springboot使用JPA集成sharding-jdbc进行分表
1. 本文目标
1.1 使用sharding-sphere提供的 sharding-jdbc-spring-boot-starter 分表组件去和JPA项目集成。
1.2 实现自己的分表算法(使用行表达式取模+自定义算法两种)。
1.3 分库本文不做研究,原理都一样。
2. 项目搭建
application.properties:
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://139.199.171.136:3306/test?characterEncoding=utf8&useSSL=false
spring.datasource.username=root
spring.datasource.password=rootmaven依赖:
org.springframework.boot
spring-boot-starter-parent
2.0.4.RELEASE
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-data-jpa
mysql
mysql-connector-java
5.1.47
io.shardingsphere
sharding-jdbc-spring-boot-starter
3.0.0.M2
com.alibaba
druid
1.1.9
org.springframework.boot
spring-boot-starter-test
然后我们先把基础的JPA调通
UserAuthEntity.java,这个类是用户认证表对应的实体类:
/**
* 用户认证信息
*/
@Entity
@Table(name = "USER_AUTH",
uniqueConstraints = {
@UniqueConstraint(name = "USER_AUTH_PHONE",columnNames = {"PHONE"}),
@UniqueConstraint(name = "USER_AUTH_EMAIL",columnNames = {"EMAIL"})
}
)
public class UserAuthEntity implements Serializable {
private static final long serialVersionUID = -3050810548161476299L;
@Id
@Column(name = "USER_ID")
private Integer userId;
@Column(name = "PHONE",length = 16)
private String phone;
@Column(name = "EMAIL",length = 16)
private String email;
@Column(name = "LOCAL_PASSWORD",length = 32,nullable = false)
private String localPassword;
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getLocalPassword() {
return localPassword;
}
public void setLocalPassword(String localPassword) {
this.localPassword = localPassword;
}
}对应的DAO:
@Repository
public interface UserAuthDao extends JpaRepository {
public List findByUserIdBetween(int start, int end);
}
MyFriendEntity.java,我的好友 表 对应的实体类
@Entity
@Table(name = "MY_FRIEND")
public class MyFriendEntity implements Serializable {
private static final long serialVersionUID = -952799334936333550L;
@EmbeddedId
private MyFriendEntityId myFriendId;
@Column(name = "REMARK",length = 16)
private String remark;
@Column(name = "ADD_DATE",nullable = false,columnDefinition = " datetime default now() ")
private LocalDateTime addDate;
public MyFriendEntityId getMyFriendId() {
return myFriendId;
}
public void setMyFriendId(MyFriendEntityId myFriendId) {
this.myFriendId = myFriendId;
}
public String getRemark() {
return remark;
}
public void setRemark(String remark) {
this.remark = remark;
}
public LocalDateTime getAddDate() {
return addDate;
}
public void setAddDate(LocalDateTime addDate) {
this.addDate = addDate;
}
}
MyFriendEntityId.java:
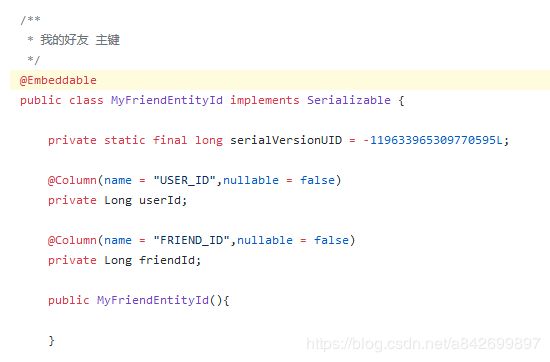
对应的DAO:
@Repository
public interface MyFriendDao extends JpaRepository {
}
单元测试:
@RunWith(SpringRunner.class)
@SpringBootTest
public class TestShardingSphere {
@Autowired
MyFriendDao myFriendDao;
@Autowired
UserAuthDao userAuthDao;
@Test
public void testInsert(){
MyFriendEntity friendEntity = new MyFriendEntity();
friendEntity.setMyFriendId(new MyFriendEntityId(3,"5"));
friendEntity.setAddDate(LocalDateTime.now());
myFriendDao.save(friendEntity);
friendEntity.setMyFriendId(new MyFriendEntityId(5,"5"));
friendEntity.setAddDate(LocalDateTime.now());
myFriendDao.save(friendEntity);
friendEntity.setMyFriendId(new MyFriendEntityId(6,"5"));
friendEntity.setAddDate(LocalDateTime.now());
myFriendDao.save(friendEntity);
UserAuthEntity user = new UserAuthEntity();
user.setUserId(2);
user.setLocalPassword("123");
userAuthDao.save(user);
}
}
数据正常插入...
然后我们对MY_FRIEND进行分表,对USER_ID取模10,将一个表分为MY_FRIEND_0、MY_FRIEND_1....MY_FRIEND_9一共10个表,注意,我们需手动创建这10个表,否则会报table not exists。

参照官方文档的配置使用行表达式进行分表,调整application.properties为如下:
spring.jpa.hibernate.ddl-auto=none
spring.jpa.show-sql=true
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
sharding.jdbc.datasource.names=test
sharding.jdbc.datasource.test.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.test.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.test.url=jdbc:mysql://192.168.1.113/test?characterEncoding=utf8&useSSL=false/oochart?characterEncoding=utf8&useSSL=false
sharding.jdbc.datasource.oochart.username=root
sharding.jdbc.datasource.oochart.password=root
#所有数据节点
sharding.jdbc.config.sharding.tables.MY_FRIEND.actual-data-nodes=test.MY_FRIEND_$->{0..9}
#根据这个列分表
sharding.jdbc.config.sharding.tables.MY_FRIEND.table-strategy.inline.sharding-column=USER_ID
#分表规则为:对USER_ID取模
sharding.jdbc.config.sharding.tables.MY_FRIEND.table-strategy.inline.algorithm-expression=test.MY_FRIEND_$->{USER_ID % 10}再次运行单元测试的testInsert()方法,可以看到数据分别插入到了3个不同后缀的MY_FRIEND_X表中。
增加单元测试方法:
@Test
public void testQuery(){
Optional byId = myFriendDao.findById(new MyFriendEntityId(6, "5"));
byId.ifPresent(one -> System.out.println(one.getMyFriendId().getFriendId()));
List all = myFriendDao.findAll();
System.out.println(all);
} 运行查看结果,数据可以全部取到。
以上是通过行表达式进行取模的简单分片,下面将实现我们自定义的分片算法。
查看官方的文档,我们需要通过这个类来配置我们的分片算法:

修改application.properties如下:
spring.jpa.hibernate.ddl-auto=none
spring.jpa.show-sql=true
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
sharding.jdbc.datasource.names=test
sharding.jdbc.datasource.test.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.test.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.test.url=jdbc:mysql://192.168.1.113/test?characterEncoding=utf8&useSSL=false/oochart?characterEncoding=utf8&useSSL=false
sharding.jdbc.datasource.oochart.username=root
sharding.jdbc.datasource.oochart.password=root
#所有数据节点
sharding.jdbc.config.sharding.tables.MY_FRIEND.actual-data-nodes=test.MY_FRIEND_$->{0..9}
#根据这个列分表
sharding.jdbc.config.sharding.tables.MY_FRIEND.table-strategy.inline.sharding-column=USER_ID
#分表规则为:对USER_ID取模
sharding.jdbc.config.sharding.tables.MY_FRIEND.table-strategy.inline.algorithm-expression=test.MY_FRIEND_$->{USER_ID % 10}
#分片列
sharding.jdbc.config.sharding.default-table-strategy.standard.sharding-column=USER_ID
#精确分片算法,用于=和IN,实现类
sharding.jdbc.config.sharding.default-table-strategy.standard.precise-algorithm-class-name=com.solider76.oo.service.chat.config.MyShardingConfig
#范围分片算法,用于BETWEEN,实现类
sharding.jdbc.config.sharding.default-table-strategy.standard.range-algorithm-class-name=com.solider76.oo.service.chat.config.MyShardingConfig分片算法实现类:
public class MyShardingConfig implements PreciseShardingAlgorithm, RangeShardingAlgorithm {
/**
* 精确分片算法
* 将user_id的值和5比较,如果小于等于5,数据对应的表为:USER_AUTH_1
* 将user_id的值和5比较,如果大于5,数据对应的表为:USER_AUTH_2
* @param availableTargetNames
* @param shardingValue
* @return
*/
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
if(availableTargetNames.contains("user_auth")){
if(shardingValue.getColumnName().equalsIgnoreCase("USER_ID")){
Comparable value = shardingValue.getValue();
int i = value.compareTo(5);
int suffix = -1;
if(i<=0){
suffix = 1;
}else{
suffix = 2;
}
String s = ("user_auth_" + suffix).toUpperCase();
return s;
}
}
return null;
}
/**
* lower 为 between and 中的较小值
* upper 为 between and 中的较大值
* 如果lower小于等于5,tables集合中就要加入USER_AUTH_1表
* 如果lower大于5,tables集合中就要加入USER_AUTH_2表
* @param availableTargetNames
* @param shardingValue
* @return
*/
@Override
public Collection doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
Collection tables = new HashSet<>();
if(availableTargetNames.contains("user_auth")){
if(shardingValue.getColumnName().equalsIgnoreCase("USER_ID")){
Comparable lower = shardingValue.getValueRange().lowerEndpoint();
Comparable upper = shardingValue.getValueRange().upperEndpoint();
int lowerResult = lower.compareTo(5);
int upperResult = upper.compareTo(5);
if(lowerResult<=0){
tables.add("user_auth_1".toUpperCase());
if(upperResult>0){
tables.add("user_auth_2".toUpperCase());
}
}else{
tables.add("user_auth_2".toUpperCase());
}
}
}
return tables;
}
} 为了方便展示,这里的代码写的较为粗略,实际的算法在这里实现,我这里只是简单的将USER_ID和5比较然后根据结果取不同的表。同样的,这里也需要先创建表USER_AUTH_1、USER_AUTH_2。
新增test方法:
@Test
public void testCustomerConfigInsert(){
UserAuthEntity user = new UserAuthEntity();
user.setUserId(2);
user.setLocalPassword("123");
userAuthDao.save(user);
user.setUserId(8);
user.setLocalPassword("123");
userAuthDao.save(user);
user.setUserId(11);
user.setLocalPassword("123");
userAuthDao.save(user);
user.setUserId(3);
user.setLocalPassword("123");
userAuthDao.save(user);
}
@Test
public void testCustomerConfigQuery(){
Optional byId = userAuthDao.findById(2);
System.out.println(byId.isPresent());
}
@Test
public void testBetween(){
List byUserIdBetween = userAuthDao.findByUserIdBetween(8, 11);
for(UserAuthEntity user : byUserIdBetween){
System.out.println("id:"+user.getUserId());
}
} 正常输出结果。。。
3. 其他说明
1. 这里只是简单的进行了分表,功能只是sharding-sphere的冰山一角。
2. 项目中MySql版本为5.X,已知如果使用MySql8.0.12启动会报语法错误,已查明是8.0.12的mysql驱动bug,oracle官网已经记载了此bug,8.0.12之后应该会修复:
Caused by: java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'ORDER BY TABLE_TYPE, TABLE_SCHEMA, TABLE_NAME' at line 1
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120) ~[mysql-connector-java-8.0.12.jar:8.0.12]
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97) ~[mysql-connector-java-8.0.12.jar:8.0.12]
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122) ~[mysql-connector-java-8.0.12.jar:8.0.12]
at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:975) ~[mysql-connector-java-8.0.12.jar:8.0.12]
at com.mysql.cj.jdbc.ClientPreparedStatement.executeQuery(ClientPreparedStatement.java:1025) ~[mysql-connector-java-8.0.12.jar:8.0.12]
at com.mysql.cj.jdbc.DatabaseMetaDataUsingInfoSchema.executeMetadataQuery(DatabaseMetaDataUsingInfoSchema.java:70) ~[mysql-connector-java-8.0.12.jar:8.0.12]
at com.mysql.cj.jdbc.DatabaseMetaDataUsingInfoSchema.getTables(DatabaseMetaDataUsingInfoSchema.java:843) ~[mysql-connector-java-8.0.12.jar:8.0.12]
at io.shardingsphere.core.metadata.table.executor.TableMetaDataInitializer.getAllTableNames(TableMetaDataInitializer.java:90) ~[sharding-core-3.0.0.M2.jar:na]
at io.shardingsphere.core.metadata.table.executor.TableMetaDataInitializer.loadDefaultTables(TableMetaDataInitializer.java:80) ~[sharding-core-3.0.0.M2.jar:na]
at io.shardingsphere.core.metadata.table.executor.TableMetaDataInitializer.load(TableMetaDataInitializer.java:61) ~[sharding-core-3.0.0.M2.jar:na]
... 55 common frames omitted