ElasticSearch 学习笔记
ElasticSearch 学习笔记
文章目录
- ElasticSearch 学习笔记
- 基本概念
- 倒排索引
- timeout 超时
- Query 与 filter 的区别
- query
- 全文检索
- 短语检索
- 高亮检索
- 分组检索
- 平均值的检索
- 区间检索
- 批量查询
- 查询排序
- 查询缓存
- 文档替换与删除
- ES路由
- 查询路由
- 分词
- Mapping 映射
- mapping的概念
- 查看mapping
- mapping的创建
- mapping的修改
- query相关度算法
- elasticSearch 存储结构
- elasticSearch 存储结构特点
- 扩容方案
- 垂直扩容(建议)
- shard重新分配(rebalance)
- master节点
- master选举
- 节点对等的分布式架构
- 并发冲突
- 乐观锁控制
- docment写入流程
- 问题
基本概念
- index : 索引 一个索引中可以有多个type (建议一个index中只有一个type , 因为它的存储结构是将一个index的所有type的field整合成一个大的json , 当多个type的field 都不同时,那么一个docment的自己的field是有值的其他的docment的field都是null,这样会浪费很多存储空间,但是在elasticSearch7中将type给忽略了,也就是index下可以直接有docment,这样就不会出现feild为空而造成的存储空间浪费现象)
- type : 类型 一个type中可以有很多docment
- docment : 文档 es中最小数据存储单元
- field : 文档内的一个属性
- mapping : 映射 ?
- primary shard : 主分片存储 (存储结构详解2)
- replica shard : 分片副本,作为主分分片的副本存在,与主分片数据一致(容错与负载)
- node : 部署节点,多节点部署会形成集群
倒排索引
-
倒排索引:
id name 1 北京布鞋 2 南京布鞋 3 澳洲皮鞋 正排索引的搜索是按照一条文档一条文档进行匹配查询(先查id再匹配判断)
根据以上的正排索引我们会生成按name分词的倒排索引
name doc1 doc2 Doc3 北京 1 0 0 南京 0 1 0 澳洲 0 0 1 布鞋 1 1 0 倒排索引是直接进行匹配判断,获取到文档ID后,根据文档ID再去查询正排索引获取数据
倒排索引在查询语句分析出后,才去确认创建那个filed的倒排索引
timeout 超时
设置timeout时间,在超过这个时间之后会将这个时间段内查询到的数据返回,后续的还会查询但是不会返回,
所以在查询大量数据的是时候进来使用分片查询
from : 1 ,开始位置1
size : 100 , 查询100条
Query 与 filter 的区别
query 翻译是查询 , 会有相关度计算 (相关度算法后面回解释)
filter 翻译是过滤 , 只有结果没有相关度计算
query
全文检索
-
命令
- 6 版本 GET /index(索引) /type(类型)/_search
- 7 版本 GET /index(索引)/_search
-
查询body
{ "query":{ "match":{ "name":"张三" } } } -
结果集分析
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 2.271394, "hits" : [ { "_index" : "user", "_type" : "user", "_id" : "2", "_score" : 2.271394, "_source" : { "name" : "张三", "age" : 21, "desc" : "这是一个测试用户" } } ] } }field 描述 took 查询花费时间单位 毫秒 timed_out 是否开启timeout _shards.total 查询了多少shard _shards.successful 成功的查询了多少shard _shards.failed 多少个shard没有被查询到 hits.max_score 最大相关度事多少 hits.hits 查询结果(是经过封装过后的) hits.hits._index 该数据的索引 hits.hits._type 该数据的类型 hits.hits._score 该数据的相关度 hits.hits._id 该docment的ID hits.hits._source 该docment的内容
短语检索
-
命令与全文检索相同
-
查询body
{ "query":{ "macth_phrase":{ "name":"张三" } } } -
结果分析与全文检索一致
高亮检索
-
命令与全文检索一致
-
查询body
{ "query":{ "match": { "name": "张" } }, "highlight": { "fields": { "name": {} } } } -
结果集分析
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 2.271394, "hits" : [ { "_index" : "user", "_type" : "user", "_id" : "2", "_score" : 2.271394, "_source" : { "name" : "张三", "age" : 21, "desc" : "这是一个测试用户" }, "highlight" : { "name" : [ "张三" ] } } ] } }field 描述 highlight 标红字的field name index的一个field 与 source中的name是一个意义
分组检索
-
命令 同上
-
查询body 按name 进行分组
{ "aggs": { "group_by_name": { "terms": { "field": "age" } } } } -
结果分析
