IAAA 2018| Improving Review Representations with User and Product Attention Sentiment Classification
最近有一个计划——40篇论文储备计划,是老班要求的。有的解读可能会放上来,有的不会。同时会把论文的地址放出来,希望能传播一些好文章吧~
论文名称:Improving Review Representations with User Attention and Product Attention for Sentiment Classification
论文链接:https://arxiv.org/abs/1801.07861

Improving Review Representations with User Attention and Product Attention for Sentiment Classification
- Abstract
- Introduction
- Background
- LSTM
- Attention Mechanism
- Document-level Sentiment Classification
- Method/Model
- Hierarchical User Attention
- Hierarchical Product Attention
- Combined Strategy
- Experiments
- Experiments Settings
- Baselines
- Model Analysis: Effect of User Attention and Product Attention
- Model Analysis: Effect of the Different Weighted Loss
- Conclusion
Abstract
神经网络方法在情感分类中取得了巨大的成功。最近,一些工作通过结合用户和产品信息来生成评论表示,在分类结果上取得了一些进步。但是通过观察,发现在用户评论中,有一些句子或是词表示了很强的用户个人看法,也有一些句子或是词表示了产品的相关特性。在直觉上,这两种不同的信息在情感分类中起到了不同的作用。因此,将这两种信息结合在一起来编码来形成一种表示是不太合理的。
在本文中,作者提供了一种全新的框架来编码用户信息和产品信息。首先,应用了两种独立的遗传神经网络来生成两种不同的表示;然后,设计了一种将这两种表示结合在一起的策略,以便之后进行最终的训练和预测。
在IMDB和Yelp数据集上的实验证明了这种方法性能好于目前的最新方法,并且通过可视化的方法来给出一些词与用户或是产品的相关性,证明了文中方法的有效性。
Introduction
随着在线评论网站如Amazon,Yelp,IMDB的快速增长,情感分析引起了研究者和工业界的重视。在这篇文章中,作者的工作关注了Document-level的情感分类问题。
尽管神经网络在情感分类中十分有效,但是前人的一些工作主要关注了文本相关,但是忽略了用户和产品信息的重要影响。用户的喜好和产品的特性对于评分有着重要的影响。对于不同的用户,同样的词可能表示了不同了意思,比如一个宽容的用户可能会使用“good”来评价一个正常的产品,但是一个苛刻的用户可能会使用“good”来表达非常棒的意思。同样的,产品特性也会对评论分数产生影响,一个好的产品评分肯定比一个坏的产品分数高。
为了将用户信息和产品信息在情感分类中加以运用,前人的一些工作有:
- [Tang, Qin, and Liu 2015b] Tang, D.; Qin, B.; and Liu, T. 2015b. Learning semantic representations of users and products
for document level sentiment classification.引入word-level的偏好矩阵,表示用户和产品的向量,使用CNN来进行分类。但是模型复杂度太高,只考虑了word-level,没有考虑的semantic-level - [Chen et al. 2016a] Chen, H.; Sun, M.; Tu, C.; Lin, Y.; and Liu, Z. 2016a. Neural sentiment classification with user and product attention.在一个句子中引入注意机制,但是将用户信息和产品信息放在一起考虑了,丢失了一些信息
在本文中,针对之前研究中的问题,作者应用了两种独立的遗传神经网络来生成两种不同的表示;然后,设计了一种将这两种表示结合在一起的策略,以便之后进行最终的训练和预测。
本文的主要贡献:
- 提出了一个全新的框架来从两个角度来编码用户评论。分别使用了用户注意机制和产品注意机制生成了两种表示,之后将二者拼接在一起进行下一步分类。
- 为了更好的学习结果,引入了一个结合策略来提升表示。使用了带权的损失函数证明了两种角度都对分类效果有提升。
- 实验证明了本文中的模型比现有方法对分类结果有显著提升。
Background
LSTM
Attention Mechanism
Document-level Sentiment Classification
Method/Model
本节将介绍文中出现的模型——HUAPA
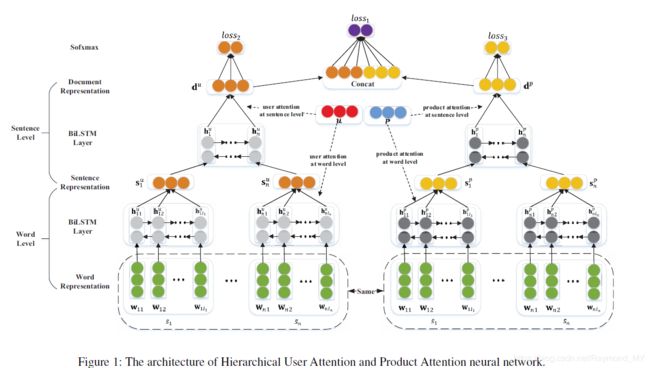
Hierarchical User Attention
从一个用户的角度来看,不是所有的词都同等意义上表现了用户的情感。为了突出一些重要的词,引入了用户注意机制来提取这些词。最终,一个句子的表示将会聚集这些重要的词。一个增强型的用户角度表示的句子公式如下
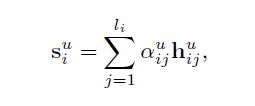
其中, h i j u h^u_{ij} hiju表示第i个句子的第j个词的隐藏状态, α i j u \alpha^u_{ij} αiju是对 h i j u h^u_{ij} hiju的注意力权值,描述了第j个词对于当前用户的重要程度。作者将每个用户都映射到一个连续的向量u中,这里 u ∈ R d u u \in R^{d_u} u∈Rdu, d u d_u du表示了用户向量的维度。对于每个隐藏状态的权值 α i j u \alpha^u_{ij} αiju计算如下
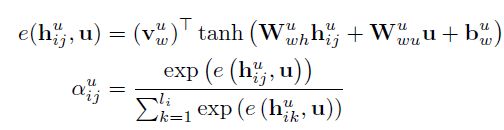
其中, v w u v^u_w vwu是一个权值向量, W w h u W^u_{wh} Wwhu和 W w u u W^u_{wu} Wwuu是权值矩阵。 e ( ) e( ) e()函数用于对一个词的重要性进行评估。
前面我们看到的是word级别的,而在作者的目标是形成一个文档级别的分类效果,所以还有句子级别的扩展如下:
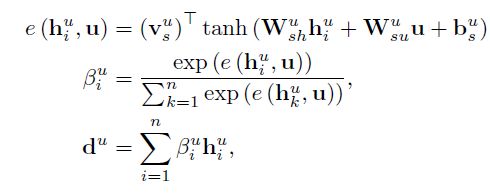
其中, h i u h^u_{i} hiu表示第i个句子在评论中的隐藏状态, β i u \beta^u_{i} βiu是对 h i u h^u_{i} hiu的注意力权值,描述了第i个句子对于当前用户的重要程度,计算方法同上所述。
Hierarchical Product Attention
这里的模型和上面的用户角度完全一样,唯一区别就是分开训练,预先设定的参数不同。
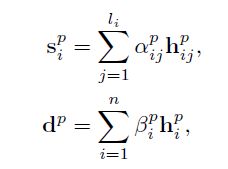
其中, α i j p \alpha^p_{ij} αijp是对 h i j p h^p_{ij} hijp在单词级别上的权重, β i p \beta^p_{i} βip是对 h i u h^u_{i} hiu在句子级别上的权重。
Combined Strategy
为了充分利用之前生成的用户角度和产品角度信息,需要考虑将两个表示结合起来形成一个最终的表示。
![]()
使用了一个线性的softmax来输出预测结果
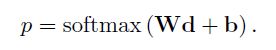
在本模型中,使用交叉熵损失函数cross-entropy error来描述预测值和真实值之间的损失
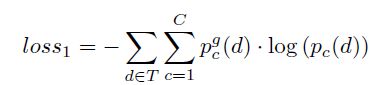
其中, p c g p^g_c pcg表示了情感标签c的可能性的真实值,0或是1, T T T是训练集的大小。
同理,对于两个角度的损失函数,同样有下面的式子
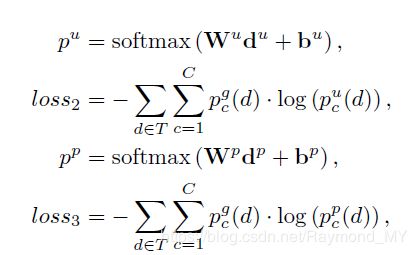
之后,我们定义总的损失函数 L L L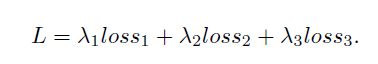
通过改变不同的权值,可以得到不同的训练效果。
Experiments
Experiments Settings
使用的数据集:IMDB,Yelp Dataset Challenge in 2013 and 2014.数据集划分是80%训练集,10%验证集,10%测试集。
使用 A c c u r a c y Accuracy Accuracy来衡量准确率, R M S E RMSE RMSE即标准差来衡量偏差程度。
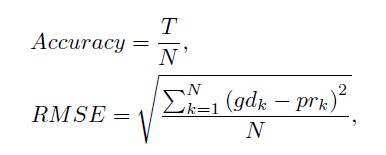
其中, T T T是预测正确的数目 N N N是样本总数 g d k gd_k gdk表示正确的标签 p r k pr_k prk表示预测的标签
具体的设置:
- 在每个数据集上预先训练了200维的词向量SkipGram(Word2Vec的一种)对用户角度和产品角度使用了相同的词向量。
- 设定用户的代表向量为200维,是从均匀分布 U ( − 0.01 , 0.01 ) U(-0.01,0.01) U(−0.01,0.01)中随机初始化而成的。
- LSTM的隐藏层维度为100维,这样BiLSTM的输出就是200维。
- 为了加速学习进程,评论文本不超过40句,每句不多于50个单词。
- 使用了Adam算法来更新参数,初始学习率设定为0.005.
