Jmeter5.0 抢红包并发操作案例
-
环境搭建
Java下载地址:
https://www.oracle.com/technetwork/java/javase/downloads/index.html
JMeter是基于java的开发的工具,因此需要使用JMeter必须要安装java。
JMeter下载地址:
http://jmeter.apache.org/download_jmeter.cgi
mysql-connector-java-version(版本号).jar下载地址:
https://mvnrepository.com/artifact/mysql/mysql-connector-java
jar是maven仓库里的JDBC(Java DataBase Connectivity)驱动,需要该驱动才可以正常通过JDBC来连接mysql的数据库
JMeter在打开页面的【Options】-【Choose language】-【Chinese(simplified)】可以进行汉化操作。(但是该操作是一次性的,每次重新打开又默认了英文)
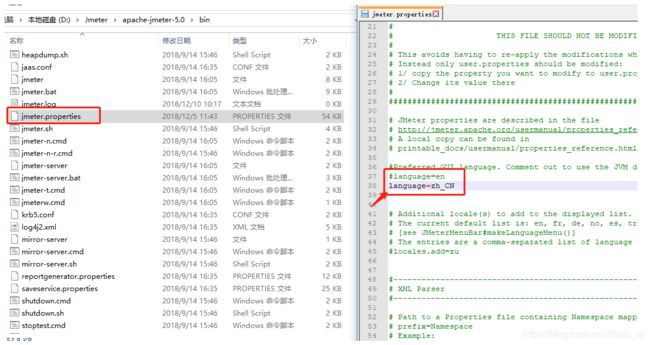
JMeter打开后默认汉化操作:
在bin文件夹找到jmeter.properties打开后,在#language=en 的下一行加入language=zh_CN 保存即可。
打开Jmeter,在bin文件下找到jmeter.bat。点击即可打开:
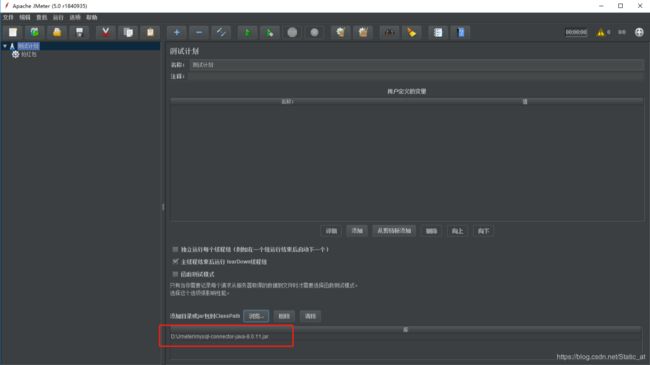
若需要连接mysql数据库,则需要装驱动,装好驱动之后,如下图,浏览导进jar的驱动包:
(每个mysql版本不一样对应的驱动不一样,下载驱动地址请见文中头部)
1. 创建线程组【线程(用户)--线程组】
打开后即可看到一个测试计划,在测试计划右键可以创建一个线程组,

线程组 各常用字段解析:

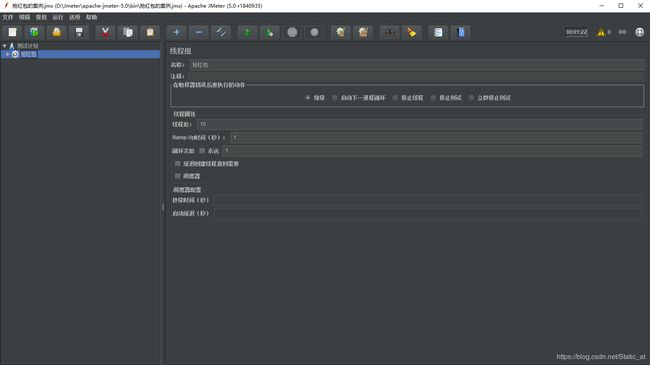
名称:给线程去名称,例如:抢红包
注释:对该线程的作用进行描述
在取样器错误后要执行的动作:一个线程里(Sample)取样器可能存在多个,就是错误时的处理,参考字面意思。
线程数: 可以理解为执行的用户数。例如设置10则10个用户去运行
Ramp-Up时间:所有用户跑完线程的总时长,单位为秒。例设置1 则1s运行完10个用户
循环次数:用户数的循环运行次数。 把永远打钩就一直循环
调度器配置: 当循环次数勾选永远时,可以通过调度器配置时间来限制在哪一个时段运行。
2. 配置JDBC Connection Connection Configuration【线程组右键—添加—配置元件--JDBC Connection Connection Configuration】
JDBC(Java DataBase Connectivity)是用来与咱们数据库做连接的配置,我们需要配置JDBC来连接到数据库,才能从数据库里取得相关的数据,并设置为变量。
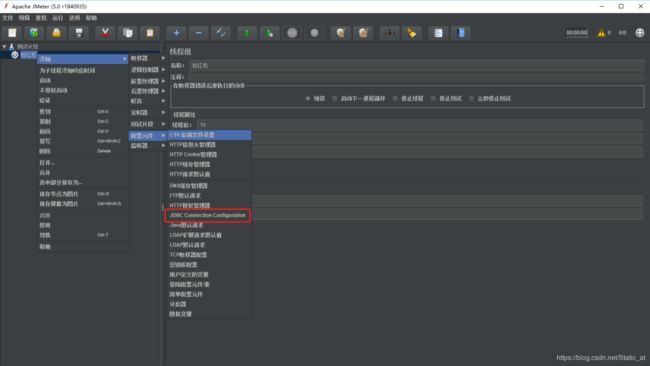
而连接数据库的前置条件时需要拿到相关数据库的驱动,才可以正常取连接数据库的数据,那么在测试计划的jar包已加入mysql-conncetor-java-8.0.11.jar后即可正常驱动。
(我的mysql版本为5.7.24) 查版本语句:select version();
以下为JDBC Connection Configuration 各常用字段解析:

Variable Name for created pool:变量名称,这个是一定要填写,后面使用JDBC request时,根据这个变量名来找对应的配置。JDBC request设置Variable name时要与该变量名一致。
Connection Pool Contiguration
Max Number of Connections:最大连接数(数据库)这里默认设置为0,表示这个数据库的连接池只提供给该线程使用。
Max Wait(ms):连接池取回连接最大等待时间。这里默认时10000ms则10s内如果拿不到数据则会报错。
……….中间一部分参数有兴趣查看:https://blog.csdn.net/u013258415/article/details/78316931
Database Connection Configuration:
Database URL:jdbc:mysql://ip:端口/数据库名称
(这个是连接mysql时的写法,jdbc:mysql://为固定格式,ip是数据库的连接地址,端口是数据库的端口,数据库名称是对应要连接的数据库名称)
JDBC Driver class: com.mysql.jdbc.Driver
驱动,连接mysql就是匹配该驱动。
Username: 连接数据库的账号
Password:连接数据库的密码
3. 配置JDBC Request【线程组右键--添加—取样器—JDBC Requset】
JDBC Request配合以上的JDBC Connection Configuration使用可以通过SQL语句拿到数据库中所需的数据并设置为变量
以下为JDBC Request 各常用字段解析:
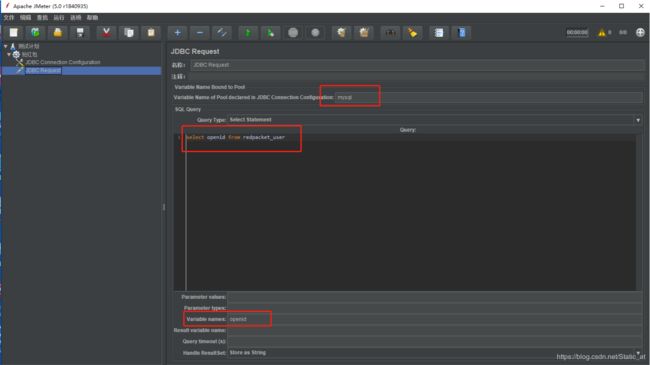
Variable Name of Pool declared in JDBC connection Configuration: mysql
(这个值是对应之前设置的Variable Name for created pool的值) 意思是连接到该数据库。

