AQS深入理解系列(四)Condition接口的实现
文章目录
- 前言
- 与wait/notify进行对比
- 同步队列 和 条件队列
- sync queue
- condition queue
- 二者的关系
- CondtionObject
- await()第一次调用park之前
- addConditionWaiter
- unlinkCancelledWaiters
- fullyRelease
- isOnSyncQueue
- await()第一次调用park之后
- signalAll流程
- signal流程
- transferForSignal假设不唤醒node线程
- transferForSignal假设唤醒node线程
- 中断流程(有线程将node线程中断,在signal之前)
- 因中断被唤醒的node线程 和 signal线程 的竞争关系
- 终于执行到acquireQueued
- await()总结
- awaitUninterruptibly()
- awaitNanos(long nanosTimeout)
- await(long time, TimeUnit unit)
- awaitUntil(Date deadline)
前言
一个新设计的出现,总是为了替换现有的略有不足的设计。而Condition接口的出现,是为了代替监视器锁的wait/notify机制,提供更强大的功能。
JUC框架 系列文章目录
与wait/notify进行对比
我们将Object自带的wait/notify方法与Condition接口提供的await/signal进行一个对比。
| Object方法 | Condition方法 | 区别 |
|---|---|---|
| void wait() | void await() | |
| void wait(long timeout) | long awaitNanos(long nanosTimeout) | 时间单位:前者毫秒ms,后者纳秒ns 返回值 |
| void wait(long timeout, int nanos) | boolean await(long time, TimeUnit unit) | 时间单位:前者只能纳秒,后者什么单位都可以 返回值 |
| void notify() | void signal() | |
| void notifyAll() | void signalAll() | |
| - | void awaitUninterruptibly() | Condition独有 |
| - | boolean awaitUntil(Date deadline) | Condition独有 |
先简单说明一下它们之间的相同之处,以便之后更好地理解Condition接口的实现:
- 调用
wait()的线程必须已经处于同步代码块中,换言之,调用wait()的线程已经获得了监视器锁;调用await()的线程则必须是已经获得了lock锁。 - 执行
wait()时,当前线程会释放已获得的监视器锁,进入到该监视器的等待队列中;执行await()时,当前线程会释放已获得的lock锁,然后进入到该Condition的条件队列中。 - 退出
wait()时,当前线程又重新获得了监视器锁;退出await()时,当前线程又重新获得了lock锁。 - 调用监视器的
notify,会唤醒等待在该监视器上的线程,这个线程此后才重新开始锁竞争,竞争成功后,会从wait方法处恢复执行;调用Condition的signal,会唤醒等待在该Condition上的线程,这个线程此后才重新开始锁竞争,竞争成功后,会从await方法处恢复执行。
同步队列 和 条件队列
对于每个Condition对象来说,都对应到一个条件队列condition queue。而对于每个Lock对象来说,都对应到一个同步队列sync queue。
sync queue
独占锁的获取过程中,我们提到了,每个线程在lock()尝试获取锁失败后,都会被包装成一个node放到sync queue中去。

sync queue是一个双向链表,它使用prev和next作为链接。在这个队列中,我们几乎不关心节点的nextWaiter成员,最多会在共享锁模式下,用来标识节点是否为共享锁节点。队头是一个dummy node即Thread成员为null,第一个等待线程永远只能是head的后继。
condition queue
每一个Condition对象都对应到一个条件队列condition queue,而每个线程在执行await()后,都会被包装成一个node放到condition queue中去。
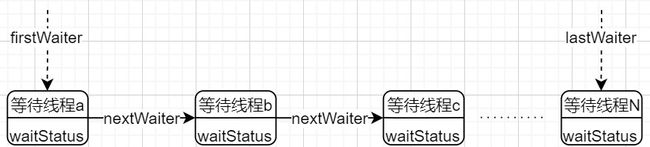
condition queue是一个单向链表,它使用nextWaiter作为链接。这个队列中,不存在dummy node,每个节点都代表一个线程。这个队列的节点的状态,我们只关心状态是否为CONDITION,如果是CONDITION的,说明线程还等待在这个Condition对象上;如果不是CONDITION的,说明这个节点已经前往sync queue了。
二者的关系
假设现在存在一个Lock对象和通过这个Lock对象生成的若干个Condition对象,从队列上来说,就存在了一个sync queue和若干个与这个sync queue关联的condition queue。本来这两种队列上的节点没有关系,但现在有了signal方法,就会使得condition queue上的节点会跑到sync queue上去。

上图简单体现了节点从从condition queue转移到sync queue上去的过程。即使是调用signalAll时,节点也是一个一个转移过去的,因为每个节点都需要重新建立sync queue的链接。
我们这里可以先简单理解一下关于队列的动作:
- 如果一个节点刚入队
sync queue,说明这个节点的代表线程没有获得锁(尝试获得锁失败了)。 - 如果一个节点刚出队
sync queue(指该节点的代表线程不在同步队列中的任何节点上,因为它已经跑到了AQS的exclusiveOwnerThread成员上去了),说明这个节点的代表线程刚获得了锁(尝试获得锁成功了)。 - 如果一个节点刚入队
condition queue,说明这个节点的代表线程此时是有锁了,但即将释放。 - 如果一个节点刚出队
condition queue,因为前往的是sync queue,说明这个节点的代表线程此时是没有获得锁的。
CondtionObject
对于ReentrantLock来说,我们使用newCondition方法来获得Condition接口的实现,而ConditionObject就是一个实现了Condition接口的类。
//ReentrantLock.java
public class ReentrantLock implements Lock, java.io.Serializable {
public Condition newCondition() {
return sync.newCondition();
}
abstract static class Sync extends AbstractQueuedSynchronizer {
final ConditionObject newCondition() {
return new ConditionObject();
}
}
}
而ConditionObject又是AQS的一个成员内部类,这意味着不管生成了多少个ConditionObject,它们都持有同一个AQS对象的引用,这和“一个Lock可以对应到多个Condition”相吻合。这也意味着:对于同一个AQS来说,只存在一个同步队列sync queue,但可以存在多个条件队列condition queue。
成员内部类有一个好处,不管哪个ConditionObject对象都可以调到同一个外部类AQS对象的方法上去。比如acquireQueued方法,这样,不管node在哪个condition queue上,最终它们离开后将要前往的地方总是同一个sync queue。
public abstract class AbstractQueuedSynchronizer{
private transient volatile Node head;
private transient volatile Node tail;
public class ConditionObject implements Condition {
private transient Node firstWaiter;
private transient Node lastWaiter;
}
}
firstWaiter和lastWaiter分别代表条件队列的队头和队尾。- 注意,
firstWaiter和lastWaiter都不再需要加volatile来保证可见性了。这是因为源码作者是考虑,使用者肯定是以获得锁的前提下来调用await() / signal()这些方法的,既然有了这个前提,那么对firstWaiter的读写肯定是无竞争的,既然没有竞争也就不需要 CAS+volatile 来实现一个乐观锁了。
final Lock lock = new ReentrantLock();
Condition Emptycondition = lock.newCondition();
Emptycondition.await(); //这样会抛出异常
现在考虑没有这个前提。上面代码在没有获得锁的情况就去调用了await,会导致await抛出异常,但是在抛出异常之前肯定会调用到addConditionWaiter,而addConditionWaiter有对这两个变量的读写,现在可能同时有两个线程对非volatile变量进行读写,也就可能造成问题。所以,在用户使用不规范的情况下,还是有可能造成变量读写竞争,且没有锁保护的情况。(函数实现后面会讲,请接着看)
public ConditionObject() { }
但ConditionObject的构造器什么也不做。
await()第一次调用park之前
public final void await() throws InterruptedException {
// 在调用await之前,当前线程就已经被中断了,那么抛出异常
if (Thread.interrupted())
throw new InterruptedException();
// 将当前线程包装进Node,然后放入当前Condition的条件队列
Node node = addConditionWaiter();
// 释放锁,不管当前线程重入锁多少次,都要释放干净
int savedState = fullyRelease(node);
int interruptMode = 0;
// 如果当前线程node不在同步队列上,说明还没有别的线程调用 当前Condition的signal。
// 第一次进入该循环,肯定会符合循环条件,然后park阻塞在这里
while (!isOnSyncQueue(node)) {
LockSupport.park(this); // 将阻塞在这里
// 如果被唤醒,要么是因为别的线程调用了signal使得当前node进入同步队列,
// 进而当前node等到自己成为head后继后并被唤醒。
// 要么是因为别的线程 中断了当前线程。
// 如果接下来发现自己被中断过,需要检查此时signal有没有执行过,
// 且不管怎样,都会直接退出循环。
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
/*之后再讲后面的部分*/
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
注释介绍了大概的过程,但首先要明确会有哪些线程在执行:
- 执行
await的当前线程。这个线程是最开始调用await的线程,也是执行await所有调用链的线程,它被包装进局部变量node中。(后面会以node线程来称呼它) - 执行
signal的线程。这个线程会改变await当前线程的node的状态state,使得await当前线程的node前往同步队列,并在一定条件在唤醒await当前线程。 - 中断
await当前线程的线程。你就当这个线程只是用来唤醒await当前线程,并改变其中断状态。只不过await当前线程它自己被唤醒后,也会做和上一条同样的事情:“使得await当前线程的node前往同步队列”。 - 执行
unlock的线程。如果await当前线程的node已经是同步队列的head后继,那么获得独占锁的线程在释放锁时,就会唤醒await当前线程。
理解了这几个线程的存在,对于本文的理解有很大帮助。从用户角度来说,执行await \ signal \ unlock的前提都是线程必须已经获得了锁。
addConditionWaiter
private Node addConditionWaiter() {
Node t = lastWaiter;//获得队尾
// 同步队列中的节点只是CONDITION的,就认为是以后将离开条件队列的节点。
// 将调用unlinkCancelledWaiters来一次大清理,并重新获得队尾
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
// 包装当前线程为node,状态初始为CONDITION
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)// 如果当前队尾为null,那么整个条件队列都没初始化呢
firstWaiter = node; //把新建node作为队头
else // 如果队列有至少一个节点
t.nextWaiter = node; // 把新建node接在队尾后面
lastWaiter = node; //让node成为新队尾
return node;
}
上面函数描述了新建node加入到条件队列中的过程,我们和独占锁获取过程中新建node加入同步队列进行对比:
- 同步队列
sync queue的新建node,它的初始状态为0。而条件队列condition queue的新建node的初始状态为CONDITION。 sync queue如果拥有队头,队头肯定会是一个dummy node(即线程成员为null)。condition queue则不会有一个dummy node,每个节点的线程成员都不为null。sync queue是一个双向链表,需要维持前驱和后继都正确。condition queue只是一个单链表,只需要维持后继即可。
这里先提前说下,中断await当前线程的线程(这里特指中断操作在signal之前)和执行signal的线程都会使得条件队列上的node的状态从CONDITION变成0。
unlinkCancelledWaiters
unlinkCancelledWaiters函数是用来从头到尾清理状态不为CONDITION的节点的。
private void unlinkCancelledWaiters() {
Node t = firstWaiter; //获得队头
Node trail = null; //trail用来保存遍历过程中,最近一次发现的状态为CONDITION的节点
while (t != null) { //只要循环变量不为null,循环继续
Node next = t.nextWaiter; //得到循环变量的后继,循环结束前使用
// 如果循环变量不为CONDITION
if (t.waitStatus != Node.CONDITION) {
t.nextWaiter = null; //首先使得t与后继断开链接
// 如果直到当前循环都还没有发现一个CONDITION的节点
if (trail == null)
firstWaiter = next;//那么将循环变量的后继,作为新队头
// 如果当前循环之前已经发现了一个CONDITION的节点
else
trail.nextWaiter = next;//那么将trail与next相连,相当于跳过了循环变量t
// 如果已经遍历到队尾,需要将trail作为队尾,因为trail才是队列中最后一个为CONDITION的节点
if (next == null)
lastWaiter = trail;
}
// 如果循环变量为CONDITION,则更新trail
else
trail = t;
t = next; //循环结束前,用next更新循环变量
}
}
主要是一些单链表的操作,trail变量很重要,它用来保存遍历过程中,最近一次发现的状态为CONDITION的节点。
fullyRelease
在调用fullyRelease之前,当前线程已经被包装成node放到条件队列中去了。注意,在这个函数以后,我们再也不会对firstWaiter和lastWaiter轻举妄动了,因为await()以后的执行过程中,当前线程很长一段时间内是没有持有锁的。
我们调用fullyRelease函数来释放当前线程占有的锁。
final int fullyRelease(Node node) {
boolean failed = true;
try {
int savedState = getState();//这里会获得重入锁的总次数
if (release(savedState)) {
failed = false;
return savedState;// 返回重入锁的总次数
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
node.waitStatus = Node.CANCELLED;
}
}
该函数很简单,只是通过调用独占锁释放过程中的release函数来释放锁,注意,不管锁被重入了几次,在这里我们都会一次性释放干净的(release(savedState))。这也是为什么这个函数叫做fullyRelease全释放。
如果真的有哪个傻子在没有获得锁时,调用了await,那么release会抛出异常且导致抛出时failed变量为真,那么在finally块里面就会执行语句,把当前线程的node的状态变成非CONDITION的。
isOnSyncQueue
在执行完fullyRelease后的这一段时间里,当前线程是没有持有锁的了,因为锁已经被自己给释放了。更重要的是,接下来的这一段时间里,另一个线程可能又获得了锁,然后开始执行await \ signal \ unlock,即接下来得考虑多线程了。
回到await的逻辑,现在要进入循环了。循环里马上就会调用LockSupport.park(this);阻塞当前线程,这也就是本章大标题说的“await()第一次调用park之前”的时间点了。
但是每次循环都会判断一下循环条件!isOnSyncQueue(node),即当前线程node不在同步队列中。很明显,如果是第一次进入循环,这个循环条件肯定会满足的,因为我们刚刚才执行了addConditionWaiter将当前线程node加入到条件队列中呢。
这个循环条件!isOnSyncQueue(node)主要是为了当前线程被唤醒后,进行必要的判断。
final boolean isOnSyncQueue(Node node) {
//如果node状态为CONDITION,或者虽然node状态不为CONDITION,但node前驱为空
if (node.waitStatus == Node.CONDITION || node.prev == null)
return false;
//执行到这里,说明上面两个条件都不成立:
//1. node状态不为CONDITION 2. node前驱不为空
//如果node后继不为空,说明已经在sync queue
if (node.next != null)
return true;
//执行到这里,说明:
//前一个时间点检测到,1. node状态不为CONDITION 2. node前驱不为空
//后一个时间点检测到:node后继为空
//现在发现node处于一个状态:前驱不为空,但后继为空。如果node是当前队尾肯定也是这种状态
//但enq进队尾时CAS设置tail失败时,也会是这种状态。所以需要从尾到头检测一遍。
return findNodeFromTail(node);
}
private boolean findNodeFromTail(Node node) {
Node t = tail;
for (;;) {
if (t == node)
return true;
if (t == null)
return false;
t = t.prev;
}
}
注意,本函数都是在检测prev next两个链接,即sync queue的数据结构。
if (node.waitStatus == Node.CONDITION || node.prev == null)分支:- 先看看进入分支的情况:
- 如果前者成立,即node状态为CONDITION。说明node代表线程还没有前往同步队列。
- 如果前者不成立,后者成立,即虽然node状态不为CONDITION,但node前驱为空。一个节点如果已经入队成功,那么它的prev肯定不为null。
- 再看看退出这个分支的情况:
- 中间条件是或,所以是二者都不成立。即1. node状态不为CONDITION 2. node前驱不为空。但如果只是已知这些信息,则还需要继续判断。
- 先看看进入分支的情况:
if (node.next != null)分支,如果说node的next都已经不为空了,说明node成为队尾后,又有节点入队成为新队尾。而发生这一切的前提则是,node已经成功入队过了。- 最后需要从尾到头遍历,看是否能在同步队列上找到node。执行
findNodeFromTail之前,发现node处于一个状态:前驱不为空,但后继为空。如果node是当前队尾肯定也是这种状态。但enq进队尾时CAS设置tail失败时,也会是这种状态。所以需要从尾到头检测一遍。
关于状态不为CONDITION,前面有说过,有两种线程可以使得条件队列上的node的状态从CONDITION变成0。但现在可以排除中断await当前线程的线程这种情况(之后具体介绍这个流程),因为如果发生了中断,await的while循环直接就会break出循环了(if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break;),也就不会执行到isOnSyncQueue函数了。
简单的说,isOnSyncQueue判断节点已经入队同步队列的标准,必须是node已经成为队尾(包括当前是队尾,或者曾经是队尾)。
await()第一次调用park之后
正常情况下,await()第一次调用park之后,就会阻塞在这里了,所以这里必须依靠别的线程出来救场了。
此时node的状态为:
- 在数据结构上,node在条件队列上(
addConditionWaiter)。 - 在执行过程上,node线程当前阻塞在
LockSupport.park(this)这里。
signalAll流程
前面我们提前说过执行signal的线程,我们先来看看执行signalAll的线程会干什么。
public final void signalAll() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignalAll(first);
}
protected final boolean isHeldExclusively() {
return getExclusiveOwnerThread() == Thread.currentThread();
}
首先会检查执行signalAll的线程是否已经获得了锁,通过判断ExclusiveOwnerThread成员变量。然后判断条件队列是否为空,只要不为空就执行doSignalAll。
private void doSignalAll(Node first) {
lastWaiter = firstWaiter = null;
do {
Node next = first.nextWaiter;
first.nextWaiter = null;
transferForSignal(first);
first = next;
} while (first != null);
}
上来就把代表条件队列的队头队尾成员置null,之后别人就无法通过队头队尾找到队列中的节点了,只有当前线程能通过局部变量first来找到队列节点了。
而接下来不断遍历,直到已经遍历到队尾(first != null)。每次遍历中,将当前遍历节点 与 剩下的条件队列链 断开,然后对当前遍历节点执行transferForSignal。
final boolean transferForSignal(Node node) {
/*
* 如果失败,说明node代表线程因中断而已经执行了中断流程中的compareAndSetWaitStatus(node, Node.CONDITION, 0)
*/
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
/*
* 执行enq将node入队sync queue,enq返回node的前驱。
*/
Node p = enq(node);
int ws = p.waitStatus;
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
transferForSignal函数简单的说,就是为让参数node入队,如果入队成功就返回true。
- 如果CAS设置node状态从CONDITION变成0失败了,说明node代表线程因中断而已经执行了中断流程中的
compareAndSetWaitStatus(node, Node.CONDITION, 0)。这也间接说明了signal流程和中断流程都是以 成功设置node状态 作为标准,哪个流程成功了,哪个流程就把node入队同步队列,从而以免重复入队。(这一点需要和后面的中断流程内容联动,如果难以理解,可以直接往下看) - 如果CAS设置成功,那么
enq(node)入队,然后肯定返回true。但是注意,在一定条件下,会唤醒node代表线程。注意enq(node)返回node入队后的前驱prev。- 这个一定条件是指,node的前驱状态是同步队列节点的取消状态,或者状态<=0但CAS设置前驱状态为SIGNAL失败了。
- 如果上面条件发生了,就直接唤醒node线程。这里我们回想一下
await()第一次调用park之后这个时间点,现在node线程终于被唤醒,假设没有中断发生过的话,不会因break退出循环,再一次检测!isOnSyncQueue(node)会发生条件不成立(node已经因为enq(node)而成功入队)。然后又会走到独占锁获得过程中的acquireQueued函数。 - 唤醒node代表线程不一定代表它接下来能够获得锁,但是我们也不用担心这会有什么坏影响,因为
acquireQueued函数自己会去做判断,如果发现还是获取不到锁的话,则会调用shouldParkAfterFailedAcquire将node的前驱设置为SIGNAL的。 - 总之,
compareAndSetWaitStatus(p, ws, Node.SIGNAL)直接保证了node的前驱状态为SIGNAL,而LockSupport.unpark(node.thread)间接保证了node的前驱状态为SIGNAL,之所以说间接,是因为这不是在signal线程里做的,而是通过唤醒node线程做到的。
简单总结一下signalAll方法:
- 将条件队列清空(通过
lastWaiter = firstWaiter = null来达到效果,但函数中的局部变量已经保存了队头,且实际上节点的链接还存在着)。 - 遍历每个节点。
- 如果遍历节点已经被取消掉了(
compareAndSetWaitStatus(node, Node.CONDITION, 0)失败),那么直接返回,处理下一个节点。 - 如果遍历节点还没取消掉(
compareAndSetWaitStatus(node, Node.CONDITION, 0)成功),那么将其入队同步队列。在一定条件下(无法设置node前驱状态为SIGNAL时),还将唤醒node代表线程。然后处理下一个节点。
另外注意,signalAll方法直到结束返回,都一直没有释放锁呢(因为没有在signalAll里面执行过release),也就是说,执行signalAll的线程一直都是持有锁的。
signal流程
相比signalAll,signal方法只会唤醒一个node,准确的说,是唤醒从同步队列队头开始的第一个状态为CONDITION的node。
public final void signal() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignal(first); //与之前的doSignalAll不同,这里是doSignal
}
首先看调用signal的线程是否已经拥有了独占锁,不然就会抛出异常。与之前的doSignalAll不同,这里调用的是doSignal。
private void doSignal(Node first) {//first参数是队头
do {
// 更新队头,让队头往后移动一位
if ( (firstWaiter = first.nextWaiter) == null)
//如果发现新队头为null,让队尾也为null
lastWaiter = null;
// 老套路,把参数和后面的链表断开
first.nextWaiter = null;
} while (!transferForSignal(first) &&
(first = firstWaiter) != null); // transferForSignal失败才会执行这行
// 获得新队头,如果新队头不为null,则继续下一次循环,因为现在一次signal都没有成功呢
}
- 整个逻辑是一个
do while循环,不过这个循环一般不会执行多次,只要有一次signal成功了(transferForSignal(first)返回了真)就不会继续循环了,因为这个函数的目的就只是signal一个节点。 - 如果signal失败了,那么获得新队头(
(first = firstWaiter) != null),只要新队头不为null,则继续下一次循环。 - 相比
signalAll流程,我们使用的还是这个transferForSignal来做的signal动作,但这里我们终于使用到了transferForSignal的返回值,如果返回了true说明已经signal了一个node了,也就不用继续循环了。 - 总之,
signal方法会唤醒条件队列中第一个状态不是取消状态(不是CONDITION)的节点。
transferForSignal假设不唤醒node线程
按照上面signal的流程(包括signal和signalAll),假设之前node线程没有被中断过,且执行signalAll的线程不唤醒node线程,那么执行signal流程完毕后此时node的状态为:
- 在数据结构上,node已经离开了条件队列(
first.nextWaiter = null),处于了同步队列上了(Node p = enq(node))。 - 在执行过程上,node线程当前还是阻塞在
LockSupport.park(this)这里。(这一点没有变化)
要想node线程执行完await()方法,得需要执行unlock的线程出马了。当node已经成为了head后继,且获得独占锁的线程开始执行unlock释放锁,将会唤醒node线程。node线程从LockSupport.park(this)处唤醒后,不会因为有中断状态而break出循环(假设没有被中断过,先不用看checkInterruptWhileWaiting的实现,这里只需要知道interruptMode还是会保持为0就行),然后判断循环条件!isOnSyncQueue(node)发现不成立而退出循环,然后将执行acquireQueued(node, savedState),但也不一定能获得锁,如果不能获得,自然还是阻塞在acquireQueued的shouldParkAfterFailedAcquire里。
transferForSignal假设唤醒node线程
按照上面signal的流程,假设之前node线程没有被中断过,且执行signalAll的线程唤醒node线程,那么执行signal流程完毕后此时node的状态为:
- 在数据结构上,node已经离开了条件队列(
first.nextWaiter = null),处于了同步队列上了(Node p = enq(node))。 - 在执行过程上,node线程从
LockSupport.park(this)这里被唤醒,不会因为有中断状态而break出循环,然后判断循环条件!isOnSyncQueue(node)发现不成立而退出循环,然后执行acquireQueued。如果不能获得锁,还是会阻塞在acquireQueued的shouldParkAfterFailedAcquire里。
要想node线程执行完await()方法,还是得需要执行unlock的线程出马。它执行unlock后,node线程从acquireQueued的shouldParkAfterFailedAcquire处被唤醒,然后再一次去获得锁。但也不一定能获得锁,如果不能获得,自然还是阻塞在acquireQueued的shouldParkAfterFailedAcquire里。
中断流程(有线程将node线程中断,在signal之前)
中断await当前线程的线程终于出马了(现在考虑没有执行signal的线程,或者说中断这个node在signal这个node之前),看看中断流程是怎样的流程。首先要知道,中断await当前线程的线程执行完中断动作后,我们就不用关心它了,剩余动作还是靠node线程自己完成的。
本场景下,中断来临之前,node的状态就和 await()第一次调用park之后 一样:
- 在数据结构上,node在条件队列上(
addConditionWaiter)。 - 在执行过程上,node线程当前阻塞在
LockSupport.park(this)这里。
首先,中断来了以后,node线程会从LockSupport.park(this)处被唤醒,然后执行checkInterruptWhileWaiting(之前一直没有讲这个函数,是因为在这个流程中它才会真正发挥作用,之前的signal流程它肯定会返回0的,而返回就不会break出循环)。
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) :
0;
Thread.interrupted()首先判断当前线程有没有被中断过,如果没有,那么返回0.- 如果有中断过,那么通过
transferAfterCancelledWait(node)判断返回THROW_IE还是REINTERRUPT.
checkInterruptWhileWaiting的返回值最终是会赋值给局部变量interruptMode的,它现在有三种可能值:
0:代表整个await过程中没有发生过中断。THROW_IE:代表await执行完毕返回用户代码处时,需要抛出异常。当中断流程发生在signal流程之前时。REINTERRUPT:代表await执行完毕返回用户代码处时,不需要抛出异常,仅需要重新置上中断状态。当signal流程发生在中断流程之前时。
之所以THROW_IE和REINTERRUPT两个值所代表的场景需要进行区分,是因为一个线程A因await而进入condition queue后,正常的流程是另一个线程B执行signal或signalAll后才使得线程A的node入队到sync queue。但如果中断流程发生在signal流程之前,也能使得线程A的node入队到sync queue,但这就没有走正常的流程了。
final boolean transferAfterCancelledWait(Node node) {
if (compareAndSetWaitStatus(node, Node.CONDITION, 0)) {
enq(node);
return true;
}
/*
* If we lost out to a signal(), then we can't proceed
* until it finishes its enq(). Cancelling during an
* incomplete transfer is both rare and transient, so just
* spin.
*/
while (!isOnSyncQueue(node))
Thread.yield();
return false;
}
首先通过CAS设置node状态从CONDITION变成0,如果成功了,就将node入队同步队列,然后直接返回true。注意,这里的CAS操作和transferForSignal里的compareAndSetWaitStatus(node, Node.CONDITION, 0)是一样的,也就是说:执行signal的线程 和 因中断被唤醒的node线程,在这句compareAndSetWaitStatus(node, Node.CONDITION, 0)这里有竞争关系,谁竞争赢了,谁才有资格将node入队同步队列enq(node)。
这样的竞争关系是很必要的,直接避免两个线程将同一个node重复入队。
通过CAS设置node状态从CONDITION变成0,如果失败了,那就不能再执行enq(node)啦。因为肯定有另一个signal线程正在执行enq(node)或者已经执行完了enq(node)了。
但这里我们如果发现另一个signal线程还没有执行完了enq(node)(通过!isOnSyncQueue(node)条件判断),就必须一直等待,直到另一个signal线程执行完了enq(node),然后循环才可以退出。之所以这么等一下,是因为如果不等,node线程自己接下来就会执行到acquireQueued了,而执行acquireQueued的前提就是已经入队同步队列完毕。
等到node线程执行完了checkInterruptWhileWaiting,考虑本章的中断场景,就会直接break出循环,然后执行到acquireQueued。如果不能获得锁,还是会阻塞在acquireQueued的shouldParkAfterFailedAcquire里。
总之执行中断流程完毕后此时node的状态为:
- 在数据结构上,node还是处于条件队列上(没有执行
first.nextWaiter = null),但同时也处于了同步队列上了(enq(node))。不用担心nextWaiter会影响到当前node不被独占锁的释放而唤醒,因为独占锁的释放过程不关心head后继的nextWaiter。 - 在执行过程上,node线程从
LockSupport.park(this)这里被中断唤醒,因为有中断状态而break出循环,然后执行acquireQueued。如果不能获得锁,还是会阻塞在acquireQueued的shouldParkAfterFailedAcquire里。
因中断被唤醒的node线程 和 signal线程 的竞争关系
上面说了中断流程和signal流程谁在前面,await的表现也会有所不同。具体的说,则体现在:因中断被唤醒的node线程 和 signal线程 的竞争关系上。这两个线程完全有可能同时在执行中,而它们的竞争点则体现在:
- 因中断被唤醒的node线程。
transferAfterCancelledWait函数里的compareAndSetWaitStatus(node, Node.CONDITION, 0)。 - signal线程。
transferForSignal函数里的compareAndSetWaitStatus(node, Node.CONDITION, 0)。
这两个transfer方法都会执行同一个CAS操作,但很明显,只能有一个线程能够执行CAS操作成功。
- 竞争成功的那一方,transfer方法会返回true,并且会执行
enq(node)。 - 竞争失败的那一方,transfer方法会返回false,并且不会执行
enq(node)。 - 当一个处于条件队列上的node,状态从
CONDITION变成0时,就意味着它正在前往同步队列,或者已经放置在同步队列上了。 - 如果
transferAfterCancelledWait竞争成功,我们称这个node线程走的是中断流程。 - 如果
transferForSignal竞争成功,我们称这个node线程走的是signal流程。
终于执行到acquireQueued
讲了半天,终于讲到acquireQueued了。但重点内容其实都在前面,acquireQueued后面的都是一些善后处理而已了。
既然已经执行到了acquireQueued,说明又会走独占锁的获取过程了,在此不赘述了。我们只需要知道,从acquireQueued返回时,node线程已经获取到了锁,并且返回了acquireQueued过程中是否有过中断。注意,这和acquireQueued执行前发生的中断是两个不同的中断,acquireQueued执行前发生的中断会被checkInterruptWhileWaiting消耗掉,并赋值给interruptMode的。
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE) //已经执行到这里啦!!!
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
注意,int savedState = fullyRelease(node)之前释放的同步器状态,现在acquireQueued(node, savedState)都要重新全部再获取回来。
acquireQueued期间发生的中断,重要性不如acquireQueued之前发生的中断。假设acquireQueued发生了中断,acquireQueued(node, savedState)则返回true,然后此时interruptMode有三种情况:
interruptMode为0,说明acquireQueued之前没发生过中断。interruptMode != THROW_IE判断成功。所以需要将interruptMode升级为REINTERRUPT。interruptMode为REINTERRUPT,说明acquireQueued之前发生过中断(signal流程在中断流程之前的那种)。interruptMode != THROW_IE判断成功。然后将interruptMode从REINTERRUPT变成REINTERRUPT,这好像是脱裤子放屁,但逻辑这样写就简洁了。interruptMode为THROW_IE,说明acquireQueued之前发生过中断(中断流程在signal流程之前的那种)。interruptMode != THROW_IE判断失败。不会去执行interruptMode = REINTERRUPT,因为执行了反而使得中断等级下降了。说到底,还是因为acquireQueued期间发生的中断,重要性不如acquireQueued之前发生的中断。
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
如果发现node的条件队列的nextWaiter还没有断开,则需要做一下善后处理。回想signal流程和中断流程:
- signal流程中(
signal和signalAll方法),都会执行first.nextWaiter = null;的,所以如果node线程之前走的是signal流程,那这里不会执行。 - 中断流程中,不会去执行
first.nextWaiter = null;的,所以如果node线程之前走的是中断流程,那这里会执行。
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
private void reportInterruptAfterWait(int interruptMode)
throws InterruptedException {
if (interruptMode == THROW_IE)
throw new InterruptedException();
else if (interruptMode == REINTERRUPT)
selfInterrupt(); // 返回用户代码之前,自我中断一下
}
最后根据interruptMode来判断做出不同的中断反应。
await()总结
await()对于使用者来说,进入await()时是持有锁的,阻塞后退出await()时也是持有锁的。signal() signalAll()也是一样。
从实现内部的持有锁情况来看:
await()在从开头到fullyRelease执行前,是持有锁的。await()在从fullyRelease执行后 到acquireQueued执行前,是没有持有锁的。await()在acquireQueued执行后到最后,是持有锁的。signal() signalAll()全程都是持有锁的。
await()的整体流程如下:
- 将当前线程包装成一个node后(
