一、介绍
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间。Beautiful Soup 3 目前已经停止开发,官网推荐在现在的项目中使用Beautiful Soup 4。
1、将pip源配置为国内源
- 需要将pip源设置为国内源,阿里源、豆瓣源、网易源等 - windows (1)打开文件资源管理器(文件夹地址栏中) (2)地址栏上面输入 %appdata% (3)在这里面新建一个文件夹 pip (4)在pip文件夹里面新建一个文件叫做 pip.ini ,内容写如下即可 [global] timeout = 6000 index-url = https://mirrors.aliyun.com/pypi/simple/ trusted-host = mirrors.aliyun.com - linux (1)cd ~ (2)mkdir ~/.pip (3)vi ~/.pip/pip.conf (4)编辑内容,和windows一模一样
2、安装Beautiful Soup
#安装 Beautiful Soup
pip install beautifulsoup4
#安装解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml:
$ apt-get install Python-lxml
$ easy_install lxml
$ pip install lxml
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
$ apt-get install Python-html5lib
$ easy_install html5lib
$ pip install html5lib
3、主流解析器对比
下表列出了主要的解析器,以及它们的优缺点,官网推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定。
| 解析器 | 使用方法 | 优势 | 劣势 |
| python标准库 | BeautifulSoup(markup, "html.parser") | Python的内置标准库 执行速度适中 文档容错能力强 |
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快 文档容错能力强 |
需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup,["lxml","xml"]) BeautifulSoup(markup, "xml") |
速度快 唯一支持XML的解析器 |
需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") | 最好的容错性 以浏览器的方式解析文档 生成HTML5格式的文档 |
速度慢 不依赖外部扩展 |
详情查看中文文档:Beautiful Soup 4.2.0 文档
二、基本使用
容错处理,文档的容错能力指的是在html代码不完整的情况下,使用该模块可以识别该错误。
使用BeautifulSoup解析不完整的html代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出。
核心思想:将html文档转换为BeautifulSoup对象,调用该对象中的属性和方法进行html文档指定内容定位查找。
1、使用流程
1、导包:from bs4 import BeautifulSoup 2、创建Beautiful对象: 如果html文档的来源是本地: Beautiful('open('本地的html文件')', 'lxml') 如果html是来源于网络: Beautiful('网络请求到的页面数据', 'lxml')
2、代码示例
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup=BeautifulSoup(html_doc,'lxml') #具有容错功能
res=soup.prettify() # 处理好缩进,结构化显示
print(res)
输出的结果补齐了缺失的html代码:
三、遍历文档树
遍历文档树即直接通过标签名字选择,特点是选择速度快,但如果存在多个相同的标签则只返回第一个。
html_doc = """
The Dormouse's story
asdf
The Dormouse's story总共
f
Once upon a time there were three little sisters; and their names were
Elsfie,
Lacie and
Tillie;
and they lived at the bottom of a well.
ad
sf
...
"""
# 1、用法
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc, features='lxml') #具有容错功能
# 2.name,根据标签名查找
# tag = soup.a
# name = tag.name # 获取标签名称
# print(name) # 输出:a
# tag.name = 'span' # 设置标签名称
# print(soup)
"""输出代码可看到第一个a标签修改为了span标签
Elsfie,
Lacie
"""
# 3.attrs,获取标签属性
# tag = soup.a
# attrs = tag.attrs # 获取标签属性
# print(attrs)
"""
{'class': ['sister0'], 'id': 'link1'}
"""
# tag.attrs = {'ik':123} # 清空并设置标签属性
# tag.attrs['id'] = 'iiiii' # 添加标签属性
# print(soup)
"""
Elsfie,
"""
# 4.string/text/get_text,获取标签的内容
# print(soup.p.string) # p下的文本只有一个时取到,否则为None
# print(soup.p.string) # 拿到一个生成器对象,取到p下所有的文本内容
# print(soup.p.text) # 取到p下所有的文本内容
# for line in soup.div.stripped_strings: # 去掉空白
# print(line)
"""
如果tag包含了多个子节点,tag就无法确定.string 方法应该调用哪个子节点的内容, .string 的输出结果是 None,
如果只有一个子节点那么就输出该子节点的文本,比如下面的这种结构,soup.p.string 返回为None,
但soup.p.strings和soup.p.get_text()就可以找到所有文本内容
"""
# 5.children,所有子节点
# body = soup.find('body')
# v = body.children # 得到一个迭代器,包含body下所有子节点
# for i, child in enumerate(v): # i只有9个
# print(i, child)
# 6.descendants,获取子孙节点
# body = soup.find('body') # 获取子孙节点,body下所有的标签都会选择出来
# v = body.descendants
# for i, child in enumerate(v): # i有30个
# print(i, child)
# 7.嵌套选择
# print(soup.head.title.string) # The Dormouse's story
# print(soup.body.a.string) # None
# 8.parent/parents, 父节点/祖先节点
# parent = soup.a.parent # 获取a标签父节点
# print(parent) # ...
# parents = soup.a.parents # 获取a标签所有祖先节点
# print(parents) #
# 9.next_sibling/previous_sibling,兄弟节点
n_s = soup.a.next_sibling # 下一个兄弟
print(n_s)
p_s = soup.a.previous_sibling # 上一个兄弟
print(p_s)
n_generator = list(soup.a.next_sibling) # 下面的兄弟们——》生成器对象
print(n_generator)
p_generator = soup.a.previous_sibling # 上面的兄弟们——》生成器对象
print(p_generator) 四、搜索文档树
BeautifulSoup定义了很多搜索方法,这里着重介绍2个:find()和find_all(),其他方法的参数和用法类似。
1、五种过滤器
html_doc = """
The Dormouse's story
asdf
The Dormouse's story总共
f
Once upon a time there were three little sisters; and their names were
Elsfie,
Lacie and
Tillie;
and they lived at the bottom of a well.
ad
sf
...
"""
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc, features='lxml') #具有容错功能
# 五种过滤器: 字符串、正则表达式、列表、True、方法
# 1、字符串: 标签名
# print(soup.find_all('b'))
"""
[The Dormouse's story总共]
"""
# 2、正则表达式
# import re
# print(soup.find_all(re.compile('^b$'))) # 找出b开头并结尾的标签
"""
[The Dormouse's story总共]
"""
# 3、列表: 如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有标签和标签:
# print(soup.find_all(['a', 'b']))
"""
[The Dormouse's story总共, Elsfie......
"""
# 4、True:可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点
# print(soup.find_all(True))
# for tag in soup.find_all(True):
# print(tag.name) # html head title等
# 5、方法:如果没有合适过滤器,那么还可以定义一个方法,方法只接受一个元素参数,
# 如果这个方法返回 True 表示当前元素匹配并且被找到,如果不是则反回 False
def has_class_but_no_id(tag):
return tag.has_attr("class") and not tag.has_attr("id")
print(soup.find_all(has_class_but_no_id))
"""
[..., ..., ...
]
"""
2、find_all(self, name=None, attrs={}, recursive=True, text=None,limit=None, **kwargs)
# 二、find_all()
# 1、name: 搜索name参数的值可以使任一类型的 过滤器 ,字符窜,正则表达式,列表,方法或是 True .
# print(soup.find_all(name=re.compile('^t')))
"""
[The Dormouse's story ]
"""
# 2、keyword: key=value的形式,value可以是过滤器:字符串,正则表达式,列表,True.
print(soup.find_all(id=re.compile('my')))
print(soup.find_all(href=re.compile('lacie'),id=re.compile('\d'))) # 注意类要用class_
print(soup.find_all(id=True)) # 查找有id属性的标签
# 有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性:
data_soup = BeautifulSoup('foo!','lxml')
# data_soup.find_all(data-foo="value") #报错:SyntaxError: keyword can't be an expression
# 但是可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag:
print(data_soup.find_all(attrs={"data-foo": "value"}))
# [foo!]
# 3、按照类名查找,注意关键字是class_,class_=value,value可以是五种选择器之一
print(soup.find_all('a',class_='sister')) # 查找类为sister的a标签
print(soup.find_all('a',class_='sister ssss')) # 查找类为sister和sss的a标签,顺序错误也匹配不成功
print(soup.find_all(class_=re.compile('^sis'))) # 查找类为sister的所有标签
# 4、attrs
print(soup.find_all('p',attrs={'class':'story'}))
# 5、text: 值可以是:字符,列表,True,正则
print(soup.find_all(text='Elsie'))
print(soup.find_all('a',text='Elsie'))
# 6、limit参数:如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.
# 效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果
print(soup.find_all('a',limit=2)) # 获取前两个符合条件的a标签
# 7、recursive:调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,
# 如果只想搜索tag的直接子节点,可以使用参数 recursive=False .
print(soup.html.find_all('a'))
print(soup.html.find_all('a',recursive=False))
'''
像调用 find_all() 一样调用tag
find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的:
soup.find_all("a")
soup("a")
这两行代码也是等价的:
soup.title.find_all(text=True)
soup.title(text=True)
'''
3、find(self, name=None, attrs={}, recursive=True, text=None,**kwargs)
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果。
比如文档中只有一个
标签,那么使用 find_all() 方法来查找标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法。下面两行代码是等价的:
print(soup.find_all("title", limit=1))
# [The Dormouse's story ]
print(soup.find("title"))
# The Dormouse's story
唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果(返回符合条件的第一个标签).
find_all() 方法没有找到目标是返回 空列表, find() 方法找不到目标时,返回 None .
print(soup.find("nosuchtag"))
"""
None
"""
soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法:
print(soup.head.title)
# The Dormouse's story
print(soup.find("head").find("title"))
# The Dormouse's story
4、其他详见官方文档
Beautiful Soup 4.2.0 文档
5、CSS选择器
该模块提供了select方法来支持css,详见官网:CSS选择器
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
Lacie and
Tillie;
- Foo
- Bar
- Jay
Foo
- Bar
- Jay
and they lived at the bottom of a well.
