Elasticsearch 学习笔记
基础概念
索引(
Index)
一个索引就是含有某些相似特性的文档的集合。例如,你可以有一个用户数据的索引,一个产品目录的索引,还有其他的有规则数据的索引。一个索引被一个名称(必须都是小写)唯一标识,并且这个名称被用于索引通过文档去执行索引,搜索,更新和删除操作。
在一个集群中,你可以根据自己的需求定义任意多的索引。
索引对应数据库中的库类型(
Type)
一个类型是你的索引中的一个分类或者说是一个分区,它可以让你在同一索引中存储不同类型的文档,例如,为用户建一个类型,为博客文章建另一个类型。现在已不可能在同一个索引中创建多个类型,并且整个类型的概念将会在未来的版本中移除。查看“映射类型的移除”了解更多。
类型对应数据库中的表
在6.0.0版本中已经不赞成使用文档(
Document)
一个文档是一个可被索引的数据的基础单元。例如,你可以给一个单独的用户创建一个文档,给单个产品创建一个文档,以及其他的单独的规则。这个文档用JSON格式表现,JSON是一种普遍的网络数据交换格式。
在一个索引或类型中,你可以根据自己的需求存储任意多的文档。注意,虽然一个文档在物理存储上属于一个索引,但是文档实际上必须指定一个在索引中的类型。
文档对应数据库中的数据
参考 https://segmentfault.com/a/1190000012612097
| 关系型数据库 | Elasticsearch |
|---|---|
数据库 Database |
索引 Index,支持全文检索 |
表 Table |
类型 Type |
数据行 Row |
文档 Document,但不需要固定结构,不同文档可以具有不同字段集合 |
数据列 Column |
字段 Field |
模式 Schema |
映像 Mapping |
检索分类思维导图
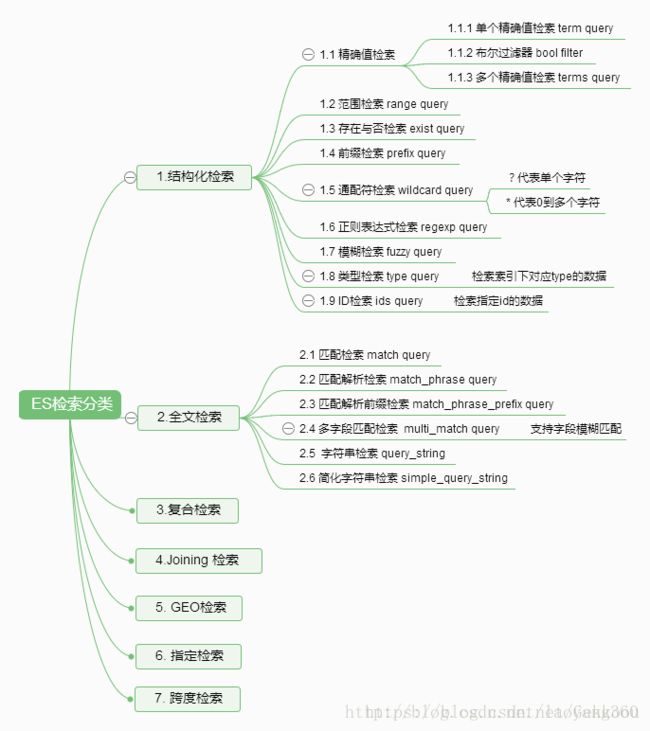
图片来源: https://blog.csdn.net/laoyang360/article/details/77623013
Mapping 小实践
创建索引 test 和定义 mapping
mapping 创建后不能修改
ES5.X版本以后, keyword 支持的最大长度为 32766 个UTF-8字符, text 对字符长度没有限制
设置 ignore_above 后, 超过给定长度后的数据将不被索引, 无法通过 term 精确匹配检索返回结果
Mapping详解: https://blog.csdn.net/napoay/article/details/73100110
# PUT /test
{
"settings":{
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"my_type": {
"properties": {
"id": {
"type": "integer"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"message": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"author": {
"type": "keyword",
"ignore_above": 256
},
"ip": {
"type": "ip"
},
"url": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 2048
}
}
},
"time": {
"type": "integer"
},
"rank": {
"type": "short"
},
"status": {
"type": "byte"
}
}
}
}
}索引字段类型 Numeric datatypes
| 类型 | 范围 |
|---|---|
| long | -2^63 ~ 2^63-1 |
| integer | -2^31 ~ 2^31-1 |
| short | -32768 ~ 32767 |
| byte | -128 ~ 127 |
| double | 双精度 64-bit IEEE 754 浮点数 |
| float | 单精度 32-bit IEEE 754 浮点数 |
byte => tinyint
short => smallint
int => integer
keyword不分词, 需要分词用text
索引迁移 (备份)
# 本地迁移 (备份)
POST /_reindex
{
"source": {
"index": "my_index"
},
"dest": {
"index": "my_index_1"
}
}
# 远程迁移 (备份)
POST /_reindex
{
"source": {
"remote": {
"host": "http://10.10.10.102:9200",
"socket_timeout": "30s",
"connect_timeout": "30s"
},
"index": "my_index",
"size": 1000,
"query": {}
},
"dest": {
"index": "my_index"
}
}
参数解释
source:{
host:源es的ip与端口
socket_timeout:读取超时时间
connect_timeout:连接超时时间
index:源索引名字
size:批量抓取的size大小
(从远程服务器重新编译使用默认最大大小为100MB的堆缓冲区, 如果远程索引包含非常大的文档, 则需要使用较小的批量)
query:查询指定条件下的字段
}检索匹配
