python2.7-matplotlib柱状图-中文label
参考文档:
http://c.biancheng.net/view/2716.html
https://blog.csdn.net/skldecsdn/article/details/79655569
https://www.jianshu.com/p/01ed72b2aeee
https://www.cnblogs.com/yunxiaofei/p/11116941.html
http://landcareweb.com/questions/638/geng-gai-matplotlibzhong-xhuo-yzhou-shang-de-di-da-pin-lu
https://matplotlib.org/users/tight_layout_guide.html
##-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import matplotlib.pyplot as plt
import matplotlib
DIR_MAP = ['其他','前','后','右侧','左侧','侧前','侧后']
font = matplotlib.font_manager.FontProperties(fname='./simkai.ttf')
fig = plt.figure(1)
x = numpy.arange(len(DIR_MAP))
plt.xticks(x, DIR_MAP, fontproperties=font)
width = 0.25
plt.bar(x, npdir, width, color='g')
for a, b in zip(x, npdir):
plt.text(a, b, '%d' % b, fontsize=7)
plt.savefig('./'+ string + 'dir.png')字体下载地址:
http://down1.xiazaicc.com/down1/simkai_downcc.zip
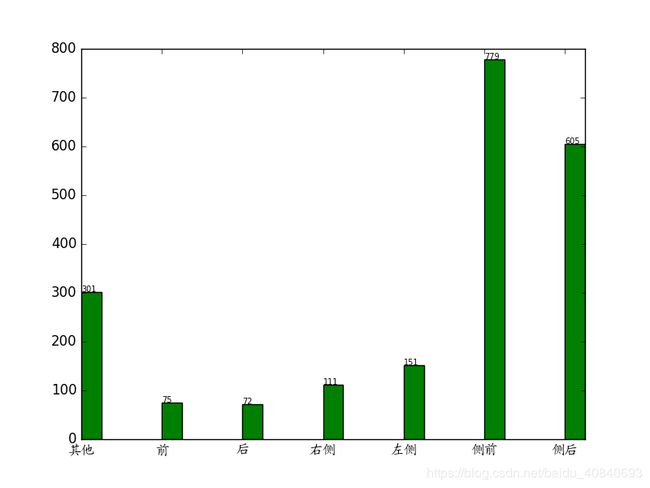
但是没有居中显示,更改代码:
##-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import matplotlib.pyplot as plt
import matplotlib
DIR_MAP = ['其他','前','后','右侧','左侧','侧前','侧后']
font = matplotlib.font_manager.FontProperties(fname='./simkai.ttf')
fig = plt.figure(1)
x = numpy.arange(len(DIR_MAP))
plt.xticks(x, DIR_MAP, fontproperties=font)
width = 0.25
plt.bar(x, npdir, width, color='g', align='center')
for a, b in zip(x, npdir):
plt.text(a, b, '%d' % b, fontsize=7, ha='center',va='bottom')
plt.savefig('./'+ string + 'dir.png')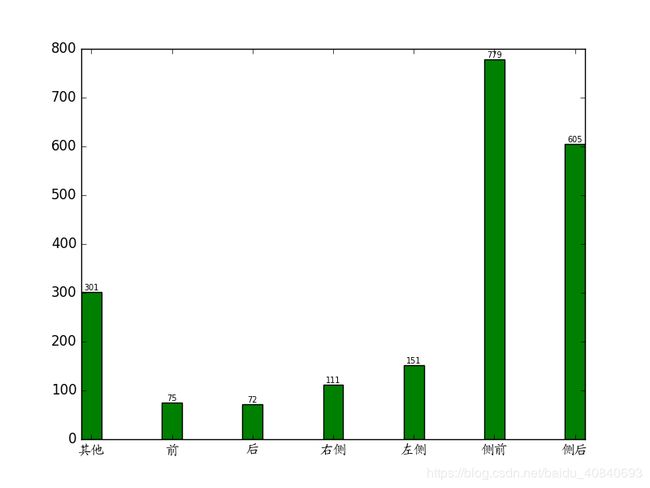
##-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import matplotlib.pyplot as plt
import matplotlib
DIR_MAP = ['其他','前','后','右侧','左侧','侧前','侧后']
font = matplotlib.font_manager.FontProperties(fname='./simkai.ttf')
fig = plt.figure(1)
x = numpy.arange(len(DIR_MAP))
plt.xticks(x, DIR_MAP, fontproperties=font)
width = 0.25
plt.bar(x, npdir, width, color='g', align='center')
for a, b in zip(x, npdir):
plt.text(a, b, '%d' % b, fontsize=7, ha='center',va='bottom')
plt.title(string + 'dir', fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.savefig('./'+ string + 'dir.png')
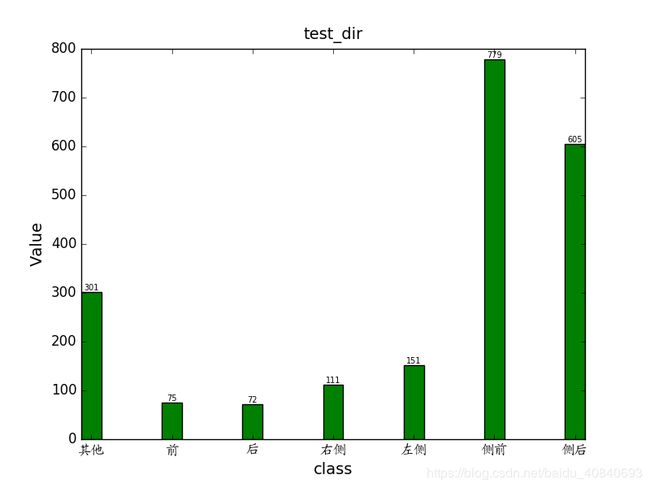
由于中文太长,要/n处理
但是又引入显示不完整的问题,一一解决:
def drawAnalysis(npdir,npcol,npcls,trainFlag):
font = matplotlib.font_manager.FontProperties(fname='./simkai.ttf')
if trainFlag==1:
string = 'train_'
else:
string = 'test_'
fig = plt.figure(1)
x = numpy.arange(len(DIR_MAP))
plt.xticks(x, DIR_MAP, fontproperties=font)
width = 0.25
plt.bar(x, npdir, width, color='g', align='center')
for a, b in zip(x, npdir):
plt.text(a, b, '%d' % b, fontsize=7, ha='center', va='bottom')
# 设置标题
plt.title(string + 'direction', fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.tight_layout()
plt.savefig('./'+ string + 'direction.png')
fig = plt.figure(2)
x = numpy.arange(len(COL_MAP))
plt.xticks(x, COL_MAP, fontproperties=font)
width = 0.25
plt.bar(x, npcol, width, color='g', align='center')
for a, b in zip(x, npcol):
plt.text(a, b, '%d' % b, fontsize=7, ha='center', va='bottom')
# 设置标题
plt.title(string + 'color', fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.tight_layout()
plt.savefig('./'+ string + 'color.png')
fig = plt.figure(3)
x = numpy.arange(len(CLS_MAP))
CLS_MAP_Temp = CLS_MAP
for k in range(len(CLS_MAP)):
lab = CLS_MAP[k]
temp = lab.decode("utf-8")
nlab = len(temp)
label = ''
for i in range(nlab):
if i != nlab-1:
label += (temp[i]+'\n')
else:
label += (temp[i])
label = label.encode("utf-8")
CLS_MAP_Temp[k] = label
plt.xticks(x, CLS_MAP_Temp, fontproperties=font, fontsize=7)
width = 0.5
plt.bar(x, npcls, width, color='g', align='center')
for a, b in zip(x, npcls):
plt.text(a, b, '%d' % b, fontsize=7, ha='center', va='bottom')
# 设置标题
plt.title(string + 'type', fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
#显示不完整的而处理
################
################
plt.tight_layout()
plt.savefig('./'+ string + 'type.png')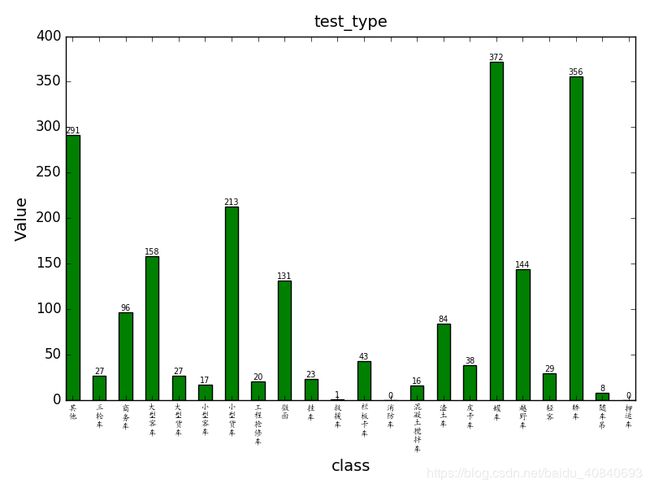
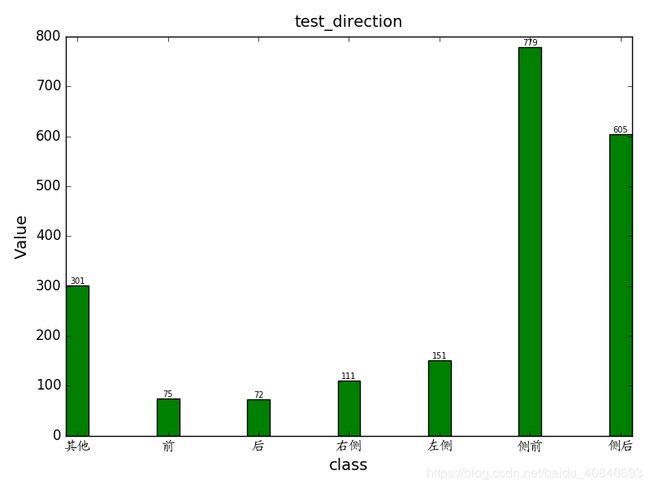
修改如果label太多,显示不全的问题,修改代码格式,改成双栏可显示
修改图的显示清晰度
##-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import os
import cv2
import random
import shutil
import numpy
from PIL import Image
import xml.etree.ElementTree as ET
import matplotlib.pyplot as plt
import matplotlib
import copy
DIR_MAP = ['其他','前','后','右侧','左侧','侧前','侧后']
COL_MAP = ['其他','棕','灰','白','粉','紫','红','绿','蓝','黄','黑']
CLS_MAP = ['其他','三轮车','商务车','大型客车','大型货车','小型客车','小型货车','工程抢修车','微面','挂车','救援车','栏板卡车','消防车','混凝土搅拌车','渣土车','皮卡车','罐车','越野车','轻客','轿车','随车吊','押运车']
CLS_MAP_Temp = CLS_MAP
for k in range(len(CLS_MAP)):
lab = CLS_MAP[k]
temp = lab.decode("utf-8")
nlab = len(temp)
label = ''
for i in range(nlab):
if i != nlab - 1:
label += (temp[i] + '\n')
else:
label += (temp[i])
label = label.encode("utf-8")
CLS_MAP_Temp[k] = label
def drawAnalysis(npdir,npcol,npcls,trainFlag,tedir=[],tecol=[],tecls=[]):
font = matplotlib.font_manager.FontProperties(fname='./simkai.ttf')
string = trainFlag
fig = plt.figure()
x = numpy.arange(len(DIR_MAP))
plt.xticks(x, DIR_MAP, fontproperties=font)
width = 0.25
plt.bar(x, npdir, width, color='g', align='center')
if(len(tedir) > 0):
plt.bar(x+width, tedir, width, color='r', align='center')
for a, b in zip(x, tedir):
plt.text(a+width, b, '%d' % b, fontsize=7, ha='center', va='bottom')
for a, b in zip(x, npdir):
plt.text(a, b, '%d' % b, fontsize=7, ha='center', va='bottom')
# 设置标题
plt.title(string + 'direction', fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.tight_layout()
plt.savefig('./'+ string + 'direction.png', dpi=150, bbox_inches = 'tight')
fig = plt.figure()
x = numpy.arange(len(COL_MAP))
plt.xticks(x, COL_MAP, fontproperties=font)
width = 0.25
plt.bar(x, npcol, width, color='g', align='center')
if(len(tecol) > 0):
plt.bar(x+width, tecol, width, color='r', align='center')
for a, b in zip(x, tecol):
plt.text(a+width, b, '%d' % b, fontsize=7, ha='center', va='bottom')
for a, b in zip(x, npcol):
plt.text(a, b, '%d' % b, fontsize=7, ha='center', va='bottom')
# 设置标题
plt.title(string + 'color', fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.tight_layout()
plt.savefig('./'+ string + 'color.png', dpi=150, bbox_inches = 'tight')
fig = plt.figure()
x = numpy.arange(len(CLS_MAP))
plt.xticks(x, CLS_MAP_Temp, fontproperties=font, fontsize=7)
width = 0.5
plt.bar(x, npcls, width, color='g', align='center')
if(len(tecls) > 0):
