大卫说:笔者在年初分享过一篇文章《大卫看Docker-第一篇》。文中介绍了Docker一些基本概念。本文同时作为《大卫看Docker-第二篇》而存在。
随着容器技术的兴起,越来越多的人都在关注这项技术。既然Docker是一项很不错的技术,如何将它应用到企业中呢?对此,红帽的提供了基于容器的、同时面向运维和开发的企业级开源PaaS解决方案。

此前文章已经提到过,红帽作为开源界的领导者,其所有企业级解决方案在社区都有对应的开源项目,openshift也不例外。2011年,Redhat启动了PaaS平台项目OpenShift。一年以后,Redhat宣布将OpenShiftOrigin项目开源。Origin既是PaaS平台OpenShift的开源代码库,也是其社区与项目的名称。
谈到OpenShift,必须提到另外两个开源项目:Atomic和Kubernetes。
AtomicProject
2014年,红帽启动Atomic项目。Atomic是一个用于运行Docker容器的原型系统。Atomic项目并不是为了构建另一个操作系统。Atomic项目的核心是一个软件包安装系统,即rpm-ostree。简单而言就是用容器运行操作系统内部的服务,提供容器化的Linux操作系统。
KubernetesProject
Kubernetes是Google和红帽发起的开源项目,它提供容器集群管理系统,其提供应用部署、维护、扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,功能很强大,谷歌每天用它管理20亿个容器。其主要功能有:
使用Docker对应用程序包装(package)、实例化(instantiate)、运行(run);
以集群的方式运行、管理跨机器的容器;
解决Docker跨机器容器之间的通讯问题;
Kubernetes的自我修复机制使得容器集群总是运行在用户期望的状态。
OpenShift的企业解决方案
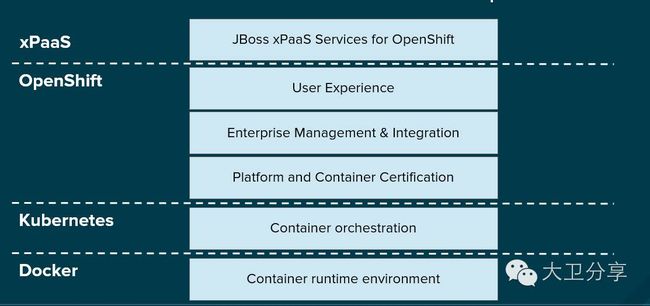
Docker的技术本身大家应该都比较熟悉了,不熟悉的同学可以参照笔者此前的文章《大卫看Docker第一篇》。Docker是一种容器的技术,有它的优势,也有其明显的劣势。比如缺乏持久化存储、高可用缺失、网络方面限制、容器的编排实现(弹性扩展等)等等,如果Docker想为企业生产所使用,这些问题必须都得到解决。
Kubernetes主要解决的是docker的编排部署问题,此外,提供了一定的运维能力。例如, Kubernetes可以控制Pod(容器的集合)的副本数,一个坏了,马上新生成一个,从而强制保证应用的高可用
OpenShift在Docker和Kubernetes之上,提供了持久化存储、企业内部registry、认证等功能,并增强了客户体验。Openshift的版本经历了1.0, 2.0等,目前最新的版本是3.2。
同时面向运维和开发的PaaS解决方案
通常PaaS解决方案主要是针对开发的。而红帽提供的OpenShift既面向运维,又面向开发。简而言之,OpenShift=容器云解决方案+应用管理解决方案(程序打包,管理)。OpenShift面向运维主要体现在能够保证Pod(包含一个或多个容器)中运行应用的高可用、实现Pod的编排部署、弹性伸缩等。
OpenShift面向开发主要体现在Source to Imagine(S2I)。OpenShift通过Image Streams跟踪imagine,实现从从源码到生产使用镜像进行***式打通,它大大缩短了客户应用开发的时间,从而帮助客户实现敏捷式开发。
由于篇幅有限,本文先着重介绍OpenStack本身的架构,S2I的内容会在随后的文章中介绍。
OpenShift的架构
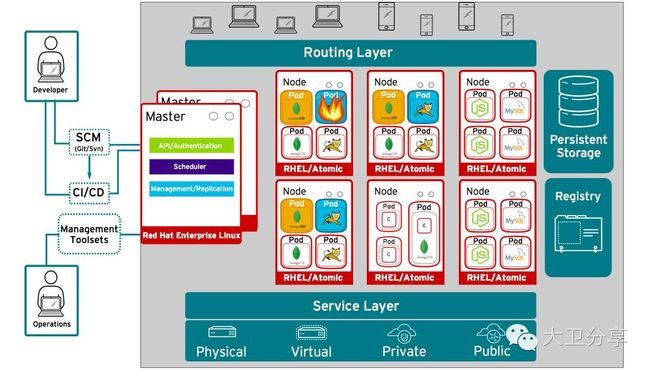
OpenShift内部几大组件: Master节点、Node节点、RoutingLayer、Service Layer、持久存储、Registry。
master是OpenShift集群的管理节点,它包含管理组件,如API Server,controller manager server, 和etcd。Master节点通过Node节点上的服务管理Node节点,管理Node节点的健康状态。在生产环境中,通常至少部署3个master节点。
Node节点提供容器的运行环境。每个Node节点都被Master管理。Node节点可以是物理机,也可以是虚拟机(当然需要安装RHEL),甚至可以是云环境。生产中,Node节点通常多余一个。
Service Layer负责不同Service之间通讯的。Service是Openshift中的一个客户应用,如Tomcat。
Routing layer:提供对外网服务。把外部的请求,路由到内部。
持久存储:为容器的数据盘提供持久存储。
Registry:企业内部镜像库。
在以上的概念中,Master和Node节点的概念相对好理解,前者负责管理,后者服务提供容器运行所依赖的资源。针对后几个概念,笔者用相对通俗的语言进行介绍。
Pod的意义
在OpenShift中,Pod是最小可管理单元。一个Pod包含一个或者多个容器。一个Pod中通常运行提供一个应用服务的一个或者多个容器。一个Pod只能在一个Node节点上,pod有自己的IP。多个Pod一起为一个应用提供服务,组成一个Service,它有一个Service IP。Service不同的pod可以运行在不同node上。
举个比较容易理解的例子:客户有一套三层的应用,Nginx/Tomcat/Msql。三层都放到容器里。其中,Tomcat和Mysql由于比较重要,需要设置两个副本,Nginx不需要设置副本。那么Pod如何划分比较好?
比较好的做法是,把Nginx,Tomcat,Mysql分成三个Pod。将后两个pod的副本数设置为2。这样,Tomcat,Mysql就会分别对应两个pod。
一般情况下,我们有强逻辑关系的容器放到一个pod里。比如,Tomcat的pod包含三个容器,一个负责运行tomcat,一个负责日志收集,一个负责健康检查,后两个容器为tomcat的正常运行提供辅助功能。这样,这个pod就是一个能够提供独立tomcat服务的一个单元,如果对其设置副本,只需要在本Node或者其他Node上运行第二个Pod即可,pod之间可以实现负载均衡。
Nginx,tomcat,mysql三个service之间的通讯,是通过service IP实现内部通讯。如果Nginx需要对外提供服务,那么就需要Routing layer的协助。Routing Layer也是一个pod,里面运行HAproxy。每个node节点上有一个Routing pod。HAproxy会获取到Pod的IP地址,并将应用对外提供的域名和80端口与Pod IP之对应起来。当对应关系建立起来以后,互联网请求访问域名时,请求就会直接链接到Pod IP上(如果一个应用有多个Pod,HAproxy胡会自动实现负载均衡),而不必再经过Service IP层。请记住,Service IP只负责Pod(一个或者多个node上)之间的通讯。
举一个例子,在实验环境中,有一个Master节点,一个Node节点,4个Service,每个Service都有自己的IP地址,我们主要关注bookstore-mysql这个service,它的IP是172.30.90.222。