深入搜索 (官方): https://www.elastic.co/guide/cn/elasticsearch/guide/current/search-in-depth.html
检索分类深入详解: https://blog.csdn.net/laoyang360/article/details/77623013
must – 所有的语句都 必须(must)匹配,与 AND 等价
must_not – 所有的语句都 不能(must not)匹配, 与 NOT 等价
should – 至少有一个语句要匹配, 与 OR 等价
filter – 必须匹配, 运行在非评分&过滤模式
创建 PUT
修改 POST
删除 DELETE
获取 GET
{
"bool": {
"must": [],
"should": [],
"must_not": [],
"filter": []
}
}
例子:
GET /my_index/my_type/_search
{
"query": {
"bool": {
"must": {
"match": {
"text": "哈哈 测试"
}
}
}
},
"from": 0,
"size": 10,
"_source": ["title", "publish_date", "publisher"],
"sort": [{
"publish_date": {
"order": "desc"
}
},
{
"title": {
"order": "desc"
}
}
]
}# filter 过滤查询不会计算相关度(直接跳过了整个评分阶段), 而且很容易被缓存, 所以速度快一些
GET /my_index/my_type/_search
{
"query": {
"bool": {
"must" : {
"multi_match": {
"query": "elasticsearch",
"fields": ["title","summary"]
}
},
"filter": {
"term": {
"title": "123AAA"
}
}
}
}
}
# 使用 constant_score 查询以非评分模式来执行 term 查询并以一作为统一评分
GET /my_index/my_type/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"price": 20
}
}
}
}
}1. 全文检索
# 全文检索 匹配多个字段 (title 和 test 字段)
GET /my_index/my_type/_search
{
"query": {
"multi_match": {
"query": "Quick brown fox",
"fields": [ "title", "text" ]
}
}
}# 全文检索 匹配分词 (匹配123或AAA)
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": "123AAA",
}
}
}# 全文检索 匹配短语 (匹配123 AAA 或 123 BBB AAA))
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": "123 AAA",
}
}
}
{
"query": {
"multi_match" : {
"query": "search engine",
"fields": ["title", "summary"],
"type": "phrase",
"slop": 3 #偏离值(slop value), 该值指示在仍然考虑文档匹配的情况下词与词之间的偏离值
}
}
}# 全文检索 语法查询 (匹配 (123和AAA)或BBB )
GET /my_index/my_type/_search
{
"query": {
"query_string": {
"query": "(123 AND AAA) OR BBB",
}
}
}# 全文检索 全文搜索
GET /my_index/my_type/_search
{
"query": {
"multi_match" : {
"query" : "guide",
"fields" : ["_all"]
}
}
}2. 结构化检索
# 结构化检索 精确查询 (匹配title等于123AAA)
GET /my_index/my_type/_search
{
"query": {
"term": {
"title": "123AAA"
}
}
}
{
"query": {
"range": {
"age": {
"get": 10,
"lte": 20
}
}
}
}# 结构化检索 通配符查询
*, 它匹配任何字符序列(包括空字符序列)
?, 它匹配任何单个字符
GET /my_index/my_type/_search
{
"query": {
"wildcard": {
"user": "ki*y"
}
}
}# 结构化检索 类型查询 (type为text的全部信息)
GET /my_index/my_type/_search
{
"query": {
"type": {
"value": "text"
}
}
}# 结构化检索 Ids查询 (返回指定id的全部信息)
GET /my_index/my_type/_search
{
"query": {
"ids": {
"type": "xext",
"values": ["2", "4", "100"]
}
}
}# 结构化检索 正则搜索
GET /my_index/my_type/_search
{
"query": {
"regexp" : {
"authors" : "t[a-z]*y"
}
}
}