plt.bar(x+width, tecls, width, color='r', align='center')
for a, b in zip(x, tecls):
plt.text(a+width, b, '%d' % b, fontsize=7, ha='center', va='bottom')
for a, b in zip(x, npcls):
plt.text(a, b, '%d' % b, fontsize=7, ha='center', va='bottom')
# 设置标题
plt.title(string + 'type', fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
#显示不完整的而处理
################
################
plt.tight_layout()
plt.savefig('./'+ string + 'type.png', dpi=150, bbox_inches = 'tight')
def proberect(txt):
f = open(txt)
lines = f.readlines()
dir = [0] * 7
col = [0] * 11
cls = [0] * 22
count = len(lines)
num = 0
for box in lines:
num += 1
print num, " / ", count
box = box.replace('\n', '')
box = box.replace('\t', '')
box = box.split(' ')
copybox = box
box = box[1:4]
#a = DIR_MAP.index(box[0])
dir[int(box[0])] += 1
col[int(box[1])] += 1
cls[int(box[2])] += 1
return dir,col,cls
# string = 'train_'
# string = 'test_'
# string = 'train_test_'
dir_test,col_test,cls_test = proberect('./testall.txt')
#数据分析
npdir_test = numpy.array(dir_test)
npcol_test = numpy.array(col_test)
npcls_test = numpy.array(cls_test)
drawAnalysis(npdir_test, npcol_test, npcls_test,'test_')
dir_train,col_train,cls_train = proberect('./trainall.txt')
#数据分析
npdir_train = numpy.array(dir_train)
npcol_train = numpy.array(col_train)
npcls_train = numpy.array(cls_train)
drawAnalysis(npdir_train, npcol_train, npcls_train,'train_')
dir = [a+b for a, b in zip(dir_test,dir_train)]
col = [a+b for a, b in zip(col_test,col_train)]
cls = [a+b for a, b in zip(cls_test,cls_train)]
npdir = numpy.array(dir)
npcol = numpy.array(col)
npcls = numpy.array(cls)
drawAnalysis(npdir, npcol, npcls,'train_test_')
drawAnalysis(npdir_test, npcol_test, npcls_test,'all_',npdir_train, npcol_train, npcls_train)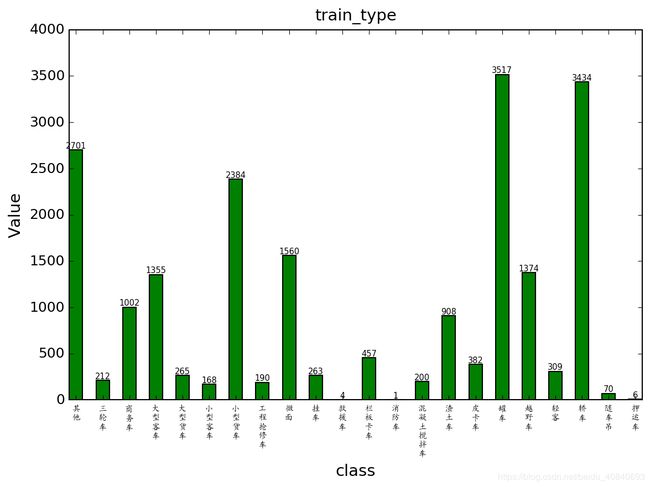
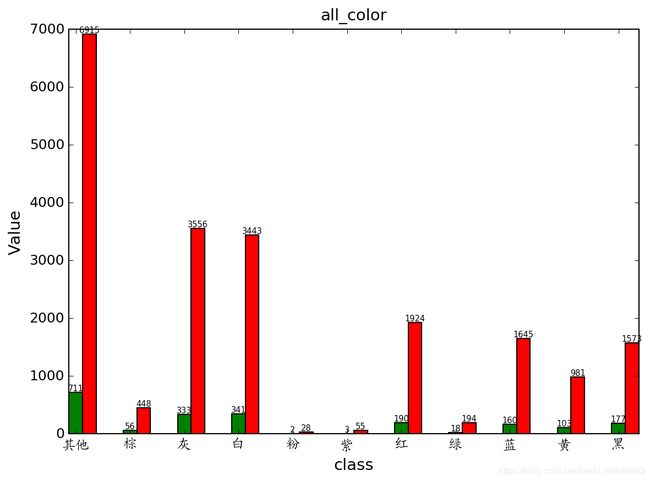
一个label三个分支的情况:
##-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import os
import cv2
import random
import shutil
import numpy
from PIL import Image
import xml.etree.ElementTree as ET
import matplotlib.pyplot as plt
import matplotlib
import copy
#[未知,是,否,其他]