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "user", "_type" : "user", "_id" : "2", "_score" : 1.0, "_source" : { "name" : "张三", "age" : 21, "desc" : "这是一个测试用户" } }, { "_index" : "user", "_type" : "user", "_id" : "3", "_score" : 1.0, "_source" : { "name" : "李四", "age" : 80, "desc" : "这是一个老人" } }, { "_index" : "user", "_type" : "user", "_id" : "1", "_score" : 1.0, "_source" : { "name" : "测试用户1", "age" : 23, "desc" : "这是一个用户1" } } ] }, "aggregations" : { "group_by_name" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : 21, "doc_count" : 1 }, { "key" : 23, "doc_count" : 1 }, { "key" : 80, "doc_count" : 1 } ] } } }feild 描述 aggregations.buckets.key 分组值 aggregations.buckets.value 分组计数 平均值的检索
-
命令 同上
-
查询body
{ "aggs": { "avg_age": { "avg": { "field": "age" } } } } -
结果分析
{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "user", "_type" : "user", "_id" : "2", "_score" : 1.0, "_source" : { "name" : "张三", "age" : 21, "desc" : "这是一个测试用户" } }, { "_index" : "user", "_type" : "user", "_id" : "3", "_score" : 1.0, "_source" : { "name" : "李四", "age" : 80, "desc" : "这是一个老人" } }, { "_index" : "user", "_type" : "user", "_id" : "1", "_score" : 1.0, "_source" : { "name" : "测试用户1", "age" : 23, "desc" : "这是一个用户1" } } ] }, "aggregations" : { "avg_age" : { "value" : 41.333333333333336 } } }field 描述 aggregations.avg_age avg_age是我们查询的时候自定义的名称与body中的名称相对应 aggregations.avg_age.value 针对于这个avg_age的平均值也就是所有用户的平均age
-
区间检索
-
命令同上
-
检索body
{ "query": { "range": { "age": { "gte": 20, "lte": 30 } } } } -
结果分析与全文检索一致
批量查询
-
命令 GET /_mget
-
查询body
{ "docs":[ { "_index":"user", "_type":"user", "_id":1 }, { "_index":"test1", "_type":"test1", "_id":1 } ] } -
结果分析
{ "docs" : [ { "_index" : "user", "_type" : "user", "_id" : "1", "_version" : 5, "_seq_no" : 6, "_primary_term" : 1, "found" : true, "_source" : { "name" : "测试用户111", "age" : 23, "desc" : "这是一个用户1111" } }, { "_index" : "test1", "_type" : "test1", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "name" : "test1" } } ] }多个index下的结果可以i 一起返回,节省io请求,优化方式之一
查询排序
当我们使用一个字符串进行排序的时候,实际上是使用的field分词之后的单词进行排序的,而不是那字符串本身进行排序,我们需要将排序字段单独设置一个mapping index设置为false ,不索引,使用字段本身进行排序
查询缓存
我们在查询的时候会进行倒排索引的查询,在查询倒排索引的时候会将查询结果以二进制数组的方式作为缓存
例如我们上面的倒排索引, 查询南京就会出现[0,1,0]这样的数组,当下一个一模一样的查询过来时,不会再查询索引表,而是直接使用这个缓存
文档替换与删除
- 文档是有_version属性的
- put 在全量替换的时候就是将之前的docment标记为删除并新创建一个docment,version会拷贝过来
- 用户在删除docment的时候es并没有直接将docment删除掉,只是将它标记为delete状态而已
- 当新的文档进来而内存不足时会将标记为delete的数据删除
ES路由
### 增删改路由
- 路由是在分布式架构下,分片存储,备份存储的前提下的解决方案
- 路由算法 shard = hash(routing)%number_of_primary_shards
- routing 默认是原数据_id ,但是我们可以进行指定
- 在指定routing的时候只可以指定一次,也就是一个index的有且只有一个,中间不可以发生改变
查询路由
- 我们在查询的时候会先走增删改路由,来确认次数据是属于那个primary shard 的数据
- 得知数据在那个primary shard 的时候我们的primary shard 有至少一个replica shard ,但是我们是用的那个shard呢?
- 这是我们可以不指定路由,10个查询请求可能有3个在primary shard 上 ,7个在replica shard上
- 我们在请求的时候指定查询routing的时候着10个请求就只会在一个shard上了
- 为什么要指定查询路由?在主从数据同步的时候会出现基础数据顺序不一致的情况,那么我们第一次查询可能是123,但是第二次查询如果不在同一个shard上是就可能是213,所以我们在查询的时候进来要指定查询路由
- 指定查询路由 GET /user/user/_search?routing= _id
分词
-
分词器就就是将一段话按词语进行切分,时态转换,单复数转换
-
es中按切分的词语创建了倒排索引的表
-
分词器的组成
- chardcter filter: 分词之前的预处理 (例如: 过滤标签 , 特殊字符转化等)
- tokenizer: 进行分词
- token filter : 去除停用词,将一些没有意义的词进行剔除,同义词转换
-
elasticsearch的内置分词器
-
standard analyzer : 大小写转换 空格拆分 (默认)
-
simple analyzer : 简单分词器 空格下划线拆分
-
whitespace analyzer :
-
Language analyzer : 特定语言分词器
-
Mapping 映射
mapping的概念
1. mapping是index的元数据,每个field都有自己的mapping,它决定了数据类型,建立索引的行为,还有搜索行为
2. mapping的基础类型
1. text
2. keyword 不会进行分词
3. integer
4. long
5. date 需要指定format格式
6. float
7. double
3. 不可修改,重点,重点,重点
查看mapping
-
命令 GET /index/_mapping/type
-
结果解析
{ "user" : { "mappings" : { "properties" : { "age" : { "type" : "long" }, "desc" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } }, "fielddata" : true } } } } }field 描述 user index索引 mappings 该索引下所有的field的mapping设置 properties 属性集合 age/name 我们的属性 type field对应的类型 fields 一个属性可以在属性内再次设置它的mapping fidlds.keyword 属性的第二个mapping这是不是它的mapping而是name.keyword的mapping要使用这个mapping的时候查询条件是name.keyword不是name
mapping的创建
PUT /user
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "english"
}
}
}
}
mapping的修改
PUT /user/_mapping
{
"properties":{
"name":{
"type":"text"
,
"fielddata":true
}
}
}
query相关度算法
- TF 算法:搜索文本中各个词条在field中出现的次数,出现的越多,相关度越高
- IDF 算法: 搜索文本中的各个词条在所有的field中出现的次数,出现越多相关度越低,(物以稀为贵)
- Field-length norm : field长度越长相关度越低 , 这个单词在这个field中的重要性越低
elasticSearch 存储结构
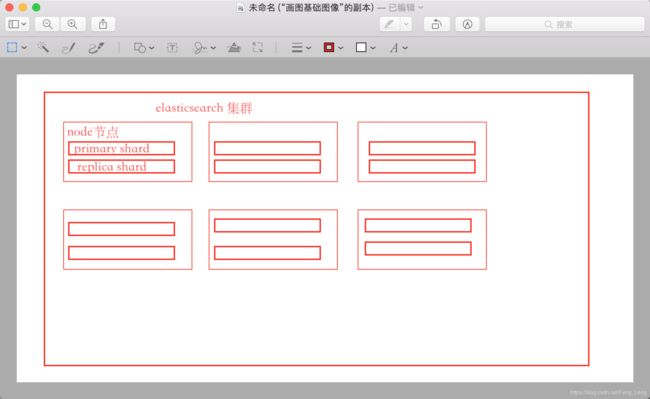
elasticSearch 存储结构特点
- 一个index可以设置多个primary shard 与多个 replica shard, 总的分片数是 peimary shard * replica shard 数(primay shard 是在创建索引是就固定的不可修改 , replica shard 是可以修改的)
- 一个node节点上对于一份数据只会存储一次,也就是说,一个node上只有index的中的一个 primary shard 或一个 replica shard (用来保障数据的高可用,提升吞吐量)不同的index的primary shard可以在一个节点上
- 在创建index的时候没有设置shard的时候默认是 5 个 primary shard 每个primary shard 有一个 replica sahrd
- shard 负载均衡
- 请求路由
- 集群扩容
- shard重新分配
扩容方案
#### 水平扩容
将现有集群的内存扩大
垂直扩容(建议)
增加节点加入集群,当每个节点上只有一个shard的时候就遇到了瓶颈,这时我们可以增加replica shard来再次增加性能
shard重新分配(rebalance)
当机器增加或减少是集群会将已有的shard重新分配到现有机器上保持负载均衡,这是需要一个
master节点
在重新分配的时候需要一个机器来计算并调配资源所以集群中需要一个master节点
管理索引的元数据,默认情况下集群回自动选举一个master节点
master节点不会去承载请求(一般不会去承载数据)
master选举
-
当master节点宕机的时候集群状态是red
-
自动选举一个新的master
-
如果有primary shard丢失,会将丢失的primary shard 的replica shard 提升为primary shard
-
这是这个primary shard 无法在创建新的replica shard的时候集群是yellow状态
-
宕机的节点重启之后会rebalance,根据primaryshard进行数据恢复
节点对等的分布式架构
- 每个节点都可以接收到所有的请求,无论我这份节点上是否有该索引的shard,我都会接受这个请求(路由的时候不会区分primary shard还是replica shard)
- 自定请求路径,当这个节点接受到非本节点的index的请求时,会将请求自定义到对应的节点上
- 相应收集,当这个请求所需要的数据不止在一个节点上的时候,该节点会将请求路由到有所有数据的节点,并收集返回的数据进行二次处理(尤其是在分页的时候)
并发冲突
乐观锁控制
- es中的元数据有version 在,docment发生修改之后就会加1,新的修改过来时会先判断version,不对就重新读区
docment写入流程
es底层使用的是lucene,lucene底层index是分为多个segment,每个segment都会存储一部分数据,
buffer始终存在,不停的写入刷新到segment中,磁盘写入完成后清空buffer
buffer每次写满或refresh_interval之后都会将数据commint到一个新的index segment中去
删除会将数据记录在.del文件中,查询结果会去匹配这个文件,将删除的数据去掉,不会返回,当commint point 的时候将标记为deleted的数据从内存及磁盘上删除
refresh_interval:内存间隔多长时间数据会执行以上所有操作
refresh_interval默认设置是1s,在设置的时候需要加单位设置 1s,2ms,3min等
当translog文件到达一定大小时会将buffer中的数据新建一个segment,并进行commint point写入OS cache及磁盘上,同时记录那些segment提交过,translog日志文件清空,这个过程叫做flush
translog内记录的数据是包含没有fsync的segment中的数据的,OS cache中的数据也是依靠translog内的数据恢复的
flush触发机制30分钟或translog过大
commint point 的时候会将已有的segment merge成一个segment刷新到OS cache和磁盘上,并删除之前的segment这样会减少segment文件过多的问题
问题
-
一个index下如果有多个type 那么docment_id就会冲突?
答:这时不可以使用数据的ID来设置,需要使用elasticsearch生成的ID否则方法id两个表中的某一条数据ID重复elasticsearch只会存储一条数据(不管是那个版本禁止一个index下有多个type)
-
Elasticsearch中每个shard上的数据最优大小是多少有算法吗?(未解决)
最后的问题我依旧没有解决,如果有了解的小伙伴记得私信一下我哦