Java培优班 - 第二十天、第二十一天 - JavaWeb - Part 1: 课程 - MySQL(理论常识 + 增删查改 + 数据类型 + 备份/恢复 ) -(较全)
文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
- 10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
- 11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
- 12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
- 13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
- 14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
- 1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
- 代码 - 创建db10数据库
- 1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
- SELECT 语句用于从表中选取数据。
- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
- 16.查询emp表中的所有部门和职位
- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
- 1.5.2 WHERE子句查询
- -- 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资
- -- 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
- ∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
- ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
- 19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
- 20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
- 21.查询薪资不为1400、1600、1800的员工
- 22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
- 23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
- 处理null值
- 24. 查询没有部门的员工(即部门列为null值)
- 思考:如何查询有部门的员工(即部门列不为null值)
- 1.5.3 模糊查询 - like
- 25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
- 26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
- 1.5.4 多行函数查询
- 28.统计emp表中薪资大于3000的员工个数)
- 29.求emp表中的最高(低)薪资
- 30.统计emp表中所有员工的薪资总和(不包含奖金)
- 31.统计emp表员工的平均薪资(不包含奖金)
- 平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
- 1.5.5分组查询
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- ∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
- 1.5.6 排序查询
- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
- 36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
- 1.5.7 分页查询
- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
- 1.5.8其他函数
- 39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
- 40.查询emp表中本月过生日的所有员工
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 1.6 mysql的数据类型
- 1.6.1 数值类型
- 1.6.2 字符串类型
- 1.6.3 日期类型
- 1.7 mysql的字段约束
- 1.7.1 主键约束
- 1.7.2 非空约束
- 1.7.3 唯一约束
- ∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
- 1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗
- 外键演示
- 1.8 表关系
- 1.9多表查询
- 1.9.1连接查询
- 42.查询部门和部门对应的员工信息
- ∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
- 1.9.2 左外连接查询
- 43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
- 1.9.3右外连接查询
- 44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
- 1.9.4 子查询
- 45.列出薪资比'王海涛'薪资高的所有员工,显示姓名、薪资
- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
- 1.9.5 多表查询练习
- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号, 显示部门名称,员工名称。
- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
- ∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
- 1.10 ∗ ∗ 数 据 库 备 份 与 恢 复 ∗ ∗ \color{#ff0011}{ ** 数据库备份与恢复 ** } ∗∗数据库备份与恢复∗∗
- 1.10.1备份数据库
- 1.10.2恢复数据库
- 1.11 扩 展 内 容 \color{#ff0011}{扩展内容} 扩展内容
- 1.11.1修改表—新增列
- 1.11.2 修改表—修改列
- 1.11.3 修改表—删除列
- 1.11.4添加或删除主键及自增
- 1.11.5添加或删除外键约束
- 1.11.6删除外键约束
- 1.11.7where中不能使用列别名
- ∗ ∗ S Q L 语 句 的 书 写 顺 序 ∗ ∗ : \color{#ff0011}{**SQL语句的书写顺序**:} ∗∗SQL语句的书写顺序∗∗:
- ∗ ∗ S Q L 语 句 的 执 行 顺 序 : ∗ ∗ : \color{#ff0011}{**SQL语句的执行顺序:**:} ∗∗SQL语句的执行顺序:∗∗:
- ** 关于where中不能使用列别名但是可以使用表别名?
- 命令
select dept , count(*) as '部门人数' , max(sal) from emp where not sal in(1800) and not sal=1400 group by dept order by sal desc ;
delete from t where ...;
select ... from t where ...;
update t set ... where ... ;
insert into t value()/values(),()... ;
- 多表
显示的列:
查询的表:
关联条件:
筛选条件:
1.1数据库概述
1.1.1什么是数据库?
数据库:英文为Database,简称DB
数据库是按照数据结构来组织、存储和管理数据的仓库,
简而言之,数据库就是存储数据的仓库。
数据库是一个专业存储和管理数据的软件系统,相比传统人工记录数据和直接使用文件保存数据,数据库具有更安全、更可靠、效率更高的优势。
扩展内容1:数据库有哪些分类?(了解)
- 早期:层次式数据库、网络型数据库(已过时)
- 现在: 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库、非关系型数据库
1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
底层以二维表的形式保存数据的数据库,就是关系型数据库,例如:下面有一个学生表。
| 编号 | 姓名 | 年龄 |
|---|---|---|
| 1 | 张三 | 20 |
| 2 | 李四 | 22 |
扩展内容2:常见的关系型数据库有哪些?(了解)
- SQL Server:微软提供,适用于中型、大型项目,收费,在java中的使用占比不高,在.NET语言中使用较多。
- Oracle:甲骨文公司提供,适用于大型、超大型项目,功能强大,性能优异,收费,在Java中使用占比很高。
- mysql:瑞典MySQLAB公司提供,适用于小型、中型项目,免费开源,小巧轻量,性能也不差。在Java中使用占比较高。
- DB2:IBM公司提供,适用于大型项目,收费,在Java中使用占比不高。
- Sqlite:迷你,嵌入式设备,智能家居,手机,ipad等
扩展内容3:什么是非关系型数据库?(了解)
非关系数据库的底层结构是以Key-Value、列等结构存储数据的
常见的非关系型数据库有:redis、mongodb
1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
-
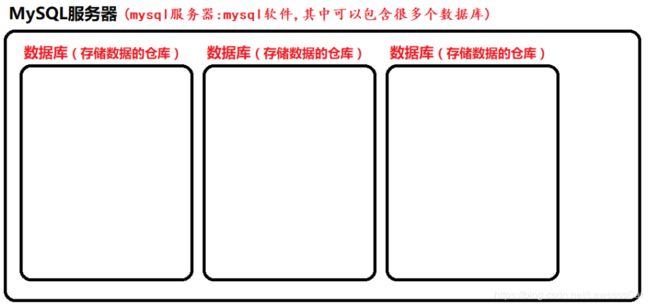
什么是数据库服务器
服务器软件,mysql 软件,将服务器软件装在电脑上,就可以作为一台服务器对外提供服务器。
(存取数据) -
什么是数据库
在每一个数据库服务器中,可以有很多个仓库(数据库),通常情况下,一个网站中的所有数据会存放在一个数据库中。
京东 db_jd数据库
百度 db_baidu数据库
淘宝 db_taobao数据库
…
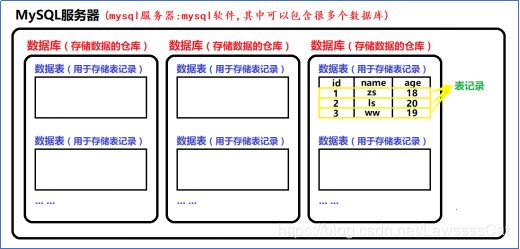
- 什么是表
一个数据库中可以创建多张表,而一张表用于存放一类信息。
(Java中的类对应数据库中的表)
商品信息 tb_product表
购物车信息 tb_cart表
用户信息 tb_user表
订单信息 tb_order表
…

- 什么表记录
一张表中可以包含多条表记录,一个表记录用于存放某一条具体的信息
1.1.4 1.1.4什么是SQL语言?
SQL:(Structured Query Language) 结构化查询语言
SQL是一种ANSI(美国国家标准化组织) 的标准计算机语言,用于访问和操作数据库。
SQL是用于操作关系型数据库的通用的语言,即通过SQL语言可以操作所有的关系型数据库。
SQL语言可以用于:
- 操作数据库(创建、删除、查看)、
- 操作数据表(创建、删除、修改、查看)、
- 操作表记录(新增、更新、删除、查询)等。
文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
- 10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
- 11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
- 12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
- 13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
- 14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
- 1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
- 代码 - 创建db10数据库
- 1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
- SELECT 语句用于从表中选取数据。
- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
- 16.查询emp表中的所有部门和职位
- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
- 1.5.2 WHERE子句查询
- -- 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资
- -- 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
- ∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
- ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
- 19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
- 20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
- 21.查询薪资不为1400、1600、1800的员工
- 22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
- 23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
- 处理null值
- 24. 查询没有部门的员工(即部门列为null值)
- 思考:如何查询有部门的员工(即部门列不为null值)
- 1.5.3 模糊查询 - like
- 25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
- 26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
- 1.5.4 多行函数查询
- 28.统计emp表中薪资大于3000的员工个数)
- 29.求emp表中的最高(低)薪资
- 30.统计emp表中所有员工的薪资总和(不包含奖金)
- 31.统计emp表员工的平均薪资(不包含奖金)
- 平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
- 1.5.5分组查询
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- ∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
- 1.5.6 排序查询
- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
- 36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
- 1.5.7 分页查询
- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
- 1.5.8其他函数
- 39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
- 40.查询emp表中本月过生日的所有员工
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 1.6 mysql的数据类型
- 1.6.1 数值类型
- 1.6.2 字符串类型
- 1.6.3 日期类型
- 1.7 mysql的字段约束
- 1.7.1 主键约束
- 1.7.2 非空约束
- 1.7.3 唯一约束
- ∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
- 1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗
- 外键演示
- 1.8 表关系
- 1.9多表查询
- 1.9.1连接查询
- 42.查询部门和部门对应的员工信息
- ∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
- 1.9.2 左外连接查询
- 43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
- 1.9.3右外连接查询
- 44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
- 1.9.4 子查询
- 45.列出薪资比'王海涛'薪资高的所有员工,显示姓名、薪资
- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
- 1.9.5 多表查询练习
- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号, 显示部门名称,员工名称。
- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
- ∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
- 1.10 ∗ ∗ 数 据 库 备 份 与 恢 复 ∗ ∗ \color{#ff0011}{ ** 数据库备份与恢复 ** } ∗∗数据库备份与恢复∗∗
- 1.10.1备份数据库
- 1.10.2恢复数据库
- 1.11 扩 展 内 容 \color{#ff0011}{扩展内容} 扩展内容
- 1.11.1修改表—新增列
- 1.11.2 修改表—修改列
- 1.11.3 修改表—删除列
- 1.11.4添加或删除主键及自增
- 1.11.5添加或删除外键约束
- 1.11.6删除外键约束
- 1.11.7where中不能使用列别名
- ∗ ∗ S Q L 语 句 的 书 写 顺 序 ∗ ∗ : \color{#ff0011}{**SQL语句的书写顺序**:} ∗∗SQL语句的书写顺序∗∗:
- ∗ ∗ S Q L 语 句 的 执 行 顺 序 : ∗ ∗ : \color{#ff0011}{**SQL语句的执行顺序:**:} ∗∗SQL语句的执行顺序:∗∗:
- ** 关于where中不能使用列别名但是可以使用表别名?
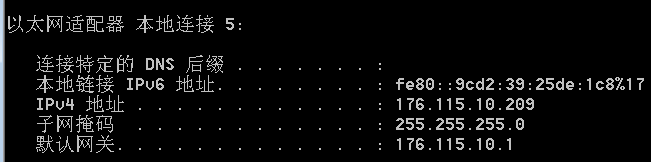
1.2连接mysql服务器
通过命令行工具可以登录MySQL客户端,连接MySQL服务器,从而访问服务器中的数据。
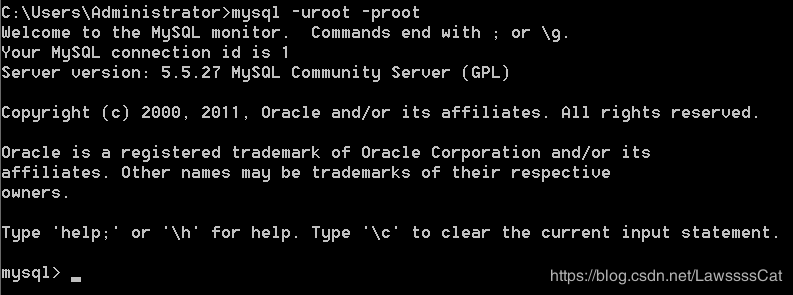
1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
mysql -uroot -proot
- -u:后面的root是用户名,这里使用的是超级管理员root;
- -p:(小写的p)后面的root是密码,这是在安装MySQL时就已经指定的密码;
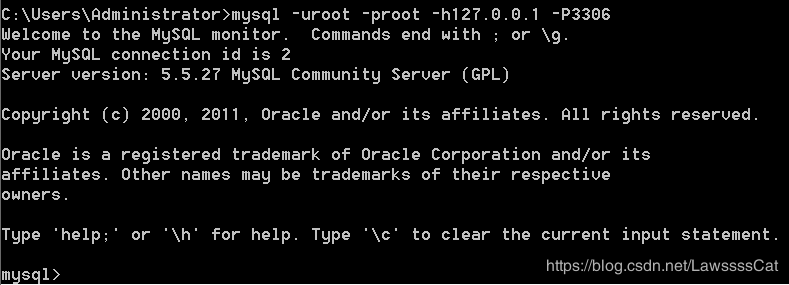
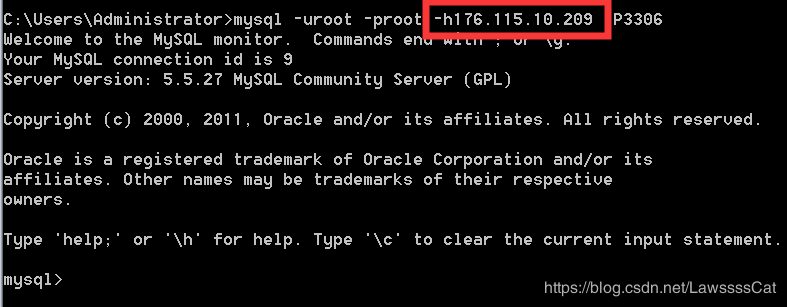
2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
mysql -uroot -proot -h127.0.0.1 -P3306
- -h:后面给出的127.0.0.1是服务器主机名或ip地址,可以省略的,默认连接本机;
- -P:(大写的P)后面的3306是连接端口,可以省略,默认连接3306端口;
Note:
- 局域网ip也可以,没有设置额外权限的话
3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- quit
- exit
- \q