SQL Query
Query Type: Select Statement 默认的就是查询语句
在查询框输入你需要查询的SQL语句
Variable names: openid (这个是设置的变量值,根搜索出来的按顺序给变量值,若有两个字段,则给两个变量值,以英文逗号隔开即可,例如: name,psw)
设置了该变量后,如果要使用从数据库拿到的第一个数据则使用:openid_1
要使用第二条数据则使用:openid_2
那么问题来了,如果我想这个1,2,3每条数据都变成自动递增叠加怎么处理?请接着往下看吧。
4. 添加察看结果树【线程组右键--添加—监听器—察看结果树】
在查看结果树之前先来看看以下的几个按钮:

![]() 表示运行线程组
表示运行线程组
![]() 单个的扫帚表示清除所选的某个请求数据,两个扫帚的表示清除掉所有的请求。
单个的扫帚表示清除所选的某个请求数据,两个扫帚的表示清除掉所有的请求。
那么在察看结果树之前,需要运行后才有结果。
察看结果树 各常用字段解析:
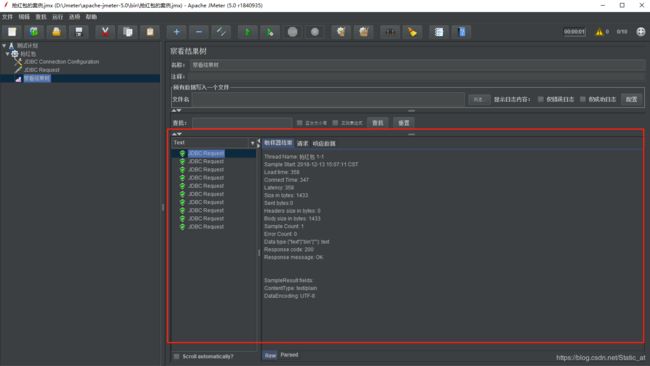
主要看框出来这一部分内容:
Text 是以文本类型展示结果。还可以选择其他的类型
JDBC Request 一共是10个请求,因为我们设置线程组的时候,设置的线程数为10,所以会有10条请求。
点击其中一条请求,右边会出现取样器结果,请求,响应数据。
取样器结果: 服务器返回的一些消息
请求(Request Body):这里是SQL的语句,这个一般是查看HTTP请求请求参数是否正确。
(Request Headers) 响应头部

响应数据(Request Body):为请求数据库时返回的信息。这个一般查看服务器或数据库返回的信息。
(Request Headers) 响应头部

除此之外,也可以通过表格查看结果
【用表格查看结果】 【线程组右键--添加—监听器—用表格察看结果】
以下为【用表格察看结果】 各字段解析
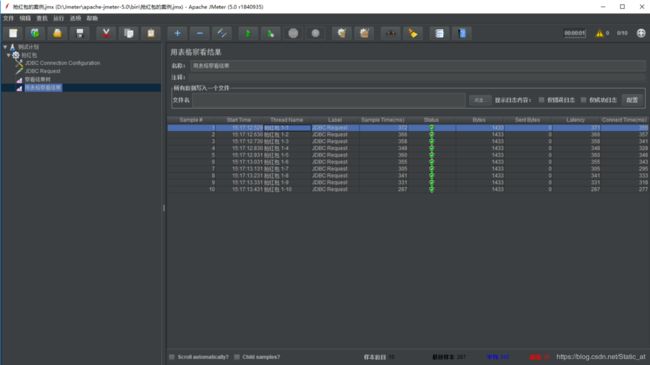
Sample# 序列号,线程用户有几个序列号就会有几个
Start Time 用户进入开始的时间,精确到毫秒
Thread Name 线程名称,每个用户有对应的线程名称
Label HTTP请求的名称
Sampler Time 运行这个用户所花的时间。单位为毫秒
Status 运行的状态,正常的就是安全符号,异常就是打X
Bytes 请求响应的文件大小
Send Bytes 发送请求的数据包大小
Latency 延迟时间
Connect Time 连接到服务器消耗的时间
那么一共能在数据库中请求到多少条数据,我们可以添加一个Debug Sampler来去查看。
【线程组右键—添加—取样器—Debug Sampler】 (要是不用了也可以右键禁用)
如下图,一共能拿到数据库中的50条数据。

