pytorch - GAN
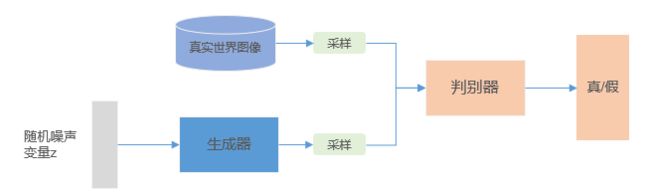
Ian Goodfellow在2014年的《Generative Adversarial Nets》中提出了生成对抗网络的概念,具体的思想大家恐怕都看烂了~整个模型的架构可以表示为
目标函数为 min G max D V ( G , D ) = E x − p data ( x ) log D ( x i ) + E x ∼ p z ( z ) log ( 1 − D ( G ( z i ) ) ) \min _{G} \max _{D} V(G, D)=E_{x-p_{\text { data }}(x)} \log D\left(x_{i}\right)+E_{x \sim p_{z}(z)} \log \left(1-D\left(G\left(z_{i}\right)\right)\right) GminDmaxV(G,D)=Ex−p data (x)logD(xi)+Ex∼pz(z)log(1−D(G(zi)))
下面来看一下我们用pytorch如何在MNIST数据集上实现GAN,以下的代码来源于pytorch-GAN。
- 首先引入所需的库文件
## argparse是python用于解析命令行参数和选项的标准模块
# 使用步骤:
# 1 import argparse
# 2 parser = argparse.ArgumentParser()
# 3 parser.add_argument()
# 4 parser.parse_args()
import argparse
import os
import numpy as np
import math
# 用于data augmentation
import torchvision.transforms as transforms
# 保存生成图像
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
- 然后设置模型中的某些参数,这里使用了argparse来集中操作
# 如果根目录下不存在images文件夹,则创建images存放生成图像结果
os.makedirs("images", exist_ok=True)
# 创建解析对象
parser = argparse.ArgumentParser()
# 向解析对象中添加命令行参数和选项
# epoch = 200,批大小 = 64,学习率 = 0.0002,衰减率 = 0.5/0.999,线程数 = 8,隐码维数 = 100,样本尺寸 = 28 * 28,通道数 = 1,样本间隔 = 400
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
# 解析参数
opt = parser.parse_args()
print(opt)
- 创建生成器G
#-------------------------
# 生成器
#-------------------------
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
# 这里简单的只对输入数据做线性转换
layers = [nn.Linear(in_feat, out_feat)]
# 使用BN
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
# 添加LeakyReLU非线性激活层
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
# 创建生成器网络模型
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
# 前向
def forward(self, z):
# 生成假样本
img = self.model(z)
img = img.view(img.size(0), *img_shape)
# 返回生成图像
return img
- 创建判别器D
#-------------------------
# 判别器
#-------------------------
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
# 因需判别真假,这里使用Sigmoid函数给出标量的判别结果
nn.Sigmoid(),
)
# 判别
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
# 判别结果
return validity
- 损失函数和优化器
# 损失函数:二分类交叉熵函数
adversarial_loss = torch.nn.BCELoss()
# 优化器,G和D都使用Adam
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
- 加载数据集
os.makedirs("../../data/mnist", exist_ok=True)
#------------------------------------------
# torch.utils.data.DataLoader
#------------------------------------------
# 数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化
#
#torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
# batch_sampler=None, num_workers=0, collate_fn=,
# pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)
# dataset:加载数据的数据集
# batch_size:每批次加载的数据量
# shuffle:默认false,若为True,表示在每个epoch打乱数据
# sampler:定义从数据集中绘制示例的策略,如果指定,shuffle必须为False
# ...
# 更多可参考: https://pytorch.org/docs/stable/data.html
# 设置数据加载器,这里使用MNIST数据集
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
- 训练模型
#-----------------------
# 训练模型
#-----------------------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
#
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# 输入
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# 训练 G
# -----------------
optimizer_G.zero_grad()
# 采样随机噪声向量
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# 训练得到一批次生成样本
gen_imgs = generator(z)
# 计算G的损失函数值
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
# 更新G
g_loss.backward()
optimizer_G.step()
# ---------------------
# 训练 D
# ---------------------
optimizer_D.zero_grad()
# 评估D的判别能力
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
# 更新D
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
#保存结果
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
实验结果
因为只有一块1080Ti,所以这里设置epoch = 50 跑了一下实现,结果如下所示:


