【大数据入门笔记系列】第五节 SpringBoot集成hadoop开发环境(复杂版的WordCount)
【大数据入门笔记系列】第五节 SpringBoot集成hadoop开发环境(复杂版的WordCount)
- 前言
- 环境清单
- 创建SpringBoot项目
- 创建包
- 创建yml
- 添加集群主机名映射
- hadoop配置文件
- 环境变量HADOOP_HOME
- 编写代码
- 添加hadoop依赖jar包
- 编译项目
- 造数据
- IDEA远程提交MapReduce任务
- 后记
- 跳转
前言
本来是想直接扒一扒MapReduce的工作原理,但是觉得只是图解或者文字描述,没有Demo的运行体验总是无趣的,一遍走下来也没有什么成就感,因此还是要撸一撸代码的。
那么谈到MapReduce的工作原理,我们的Demo首选自然是WordCount,WordCount是很优秀的讲解MapReduce的案例,也是理解MapReduce的最好的方法,本节我们的目标只是将环境搭建起来,然后运行成功(不必纠结一些细节,因为开发习惯和为后面的Demo做准备的想法,一些类与文件的创建我是按模板来安排的,最好不要在没有搞懂原理的时候停下来死扣代码,此时运行成功就是成功!)。
环境清单
- 开发工具使用IDEA(Eclipse也行);
- 使用Jdk1.8;
- 需要maven环境;
- 需要IDEA提前装好SpringBoot插件(因为诸如kafka、elasticsearch、flink、spark等一大批大数据应用组件,SpringBoot都提供了良好的集成环境,所以不要嫌麻烦就用Maven,动动手顺便把SpringBoot也入门了岂不美滋滋?以后你再有什么demo直接就在这个项目里面干了,所以这个插件没装的可以装一下,网上教程一搜一大把);
- 需要一个Hadoop集群(既然决定学习大数据,搭集群这个过程不可避免,如果你的机器性能扛得住的话,可以装CDH,根据【Centos7.6安装CDH6.1.0】第一节 基础环境准备(host域名及免密登录)相关章节介绍一步一步跟着做相应操作就好,如安装遇到问题则可下方留言);
创建SpringBoot项目
首先,我们用IDEA(Eclipse也可以)创建一个普通的maven项目(groupId为com.jackroy.www,artifactId为BigData),然后我们将这个普通的Maven项目变成SpringBoot项目(需要提前准备好SpringBoot插件),转变的方法很简单,以下是我的pom.xml(注意,有个位置需要自己动手改一下hadoop依赖版本,查看自己hadoop的版本后,替换版本号):
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.jackroy.wwwgroupId>
<artifactId>BigDataartifactId>
<version>1.0-SNAPSHOTversion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.0.5.RELEASEversion>
parent>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<java.version>1.8java.version>
<fastjson.version>1.2.49fastjson.version>
<springboot.version>2.0.5.RELEASEspringboot.version>
<hadoop.version>3.0.0hadoop.version>
<skipTests>trueskipTests>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<version>${springboot.version}version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<version>${springboot.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>${hadoop.version}version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12artifactId>
<groupId>org.slf4jgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>${hadoop.version}version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12artifactId>
<groupId>org.slf4jgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-commonartifactId>
<version>${hadoop.version}version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12artifactId>
<groupId>org.slf4jgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-jobclientartifactId>
<version>${hadoop.version}version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12artifactId>
<groupId>org.slf4jgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>${hadoop.version}version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12artifactId>
<groupId>org.slf4jgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>com.janeluogroupId>
<artifactId>ikanalyzerartifactId>
<version>2012_u6version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
dependencies>
<build>
<finalName>BigData-1.0finalName>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<skip>trueskip>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-jar-pluginartifactId>
<version>2.5version>
plugin>
plugins>
build>
project>
创建包
在java下创建包com.jackroy.www、com.jackroy.www.Controller、com.jackroy.www.Service、com.jackroy.www.ServiceImpl和com.jackroy.www.Utils,顺便根目录下创建一个logs文件夹,结构like this:

创建yml
待依赖导入后,在我们的main目录下会多一个resources文件夹,在这个文件夹下分别创建application.yml、application-dev.yml(我们的相关配置写在这个yml里面)、application-test.yml、application-prod.yml四个文件,其中,application.yml写入:
# application-dev.yml里面放的是开发环境配置
# application-test.yml里面放的是测试环境配置
# application-prod.yml里面放的是生产环境配置
spring:
profiles:
active: dev
# 上面的dev的意思是dev这个开发环境配置文件生效,同理可以切换为test测试环境或者prod生产环境
在application-dev.yml写入:
server:
port: 8080
hdfs:
# 用NameNode节点IP,你的端口可能是9000
path: hdfs://172.20.22.11:8020/
# 用ResourceManager节点IP
ip: 172.20.22.11
logging:
file: logs/hadoop-demo.log
level:
com.example.demo.mapper: debug
com.jackroy.www: ERROR
learning: trace
log4j:
rootLogger: WARN
添加集群主机名映射
将集群的主机名映射添加到wind本地的hosts文件中,like this:

这一步一定要做,不然会运行会报错(除非你的配置文件里面用的全是IP,没有主机名掺杂在里面)。
hadoop配置文件
从生产集群上将core-site.xml、mapred-site.xml、yarn-site.xml这三个文件拷下来,放到resources文件夹下,与yml文件放在一起,like this:
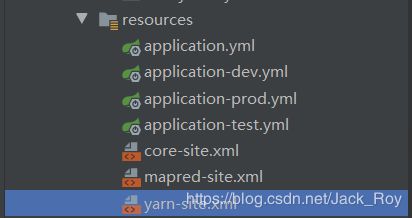
以上操作是为了解决报错Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster。
环境变量HADOOP_HOME
先从git上把hadoop组件工程包配置下载下来,然后打开你会看到多个版本的hadoop组件包,like this:

去看看自己的hadoop版本(像我的就是3.0.0的),就把相应版本的组件的内容拷出来,放在D盘下,然后配置环境变量HADOOP_HOME=D:\hadoop-3.0.0,like this:

将HADOOP_HOME加入PATH,like this:
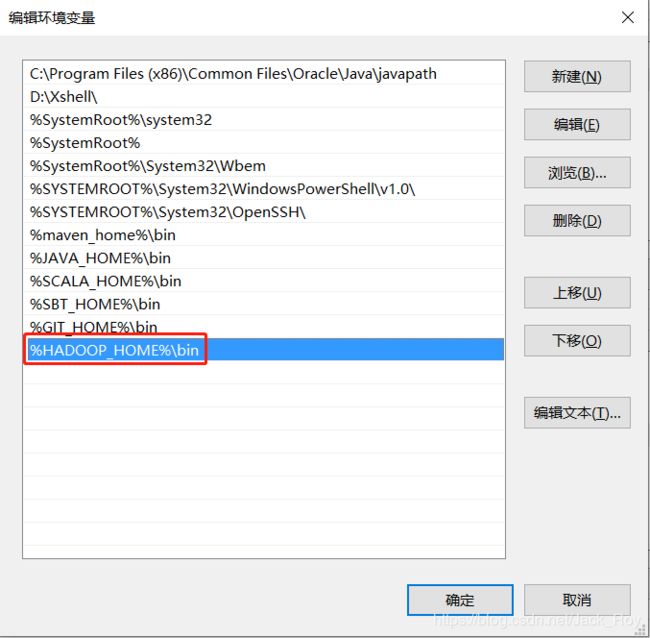
然后重启IDEA,不然环境变量不生效! 以上准备妥当之后,开始撸代码。
编写代码
在com.jackroy.www下面创建Application.java:
package com.jackroy.www;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.builder.SpringApplicationBuilder;
import org.springframework.boot.web.servlet.support.SpringBootServletInitializer;
@SpringBootApplication
public class Application extends SpringBootServletInitializer {
protected SpringApplicationBuilder configure(SpringApplicationBuilder application) {
return application.sources(Application.class);
}
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
在com.jackroy.www.ServiceImpl包下创建类WordCountMap.java继承Mapper并实现map方法:
package com.jackroy.www.ServiceImpl;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
public class WordCountMap extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable intWritable = new IntWritable(1);
private Text text = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = new String(value.getBytes(), 0, value.getLength(), "UTF-8").trim();
if (StringUtils.isNotEmpty(line)) {
byte[] btValue = line.getBytes();
InputStream inputStream = new ByteArrayInputStream(btValue);
Reader reader = new InputStreamReader(inputStream);
IKSegmenter ikSegmenter = new IKSegmenter(reader, true);
Lexeme lexeme;
while ((lexeme = ikSegmenter.next()) != null) {
text.set(lexeme.getLexemeText());
context.write(text, intWritable);
}
}
}
}
在com.jackroy.www.ServiceImpl包下创建类WordCountReduce.java继承Reducer并实现reduce方法:
package com.jackroy.www.ServiceImpl;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable intWritable = new IntWritable();
@Override
public void reduce(Text text, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable val : values) {
count += val.get();
}
intWritable.set(count);
context.write(text, intWritable);
}
}
在包com.jackroy.www.Utils下创建作业工具类JobUtils .java:
package com.jackroy.www.Utils;
import java.io.IOException;
import javax.annotation.PostConstruct;
import com.jackroy.www.Controller.WordCountController;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
@Component
public class JobUtils {
@Value("${hdfs.path}")
private String path;
@Value("${hdfs.ip}")
private String ip;
private static String hdfsPath;
private static String host;
public static Configuration getConfiguration() {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", hdfsPath);
configuration.set("mapred.job.tracker", hdfsPath);
configuration.set("mapreduce.framework.name", "yarn");
configuration.set("yarn.resourcemanmager.hostname", host);
configuration.set("yarn.resourcemanager.address", host+":8032");
configuration.set("yarn.resourcemanager.scheduler.address", host+":8030");
configuration.set("mapreduce.app-submission.cross-platform", "true");
return configuration;
}
public static void getWordCountJobsConf(String jobName, String inputPath, String outputPath)