登录到node节点上,通过iptables看service IP的指向:

bookstore-mysql的service IP指向172.25.6.11:52176,172.25.6.11是Node的本机IP。我么

可以看到,不同的service绑定Node IP不同的端口。
我们进一步查看一个Service IP和Pod IP的对应关系,以及Pod IP如何对外提供服务。
首先先查看一个名为bookstore的service。它的service IP是172.30.87.202。
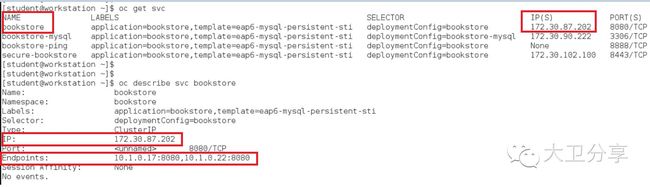
可以查看到,service ip后端对应的两个pod的IP,分别是10.1.0.17和10.1.0.22。
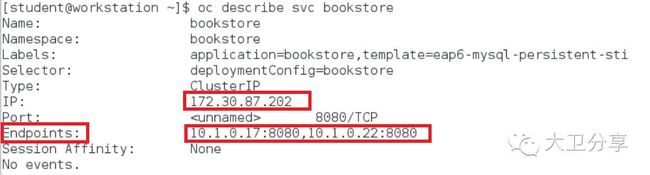
我们通过图形化界面,也可以看到两个pod的信息以及IP地址:
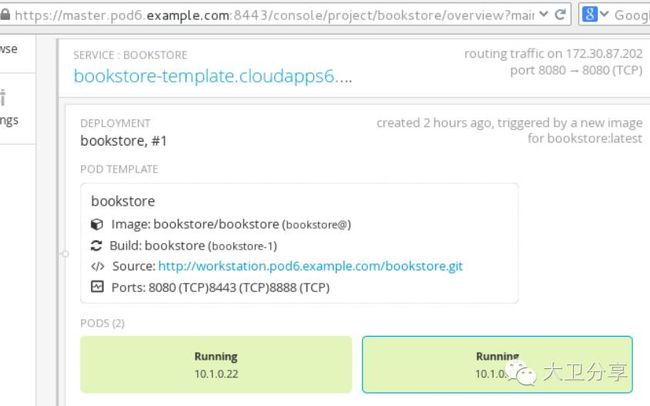
Routing Layer对域名查看
首先进入到routing对应的pod,查看HAproxy的配置文件(haproxy.conf),在配置文件中,最后部分是backend的对应地址,也就是pod的地址:

查看配置文件中前面的部分,可以查看/var/lib/haproxy/conf/os_http_be.map。该文件记录了Routing对外提供的域名。
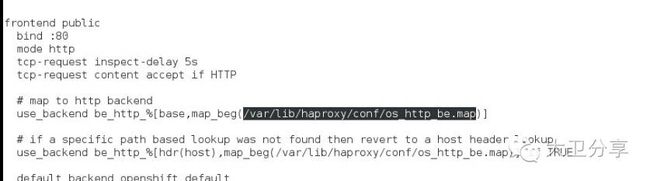
查看该配置文件,可以看到对外暴露的域名:
![]()
其中,bookstore-template.cloudapps6.example.com就是应用对外的域名。通过它,用户就可以访问这个域名,然后请求按照负载均衡的方式会,被转发到两个Pod上,它们的IP是:10.1.0.17、10.1.0.22。
Pod的弹性扩展:
在虚拟化时代,应用的弹性扩展是比较复杂的,而在OpenShift中,我们可以通过一条命令,动态增加或者减少一个应用Pod的数量,从而实现弹性扩展。接上面的实验,bookstore service对应两个pod,将其扩展到三个:
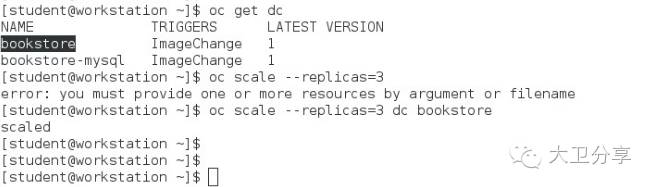
我们在页面上看到,pod的副本数已经变成了三个:
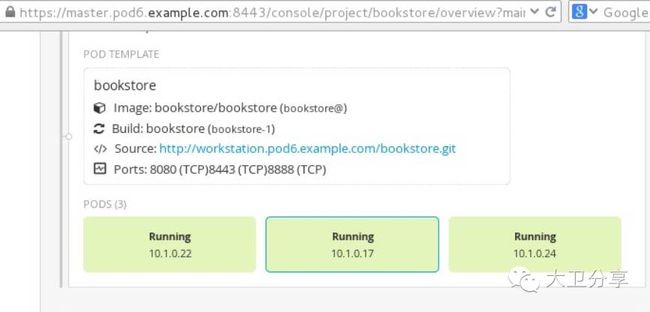
新生成的pod的IP地址,10.1.0.24,也会随后被自动添加到HAProxy的对应表中,与外网域名对应起来,新的外部访问请求进来以后,新的pod就可以承担负载了。
持久化存储的意义
Pod由于意外down以后,Pod在分钟级别就可以完成重建。但我们知道,对客户而言,数据时最重要的,这就需要为容器提供持久化存储。有了持久化存储,重建的Pod可以访问之前Pod存放的数据,迅速恢复应用。如果将应用部署在多个Pod上,就可以轻松实现应用的多活。
Openshit提供的持久化存储目前支持主流存储协议,iscsi,NFS,ceph等。OpenShift提供持久化存储,有两个概念:PV(Persistent Volume)和PVC(Persistent VolumeClaim)
概念听起来比较难复杂,为了方便理解,我举一个例子。
我们要新建一个pod,pod中有三个容器,这个Pod需要2G的持久存储空间。那我们需要做什么?
首先,创建PV。也就是这个2G的空间。就操作方式而言,是修改PV的JSON配置文件,指定PV的大小和PV存放的地址:

然后根据修改好的JSON文件创建PV。PV创建好以后,接着创建PVC。
PVC的JSON文件中,除了定义了Pod需要的存储空间大小,还会定义其他参数,如对PV的访问方式等等。
接下来,通过OpenShift命令创建PVC,
#oc create -f ./pvc.json
PVC创建好以后,它会根据自己配置文件中的设置(容量等),主动寻找PV并与之关联。PV和PVC之间是一一对应的。
#oc get pvc

创建Pod的时候,就可以在它的JSON文件中,指定它访问的PVC,因为PVC已经与PC强关联起来,Pod在创建的时候,就能够申请到持久化存储空间了。
下图是创建Pod的JSON文件的部分内容,在该文件存储配置部分指定了创建Pod访问的PVC,因为这个PVC已经与PV,也就是mysqldb-volume关联起来了,Pod创建好以后,数据就会存在这个PV上。
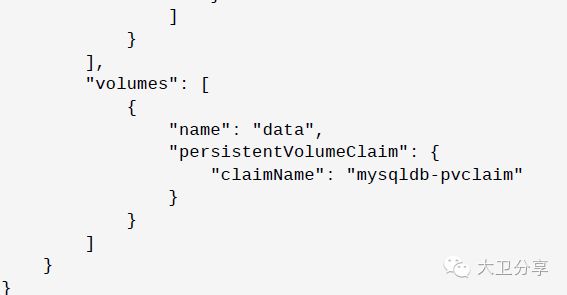
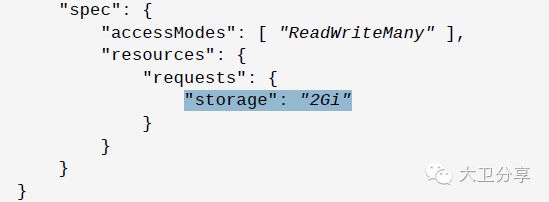
很多时候,多个Pod可能需要访问共同的外部数据,那么就可以在Pod的JSON文件中,指定多个PVC。也就是说,让一个PVC被多个Pod关联。但需要注意的是,被共享的PV,在其JSON的配置文件中,需要指明access mode的方式为ReadWriteMany:
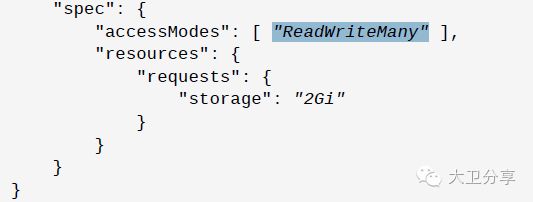
AccessModes可以被设置成三种方式:
ReadWriteOnce:PV可以被单个Pod读写。
ReadOnlyMany:PV可以被多Pods只读。
ReadWriteMany:PV可以被多个Pods读写。
Registry
有了OpenShift,用户获取p_w_picpath可以有三种方式:
通过Docker组织的Registry获取;
通过红帽认提供的Registry获取;
通过OpenShift自建的Registry获取;
内部Registry方便实现SI2中的BC或者DC获取和上传p_w_picpath,而不必连接到公网。
配置registry的步骤比较简单和常见,这里就不再进行详细介绍了。
