pageRank() 按照其他节点指向它的数目来排序,指向一个节点的越多,这个节点就越重要
1)简单数据分析
g.inDegree() #计算顶点的入度
g.inDegrees.sort("id").show()
g.outDegree() #计算顶点的出度
g.outDegrees.sort("id").show()
g.vertices.show()
g.vertices.groupBy().min("age").show() #对顶点进行分组聚合
g.vertices.filter("age < 30").show() #按条件筛选顶点
g.edges.show()
g.edges.filter("relationship = 'follow'").count() #按条件筛选边2)复杂数据分析
pageRank算法
#查找图中最重要的用户可以用pageRank函数:
results = g.pageRank(resetProbability=0.15, maxIter=10)
display(results.vertices)
pageRank算法核心思想:
(1)如果一个网页被很多其他网页链接到的话,说明这个网页比较重要,也就是PageRank值会相对较高;
(2)如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高。
一般情况下,一个网页的PR值计算公式为:
P R ( p i ) = α ( P R ( B ) 2 ) + ( 1 − α ) 4 , 一 般 取 值 α = 0.85 PR(p_i)=\alpha\left(\frac{PR(B)}{2}\right)+\frac{(1-\alpha)}{4}, 一般取值\alpha=0.85 PR(pi)=α(2PR(B))+4(1−α),一般取值α=0.85
GraphFrames还支持的算法
- 广度优先搜索(BFS):查找从一组顶点到另一组顶点的最短路径
- 模式发现(Motif finding):在图中搜索结构模式
再举一个Motif finding例子,比如我们想给用户推荐关注的人就可以寻找图中满足下面这个条件的ABC三个用户:A关注B,B关注C但A并未关注C。代码如下:
# Motif: A->B->C but not A->C
results = g.find("(A)-[ab]->(B); (B)-[bc]->(C); !(A)-[ac]->(C)")
# Filter out loops (with DataFrame operation)
results = results.filter("A.id != C.id")
# Select recommendations for A to follow C
results = results.select("A", "C")
display(results)
3)GraphFrames支持的全套GraphX算法
- PageRank:查找图中的重要顶点。
- 最短路径:查找从每个顶点到目标顶点的最短路径。
- 连通组件:通常在分析的早期用于理解图的结构,事先运行连通组件来测试图是否连接,避免在图的一个孤岛组件上运行算法而得到不正确的结果。它可以快速显示组之间的新节点,对于欺诈检测等分析非常有用。
- 强连通组件:作为图分析的早期步骤,以了解图的结构,或确定可能需要独立调查的紧密集群。对于推荐引擎等应用程序,可以使用强连通的组件来分析组中的类似行为或关注的重点。
- 三角形计数:计算每个顶点所属的三角形的数量,经常用于确定组的稳定性(相互连接的数量代表了稳定性)或作为其他网络度量(如聚类系数)的一部分,在社交网络分析中用来检测社区。
- 标签传播算法(LPA):检测图中的社区。
4、创建子图
第一种:
# 直接用filterVertices和filterEdges过滤顶点和边用来创建子图
g1 = g.filterVertices("age > 30").filterEdges("relationship = 'friend'")
g1 = g.filterVertices("age > 30").filterEdges("relationship = 'friend'").dropIsolatedVertices()上面对子图调用dropIsolatedVertices()方法,删除孤立的没有连接的点。
第二种:
# 路径搜索
paths = g.find("(a)-[e]->(b)")\
.filter("e.relationship = 'follow'")\
.filter("a.age < b.age")
# 选择关系数据集中的列
e2 = paths.select("e.src", "e.dst", "e.relationship")
# 使用顶点和边的集合构造子图
g2 = GraphFrame(g.vertices, e2)代码分析:
① 首先用(a)-[e]->(b)过滤出所有连接的顶点,并使用filter条件过滤,得到顶点数据集;
② select映射边的格式,得到一个边的数据集;
③ 再将顶点和边的数据集传入GraphFrame可以得到一个子图。
参考:
[1]Introducing GraphFrames
[2]基于pyspark GraphFrames实现图查询和计算
[3]Pagerank算法
[4]各类图算法的使用场景