- 没有使用正则化或是随机失活方法来提升模型表现
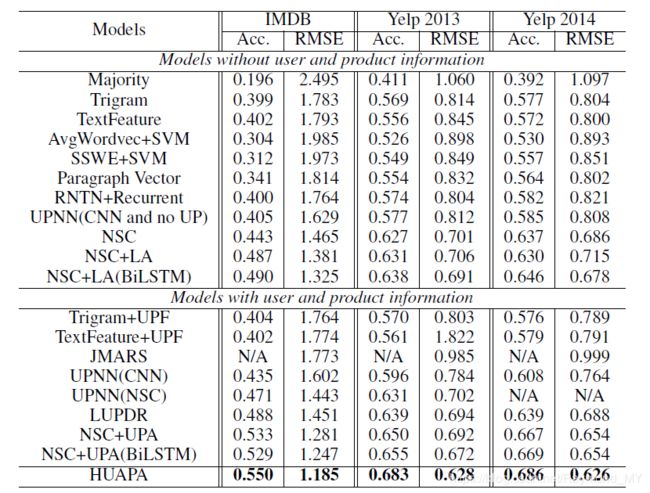
Baselines
Model Analysis: Effect of User Attention and Product Attention
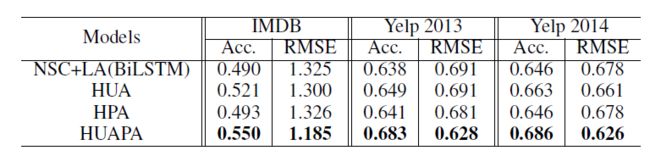
为了研究用户角度和产品角度的影响,作者从还分别建立了两个模型。HUA是用户角度,HPA是产品角度。上图中展现了它们的效果,从上图中,我们可以发现:
- 通过与未使用注意力机制的最好方法NSC+LA(BiLSTM)比较,发现无论是HUA还是HPA都有一些提升,这证明了引入注意力机制是合理的。
- 从HUA和HPA的对比中可以发现,用户角度有更好的效果。可以这样思考,尽管产品各有各的特性,但是打分还是用户主观性较强的。所以用户角度的表现会更好。
- 从HUAPA和HUA/HPA的比较可以发现,结合了用户和产品角度的结果比单个角度的结果要好。这证明了模型中的注意力机制确实可以找到用户的喜爱和产品的特性。
Model Analysis: Effect of the Different Weighted Loss
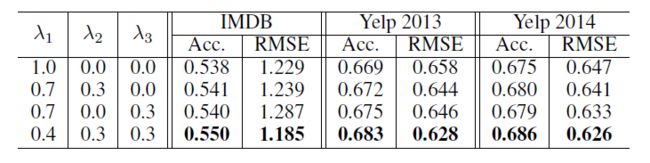
λ 1 , λ 2 , λ 3 \lambda_1,\lambda_2,\lambda_3 λ1,λ2,λ3 分别是损失函数分量 l o s s 1 , l o s s 2 , l o s s 3 loss_1,loss_2,loss_3 loss1,loss2,loss3的权重。通过设置权重,可以调整侧重的角度。上表中给出了权重不同时的一些表现。从上图中,可以发现:
- 和现有方法比较,在没有 l o s s 2 , l o s s 3 loss_2,loss_3 loss2,loss3参与的情况下,模型仍能取得较好的效果。
- 在有 l o s s 2 , l o s s 3 loss_2,loss_3 loss2,loss3参与的情况下,模型可以取得更好的效果。
Conclusion
在本文中,作者提供了一种全新的框架来编码用户信息和产品信息。首先,应用了两种独立的遗传神经网络来生成两种不同的表示;然后,设计了一种将这两种表示结合在一起的策略,以便之后进行最终的训练和预测。实验结果表明了这种模型比现有方法有明显的进步。