throws IOException, ClassNotFoundException, InterruptedException {
/* 获取hdfs配置 */
Configuration conf = getConfiguration();
Job job = Job.getInstance(conf, jobName);
job.setMapperClass(com.jackroy.www.ServiceImpl.WordCountMap.class);
job.setCombinerClass(com.jackroy.www.ServiceImpl.WordCountReduce.class);
job.setReducerClass(com.jackroy.www.ServiceImpl.WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.addFileToClassPath(new Path("/0000/lib/ikanalyzer-2012_u6.jar"));
job.setJar("D:\\project\\BigData\\target\\BigData-1.0.jar");
/* 小文件合并 */
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4 * 1024 * 1024);
CombineTextInputFormat.setMinInputSplitSize(job, 2 * 1024 * 1024);
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
job.waitForCompletion(true);
}
@PostConstruct
public void setHhdfsPath() {
hdfsPath = this.path;
}
public static String getHdfsPath() {
return hdfsPath;
}
@PostConstruct
public void setHost() {
host = this.ip;
}
public static String getHost() {
return host;
}
}
在com.jackroy.www.Service包下创建接口WordCountService.java:
package com.jackroy.www.Service;
public interface WordCountService {
public void wordCount(String jobName, String inputPath);
}
在com.jackroy.www.ServiceImpl包下创建类WordCountServiceImpl.java:
package com.jackroy.www.ServiceImpl;
import com.jackroy.www.Utils.JobUtils;
import com.jackroy.www.Service.WordCountService;
import org.apache.commons.lang.StringUtils;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
@Service
public class WordCountServiceImpl implements WordCountService {
SimpleDateFormat df = new SimpleDateFormat("yyyy_MM_dd_HH_mm_ss");
String BATCH = df.format(new Date());
@Override
public void wordCount(String jobName, String inputPath) throws InterruptedException, IOException, ClassNotFoundException {
if (StringUtils.isEmpty(jobName) || StringUtils.isEmpty(inputPath)) {
return;
}
/* 存储路径 */
String outputPath = "/0000/" + jobName+"_"+BATCH;
JobUtils.getWordCountJobsConf(jobName, inputPath, outputPath);
}
}
最后,在com.jackroy.www.Controller包下编写类MapReduceController.java:
package com.jackroy.www.Controller;
import com.jackroy.www.Service.WordCountService;
import org.apache.commons.lang.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.*;
@Controller
@CrossOrigin
public class WordCountController {
@Autowired
WordCountService wordCountService;
@GetMapping("/WordCountController/wordCount")
@ResponseBody
public String wordCount(@RequestParam("jobName") String jobName, @RequestParam("inputPath") String inputPath) throws Exception {
String str="";
System.setProperty("HADOOP_USER_NAME", "deploy_man");
if (StringUtils.isEmpty(jobName) || StringUtils.isEmpty(inputPath)) {
return str="请输入作业名和文件路径";
}
wordCountService.wordCount(jobName, inputPath);
return "统计完成,请前去hdfs相关路径下查看";
}
}
整体工程结构like this:

添加hadoop依赖jar包
刚刚工具类的代码里:

这个分词器的jar看到了没有,需要提前上传到Hdfs的/0000/lib,路径没有的自行创建,linux上执行:
hadoop dfs -mkdir /0000/lib
然后在本地的maven仓库找到ikanalyzer-2012_u6.jarr包(耐心找肯定能找到,不会找百度一下怎么找,我这里就不赘述了),先将其上传到linux上,然后执行:
hadoop dfs -put ikanalyzer-2012_u6.jar /0000/lib
然后我们代码里那样调用,MapReduceApplication就能找到依赖了,现在别急着运行,我们还有最后一步。
以上步骤是为了解决报错Error: java.lang.ClassNotFoundException: org.wltea.analyzer.core.IKSegmenter。
编译项目
之所以编译项目,是要将相关的类作为依赖,一同上传至集群中,因为我们在JobUtils写了:

IDEA编译打包,过程不会的可以百度,然后将这个jar包路径替换一下即可。
以上步骤是为了解决报错ClassNotFoundException: Class com.jackroy.www.ServiceImpl.WordCountMap not found。
造数据
这个数据就写在test.txt里面好了,我随便找了一段英文,作为伪数据,:
AA: I'm Avi Arditti with Rosanne Skirble, and this week on Wordmaster: counting words.
RS: If you wanted to show people the 88,000 most common words in English, how would you do it? Jonathan Harris thought of a sentence -- or something that looks like one. He works on interactive art projects. He laid out the words in a straight line, from the most frequently used to the least frequently used.
AA: This is all on a Web site, so you keep clicking to the right to read the words on the screen. Or you can look up specific words to see their ranking. There's also a visual trick that displays the words as a graph. The most common are in really big type; the least common are in really small type.
RS: Jonathan Harris is an artist in the field of "information visualization." What he created is wordcount-dot-org.
JONATHAN HARRIS: "The experience I was trying to create for the user was like an archeologist sort of sifting through sand. And you never really get a look at the whole language at any one time. You really have to zero in one specific part and explore there. And in this sense you can really spend hours just killing time on this and playing around."RS: "You say it's like one very long sentence, but is there anything connecting these words?"JONATHAN HARRIS: "That's what's really interesting, and this is the one aspect of WordCount that people have really gravitated toward, as I've found. Because the data is essentially random -- I mean, it's not random, but the fact that a given word is next to another word is only based on how often those words appear in normal English usage. But when you have 88,000 words placed back to back, chances are pretty good that a few of those sequences are going to form some pretty conspiratorial meanings.
"Every morning I sort of come into work and I check my e-mail and I have a pile of e-mails waiting for me from people all around the globe that have found interesting sequences in WordCount. Some of my favorites are words 992 to 995 are 'American ensure oil opportunity.' Then 4304 to 4307 is 'Microsoft acquire salary tremendous.'"AA: "I like this one, 5283 to 5285, which is 'angel seeks supper.'"JONATHAN HARRIS: "Exactly. I found that a lot of people suggest that this be used as a good device for people trying to come up with a name for their band."RS: "How is it determined, the frequency of any given word?"JONATHAN HARRIS: "The frequency is data that is not generated by me. The frequency data was all coming from this source data that I used, which is the British National Corpus and that's a collection of written and spoken English words that were collected over a few years, I think back in the mid-1990s, by this group in England. It's a little bit dated; I've found one word that people are often surprised does not appear at all in the archive is blog. So clearly the phenomenon of Web logging came up after this data was collected."AA: "So now you describe this basically as an 88,000-word-long sentence, starting with the word 'the,' the most frequently used word in the English language. What's at the other end?"JONATHAN HARRIS: "The other end is surprising, and this is a big point of contention for a lot of people that actually find what the last word is. But the last word, surprisingly or not, is conquistador. And if you look through the list and you spend some time with it, you'll find that there are many words much, much further in front of conquistador that you've never even heard of. So clearly there seems to be some errata in their data."AA: "So conquistador, as in a Spanish conqueror?"JONATHAN HARRIS: "Some other interesting sort of comparative rankings: war is 304 and peace is 1,155. Love beats hate, Coke beats Pepsi and love beats sex by over 1,000."AA: "Now this is according to British usage from a few years ago, right?"JONATHAN HARRIS: "That's right, so maybe this has all changed since then. WordCount went online about five months ago, and almost nobody saw it for about four months. And then back at the beginning of July a friend of mine posted it on his blog and within about a day or two days, the site was getting about 20,000 unique visitors a day.
"And I was getting e-mails from all over the world, mainly people taking issue with some of the apparent disparities in the data, how some seemingly obscure words were being placed ahead of seemingly more common ones, but other people that were just sort of touched by how fun it was. And people, you know, found these little comparisons entertaining, like the Coke and Pepsi, and the love and the hate, and the war and the peace. Things like this."RS: Jonathan Harris, talking to us from Fabrica, a creative think tank for young artists where he has a year-long fellowship. It located near Venice, Italy, and it's where he developed wordcount dot o-r-g.
AA: And that's all for this week. Our e-mail address is [email protected]. And our Web site is voanews.com/wordmaster. With Rosanne Skirble.
创建一个文件夹用来放数据:
hadoop dfs -mkdir /0000/00001
先将其上传到linux上,然后执行:
hadoop dfs -put test.txt /0000/00001
准备妥当:

IDEA远程提交MapReduce任务
IDEA直接启动任务,然后我们用PostMan的get请求如下地址(浏览器回车也可以):
http://localhost:8080/WordCountController/wordCount?jobName=jack_roy_word_count&inputPath=/0000/00001
静待运行完成:
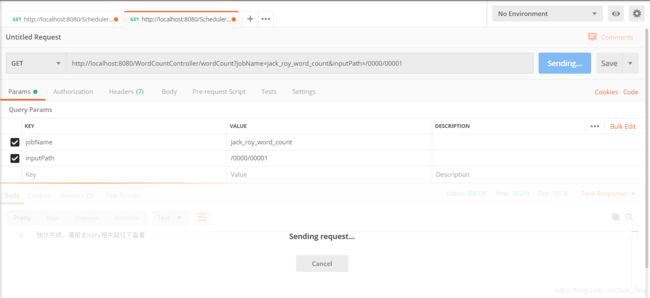
控制台输出效果:

去输出路径下看看输出:

随便找一个输出文件打开看看:

我们看到相关词频率统计成功。
后记
WordCount体验成功后,我们再有针对地进行讲解MapReduce工作原理,本节比较容易踩坑,如遇问题可下方留言交流,希望能帮到你。
跳转
【大数据入门笔记系列】写在前面
【大数据入门笔记系列】第一节 大数据常用组件
【大数据入门笔记系列】第二节 Zookeeper简介
【大数据入门笔记系列】第三节 Hdfs读、写数据处理流程
【大数据入门笔记系列】第四节 NameNode元数据缓存机制
【大数据入门笔记系列】第五节 SpringBoot集成hadoop开发环境(复杂版的WordCount)