Node node = addConditionWaiter()),完全释放锁(int savedState = fullyRelease(node))。 - 当前线程阻塞在
LockSupport.park(this)处,等待signal线程或者中断线程的到来。 - 被唤醒后,到达
acquireQueued之前,当前线程的node已经置于sync queue之上了。 - 执行
acquireQueued,进行阻塞式的抢锁。 - 退出
acquireQueued时,当前线程已经重新获得了锁,之后进行善后工作。
awaitUninterruptibly()
前面介绍的await方法里,中断来临时会使得当前线程离开while循环进而去执行acquireQueued开始抢锁。换句话说,await方法允许,当前线程因为中断而不是因为signal,而最终退出await方法(毕竟acquireQueued最终还是会抢锁成功的)。
有时候我们希望,退出await方法的原因,只能是因为signal,所以就需要使用awaitUninterruptibly了。
public final void awaitUninterruptibly() {
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
boolean interrupted = false;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if (Thread.interrupted())
interrupted = true;
}
if (acquireQueued(node, savedState) || interrupted)
selfInterrupt();
}
首先看到awaitUninterruptibly不会抛出中断异常,我们拿它与await方法进行下对比:
public final void await() throws InterruptedException {
if (Thread.interrupted()) // 不同之处1
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0; // 不同之处2
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) // 不同之处3
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE) // 不同之处4
interruptMode = REINTERRUPT;
// 后面的善后工作全都不需要做了
if (node.nextWaiter != null) // 不同之处5
unlinkCancelledWaiters();
if (interruptMode != 0) // 不同之处6
reportInterruptAfterWait(interruptMode);
}
可以发现awaitUninterruptibly方法只是对await方法进行了大面积的删改:
- 函数开头不需要检查调用前是否被中断过了
- 用来记录中断状态的变量只需要记录两种状态(中断过,或没有中断),所以用
boolean变量就够了。 - 在while循环里,当前线程如果只是因为中断而被唤醒,那么消耗掉中断状态(
Thread.interrupted())。如果还没有signal线程的到来,那么当前线程的node还是不处于sync queue之上的,所以下次循环继续,然后又阻塞在LockSupport.park(this)这里。 - 如果抢锁过程中(
acquireQueued(node, savedState))发生过中断,或者抢锁之前发生过中断(|| interrupted),那么就自我中断一下。 - 不需要判断当前线程node在条件队列上的链接是否断开,因为
awaitUninterruptibly方法只会因为signal流程会退出while循环,而signal流程肯定会 断开条件队列上的链接的。 - 不需要执行
reportInterruptAfterWait了,因为自我中断已经做过了。
经过上面分析可以发现,awaitUninterruptibly方法全程都不会响应中断,不管是在抢锁过程之前还是之中发生过中断,都是只是简单地自我中断一下就好了。
而因为awaitUninterruptibly方法不会去执行checkInterruptWhileWaiting,所以要想满足退出while循环的条件!isOnSyncQueue(node)进而去执行acquireQueued开始抢锁,只能是因为signal流程中执行了transferForSignal(里面执行了enq(node),使得node入队了sync queue)。而从使用者的角度看,中断并不能使得线程从await调用处唤醒,只有执行了signal,线程才能从await调用处唤醒。
总结一下awaitUninterruptibly方法:
- 中断会唤醒当前线程,但当前线程的node还是不处于
sync queue之上,所以当前线程马上又会阻塞。 - 只有signal方法才可以使得当前线程的node处于
sync queue之上。 - 调用该方法中,如果发生了中断,会在返回用户代码之前,自我中断一下。
awaitNanos(long nanosTimeout)
前面的方法不管是await和awaitUninterruptibly,它们在while循环中如果一直没有中断线程或者signal线程的到来,会一直阻塞在while循环的park处。如果长时间signal线程一直不来,当前线程就会一直阻塞(一直阻塞就会一直不会去执行acquireQueued,也就不可能执行完函数了),所以此时我们可能需要一个带有超时机制的awaitNanos(long nanosTimeout),如果超时了就啥也不用管,直接去执行acquireQueued。
参数nanosTimeout,代表你最多愿意在这个方法等待多长时间。
返回值long,代表nanostimeout值 减去 花费在等待在此方法上的时间 的估算。
public final long awaitNanos(long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
final long deadline = System.nanoTime() + nanosTimeout; // 不同之处1
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) { // 不同之处2
transferAfterCancelledWait(node);
break;
}
if (nanosTimeout >= spinForTimeoutThreshold) // 不同之处3
LockSupport.parkNanos(this, nanosTimeout);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
nanosTimeout = deadline - System.nanoTime(); // 不同之处4
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return deadline - System.nanoTime(); // 不同之处5
}
让我们直接来看awaitNanos(long nanosTimeout)方法它与await()的不同之处:
- 需要计算出一个
deadline,作为是否超时的标准。 - 如果
LockSupport.parkNanos(this, nanosTimeout)之后的这段长达nanosTimeout的时间段内,既没有中断来临(不会进入if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)分支而break出循环),也没有signal来临(那么当前线程node还是不处于sync queue上,循环条件!isOnSyncQueue(node)通过),线程足足阻塞了nanosTimeout这么久才被唤醒,那么经过nanosTimeout = deadline - System.nanoTime()重新计算后,就肯定会进入到if (nanosTimeout <= 0L)分支,执行transferAfterCancelledWait将node入队同步队列,然后退出循环,开开心心地去执行acquireQueued就好了。 - 只有当
nanosTimeout >= spinForTimeoutThreshold,才可以阻塞当前线程,不然时间太短的话,就直接自旋就好了。这是因为考虑到阻塞线程和唤醒线程的过程,时间太短就不好控制了。注意进入这个分支的可能性:- 用户给的
nanosTimeout太小,第一次进入循环时,就开始自旋。 - 走了signal流程,signal流程在一定条件下唤醒了当前线程。但唤醒时剩余时间已经很少了。
- 走了signal流程,但没有唤醒当前线程。之后当前线程node已经成为了head后继,然后另一个线程执行了
unlock,唤醒了当前线程。但唤醒时剩余时间已经很少了。 - 不可能是走的中断流程。因为会直接break出循环,也就不会执行这个分支。
- 用户给的
nanosTimeout = deadline - System.nanoTime()计算出剩余时间还有多久。能执行到这里,说明之前肯定没有过中断。return deadline - System.nanoTime()返回剩余时间还有多久。
我们来总结下awaitNanos(long nanosTimeout)中能执行到acquireQueued的几种流程:
- 都已经超时了,且之前没有过中断,那么接下来就会去执行
acquireQueued,不过分两种情况:- 如果之前signal线程来过,signal线程就已经把当前线程node放到同步队列里去了,所以
!isOnSyncQueue(node)循环条件不成立,直接退出循环进而去执行的acquireQueued。 - 如果之前signal线程没有来过,
!isOnSyncQueue(node)循环条件成立,进入if (nanosTimeout <= 0L)分支去执行transferAfterCancelledWait让当前线程node先入队后,再去执行acquireQueued。
- 如果之前signal线程来过,signal线程就已经把当前线程node放到同步队列里去了,所以
- 因为来了中断,而去执行的
acquireQueued。这个过程和await()一样。 - 因为signal流程中的一定条件的唤醒,或因为执行
unlock的线程而唤醒。这两种情况,当前线程node都已经处于同步队列上了,所以循环条件不成立而退出循环,进而去执行的acquireQueued。
if (nanosTimeout <= 0L) {
transferAfterCancelledWait(node);
break;
}
当然,如果用户给的参数nanosTimeout本来就是<=0的,第一次循环就会直接将当前线程node加入到同步队列中,然后退出循环后进而执行acquireQueued。
总结一下awaitNanos(long nanosTimeout):相比await()方法,它能在超时后,无条件地去执行acquireQueued,而这不需要signal线程或中断线程的到来。
await(long time, TimeUnit unit)
理解了awaitNanos(long nanosTimeout),这个await(long time, TimeUnit unit)方法就好懂多了。从参数上就可以看出来,它只是对时间单位进行了拓展。我们直接看看它与awaitNanos(long nanosTimeout)的不同之处。
public final boolean await(long time, TimeUnit unit) //不同之处1
throws InterruptedException {
long nanosTimeout = unit.toNanos(time); //不同之处2
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
final long deadline = System.nanoTime() + nanosTimeout;
boolean timedout = false; //不同之处3
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {
timedout = transferAfterCancelledWait(node); //不同之处4
break;
}
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
nanosTimeout = deadline - System.nanoTime();
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return !timedout; //不同之处5
}
来分析一下不同之处:
- 返回值是
boolean型。 - 将时间最终都转换为nanos的时间。
- 增加了一个局部变量
timedout,代表退出while循环是否是因为超时才退出的。退出循环后会接着执行acquireQueued。 - 如果当前线程因为超时而唤醒,会进入到
if (nanosTimeout <= 0L)分支,之后如果transferAfterCancelledWait执行成功,会将局部变量timedout置为true,代表退出while循环是因为超时才退出的。 - 返回
!timedout,所以返回值为false,代表退出while循环是因为超时才退出的;返回值为true,代表退出while循环不是因为超时才退出的。
可以发现,await(long time, TimeUnit unit)的整个过程与awaitNanos(long nanosTimeout)几乎一样,只是返回值类型不一样了。但await(long time, TimeUnit unit)只关心退出while循环的原因,awaitNanos(long nanosTimeout)关心的是整个执行过程中花费的时间。
所以,并不能简单的认为,调用await(long time, TimeUnit unit) 等价于 调用awaitNanos(unit.toNanos(time)) > 0。比如考虑这种场景,假设没有中断,退出循环是因为signal线程来过才退出的循环,但直到执行unlock的线程来唤醒当前线程进而使得当前线程得到锁却很迟。此时:
awaitNanos(unit.toNanos(time))返回的值是小于0的,所以awaitNanos(unit.toNanos(time)) > 0返回false。await(long time, TimeUnit unit)退出while循环之前,不会去执行timedout = transferAfterCancelledWait(node),因为是直接不满足了循环条件!isOnSyncQueue(node)。所以timedout = false,返回!timedout,即返回的是true了。- 按照上面两点,发现二者不一致了。
awaitUntil(Date deadline)
这个方法其实和await(long time, TimeUnit unit)几乎一模一样,只是获得deadline的方式改变了而已,以前是自己计算出来。
public final boolean awaitUntil(Date deadline)
throws InterruptedException {
long abstime = deadline.getTime(); //不同之处1
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
// 此处不需要计算出deadline了,因为参数给了。 不同之处2
boolean timedout = false;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (System.currentTimeMillis() > abstime) { //不同之处3
timedout = transferAfterCancelledWait(node);
break;
}
LockSupport.parkUntil(this, abstime); //不同之处4
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return !timedout;
}
分析一下不同之处:
long abstime = deadline.getTime(),直接获得这个绝对时间。- 此处不需要计算出deadline了,因为参数给了。
- 以前是判断
deadline与当前系统时间 之间的差值。现在是比较deadline与当前系统时间 之间的大小。 - 相比之前两个超时版本,这里没有使用自旋优化,在剩余时间特别短的时候。所以调用这个方法时,最好给定的绝对时间比较远,才比较好。