在 AAAI 2018 接收论文列表中,来自阿尔伯塔大学强化学习和人工智能实验室 Richard S. Sutton 等研究者的一篇论文提出一种新的多步动作价值算法 Q(σ),该算法结合已有的时序差分算法,可带来更好性能。机器之心对此论文做了简要介绍,更多详细内容请查看原文。
时序差分(TD, Sutton, 1988)法是强化学习中的一个重要概念,结合了蒙特卡洛和动态规划法。TD 允许在缺少环境动态模型的情况下从原始经验中直接进行学习,这一点与蒙特卡洛方法类似;同时也允许在最终结果未出来时基于其他学得的评估更新评估结果,与动态规划法类似。TD 法的核心概念提供一个构建多种强大算法的灵活框架,这些算法可用于预测和控制。
TD(λ) 算法结合一步 TD 学习(one-step TD learning)和蒙特卡洛方法(Sutton, 1988)。通过使用 eligibility trace 和 trace-decay 参数,λ ∈ [0, 1],创建了一系列算法。当λ = 1 时,就是蒙特卡洛方法,λ = 0 时,就是一步 TD 学习。
人们通常认为多步 TD 方法是多个不同长度步长的收益平均值,通常与 eligibility trace 有关,和 TD(λ) 一样。但是,也可以认为它们是相关的 n 步备份的第 n 步收益(Sutton & Barto, 1998)。
Q(σ) 是 Sutton 和 Barto 2017 年提出的算法,该算法结合和推广了现有的多步 TD 控制方法。该算法执行的采样程度由采样参数 σ 控制。当 σ = 1 时出现 Sarsa(全采样),当 σ = 0 时出现树备份(Tree-backup,纯粹预期)。σ 的中间值构建的算法既有采样也有预期。这篇论文展示了 σ 的中间值构建的算法优于 σ 等于 0 或 1 时的算法。此外,研究者还展示了 σ 可以进行动态调整,以输出更好的性能。研究者将对 Q(σ) 的讨论限制在没有 eligibility trace 的 atomic 多步情况,但是使用复合备份(compound backup)是其自然扩展,也是未来研究的方向。Q(σ) 通常可用于在策略和离策略学习,但是该论文中的初始实验仅研究在策略预测和控制问题。
论文:Multi-step Reinforcement Learning: A Unifying Algorithm

论文链接:https://arxiv.org/abs/1703.01327
摘要:结合看似完全不同的算法来生成性能更好的算法是强化学习的长久以来的目标。作为主要示例,TD(λ) 使用 eligibility trace 和 trace-decay 参数 λ 将一步 TD 预测和蒙特卡洛方法结合起来。目前,有大量算法可用于执行 TD 控制,包括 Sarsa、Q-learning 和 Expected Sarsa。这些方法通常用于一步的情况中,但是它们可以扩展到多步以达到更好的性能。其中每一个算法都是针对不同任务的特定算法,没有一个在所有问题上优于其他算法。本论文研究一种新的多步动作价值算法 Q(σ),该算法结合和推广了这些已有算法,并对它们进行子求和(subsuming)作为特殊案例。新参数 σ 被引入作为算法每一步执行的采样程度,其备份不断改变,当 σ = 1 时出现 Sarsa(全采样),当 σ = 0 时出现 Expected Sarsa(纯粹预期)。Q(σ) 通常可用于在策略(on-policy)和离策略(off-policy)学习,但是本论文主要关注在策略的情况。实验结果显示 σ 的中间值会带来现有算法的混合,性能优于 σ 在两级的情况。该混合可以动态调整,带来更好的性能。
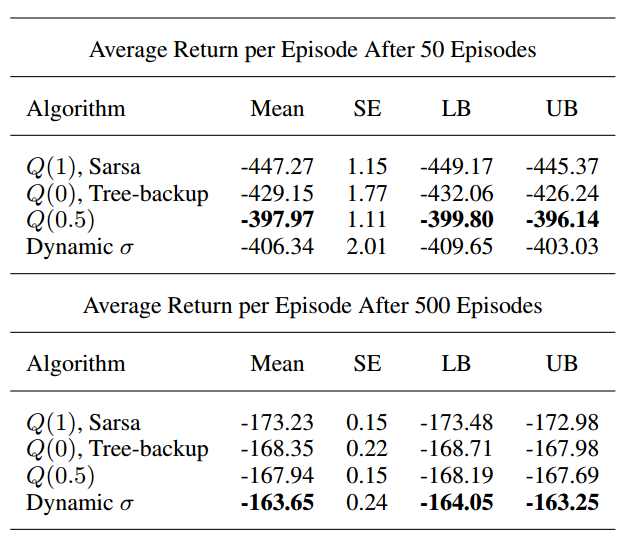
可视化备份操作的常见方式是使用备份图示,如图 1 所示。
图 1. atomic 4 步 Sarsa、Expected Sarsa、Tree-backup 和 Q(σ) 的备份图示。我们可以看到 Q(σ) 基于 σ 的设置包含其他三种算法。
算法 1 展示了在策略 Q(σ) 的伪代码:

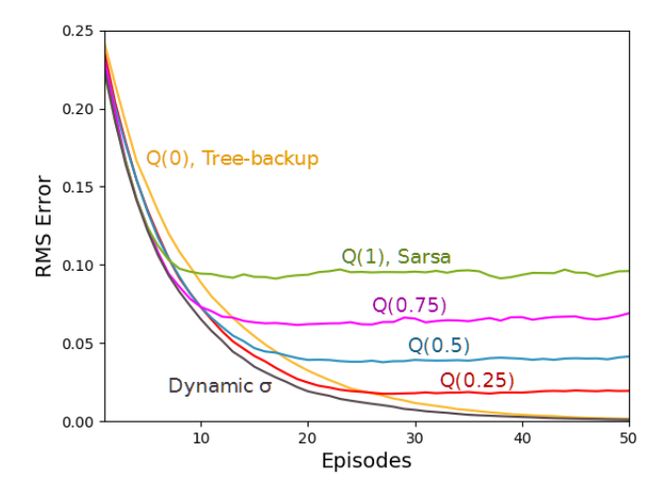
图 3. 带有 19 个状态的随机游走结果。上图从价值函数的 RMS 误差的角度展示了 Q(σ) 的性能。结果是 100 次运行的平均值,标准误差全部小于 0.006。Q(1) 具备最优初始性能,Q(0) 具备最优渐近性能,动态 σ 优于所有的固定 σ 值。

图 5. Stochastic windy gridworld 结果。上图通过对于不同 σ 值和α值的函数运行 100 episode 的平均收益展示了 Q(σ) 的性能。结果首先是选定 α 值的结果,然后是直线,之后是 1000 次运行的平均值。标准误差低于 0.05,差不多是线的宽度。4 步算法的性能优于 1 步算法,σ 为动态值的 Q(σ) 性能最好。
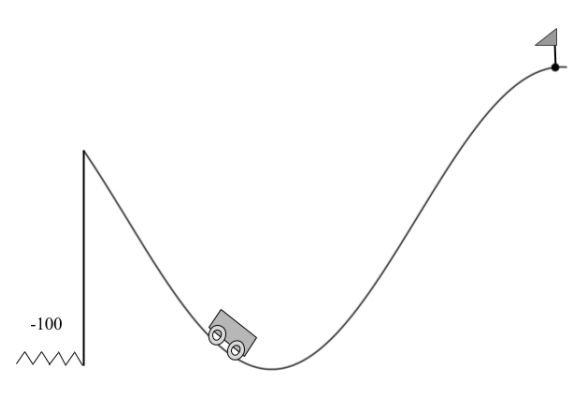
图 6. 山崖环境。智能体的目标是在不掉下山崖的前提下驶过小旗。该智能体每一个时间步收到的奖励为 -1,而掉下山崖就会在山谷的随机初始位置得到 -100 的奖励。
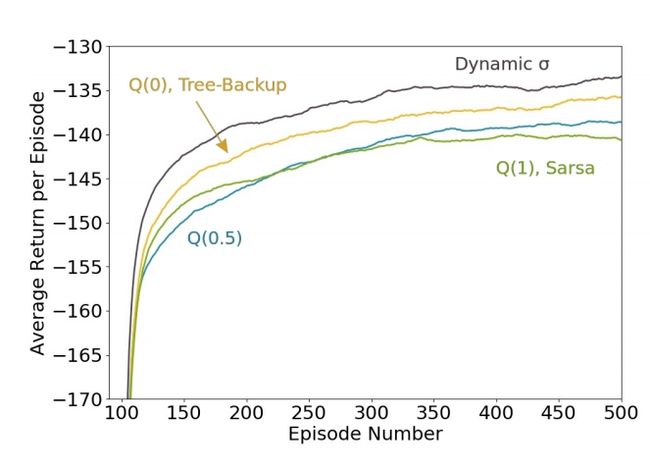
图 7:山崖结果。上图通过每个 episode 的平均回报展示了每个 atomic 多步算法的性能。为了平滑结果,采用了适当均值的移动平均数,其带有 100 个连续 episode 的窗口。σ 为动态值的 Q(σ) 性能最好。