- Ctrl + c
![]()
4、FAQ:常见问题:

解决方法:复制mysql安装目录下的bin目录,将bin目录的路径添加到path环境变量中!!
扩展内容4:
-
在cmd中连接mysql服务器之后,可以使用 #、/**/、-- 等符号添加注释
例如:

-
在cmd中连接mysql服务器之后,在书写SQL语句时,可以通过 \c 取消当前语句的执行。例如:加粗样式

文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
- 10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
- 11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
- 12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
- 13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
- 14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
- 1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
- 代码 - 创建db10数据库
- 1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
- SELECT 语句用于从表中选取数据。
- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
- 16.查询emp表中的所有部门和职位
- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
- 1.5.2 WHERE子句查询
- -- 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资
- -- 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
- ∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
- ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
- 19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
- 20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
- 21.查询薪资不为1400、1600、1800的员工
- 22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
- 23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
- 处理null值
- 24. 查询没有部门的员工(即部门列为null值)
- 思考:如何查询有部门的员工(即部门列不为null值)
- 1.5.3 模糊查询 - like
- 25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
- 26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
- 1.5.4 多行函数查询
- 28.统计emp表中薪资大于3000的员工个数)
- 29.求emp表中的最高(低)薪资
- 30.统计emp表中所有员工的薪资总和(不包含奖金)
- 31.统计emp表员工的平均薪资(不包含奖金)
- 平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
- 1.5.5分组查询
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- ∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
- 1.5.6 排序查询
- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
- 36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
- 1.5.7 分页查询
- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
- 1.5.8其他函数
- 39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
- 40.查询emp表中本月过生日的所有员工
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 1.6 mysql的数据类型
- 1.6.1 数值类型
- 1.6.2 字符串类型
- 1.6.3 日期类型
- 1.7 mysql的字段约束
- 1.7.1 主键约束
- 1.7.2 非空约束
- 1.7.3 唯一约束
- ∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
- 1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗
- 外键演示
- 1.8 表关系
- 1.9多表查询
- 1.9.1连接查询
- 42.查询部门和部门对应的员工信息
- ∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
- 1.9.2 左外连接查询
- 43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
- 1.9.3右外连接查询
- 44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
- 1.9.4 子查询
- 45.列出薪资比'王海涛'薪资高的所有员工,显示姓名、薪资
- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
- 1.9.5 多表查询练习
- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号, 显示部门名称,员工名称。
- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
- ∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
- 1.10 ∗ ∗ 数 据 库 备 份 与 恢 复 ∗ ∗ \color{#ff0011}{ ** 数据库备份与恢复 ** } ∗∗数据库备份与恢复∗∗
- 1.10.1备份数据库
- 1.10.2恢复数据库
- 1.11 扩 展 内 容 \color{#ff0011}{扩展内容} 扩展内容
- 1.11.1修改表—新增列
- 1.11.2 修改表—修改列
- 1.11.3 修改表—删除列
- 1.11.4添加或删除主键及自增
- 1.11.5添加或删除外键约束
- 1.11.6删除外键约束
- 1.11.7where中不能使用列别名
- ∗ ∗ S Q L 语 句 的 书 写 顺 序 ∗ ∗ : \color{#ff0011}{**SQL语句的书写顺序**:} ∗∗SQL语句的书写顺序∗∗:
- ∗ ∗ S Q L 语 句 的 执 行 顺 序 : ∗ ∗ : \color{#ff0011}{**SQL语句的执行顺序:**:} ∗∗SQL语句的执行顺序:∗∗:
- ** 关于where中不能使用列别名但是可以使用表别名?
1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
1.3.1 创建、删除、查看数据库
提示:
- SQL 语句对大小写不敏感。推荐关键字使用大写,自定义的名称(库名,表名,列名等)使用小写。
- 并且在自定义名称时,针对多个单词不要使用驼峰命名,而是使用下划线连接。(例如:tab_name,而不是 tabName)
1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
show databases ;
SHOW DATABASES ; #最好用大写
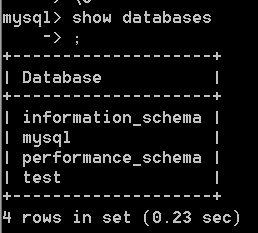
Note:
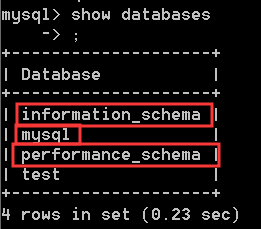
红 色 方 框 内 的 库 不 要 删 , 存 储 数 据 库 本 身 需 要 的 数 据 , 删 了 就 炸 了 \color{#ff0011}{红色方框内的库不要删,存储数据库本身需要的数据,删了就炸了} 红色方框内的库不要删,存储数据库本身需要的数据,删了就炸了
2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
(进入数据库后,才能操作库中的表和表记录)
USE test;
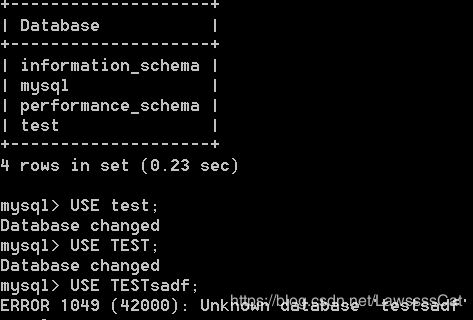
Note:
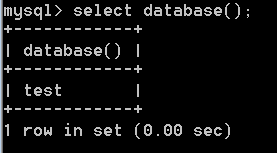
查看当前库
SELECT database();
03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
SHOW tables;
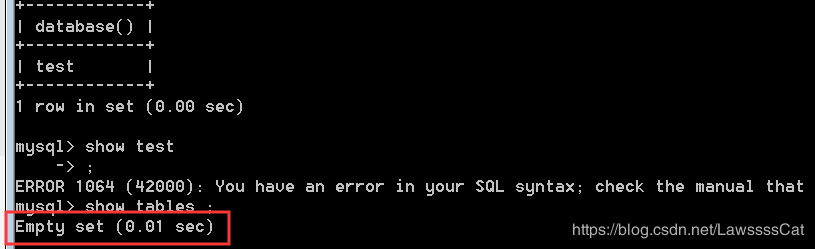
04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
DROP DATABASE IF EXISTS mydb1;

– 思考:当删除的表不存在时,如何避免错误产生?
05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
– 语法:CREATE DATABASE 库名 CHARSET 编码;
CREATE DATABASE mydb1 CHARSET utf8;
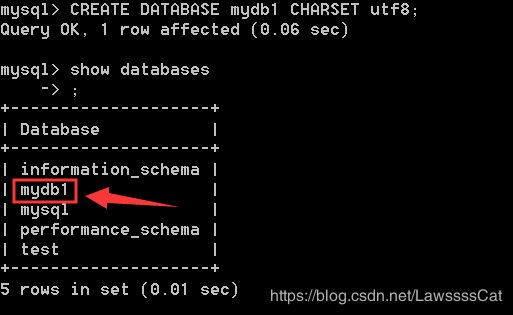
– 如果不存在则创建mydb1;
CREATE DATABASE IF NOT EXISTS mydb1 CHARSET utf8 ;

06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
– 语法:SHOW CREATE DATABASE 库名;
SHOW CREATE DATABASE mydb1 ;

1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
– 语法:DROP TABLE 表名;
USE mydb1 ;
DROP TABLE IF EXISTS stu;

08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
(
编号 [数值类型],
姓名,
性别,
出生年月,
考试成绩[浮点型]
),
建表的语法:
CREATE TABLE 表名(
列名 数据类型,
列名 数据类型,
…
);
CREATE TABLE stu(
id INT,
name VARCHAR(50),
gender VARCHAR(10),
birthday DATE,
score DOUBLE
);

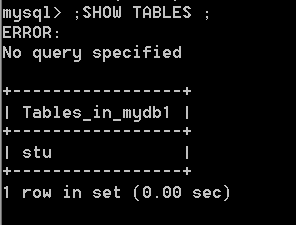
09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
– 语法:desc 表名
DESC stu;

查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
SHOW CREATE TABLE STU ; --查看建表时的语句

文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
- 10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
- 11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
- 12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
- 13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
- 14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
- 1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
- 代码 - 创建db10数据库
- 1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
- SELECT 语句用于从表中选取数据。
- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
- 16.查询emp表中的所有部门和职位
- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
- 1.5.2 WHERE子句查询
- -- 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资
- -- 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
- ∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
- ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
- 19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
- 20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
- 21.查询薪资不为1400、1600、1800的员工
- 22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
- 23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
- 处理null值
- 24. 查询没有部门的员工(即部门列为null值)
- 思考:如何查询有部门的员工(即部门列不为null值)
- 1.5.3 模糊查询 - like
- 25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
- 26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
- 1.5.4 多行函数查询
- 28.统计emp表中薪资大于3000的员工个数)
- 29.求emp表中的最高(低)薪资
- 30.统计emp表中所有员工的薪资总和(不包含奖金)
- 31.统计emp表员工的平均薪资(不包含奖金)
- 平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
- 1.5.5分组查询
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- ∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
- 1.5.6 排序查询
- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
- 36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
- 1.5.7 分页查询
- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
- 1.5.8其他函数
- 39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
- 40.查询emp表中本月过生日的所有员工
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 1.6 mysql的数据类型
- 1.6.1 数值类型
- 1.6.2 字符串类型
- 1.6.3 日期类型
- 1.7 mysql的字段约束
- 1.7.1 主键约束
- 1.7.2 非空约束
- 1.7.3 唯一约束
- ∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
- 1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗
- 外键演示
- 1.8 表关系
- 1.9多表查询
- 1.9.1连接查询
- 42.查询部门和部门对应的员工信息
- ∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
- 1.9.2 左外连接查询
- 43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
- 1.9.3右外连接查询
- 44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
- 1.9.4 子查询
- 45.列出薪资比'王海涛'薪资高的所有员工,显示姓名、薪资
- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
- 1.9.5 多表查询练习
- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号, 显示部门名称,员工名称。
- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
- ∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
- 1.10 ∗ ∗ 数 据 库 备 份 与 恢 复 ∗ ∗ \color{#ff0011}{ ** 数据库备份与恢复 ** } ∗∗数据库备份与恢复∗∗
- 1.10.1备份数据库
- 1.10.2恢复数据库
- 1.11 扩 展 内 容 \color{#ff0011}{扩展内容} 扩展内容
- 1.11.1修改表—新增列
- 1.11.2 修改表—修改列
- 1.11.3 修改表—删除列
- 1.11.4添加或删除主键及自增
- 1.11.5添加或删除外键约束
- 1.11.6删除外键约束
- 1.11.7where中不能使用列别名
- ∗ ∗ S Q L 语 句 的 书 写 顺 序 ∗ ∗ : \color{#ff0011}{**SQL语句的书写顺序**:} ∗∗SQL语句的书写顺序∗∗:
- ∗ ∗ S Q L 语 句 的 执 行 顺 序 : ∗ ∗ : \color{#ff0011}{**SQL语句的执行顺序:**:} ∗∗SQL语句的执行顺序:∗∗:
- ** 关于where中不能使用列别名但是可以使用表别名?
1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
要插入中文时,要设置编码,如 set name gbk;
![]()
语法:INSERT INTO 表名( 列名1,列名2,列名3… ) VALUES( 值1,值2,值3… );
INSERT INTO stu VALUE(
1, /*ID*/
'小明', /*姓名*/
'男',/*性别*/
'1988-11-29',/*出生年龄*/
85/*成绩*/
);
INSERT INTO stu VALUE(2,'刘沛霞','女','1988-12-18',76);
INSERT INTO stu VALUE(3,'霞','女','1999-12-22',30);
提示:
- 当为所有列插入值时,可以省写列名,但值的个数和顺序必须和声明时列的个数和顺序保持一致!
- SQL语句中的值为字符串或日期时,值的两边要加上单引号
(有的版本的数据库双引号也可以,但推荐使用单引号)。- 在插入数据之前,先设置编码设置编码:set names gbk;
或者用一下命令连接mysql服务器:
mysql --default-character-set=gbk -uroot -proot
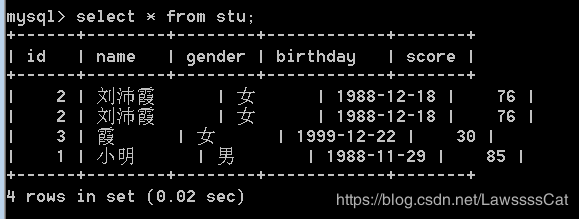
11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
– 语法:SELECT 列名 | * FROM 表名
SELECT * FROM stu;
12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
– 修改语法: UPDATE 表名 SET 列=值,列=值,列=值…[WHERE子句];
UPDATE stu SET score=score+10 ;
UPDATE stu SET score+=10 ; -- 语法错误,mysql不支持+=

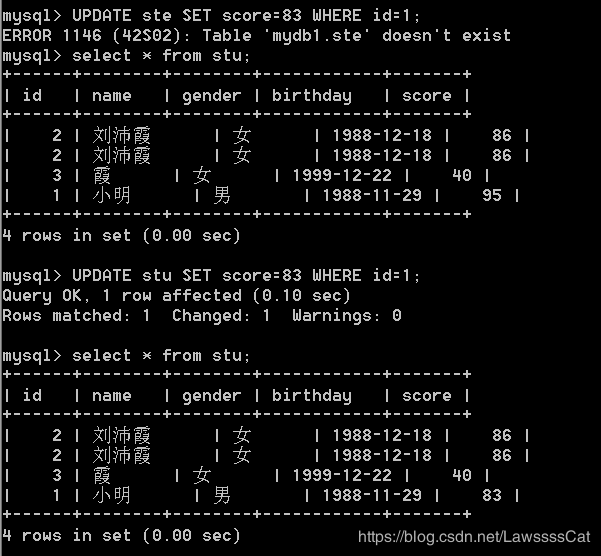
13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
UPDATE stu SET score=83 WHERE id=1;
提示:
where子句用于对记录进行筛选过滤,保留符合条件的记录,将不符合条件的记录剔除。
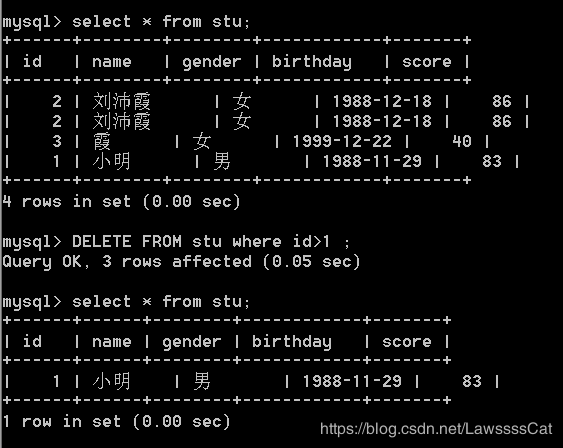
14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
– 仅删除符合条件的
DELETE FROM stu where id>1 ;
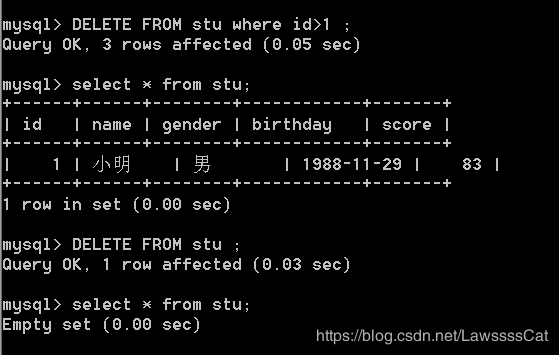
– 删除记录语法: DELETE FROM 表名 [where条件]
DELETE FROM stu ;
文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
- 10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
- 11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
- 12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
- 13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
- 14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
- 1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
- 代码 - 创建db10数据库
- 1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
- SELECT 语句用于从表中选取数据。
- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
- 16.查询emp表中的所有部门和职位
- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
- 1.5.2 WHERE子句查询
- -- 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资
- -- 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
- ∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
- ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
- 19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
- 20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
- 21.查询薪资不为1400、1600、1800的员工
- 22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
- 23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
- 处理null值
- 24. 查询没有部门的员工(即部门列为null值)
- 思考:如何查询有部门的员工(即部门列不为null值)
- 1.5.3 模糊查询 - like
- 25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
- 26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
- 1.5.4 多行函数查询
- 28.统计emp表中薪资大于3000的员工个数)
- 29.求emp表中的最高(低)薪资
- 30.统计emp表中所有员工的薪资总和(不包含奖金)
- 31.统计emp表员工的平均薪资(不包含奖金)
- 平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
- 1.5.5分组查询
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- ∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
- 1.5.6 排序查询
- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
- 36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
- 1.5.7 分页查询
- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
- 1.5.8其他函数
- 39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
- 40.查询emp表中本月过生日的所有员工
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 1.6 mysql的数据类型
- 1.6.1 数值类型
- 1.6.2 字符串类型
- 1.6.3 日期类型
- 1.7 mysql的字段约束
- 1.7.1 主键约束
- 1.7.2 非空约束
- 1.7.3 唯一约束
- ∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
- 1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗
- 外键演示
- 1.8 表关系
- 1.9多表查询
- 1.9.1连接查询
- 42.查询部门和部门对应的员工信息
- ∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
- 1.9.2 左外连接查询
- 43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
- 1.9.3右外连接查询
- 44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
- 1.9.4 子查询
- 45.列出薪资比'王海涛'薪资高的所有员工,显示姓名、薪资
- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
- 1.9.5 多表查询练习
- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号, 显示部门名称,员工名称。
- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
- ∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
- 1.10 ∗ ∗ 数 据 库 备 份 与 恢 复 ∗ ∗ \color{#ff0011}{ ** 数据库备份与恢复 ** } ∗∗数据库备份与恢复∗∗
- 1.10.1备份数据库
- 1.10.2恢复数据库
- 1.11 扩 展 内 容 \color{#ff0011}{扩展内容} 扩展内容
- 1.11.1修改表—新增列
- 1.11.2 修改表—修改列
- 1.11.3 修改表—删除列
- 1.11.4添加或删除主键及自增
- 1.11.5添加或删除外键约束
- 1.11.6删除外键约束
- 1.11.7where中不能使用列别名
- ∗ ∗ S Q L 语 句 的 书 写 顺 序 ∗ ∗ : \color{#ff0011}{**SQL语句的书写顺序**:} ∗∗SQL语句的书写顺序∗∗:
- ∗ ∗ S Q L 语 句 的 执 行 顺 序 : ∗ ∗ : \color{#ff0011}{**SQL语句的执行顺序:**:} ∗∗SQL语句的执行顺序:∗∗:
- ** 关于where中不能使用列别名但是可以使用表别名?
1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
– 准备数据: 以下练习将使用db10库中的表及表记录,请先进入db10数据库!!!
代码 - 创建db10数据库
进入mysql程序,复杂粘贴
-- -----------------------------------
-- 创建db10库、emp表并插入记录
-- -----------------------------------
-- 删除db10库(如果存在)
drop database if exists db10;
-- 重新创建db10库
create database db10 charset utf8;
-- 选择db10库
use db10;
-- 删除员工表(如果存在)
drop table if exists emp;
-- 创建员工表
create table emp(
id int primary key auto_increment, -- 员工编号
name varchar(50), -- 员工姓名
gender char(1), -- 员工性别
birthday date, -- 员工生日
dept varchar(50), -- 所属部门
job varchar(50), -- 所任职位
sal double, -- 薪资
bonus double -- 奖金
);
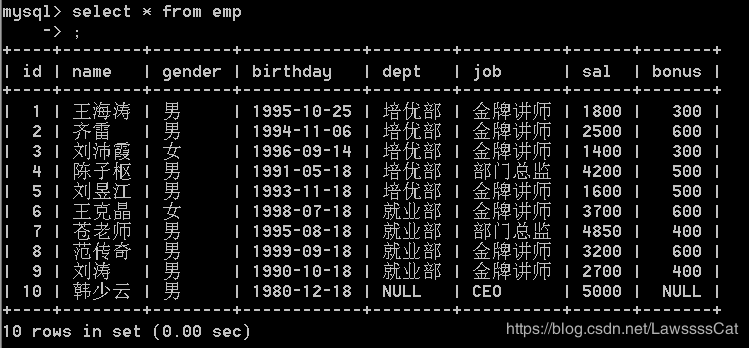
-- 往员工表中插入记录
insert into emp values(null,'王海涛','男','1995-10-25','培优部','金牌讲师','1800','300');
insert into emp values(null,'齐雷','男','1994-11-6','培优部','金牌讲师','2500','600');
insert into emp values(null,'刘沛霞','女','1996-09-14','培优部','金牌讲师','1400','300');
insert into emp values(null,'陈子枢','男','1991-05-18','培优部','部门总监','4200','500');
insert into emp values(null,'刘昱江','男','1993-11-18','培优部','金牌讲师','1600','500');
insert into emp values(null,'王克晶','女','1998-07-18','就业部','金牌讲师','3700','600');
insert into emp values(null,'苍老师','男','1995-08-18','就业部','部门总监','4850','400');
insert into emp values(null,'范传奇','男','1999-09-18','就业部','金牌讲师','3200','600');
insert into emp values(null,'刘涛','男','1990-10-18','就业部','金牌讲师','2700','400');
insert into emp values(null,'韩少云','男','1980-12-18',null,'CEO','5000',null);
-- -----------------------------------
-- 创建db20库、dept表、emp表并插入记录
-- -----------------------------------
-- 删除db20库(如果存在)
drop database if exists db20;
-- 重新创建db20库
create database db20 charset utf8;
-- 选择db20库
use db20;
-- 删除部门表, 如果存在
drop table if exists dept;
-- 重新创建部门表, 要求id, name字段
create table dept(
id int primary key auto_increment, -- 部门编号
name varchar(20) -- 部门名称
);
-- 往部门表中插入记录
insert into dept values(null, '财务部');
insert into dept values(null, '人事部');
insert into dept values(null, '科技部');
insert into dept values(null, '销售部');
-- 删除员工表, 如果存在
drop table if exists emp;
-- 创建员工表, 要求id, name, dept_id
create table emp(
id int primary key auto_increment, -- 员工编号
name varchar(20), -- 员工姓名
dept_id int -- 部门编号
-- ,foreign key(dept_id) references dept(id)
);
insert into emp values(null, '张三', 1);
insert into emp values(null, '李四', 2);
insert into emp values(null, '老王', 3);
insert into emp values(null, '赵六', 4);
insert into emp values(null, '刘能', 4);
-- -----------------------------------
-- 创建db30库、dept表、emp表并插入记录
-- -----------------------------------
-- 删除db30库(如果存在)
drop database if exists db30;
-- 重新创建db30库
create database db30 charset utf8;
-- 选择db30库
use db30;
-- 删除部门表, 如果存在
drop table if exists dept;
-- 重新创建部门表, 要求id, name字段
create table dept(
id int primary key auto_increment, -- 部门编号
name varchar(20) -- 部门名称
);
-- 往部门表中插入记录
insert into dept values(null, '财务部');
insert into dept values(null, '人事部');
insert into dept values(null, '科技部');
insert into dept values(null, '销售部');
-- 删除员工表, 如果存在
drop table if exists emp;
-- 创建员工表(员工编号、员工姓名、所在部门编号)
create table emp(
id int primary key auto_increment, -- 员工编号
name varchar(20), -- 员工姓名
dept_id int -- 部门编号
);
-- 往员工表中插入记录
insert into emp values(null, '张三', 1);
insert into emp values(null, '李四', 2);
insert into emp values(null, '老王', 3);
insert into emp values(null, '赵六', 5);
-- -----------------------------------
-- 创建db40库、dept表、emp表并插入记录
-- -----------------------------------
-- 删除db40库(如果存在)
drop database if exists db40;
-- 重新创建db40库
create database db40 charset utf8;
-- 选择db40库
use db40;
-- 创建部门表
create table dept( -- 创建部门表
id int primary key, -- 部门编号
name varchar(50), -- 部门名称
loc varchar(50) -- 部门位置
);
-- 创建员工表
create table emp( -- 创建员工表
id int primary key, -- 员工编号
name varchar(50), -- 员工姓名
job varchar(50), -- 职位
topid int, -- 直属上级
hdate date, -- 受雇日期
sal int, -- 薪资
bonus int, -- 奖金
dept_id int, -- 所在部门编号
foreign key(dept_id) references dept(id)
);
-- 往部门表中插入记录
insert into dept values ('10', '培优部', '北京');
insert into dept values ('20', '就业部', '上海');
insert into dept values ('30', '大数据部', '广州');
insert into dept values ('40', '销售部', '深圳');
-- 往员工表中插入记录
insert into emp values ('1001', '王克晶', '办事员', '1007', '1980-12-17', '800', 500, '20');
insert into emp values ('1003', '齐雷', '分析员', '1011', '1981-02-20', '1900', '300', '10');
insert into emp values ('1005', '王海涛', '推销员', '1011', '1981-02-22', '2450', '600', '10');
insert into emp values ('1007', '刘苍松', '经理', '1017', '1981-04-02', '3675', 700, '20');
insert into emp values ('1009', '张慎政', '推销员', '1011', '1981-09-28', '1250', '1400', '10');
insert into emp values ('1011', '陈子枢', '经理', '1017', '1981-05-01', '3450', 400, '10');
insert into emp values ('1013', '张久军', '办事员', '1011', '1981-06-09', '1250', 800, '10');
insert into emp values ('1015', '程祖红', '分析员', '1007', '1987-04-19', '3000', 1000, '20');
insert into emp values ('1017', '韩少云', '董事长', null, '1981-11-17', '5000', null, null);
insert into emp values ('1019', '刘沛霞', '推销员', '1011', '1981-09-08', '1500', 500, '10');
insert into emp values ('1021', '范传奇', '办事员', '1007', '1987-05-23', '1100', 1000, '20');
insert into emp values ('1023', '赵栋', '经理', '1017', '1981-12-03', '950', null, '30');
insert into emp values ('1025', '朴乾', '分析员', '1023', '1981-12-03', '3000', 600, '30');
insert into emp values ('1027', '叶尚青', '办事员', '1023', '1982-01-23', '1300', 400, '30');
-- ------------------- 执行完毕 -----------------------
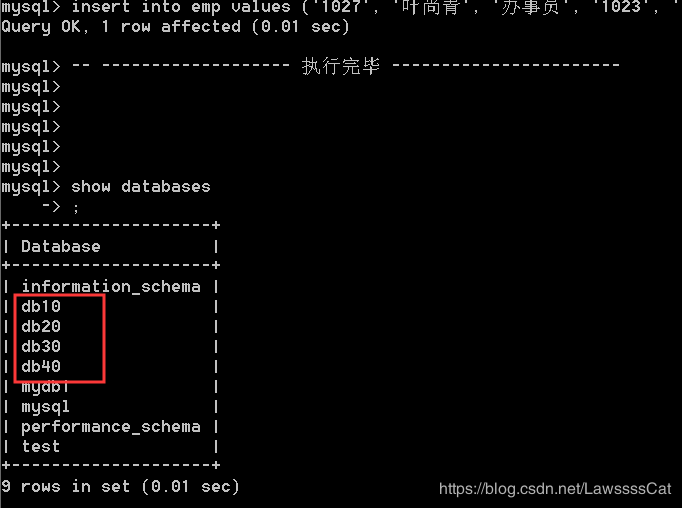
1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
SELECT 语句用于从表中选取数据。
结果被存储在一个结果表中(称为结果集)。
语法:SELECT 列名称 | * FROM 表名
提示:
- *(星号)为通配符,表示查询所有列。
- 但使用 *(星号)有时会把不必要的列也查出来了,并且效率不如直接指定列名
use db10 ; /* 进入这个数据库 */
SELECT name,sal,bonus FROM emp;

15.查询emp表中的所有员工,显示姓名,薪资,奖金
SELECT * FROM emp;
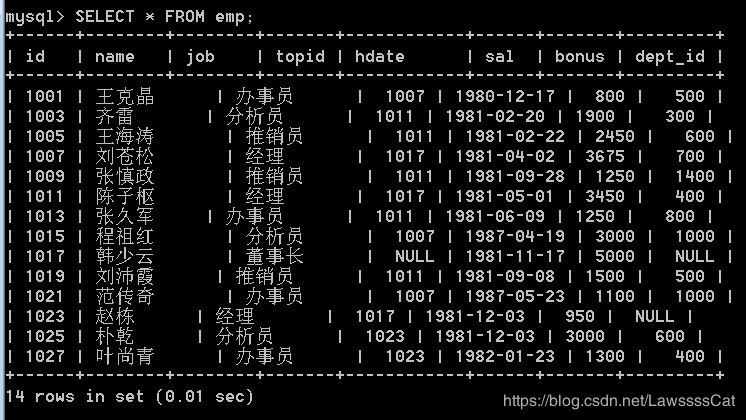
16.查询emp表中的所有部门和职位
SELECT dept,job from emp;
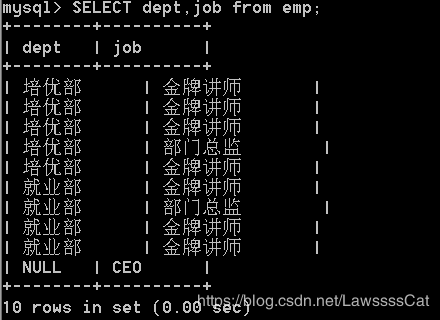
思考:如果查询的结果中,存在大量重复的记录,如何剔除重复记录,只保留一条? */
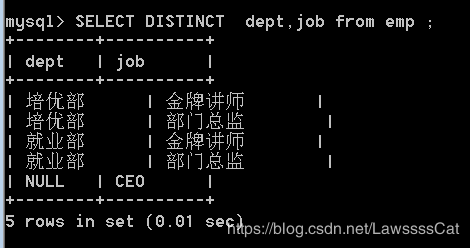
在select之后、列名之前,使用DISTINCT 剔除重复的记录
SELECT DISTINCT dept,job from emp ;
1.5.2 WHERE子句查询
WHERE子句查询语法:SELECT 列名称 FROM 表名称 WHERE 列 运算符 值
下面的运算符可在 WHERE 子句中使用:
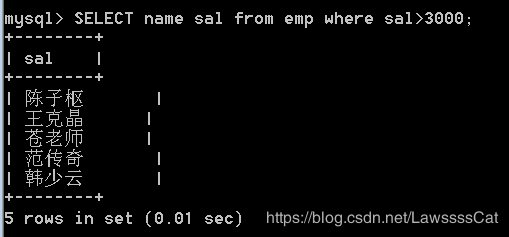
– 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资

SELECT name sal from emp where sal>3000;
– 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
SELECT name,sal+bonus from emp where sal+bonus > 3500 ;

∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
注意到,上面的数据少了一个,原因是 bouns=null,导致总薪资=null。
怎么解决?
ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
SELECT name,sal+ifnull(bonus,0) from emp where sal+ifnull(bonus,0)>3500;

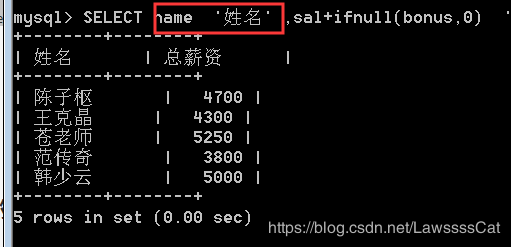
注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 “总薪资”
AS 关键字可以指定别名,格式 列名 as 别名
SELECT name as '姓名' ,sal+ifnull(bonus,0) as '总薪资' from emp where sal+ifnull(bonus,0)>3500;

- 注意:下面的写法错误
SELECT name as '姓名' ,sal+ifnull(bonus,0) as '总薪资'
from emp
where '总薪资' >3500; -- 写法错误
警告:where 子句子中不能使用列别名(但是可以使用表别名)
- AS 可以省略:也就是上面的语句可以写成下面的这样:
SELECT name '姓名' ,sal+ifnull(bonus,0) '总薪资' from emp where sal+ifnull(bonus,0)>3500;
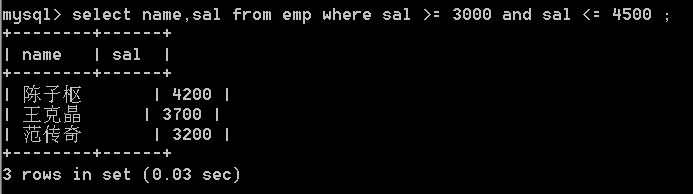
19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
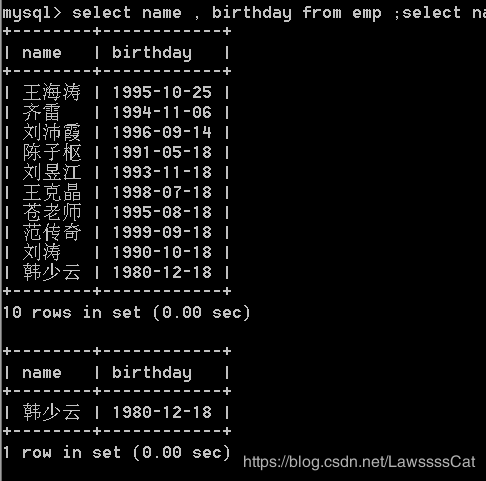
select name,sal from emp
where sal >= 3000 and sal <= 4500 ;
– 提示: between…and… 在…之间
select name , sal from emp
where sal between 3000 and 4500 ;

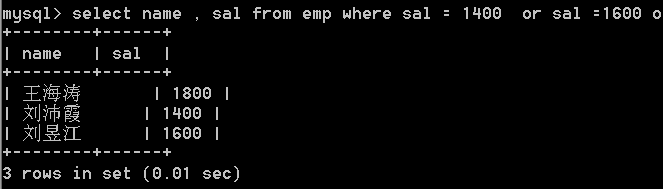
20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
/*答案1*/
select name , sal from emp
where sal = 1400 or sal =1600 or sal = 1800 ;
/*答案2*/
select name , sal from emp
where sal in (1400,1600,1800);

21.查询薪资不为1400、1600、1800的员工
/*答案1*/
select name , sal from emp
where sal != 1400 and sal != 1600 and sal != 1800 ;
/*答案2*/
select name , sal from emp
where sal not in(1400,1600,1800) ;
/*答案3*/
select name , sal from emp
where not (sal = 1400 or sal = 1600 or sal = 1800 );

22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
select name,sal from emp
where sal > 4000 or sal < 2000;
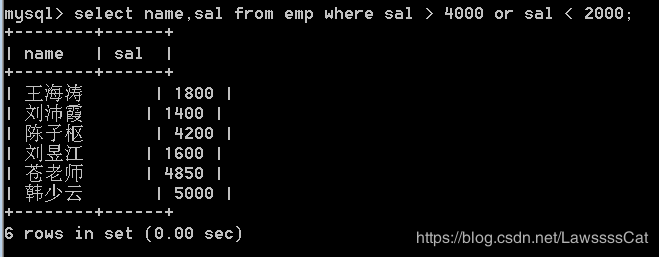
23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
select name,sal,bonus from emp
where sal>3000 and bonus<600 ;
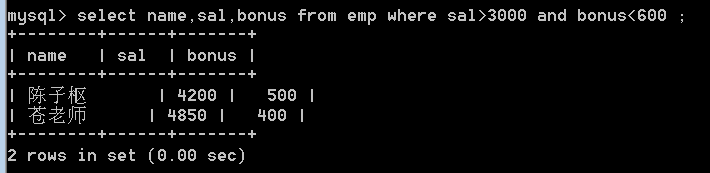
处理null值
select name,sal,bonus from emp
where ifnull(sal,0)>3000 and ifnull(bonus,0)<600 ;

24. 查询没有部门的员工(即部门列为null值)
/* 答案1 */
select name,dept from emp
where isnull(dept);
select name , dept from emp
where dept is null ;
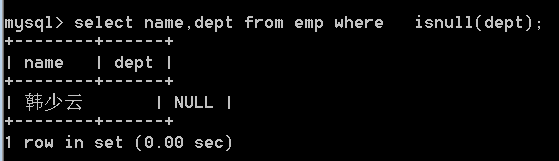
思考:如何查询有部门的员工(即部门列不为null值)
/* 答案1 */
select name , dept from emp
where not isnull(dept);
/* 答案2 */
select name , dept from emp
where dept is not null;
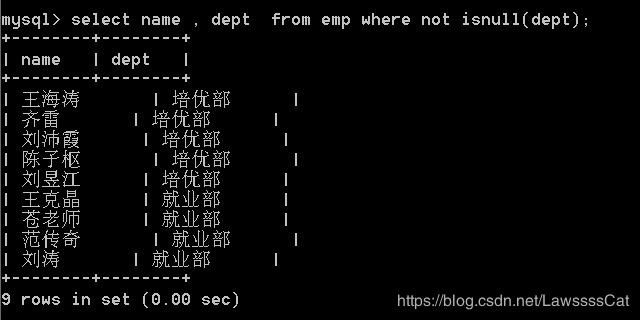
1.5.3 模糊查询 - like
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
可以和通配符(%、_)配合使用,其中
- "%"表示0或多个任意的字符。
- "_"表示一个任意的字符。
语法:SELECT 列 | * FROM 表名 WHERE 列名 LIKE 值
示例:
25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
xx 涛 xx
涛 xx
xx 涛
select name from emp
where name like '%涛%' ;
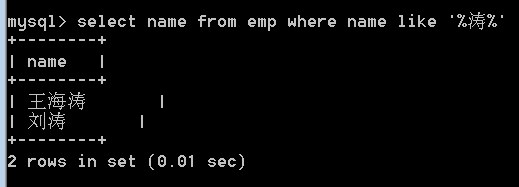
26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
刘 xx
select name from emp
where name like '刘%';
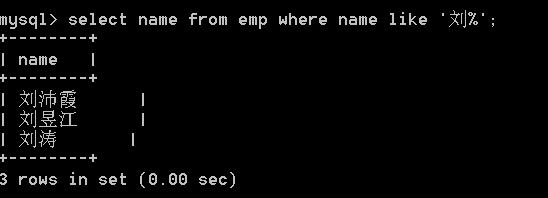
27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
select name from emp
where name like '刘__';
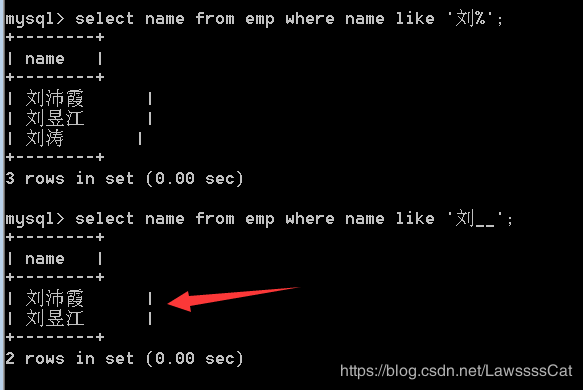
1.5.4 多行函数查询
多行函数也叫做聚合(聚集)函数,根据某一列或所有列进行统计。
常见的多行函数有:
COUNT( 列名|* ):统计结果集中某一列或记录行的行数。
MAX( 列 ):统计结果集中某一列值中的最大值
MIN( 列 ):统计结果集中某一列值中的最小值
SUM( 列 ):统计结果集中某一列所有值的和
AVG( 列 ):统计结果集中某一列值的平均值
提示:多行函数不能用在where子句中
28.统计emp表中薪资大于3000的员工个数)
count单一列时候,遇到null,不会计数
因此通常是count(*)
select * from emp where sal>3000;
select count(*) as '员工人数' from emp where sal>3000;
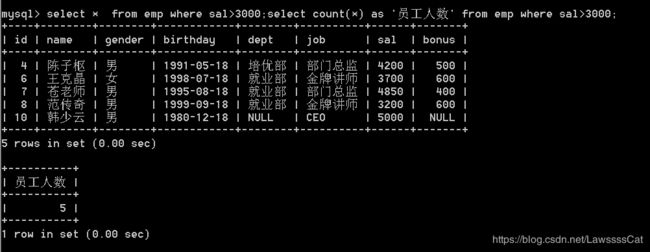
29.求emp表中的最高(低)薪资
select sal from emp ;
select max(sal) from emp ;
select min(sal) from emp ;
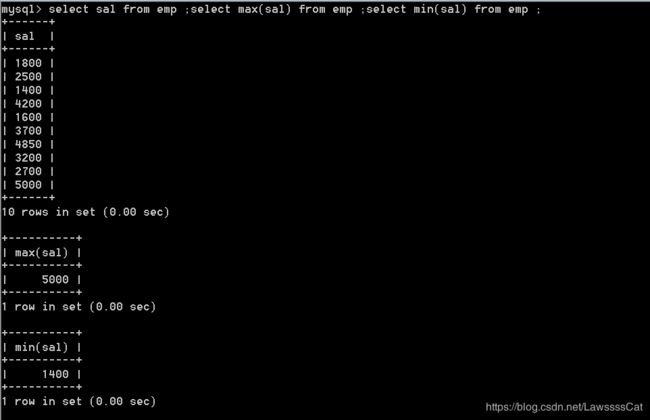
30.统计emp表中所有员工的薪资总和(不包含奖金)
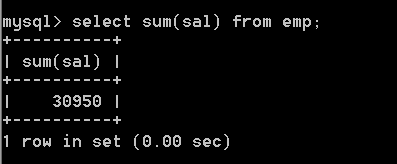
select sum(sal) from emp;
31.统计emp表员工的平均薪资(不包含奖金)
select avg(sal) from emp ;

平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
出现问题
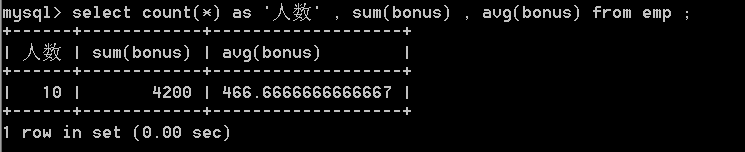
平均奖金 应该是 420 ;
select count(*) as '人数' , sum(bonus) , avg(bonus) from emp ;
解决问题
select count(*) as '人数' , sum(bonus) , avg(ifnull(bonus,0)) from emp ;

1.5.5分组查询
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT,SUM,AVG,MAX,MIN等函数。
语法:SELECT 列 | * FROM 表名 [WHERE子句] GROUP BY 列;
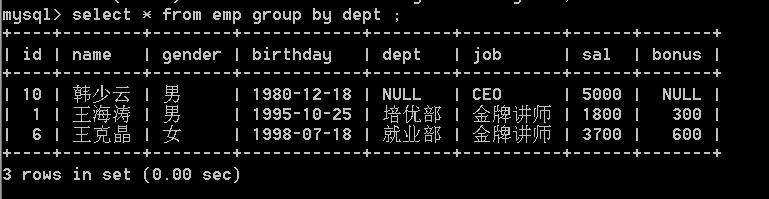
32.对emp表按照部门对员工进行分组,查看分组后效果。
32.对emp表按照部门对员工进行分组,查看分组后效果。
问题: 只显示每组的第一个人
select * from emp group by dept ;
∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
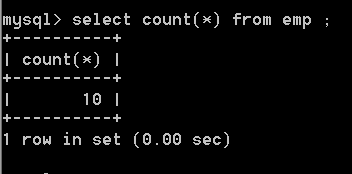
聚合函数在查询时,如果没有分组,默认会将整个查询结果看做是一个组进行统计。
如果有分组,分了多少个组,就会统计出多少个结果。
如果没有分组,统计emp表中的人数;
e.g.
select count(*) from emp ;
如果按照部门分组,再使用count进行统计人数:
e.g.
select dept, count(*) from emp group by dept;

再例如:如果没有分组,统计emp表中的最高薪资;
select max(sal) from emp ;
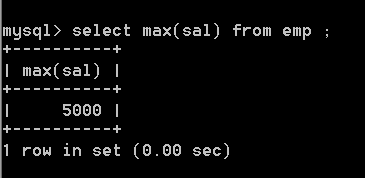
如果按照部门分组,再使用max函数进行统计:
select dept , min(sal) from emp group by dept ;

33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
select job , count(*) from emp group by job;
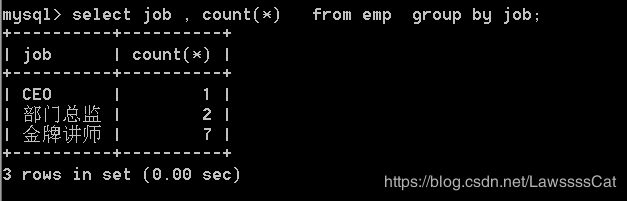
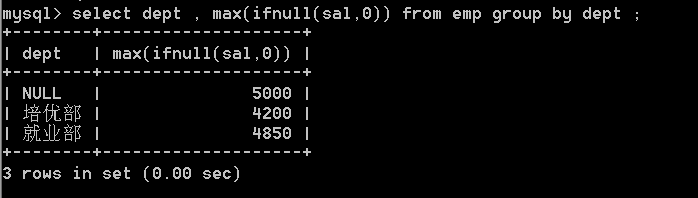
34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
select dept , max(ifnull(sal,0)) from emp group by dept ;
1.5.6 排序查询
使用 ORDER BY 子句将结果集根据指定的列排序后再返回
语法:SELECT 列名 FROM 表名 ORDER BY 列名 [ASC|DESC]
- ASC(默认) - 升序,即从低到高 - ascend ;
- DESC - 降序,即从高到低。 - descend;
35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
select name , sal from emp order by sal asc ;

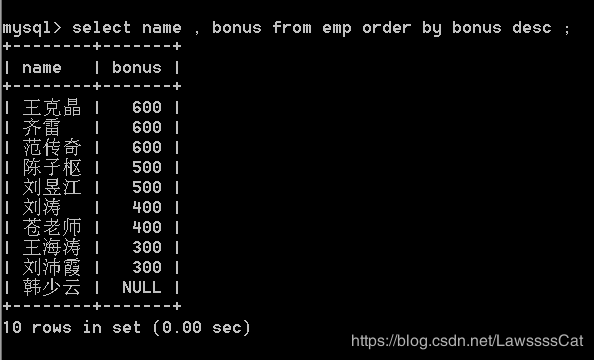
36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
select name , bonus from emp order by bonus desc ;
1.5.7 分页查询
在mysql中,通过limit进行分页查询:
limit (页码-1)*每页显示记录数,每页显示记录数
(limit 跳过数据数,显示数据数)
37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
select * from emp ;
select * from emp limit 0 , 3 ;
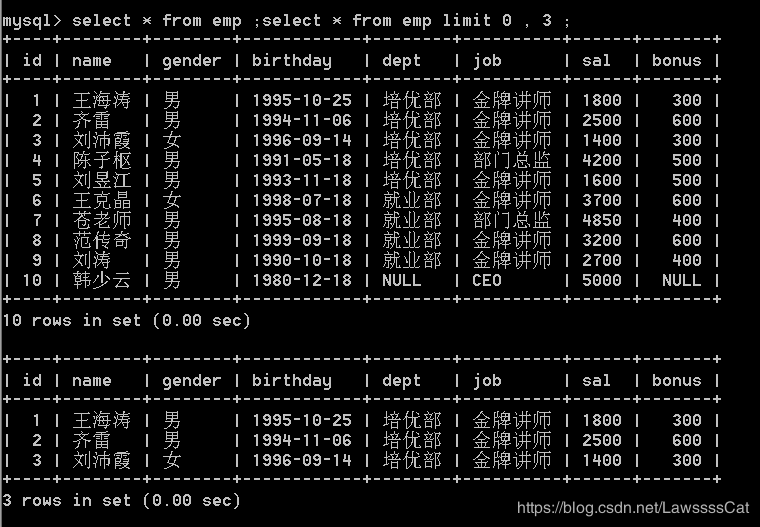
38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
select * from emp ;
select * from emp limit 3 , 3 ;

1.5.8其他函数
curdate() 获取当前日期 年月日
curtime() 获取当前时间 时分秒
sysdate() 获取当前日期+时间 年月日 时分秒
year(date) 返回date中的年份
month(date) 返回date中的月份
day(date) 返回date中的月份
hour(date) 返回date中的小时
minute(date) 返回date中的分钟
second(date) 返回date中的秒
now() 当前时间
CONCAT(s1,s2…) 将s1,s2 等多个字符串合并为一个字符串
CONCAT_WS(x,s1,s2…) 同CONCAT(s1,s2,…) 函数,但是每个字符串之间要加上x,x是分隔符
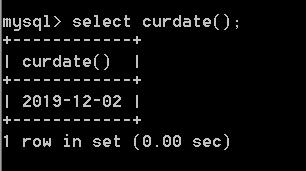
e.g.
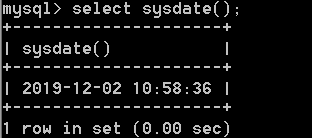
select curdate();
select curtime();

select sysdate();
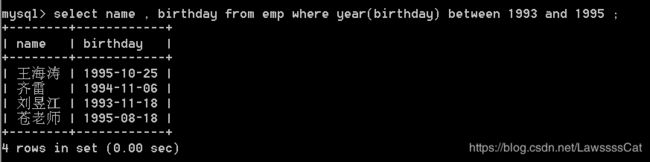
39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
/* 不好的答案 */
select name , birthday from emp
where birthday between '1993-1-1' and '1995-12-31' ;
/* 答案 */
select name , birthday from emp
where year(birthday) between 1993 and 1995 ;
40.查询emp表中本月过生日的所有员工
select name , birthday from emp ;
select name , birthday from emp
where month(birthday) = month(curdate()) ;
/* 上个月 */
select name , birthday from emp
where month(now())-1=month(birthday);

41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
select name, concat(sal,'(元)') from emp ;

41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
- 10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
- 11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
- 12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
- 13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
- 14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
- 1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
- 代码 - 创建db10数据库
- 1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
- SELECT 语句用于从表中选取数据。
- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
- 16.查询emp表中的所有部门和职位
- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
- 1.5.2 WHERE子句查询
- -- 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资
- -- 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
- ∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
- ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
- 19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
- 20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
- 21.查询薪资不为1400、1600、1800的员工
- 22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
- 23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
- 处理null值
- 24. 查询没有部门的员工(即部门列为null值)
- 思考:如何查询有部门的员工(即部门列不为null值)
- 1.5.3 模糊查询 - like
- 25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
- 26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
- 1.5.4 多行函数查询
- 28.统计emp表中薪资大于3000的员工个数)
- 29.求emp表中的最高(低)薪资
- 30.统计emp表中所有员工的薪资总和(不包含奖金)
- 31.统计emp表员工的平均薪资(不包含奖金)
- 平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
- 1.5.5分组查询
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- ∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
- 1.5.6 排序查询
- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
- 36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
- 1.5.7 分页查询
- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
- 1.5.8其他函数
- 39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
- 40.查询emp表中本月过生日的所有员工
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 1.6 mysql的数据类型
- 1.6.1 数值类型
- 1.6.2 字符串类型
- 1.6.3 日期类型
- 1.7 mysql的字段约束
- 1.7.1 主键约束
- 1.7.2 非空约束
- 1.7.3 唯一约束
- ∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
- 1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗
- 外键演示
- 1.8 表关系
- 1.9多表查询
- 1.9.1连接查询
- 42.查询部门和部门对应的员工信息
- ∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
- 1.9.2 左外连接查询
- 43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
- 1.9.3右外连接查询
- 44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
- 1.9.4 子查询
- 45.列出薪资比'王海涛'薪资高的所有员工,显示姓名、薪资
- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
- 1.9.5 多表查询练习
- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号, 显示部门名称,员工名称。
- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
- ∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
- 1.10 ∗ ∗ 数 据 库 备 份 与 恢 复 ∗ ∗ \color{#ff0011}{ ** 数据库备份与恢复 ** } ∗∗数据库备份与恢复∗∗
- 1.10.1备份数据库
- 1.10.2恢复数据库
- 1.11 扩 展 内 容 \color{#ff0011}{扩展内容} 扩展内容
- 1.11.1修改表—新增列
- 1.11.2 修改表—修改列
- 1.11.3 修改表—删除列
- 1.11.4添加或删除主键及自增
- 1.11.5添加或删除外键约束
- 1.11.6删除外键约束
- 1.11.7where中不能使用列别名
- ∗ ∗ S Q L 语 句 的 书 写 顺 序 ∗ ∗ : \color{#ff0011}{**SQL语句的书写顺序**:} ∗∗SQL语句的书写顺序∗∗:
- ∗ ∗ S Q L 语 句 的 执 行 顺 序 : ∗ ∗ : \color{#ff0011}{**SQL语句的执行顺序:**:} ∗∗SQL语句的执行顺序:∗∗:
- ** 关于where中不能使用列别名但是可以使用表别名?
1.6 mysql的数据类型
1.6.1 数值类型
MySQL中支持多种整型,其实很大程度上是相同的,只是存储值的大小范围不同而已。
tinyint:占用1个字节,相对于java中的byte
smallint:占用2个字节,相对于java中的short
int:占用4个字节,相对于java中的int
bigint:占用8个字节,相对于java中的long
其次是浮点类型即:float和double类型
float:4字节单精度浮点类型,相对于java中的float
double:8字节双精度浮点类型,相对于java中的double
1.6.2 字符串类型
- char(n) 定长字符串,最长255个字符。n表示字符数,
例如:
– 创建user表,指定用户名为char类型,字符长度不超过10
create table user(
username char(10),
...
);
所谓的定长,是当插入的值长度小于指定的长度时,剩余的空间会用空格填充。(这样会浪费空间)
- varchar(n) 变长字符串,最长不超过 65535个字节,n表示字符数,
一般超过255个字节,会使用text类型,
例如:
– 创建user表,指定用户名为varchar类型,长度不超过10
create table user(
username varchar(10)
);
所谓的不定长,是当插入的值长度小于指定的长度时,剩余的空间可以留给别的数据使用。(节省空间)
对比
- char:相对varchar,效率高,可能浪费空间
- varchar:相对char,效率低,节省空间
- text 大文本(长文本)类型
最长65535个字节,一般超过255个字符列的会使用text。
– 创建user表:
create table user(
resume text
);
另,text也分多种,其中bigtext存储数据的长度约为4GB。
扩展内容3:(面试题)char(n)、varchar(n)、text都可以表示字符串类型,其区别在于:
- char(n)在 保存数据时, 如果存入的字符串长度小于指定的长度n,后面会用空格补全,因此可能会造成空间浪费,但是char类型的存储速度较varchar和text快。
因此char类型适合存储长度固定的数据,这样就不会有空间浪费,存储效率比后两者还快! - varchar(n)保存数据时, 按数据的真实长度存储, 剩余的空间可以留给别的数据用,因此varchar不会浪费空间。
因此varchar适合存储长度不固定的数据,这样不会有空间的浪费。 - text是大文本类型,一般文本长度超过255个字符,就会使用text类型存储。
1.6.3 日期类型
date:年月日
time:时分秒
datetime:年月日 时分秒
timestamp:时间戳(实际存储的是一个时间毫秒值),与datetime存储日期格式相同。
stamp 标记
两者的区别是:
- timestamp最大表示2038年,而datetime范围是1000~9999
- timestamp在插入数、修改数据时,可以自动更新成系统当前时间(后面用到时再做讲解)
文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
- 10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
- 11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
- 12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
- 13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
- 14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
- 1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
- 代码 - 创建db10数据库
- 1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
- SELECT 语句用于从表中选取数据。
- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
- 16.查询emp表中的所有部门和职位
- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
- 1.5.2 WHERE子句查询
- -- 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资
- -- 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
- ∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
- ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
- 19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
- 20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
- 21.查询薪资不为1400、1600、1800的员工
- 22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
- 23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
- 处理null值
- 24. 查询没有部门的员工(即部门列为null值)
- 思考:如何查询有部门的员工(即部门列不为null值)
- 1.5.3 模糊查询 - like
- 25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
- 26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
- 1.5.4 多行函数查询
- 28.统计emp表中薪资大于3000的员工个数)
- 29.求emp表中的最高(低)薪资
- 30.统计emp表中所有员工的薪资总和(不包含奖金)
- 31.统计emp表员工的平均薪资(不包含奖金)
- 平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
- 1.5.5分组查询
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- ∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
- 1.5.6 排序查询
- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
- 36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
- 1.5.7 分页查询
- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
- 1.5.8其他函数
- 39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
- 40.查询emp表中本月过生日的所有员工
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 1.6 mysql的数据类型
- 1.6.1 数值类型
- 1.6.2 字符串类型
- 1.6.3 日期类型
- 1.7 mysql的字段约束
- 1.7.1 主键约束
- 1.7.2 非空约束
- 1.7.3 唯一约束
- ∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
- 1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗
- 外键演示
- 1.8 表关系
- 1.9多表查询
- 1.9.1连接查询
- 42.查询部门和部门对应的员工信息
- ∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
- 1.9.2 左外连接查询
- 43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
- 1.9.3右外连接查询
- 44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
- 1.9.4 子查询
- 45.列出薪资比'王海涛'薪资高的所有员工,显示姓名、薪资
- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
- 1.9.5 多表查询练习
- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号, 显示部门名称,员工名称。
- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
- ∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
- 1.10 ∗ ∗ 数 据 库 备 份 与 恢 复 ∗ ∗ \color{#ff0011}{ ** 数据库备份与恢复 ** } ∗∗数据库备份与恢复∗∗
- 1.10.1备份数据库
- 1.10.2恢复数据库
- 1.11 扩 展 内 容 \color{#ff0011}{扩展内容} 扩展内容
- 1.11.1修改表—新增列
- 1.11.2 修改表—修改列
- 1.11.3 修改表—删除列
- 1.11.4添加或删除主键及自增
- 1.11.5添加或删除外键约束
- 1.11.6删除外键约束
- 1.11.7where中不能使用列别名
- ∗ ∗ S Q L 语 句 的 书 写 顺 序 ∗ ∗ : \color{#ff0011}{**SQL语句的书写顺序**:} ∗∗SQL语句的书写顺序∗∗:
- ∗ ∗ S Q L 语 句 的 执 行 顺 序 : ∗ ∗ : \color{#ff0011}{**SQL语句的执行顺序:**:} ∗∗SQL语句的执行顺序:∗∗:
- ** 关于where中不能使用列别名但是可以使用表别名?
1.7 mysql的字段约束
1.7.1 主键约束
主键约束:如果为一个列添加了主键约束,那么这个列就是主键,主键的特点是唯一且不能为空。
添加主键约束,例如将id设置为主键:
create table stu(
id int primary key,
...
);
如果组件约束的列是数值类型,可以设置主键自增:
create table stu(
id int primary key auto_increment,
...
);
即以后再插入数据时,不用给id(主键)赋值,数据库会自动获取一个id值插入到数据库中。
1.7.2 非空约束
非空约束:如果为一个列添加了非空约束,那么这个列的值就不能为空,但可以重复。
添加非空约束,例如为password添加非空约束:
create table user(
password varchar(50) not null,
...
);
1.7.3 唯一约束
唯一约束:如果为一个列添加了唯一约束,那么这个列的值就必须是唯一的(即不能重复),但可以为空。
添加唯一约束,例如为username添加唯一约束及非空约束:
create table user(
username varchar(50) unique not null,
...
);
∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
创建有约束属性的表
CREATE TABLE stu(
id INT PRIMARY KEY auto_increment,
name VARCHAR(50),
gender VARCHAR(10),
birthday DATE,
score DOUBLE
);

插入数据
INSERT INTO stu VALUE(
null, /*ID*/
'小明', /*姓名*/
'男',/*性别*/
'1988-11-29',/*出生年龄*/
85/*成绩*/
);
INSERT INTO stu VALUE(2,'刘沛霞','女','1988-12-18',76);
INSERT INTO stu VALUE(null,'霞','女','1999-12-22',30);

1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗

外键其实就是用于通知数据库两张表数据之间对应关系的这样一个列。
这样数据库就会帮我们维护两张表中数据之间的关系。
在一个表中添加一个列,保存另外一个表的主键。
在1-》n的关系中,通常是n表中存储外键约束。
有外键存在,数据库会自动维护关系,
如:
- 当删除以外键为id的数据时,且存储的另外表中,还有存储了的外键的数据。那么删除就会失败。
- 创建表的同时添加外键
create table emp(
id int,
name varchar(50),
dept_id int,
foreign key(dept_id) references dept(id)
);
create table table1 (
id int primary key auto_increment,
name varchar(50),
emp_id int ,
foreign key(emp_id) references emp(id)
);
insert into table1 value(
null, 't1' , 1001
);
- 如果在创建表时没有指定外键,那么后期该如何指定外键?以及如何删除外键?
在 扩 展 内 容 \color{#ff0011}{在扩展内容} 在扩展内容 - 一定 要看
在表寸两张表(dept,emp)数据之间的关系时,可以在其中的一张表(emp)中添加一个列(dept_id),保存另外一张表(dept)的主键(id),从而保存两张表数据之间的对应关系。
- 如果不将dept_id指定为外键,这个关系就只有我们开发人员知道,但是数据库并不知道两张表之存在的关系,所以数据库也就不会帮你维护这个关系。
- 如果将dept_id指定为外键,等同于通知数据库,部门表和员工之间存在的对应关系,这个关系就是通过dept_id列指定:即要参考部门的主键,一旦指定了外键,数据库就会知道并维护这个关系。
- 如果要
外键演示
没有db20的先导入数据库
-- --------------------------------------------------
-- 创建db20库、dept表、emp表并插入记录
-- --------------------------------------------------
-- 删除db20库(如果存在)
drop database if exists db20;
-- 重新创建db20库
create database db20 charset utf8;
-- 选择db20库
use db20;
-- 删除部门表, 如果存在
drop table if exists dept;
-- 重新创建部门表, 要求id, name字段
create table dept(
id int primary key auto_increment, -- 部门编号
name varchar(20) -- 部门名称
);
-- 往部门表中插入记录
insert into dept values(null, '财务部');
insert into dept values(null, '人事部');
insert into dept values(null, '科技部');
insert into dept values(null, '销售部');
-- 删除员工表, 如果存在
drop table if exists emp;
-- 创建员工表, 要求id, name, dept_id
create table emp(
id int primary key auto_increment, -- 员工编号
name varchar(20), -- 员工姓名
dept_id int -- 部门编号
-- ,foreign key(dept_id) references dept(id) -- 指定外键
);
insert into emp values(null, '张三', 1);
insert into emp values(null, '李四', 2);
insert into emp values(null, '老王', 3);
insert into emp values(null, '赵六', 4);
insert into emp values(null, '刘能', 4);
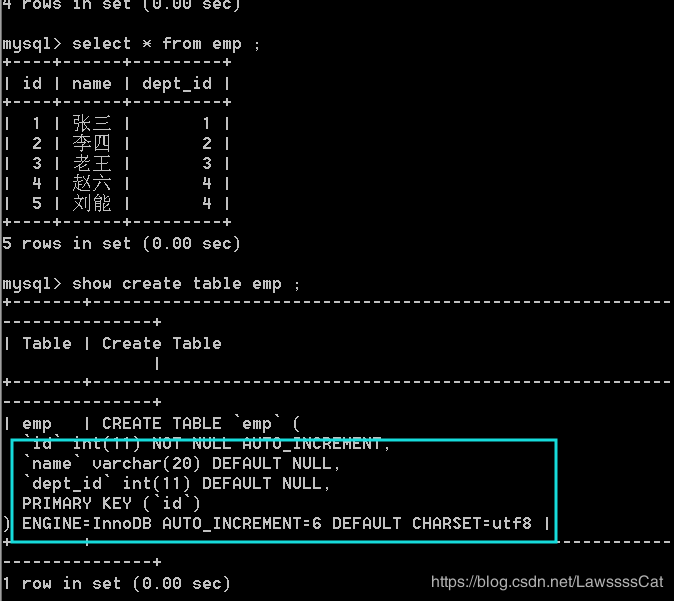
use db20 ;
show * from dept ;
show * from emp ;
show create table emp ;
/* 发现没有添加外键 */
把上面注释的代码打开,
show create table emp ;
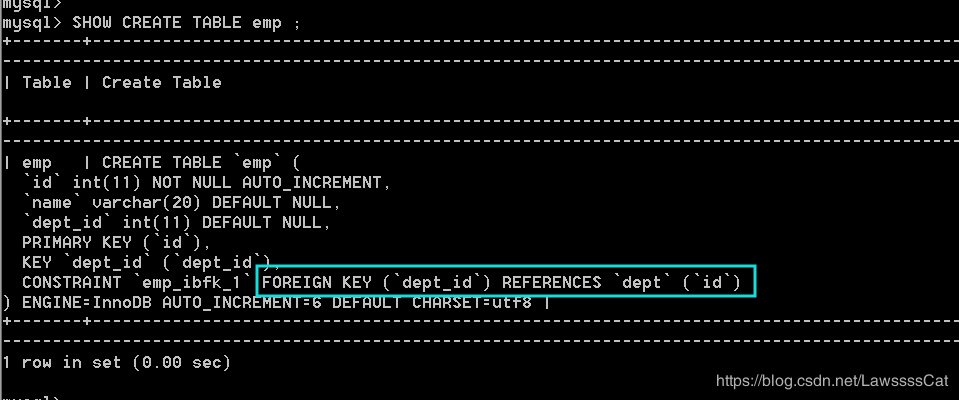
delete from dept where id=4 ;

1.8 表关系
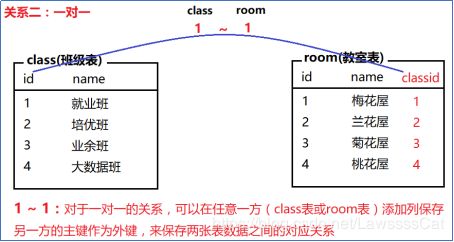
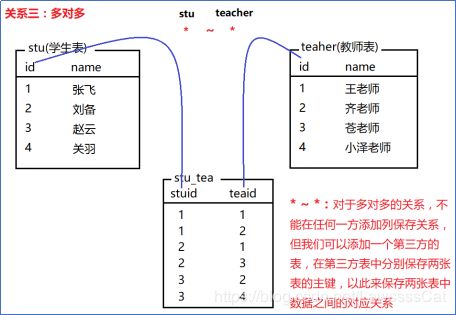
常见的表关系分为以下三种:
- 一对多(多对一)、
- 一对一、
- 多对多
技巧,
- 对于一对多/多对一,就在多的表中添加一的主键作为外键。
- 一对一,外键在哪都可以。
- 多对多,需要创建第三个表,专门管理外键,外键分别为两张表主键。

文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录} 记录
- 10.往学生表(stu)中 插 入 \color{#ff0011}{插入} 插入 记 录 \color{#ff0011}{记录} 记录(数据)
- 11. 查 询 \color{#ff0011}{查询} 查询stu表所有学生的 记 录 \color{#ff0011}{记录} 记录
- 12. 修 改 \color{#ff0011}{修改} 修改stu表中所有学生的成绩,加10分特长分 记 录 \color{#ff0011}{记录} 记录
- 13. 修 改 \color{#ff0011}{修改} 修改stu表中编号为1的学生成绩,将成绩改为83分 记 录 \color{#ff0011}{记录} 记录。
- 14. 删 除 \color{#ff0011}{删除} 删除stu表中所有的 记 录 \color{#ff0011}{记录} 记录
- 1.5 ∗ ∗ ∗ 查 询 表 记 录 ∗ ∗ ∗ 重 点 ∗ ∗ ∗ \color{#ff0011}{* * * 查询表记录 * * * 重点 * * * } ∗∗∗查询表记录∗∗∗重点∗∗∗
- 代码 - 创建db10数据库
- 1.5.1 基础查询 - s e l e c t \color{#ff0011}{select} select
- SELECT 语句用于从表中选取数据。
- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
- 16.查询emp表中的所有部门和职位
- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
- 1.5.2 WHERE子句查询
- -- 17.查询emp表中薪资大于3000的所有员工,显示员工姓名、薪资
- -- 18.查询emp表中总薪资(薪资+奖金)大于3500的所有员工,显示员工姓名、总薪资
- ∗ ∗ ∗ n u l l + 任 何 东 西 = n u l l ∗ ∗ ∗ \color{#ff0011}{ *** null+任何东西 = null ***} ∗∗∗null+任何东西=null∗∗∗
- ifnull(列, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
- 19.查询emp表中薪资在3000和4500之间的员工,显示员工姓名和薪资
- 20.查询emp表中薪资为 1400、1600、1800的员工,显示员工姓名和薪资
- 21.查询薪资不为1400、1600、1800的员工
- 22.查询emp表中薪资大于4000和薪资小于2000的员工,显示员工姓名、薪资。
- 23.查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。(不处理null)
- 处理null值
- 24. 查询没有部门的员工(即部门列为null值)
- 思考:如何查询有部门的员工(即部门列不为null值)
- 1.5.3 模糊查询 - like
- 25.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
- 26.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
- 1.5.4 多行函数查询
- 28.统计emp表中薪资大于3000的员工个数)
- 29.求emp表中的最高(低)薪资
- 30.统计emp表中所有员工的薪资总和(不包含奖金)
- 31.统计emp表员工的平均薪资(不包含奖金)
- 平均奖金 - n u l l 值 导 致 的 问 题 \color{#ff0011}{null值导致的问题} null值导致的问题
- 1.5.5分组查询
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- 32.对emp表按照部门对员工进行分组,查看分组后效果。
- ∗ ∗ 分 组 的 多 行 查 询 ∗ ∗ \color{#ff0011}{** 分组的多行查询 **} ∗∗分组的多行查询∗∗
- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
- 1.5.6 排序查询
- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
- 36.对emp表中所有员工奖金进行降序(从高到低)排序,显示员工姓名、奖金。
- 1.5.7 分页查询
- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 1 页。
- 38.查询emp表中的所有记录,分页显示:每页显示3条记录,返回第 2 页。
- 1.5.8其他函数
- 39.查询emp表中所有在1993和1995年之间出生的员工,显示姓名、出生日期。
- 40.查询emp表中本月过生日的所有员工
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
- 1.6 mysql的数据类型
- 1.6.1 数值类型
- 1.6.2 字符串类型
- 1.6.3 日期类型
- 1.7 mysql的字段约束
- 1.7.1 主键约束
- 1.7.2 非空约束
- 1.7.3 唯一约束
- ∗ ∗ 测 试 ∗ ∗ \color{#ff0011}{** 测试 **} ∗∗测试∗∗
- 1.7.4 ∗ ∗ 外 键 约 束 ∗ ∗ \color{#ff0011}{ ** 外键约束 ** } ∗∗外键约束∗∗
- 外键演示
- 1.8 表关系
- 1.9多表查询
- 1.9.1连接查询
- 42.查询部门和部门对应的员工信息
- ∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
- 1.9.2 左外连接查询
- 43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
- 1.9.3右外连接查询
- 44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
- 1.9.4 子查询
- 45.列出薪资比'王海涛'薪资高的所有员工,显示姓名、薪资
- 46.列出与'刘沛霞'从事相同职位的所有员工,显示姓名、职位。
- 47.列出薪资比'大数据部'部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
- 1.9.5 多表查询练习
- 48.列出在'培优部'任职的员工,假定不知道'培优部'的部门编号, 显示部门名称,员工名称。
- 49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
- 50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
- ∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
- 51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
- 52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
- 53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
- 54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
- 1.10 ∗ ∗ 数 据 库 备 份 与 恢 复 ∗ ∗ \color{#ff0011}{ ** 数据库备份与恢复 ** } ∗∗数据库备份与恢复∗∗
- 1.10.1备份数据库
- 1.10.2恢复数据库
- 1.11 扩 展 内 容 \color{#ff0011}{扩展内容} 扩展内容
- 1.11.1修改表—新增列
- 1.11.2 修改表—修改列
- 1.11.3 修改表—删除列
- 1.11.4添加或删除主键及自增
- 1.11.5添加或删除外键约束
- 1.11.6删除外键约束
- 1.11.7where中不能使用列别名
- ∗ ∗ S Q L 语 句 的 书 写 顺 序 ∗ ∗ : \color{#ff0011}{**SQL语句的书写顺序**:} ∗∗SQL语句的书写顺序∗∗:
- ∗ ∗ S Q L 语 句 的 执 行 顺 序 : ∗ ∗ : \color{#ff0011}{**SQL语句的执行顺序:**:} ∗∗SQL语句的执行顺序:∗∗:
- ** 关于where中不能使用列别名但是可以使用表别名?
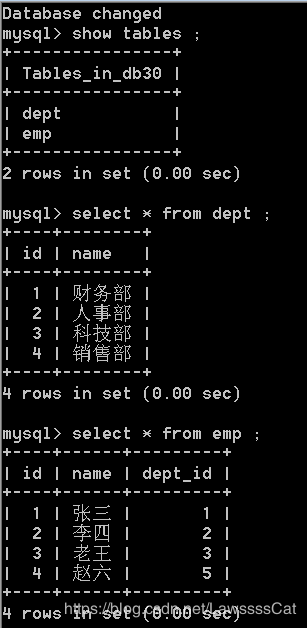
1.9多表查询
– 准备数据:
以下练习将使用db30库中的表及表记录,请先进入db30数据库!!!
脚本在上面。
脚本运行结果。
1.9.1连接查询
42.查询部门和部门对应的员工信息
/* 错误结果 */
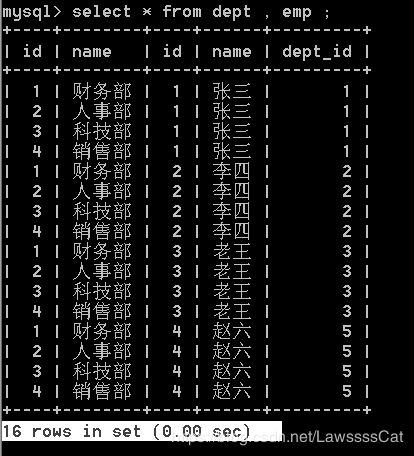
select * from dept , emp ;
/* 笛卡尔积查询 */
笛卡尔积查询:同时查询两张表,其中一张表有m条记录,另一张表有n条记录,笛卡尔积查询的结果就是m*n条
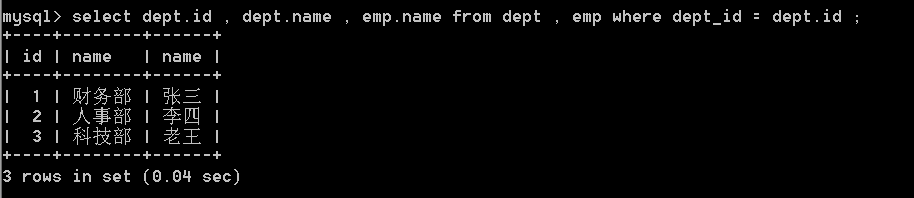
select dept.id , dept.name , emp.name from dept , emp
where dept_id = dept.id ;
∗ ∗ 思 考 题 ∗ ∗ ∗ \color{#ff0011}{**思考题***} ∗∗思考题∗∗∗
现在有班级表class(id,name)、学生表stu(sid,name , class_id) ,现在查询班级及班级对应的学生信息。
select * from class , stu
where class.id = class_id;
1.9.2 左外连接查询
select 显示 from 全表 left join 连接表 on 条件
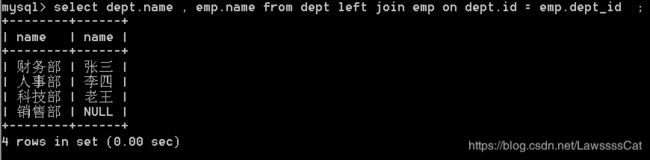
43.查询所有部门和部门下的员工, 如 果 部 门 下 没 有 员 工 , 员 工 显 示 为 n u l l \color{#ff0011}{如果部门下没有员工,员工显示为null} 如果部门下没有员工,员工显示为null
select dept.name , emp.name from dept left join emp
on dept.id = emp.dept_id ;
1.9.3右外连接查询
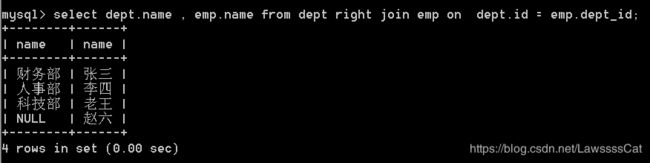
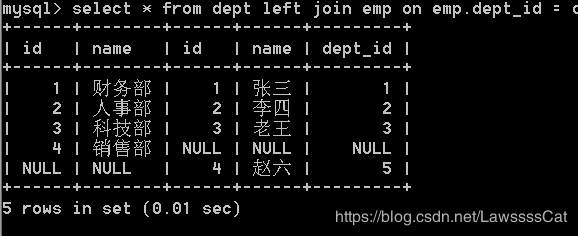
44.查询部门和所有员工, 如 果 员 工 没 有 所 属 部 门 , 部 门 显 示 为 n u l l \color{#ff0011}{如果员工没有所属部门,部门显示为null} 如果员工没有所属部门,部门显示为null
select dept.name , emp.name from dept right join emp
on dept.id = emp.dept_id;
/* mysql不支持full join */
select * from dept full join emp
on emp.dept_id = dept.id;
/* 扩展 */
union : 合并两个SQL 查询的结果,去除重复数据(要求,列数一样,列名一样)
union all :合并两个SQL 查询的结果,不去除重复数据(要求,列数一样,列名一样)
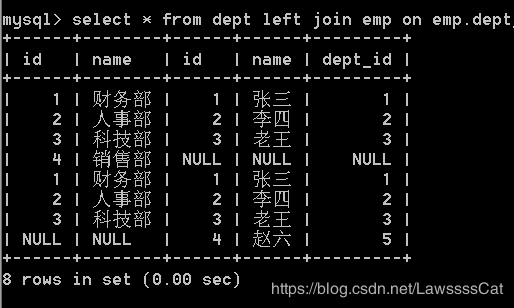
/* 解决方法 */
select * from dept left join emp
on emp.dept_id = dept.id
union
select * from dept right join emp
on emp.dept_id = dept.id;
/* union all 测试 */
select * from dept left join emp
on emp.dept_id = dept.id
union all
select * from dept right join emp
on emp.dept_id = dept.id;
1.9.4 子查询
准备数据:以下练习将使用db40库中的表及表记录,请先进入db40数据库!!!
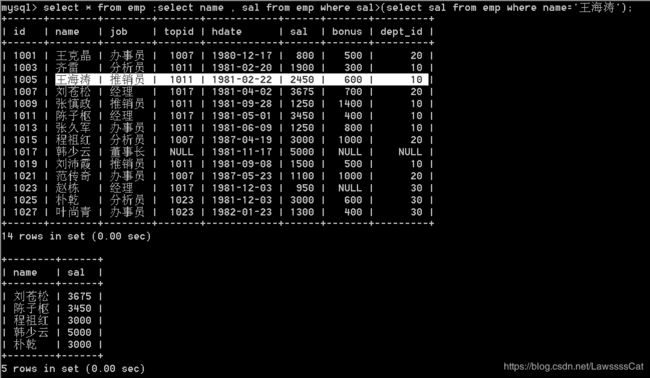
45.列出薪资比’王海涛’薪资高的所有员工,显示姓名、薪资
use db40 ;
select * from emp ;
select name , sal from emp
where sal>(select sal from emp where name='王海涛') ;
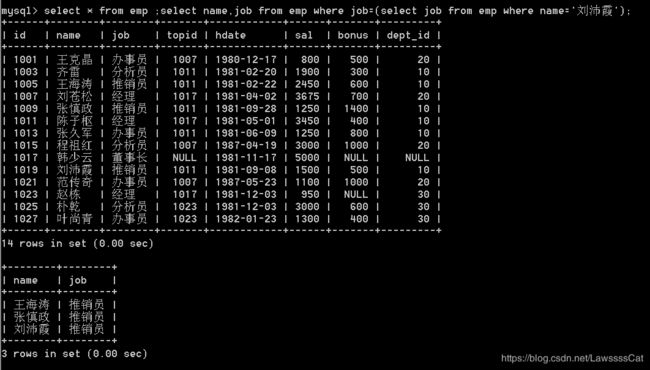
46.列出与’刘沛霞’从事相同职位的所有员工,显示姓名、职位。
select * from emp ;
select name,job from emp
where job=(select job from emp where name='刘沛霞') /*and not name ='刘沛霞'*/;
47.列出薪资比’大数据部’部门(已知部门编号为30)所有员工薪资都高的员工信息,显示员工姓名、薪资和部门名称。
/* 第一步:最大薪资 */
select max(sal) from emp where dept_id=30 ;
/* 第二步:加入条件 */
select max(sal) from emp where dept_id=(select id from dept where name='大数据部') ;
/* 第三步:添加需求 */ /* 关联查询 */
select emp.name , emp.sal , dept.name from emp left join dept
on emp.dept_id=dept.id
where sal > (select max(sal) from emp where dept_id=(select id from dept where name='大数据部') );
/* 错误 */
select emp.name , emp.sal , dept.name from emp , dept
where emp.dept_id=dept.id;
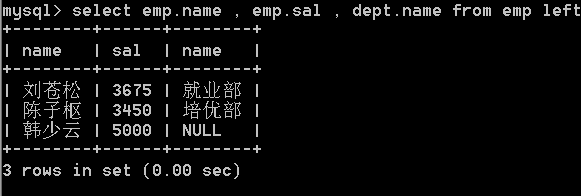
1.9.5 多表查询练习
48.列出在’培优部’任职的员工,假定不知道’培优部’的部门编号, 显示部门名称,员工名称。
– 关联查询两张表
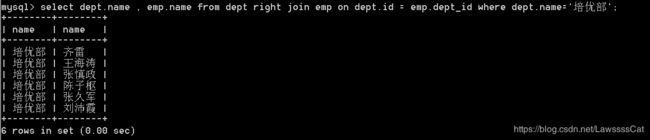
select dept.name , emp.name from dept right join emp
on dept.id = emp.dept_id;
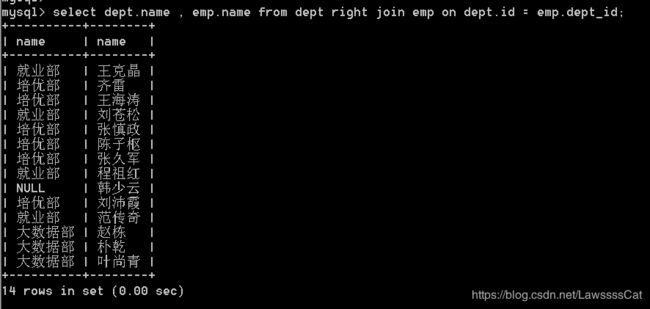
– 求出在培优部的员工
select dept.name , emp.name from dept right join emp
on dept.id = emp.dept_id
where dept.name='培优部';
49.(自查询)列出所有员工及其直接上级,显示员工姓名、上级编号,上级姓名
自查询
step1 : 起别名
/*
emp e1 表示员工表
emp e2 表示上级表
关联条件:
e1.topid=e2.id;
*/
select e1.name , e1.topid , e2.name
from emp e1 , emp e2
where e1.topid = e2.id
order by e1.topid;
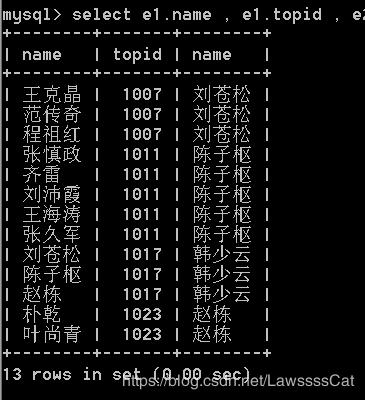
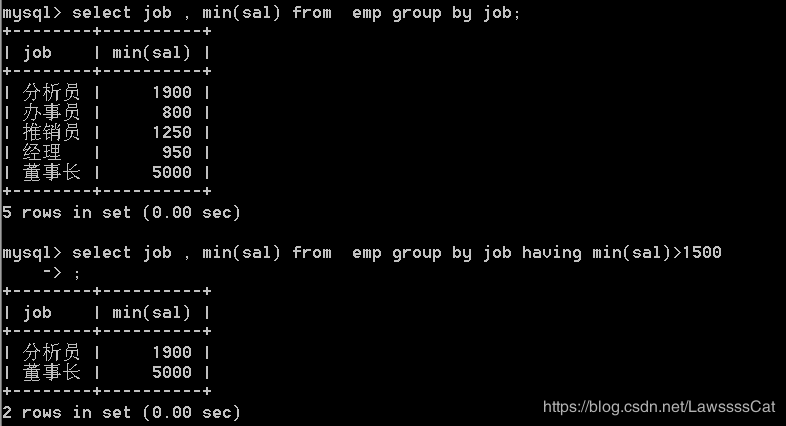
50.列出最低薪资大于1500的各种职位,显示职位和该职位最低薪资
/* 根据职位进行分组() , 求每个职位(组)的最低薪资 */
select job , min(sal) from emp group by job;
/* having 分组后判断 */
select job , min(sal) from emp group by job
having min(sal)>1500;
∗ ∗ 扩 展 内 容 − h a v i n g ∗ ∗ \color{#ff0011}{** 扩展内容 - having **} ∗∗扩展内容−having∗∗
where 和 having 都可以用于筛选过滤,其区别在于:
- where 是在分组之前进行筛选过滤,而且 where 中不能使用列别名和聚合函数
- having 是在分组之后进行筛选过滤,having 中可以使用列别名和聚合函数。
51.列出在每个部门就职的员工数量、平均工资。显示部门编号、员工数量,平均薪资。
select dept_id as '部门编号' , count(*) as '员工数量' , avg(emp.sal) as '平均薪资' from emp
group by dept_id ;

52.查出至少有一个员工的部门,显示部门编号、部门名称、部门位置、部门人数。
select dept.id , dept.name , dept.loc , count(*) from dept, emp
where dept.id=emp.dept_id
group by emp.dept_id;

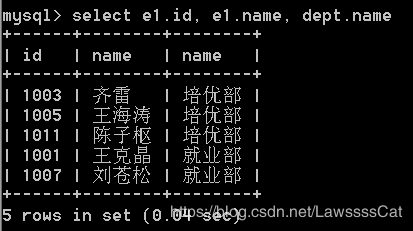
53.列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。
/*
emp e1 下级
emp e2 上级
显示的列:
查询的表:
关联条件:
筛选条件:
*/
select e1.id, e1.name, dept.name
from emp e1 , emp e2 , dept
where e1.topid=e2.id and e1.hdate<e2.hdate and e1.dept_id=dept.id;
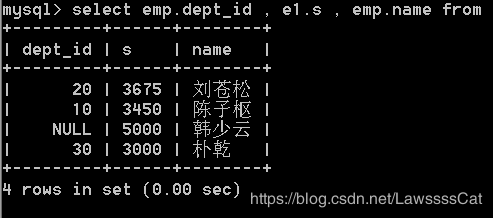
54.列出每个部门薪资最高的员工信息,显示部门编号、员工姓名、薪资
/*
显示:emp.dept_id , emp.name , emp.sal
分组:dept_id
(在组里面)
条件:sal = max(sal)
*/
select dept_id , name , sal from emp order by dept_id ;
/* 先找出最高工资 */
select dept_id , max(sal) from emp
group by dept_id ;
select emp.dept_id , e1.s , emp.name
from emp , (select dept_id , max(sal) as s from emp
group by dept_id) e1
where ifnull(emp.dept_id,0)=ifnull(e1.dept_id,0) and emp.sal=e1.s;
文章目录
- 1.1数据库概述
- 1.1.1什么是数据库?
- 1.1.2什么是 关 系 型 数 据 库 \color{#ff0011}{关系型数据库} 关系型数据库?
- 1.1.3数据库 相 关 概 念 \color{#ff0011}{相关概念} 相关概念
- 1.1.4 1.1.4什么是SQL语言?
- 1.2连接mysql服务器
- 1、 连 接 m y s q l 服 务 器 : \color{#ff0011}{连接mysql服务器:} 连接mysql服务器:
- 2、 连 接 \color{#ff0011}{连接} 连接mysql服务器并 指 定 I P 和 端 口 \color{#ff0011}{指定IP和端口} 指定IP和端口:
- 3、 退 出 客 户 端 \color{#ff0011}{退出客户端} 退出客户端命令:quit或exit或 \q或Ctrl+c
- 4、FAQ:常见问题:
- 1.3 数 据 库 \color{#ff0011}{数据库} 数据库及表操作
- 1.3.1 创建、删除、查看数据库
- 1. 查 看 \color{#ff0011}{查看} 查看mysql服务器中所有 数 据 库 \color{#ff0011}{数据库} 数据库
- 2. 进 入 \color{#ff0011}{进入} 进入某一 数 据 库 \color{#ff0011}{数据库} 数据库
- 03. 查 看 \color{#ff0011}{查看} 查看当前数据库中的所有 表 \color{#ff0011}{表} 表
- 04. 删 除 \color{#ff0011}{删除} 删除mydb1 数 据 库 \color{#ff0011}{数据库} 数据库
- 05.重新 创 建 \color{#ff0011}{创建} 创建mydb1 数 据 库 \color{#ff0011}{数据库} 数据库, 指 定 编 码 \color{#ff0011}{指定编码} 指定编码为utf8
- 06. 查 看 建 库 时 的 语 句 \color{#ff0011}{查看建库时的语句} 查看建库时的语句(并验证数据库库使用的编码)
- 1.3.2 创建、删除、查看 表 \color{#ff0011}{表} 表
- 07.进入mydb1库, 删 除 \color{#ff0011}{删除} 删除stu学生 表 \color{#ff0011}{表} 表(如果存在)
- 08. 创 建 \color{#ff0011}{创建} 创建stu学生 表 \color{#ff0011}{表} 表
- 09. 查 看 \color{#ff0011}{查看} 查看stu学生 表 \color{#ff0011}{表} 表结构
- 查 看 \color{#ff0011}{查看} 查看, 建 表 时 的 语 句 \color{#ff0011}{建表时的语句} 建表时的语句
- 1.4 新增、更新、删除表 记 录 \color{#ff0011}{记录}