CLS_MAP = ["主架是否有人","主架安全带","主架遮阳板","主架打电话","副架是否有人","副架安全带","副架遮阳板","附加打电话"]
CLS_MAP_Temp = CLS_MAP
for k in range(len(CLS_MAP)):
lab = CLS_MAP[k]
temp = lab.decode("utf-8")
nlab = len(temp)
label = ''
for i in range(nlab):
if i != nlab - 1:
label += (temp[i] + '\n')
else:
label += (temp[i])
label = label.encode("utf-8")
CLS_MAP_Temp[k] = label
def drawAnalysis(npdir,npcol,npcls,trainFlag):
font = matplotlib.font_manager.FontProperties(fname='./simkai.ttf')
string = trainFlag
fig = plt.figure()
x = numpy.arange(len(CLS_MAP))
plt.xticks(x, CLS_MAP_Temp, fontproperties=font, fontsize=7)
width = 0.3
plt.bar(x, npdir, width, color='g', align='center')
plt.bar(x+width, npcol, width, color='r', align='center')
plt.bar(x+2*width, npcls, width, color='b', align='center')
for a, b in zip(x, npdir):
plt.text(a, b, '%d' % b, fontsize=7, ha='center', va='bottom')
for a, b in zip(x, npcol):
plt.text(a+width, b, '%d' % b, fontsize=7, ha='center', va='bottom')
for a, b in zip(x, npcls):
plt.text(a+2*width, b, '%d' % b, fontsize=7, ha='center', va='bottom')
# 设置标题
plt.title(string + '未知-是-否', fontproperties=font, fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
#显示不完整的而处理
################
################
plt.tight_layout()
plt.savefig('./'+ string + 'type.png', dpi=150, bbox_inches = 'tight')
def proberect(txt):
f = open(txt)
lines = f.readlines()
dir = [0] * 8
col = [0] * 8
cls = [0] * 8
count = len(lines)
num = 0
for box in lines:
num += 1
print num, " / ", count
box = box.replace('\n', '')
box = box.replace('\t', '')
box = box.split(' ')
copybox = box
box = box[1:]
#a = DIR_MAP.index(box[0])
for i in range(0,len(box),3):
temp= box[i:i+3]
temp = numpy.array(temp)
index = temp.argsort()[-1]
key = i/3
if index==0:
dir[key] += 1 #未知是否
if index==1:
col[key] += 1
if index == 2:
cls[key] += 1
return dir,col,cls
# string = 'train_'
# string = 'test_'
# string = 'train_test_'
dir_test,col_test,cls_test = proberect('./srn_label_train.txt')
#数据分析
npdir_test = numpy.array(dir_test)
npcol_test = numpy.array(col_test)
npcls_test = numpy.array(cls_test)
drawAnalysis(npdir_test, npcol_test, npcls_test,'train_')
dir_train,col_train,cls_train = proberect('./srn_label_valid.txt')
#数据分析
npdir_train = numpy.array(dir_train)
npcol_train = numpy.array(col_train)
npcls_train = numpy.array(cls_train)
drawAnalysis(npdir_train, npcol_train, npcls_train,'valid_')
dir = [a+b for a, b in zip(dir_test,dir_train)]
col = [a+b for a, b in zip(col_test,col_train)]
cls = [a+b for a, b in zip(cls_test,cls_train)]
npdir = numpy.array(dir)
npcol = numpy.array(col)
npcls = numpy.array(cls)
drawAnalysis(npdir, npcol, npcls,'train_valid_')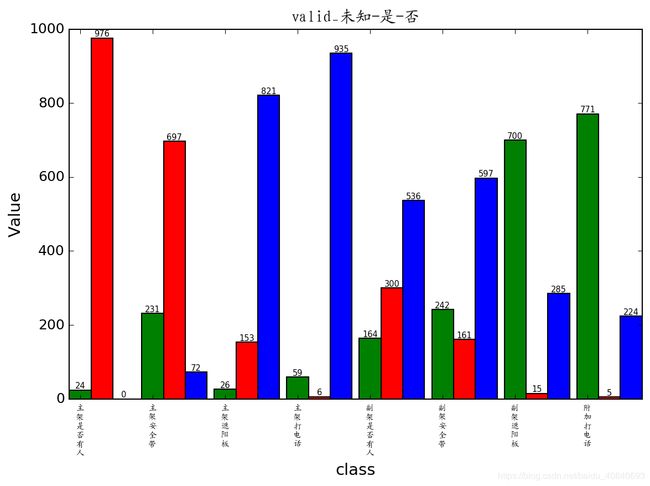
关于ccpd的分布情况,有点挤
通过设置画布大小和改变数字坐落位置:
fig = plt.figure(figsize=(12,4))如果希望matplotlib 柱状图 数据标签往上一点
for a, b in zip(x, npdir):
plt.text(a, b + 5000, '%d' % b, fontsize=5, ha='center', va='bottom') 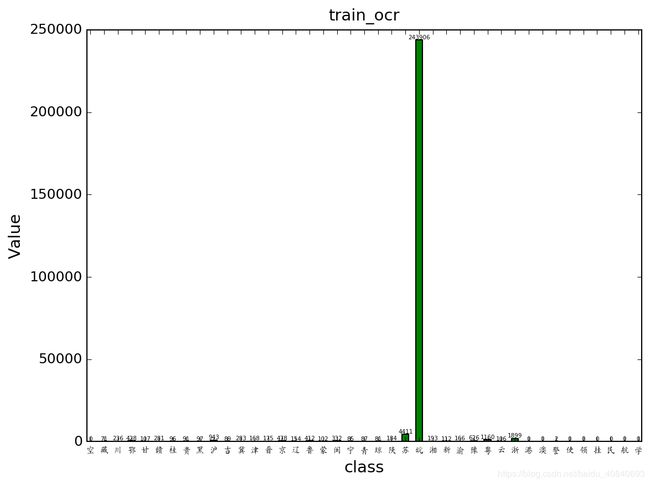
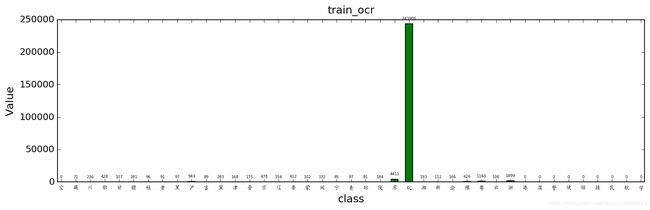
def drawAnalysis(npdir,trainFlag):
maxValue = max(npdir)
font = matplotlib.font_manager.FontProperties(fname='./simkai.ttf')
string = trainFlag
fig = plt.figure(figsize=(12,4))
x = numpy.arange(len(CLS_MAP))
plt.xticks(x, CLS_MAP, fontproperties=font,fontsize=7)
width = 0.5
plt.bar(x, npdir, width, color='g', align='center')
for a, b in zip(x, npdir):
plt.text(a, b + maxValue*0.01, '%d' % b, fontsize=5, ha='center', va='bottom')
# 设置标题
plt.title(string + 'ocr', fontsize=14, ha='center', va='bottom')
plt.xlabel('class', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.tight_layout()
plt.savefig('./'+ string + 'ocr.png', dpi=150, bbox_inches = 'tight')有一个需求,对2000类的属性进行统计:
但是保存成png太不清晰了,调整dpi会导致图片特别大:

我们把他保存成pdf,会非常清楚
from matplotlib.backends.backend_pdf import PdfPages
plt.savefig('./'+ string + 'car_2000.pdf', dpi=150, bbox_inches = 'tight')
plt.close()PDF虽然已经非常清晰了,但是不够方便,我们把字典保存在excel中比较方便:
import xlwt
workbook = xlwt.Workbook(encoding='utf-8')
#创建表
worksheet = workbook.add_sheet('sheet1')
#往单元格内写入内容:写入表头
worksheet.write(0, 0, label="word")
worksheet.write(0, 1, label="frequency")
# 往单元格内写入内容:写入内容
i=1
for word in npdir:
worksheet.write(i, 0, label=word)
worksheet.write(i, 1, label=npdir[word])
i=i+1
workbook.save('Excel_Workbook.xls')
print 'Excel结束'