...
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
# 1、CSS选择器
# print(soup.p.select('.sister'))
# print(soup.select('.sister span'))
"""
[Elsie,
Lacie,
Tillie]
[Elsie]
"""
# print(soup.select('#link1'))
# print(soup.select('#link1 span'))
"""
[Elsie]
[Elsie]
"""
# print(soup.select('#list-2 .element.xxx'))
"""
[Bar ]
"""
# 可以一直select,但其实没必要,一条select就可以了
# print(soup.select('#list-2')[0].select('.element'))
"""
[Foo
Bar , Jay ]
"""
# 2、获取属性
# print(soup.select('#list-2 h1')[0].attrs)
"""
{'class': ['yyyy']}
"""
# 3、获取内容
print(soup.select('#list-2 h1')[0].get_text())
"""
Foo
"""注意:
(1)常见的选择器有:标签选择器、类选择器、id选择器、层级选择器。
(2)select选择器返回永远是列表,需要通过下标提取指定的对象。
(3)通过 class_ 参数搜索有指定CSS类名的tag
按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字 class 在Python中是保留字,使用 class 做参数会导致语法错误.从Beautiful Soup的4.1.1版本开始,可以通过 class_ 参数搜索有指定CSS类名的tag:
class_ 参数同样接受不同类型的 过滤器 ,字符串,正则表达式,方法或 True :
soup.find_all(class_=re.compile("itl")) # [The Dormouse's story
] def has_six_characters(css_class): return css_class is not None and len(css_class) == 6 soup.find_all(class_=has_six_characters) # [Elsie, # Lacie, # Tillie]
五、修改文档树
Beautiful Soup的强项是文档树的搜索,但同时也可以方便的修改文档树。
详见官网:修改文档树。
六、bs4项目演练
需求:爬取古诗文网中三国小说里的标题和内容。古诗文网三国演义网址
1、项目代码实现
import requests
from bs4 import BeautifulSoup
url = "http://www.shicimingju.com/book/sanguoyanyi.html"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
}
def get_content(url):
"""
根据url获取页面中指定的标题所对应的文章内容
:param url:
:return:
"""
content_page = requests.get(url=url, headers=headers).text
# 指定文章内容解析
soup = BeautifulSoup(content_page, 'lxml')
# 通过 class_ 参数搜索有指定CSS类名的tag
div = soup.find('div', class_='chapter_content')
return div.text
page_text = requests.get(url=url, headers=headers).text
# 数据解析
soup = BeautifulSoup(page_text, 'lxml')
a_list = soup.select('.book-mulu > ul > li > a') # 层级表达式定位到li标签下的a标签
# print(a_list)
"""a_list存储的一系列的a标签对象
[第一回·宴桃园豪杰三结义 斩黄巾英雄首立功,
...,
第一百二十回·荐杜预老将献新谋 降孙皓三分归一统]
"""
# print(type(a_list[0]))
"""
# 注意:Tag类型的对象可以继续调用响应的解析属性和方法进行局部数据的解析
"""
# 持久化存储
fp = open('./sanguo.txt', 'w', encoding='utf-8')
for a in a_list:
# 获取章节标题
title = a.string # Tag类型的对象可以继续调用响应的解析属性和方法进行局部数据的解析
# 获取章节url
content_url = 'http://www.shicimingju.com' + a['href']
# 获取章节内容
content = get_content(content_url)
# print(content)
fp.write(title + ':' + content + "\n\n\n")
print('写入一个章节内容')
2、实现效果
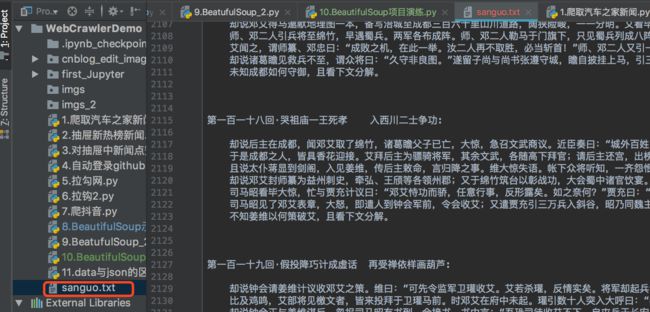
七、总结
1、推荐使用 lxml 解析库
2、讲了三种选择器:标签选择器,find与find_all,css选择器
1)标签选择器筛选功能弱,但是速度快;
2)建议使用find,find_all查询匹配单个结果或者多个结果;
3)如果对css选择器非常熟悉建议使用select。
3、记住常用的获取属性attrs和文本值get_text()的方法