5. 添加计数器【线程组右键—添加—配置元件—计数器】
计数器是为了让第三步骤中的openid_1, openid_2, openid_3的中的1,2,3数据进行自动叠加,设置为变量,以参数的形式进行传输。
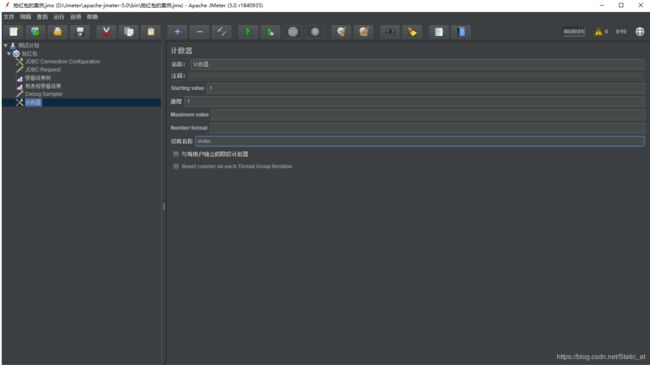
Starting value: 开始迭代的数值 设置为1则是以数据库的第1个值开始取
递增: 设置为1 则是在每次迭代后给计数器数值+1
Maximum value:最大值,如果超过最大值,则重新设置为开始迭代的数值,默认的最大值为263-1
Number format:数值格式,默认的话为0。若你给01的话 格式就是01,02,03
引用名称:这里就是设置一个变量,要用到计数器时,可以用这个变量去代替。例如我这里设置的是index,那么使用格式就为:${index}
(那么我们有计数器了 上面原先的值是openid_1,opened_2,opened_3则可以使用openid_${index}来代替了,目前这里就实现了数值自动叠加计算,但是你以为这样就可以使用了吗?不,除了迭代起来,还需要使用_V函数来始得迭代的变量值是可用的。请继续看下文的_V函数设置迭代变量)
6. 函数助手中的__V函数使用【选项—函数助手对话框】
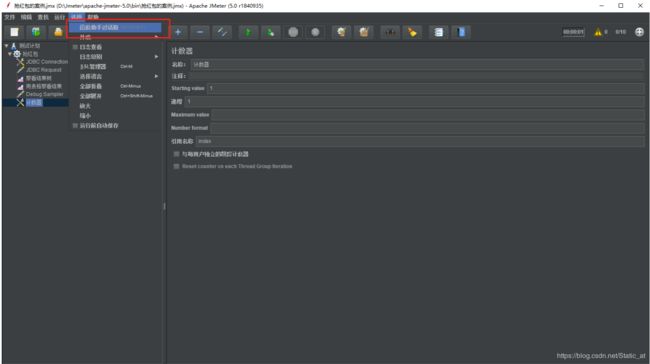
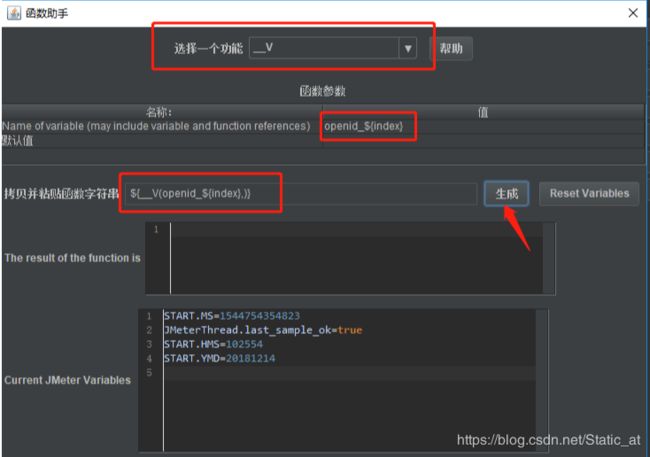
各函数功能可参考 http://www.cnblogs.com/imyalost/p/6802173.html
选择一个功能 选择__V
函数参数:
Name of variable(may include variable and function references) 值就是填写JDBC Connection Configuration里的变量名称_${计数器设置的变量名称},即填写 openid_${index}
然后点击生成:${__V(openid_${index},)}
生成后,先拷贝这个变量。这个变量也就是会去把数据库中的所有openid依次进行代入。
很多时候,我们未登陆时是无法去抢红包的,很多时候抢红包的接口都需要在请求的头部带token,而这个token往往是登陆的时候才会获取到,因此token的话需要使用正则表达式去拿,再设置为变量。这一块暂时不深究,因为目前公司的token是用的openid,这样的话会省去很多的步骤,但是这样也会存在安全隐患,后期要是有随机token产生,再研究这一块的内容。以下内容则是以token=openid进行演示
7. 添加HTTP信息头管理器【线程组右键—添加—配置元件—HTTP信息管理器】
HTTP信息头管理器,这个是用来放请求头部信息需要携带的内容,比如:token,cookie等。
那么以token=openid为例的话:

添加—>名称为 token
值:${__V(openid_${index},)} (这里会遍历数据库的每一个openid)
若HTTP请求头部还有其他信息,可以继续点击添加。输入对应的名称和值即可。
8. 添加HTTP请求 【线程组右键—添加—取样器—HTTP请求】
以下为【HTTP请求】 各常用字段解析

名称:默认是HTTP请求,当然最好取一个见名知意的名称。(其他HTTP信息管理头,计数器以及以上所有的等都可以改一个见名知意的名称)
注释:不解释
Web服务器
协议: 一般是http 和 https (似乎不填也不影响)
服务器名称或IP : 请求目标服务器名称或IP地址
端口号: 目标服务器的端口号,默认值是80
方法:http的请求方法 常用的有GET、POST
路径:请求的接口指定路径
内容编码:表示可支持的编码内容 例如 utf-8
参数:GET请求传参时,点击添加,把参数名填写在名称列,把对应参数值填写在值列。多个参数时,添加多个即可。
例如:这里的openid是以变量的形式传入,也就是依次从数据库拿到的openid。
而两一个则是红包的id,这个红包的id也可以通过数据库去获取,直接拿到该红包的id,然后拷贝进去即可。
9. 添加聚合报告【线程组右键—添加—监听器—聚合报告】
以下是运行后的结果:
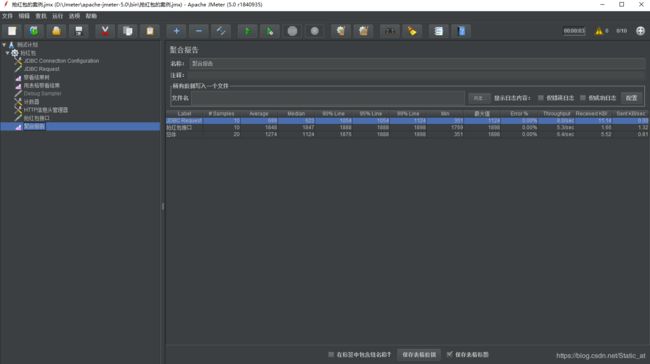
Average : 运行所有用户所花的平均时间,单位为毫秒
Median: 中位数,表示50%用户的响应时间小于多少毫秒
90% 95% 99% Line: 意思同上同上。
Min /Max: 运行所有用户中的消耗时间最小/大的
Error% : 错误事务率
Throughtput : tps吞吐量,表示每秒完成的请求数
KB/Sec : 每秒从服务器接收到的数据量
10. 导出测试报告(cmd导出测试报告)
cmd 进入到jmeter的bin目录,输入以下命令:
jmeter -n -t D:\Jmeter\apache-jmeter-5.0\bin\抢红包的案例.jmx -l C:\Users\DELL\Desktop\抢红包.log -e -o C:\Users\DELL\Desktop\抢红包Report
命令中参数详解:
-n 全称 non-gui模式,非界面模式运行
-t 全称 testfile 需要运行的测试文件脚本
-l 全称 logfile 需要保存的log文件路径
-e 生成报告文件
-o 保存报告的地址
分别有三个路径。第一个路径是我们运行.jmx,也就是我们保存好的案例的路径,第二个路径是存储运行时的保存日志文件路径,第三个路径是导出测试报告保存的文件夹路径
运行完之后桌面会生成一个log文件和一个报告的文件夹

进入抢红包Report文件夹:
点击index.html即可看到测试报告:
