cocos2dx-实现CCDictionary的hash库uthash详解
uthash详解
CCDictionary底层用的是uthash,追踪CCDictionary的接口,查看CCDictionary是如何利用uthash的接口的,以及uthash是怎么实现的。
下面是uthash的类图:
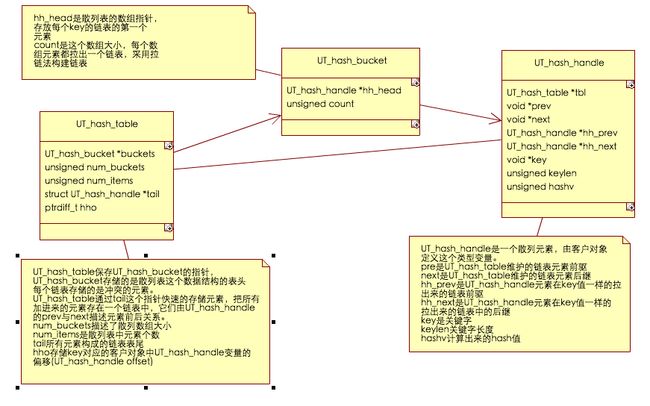
tail方便uthash快速索引所有对象,每个bucket就是一个拉链法hash表的一个链表。客户变量m_pElements指向客户所有加入uthash中的客户对象构成的链表第一个元素,客户对象包含了uthash中的对象
这里客户对象指用户创建的包含UT_hash_handle类型成员的对象,uthash中的对象指被包含的UT_hash_handle类型成员。下面是对象间的关系图:
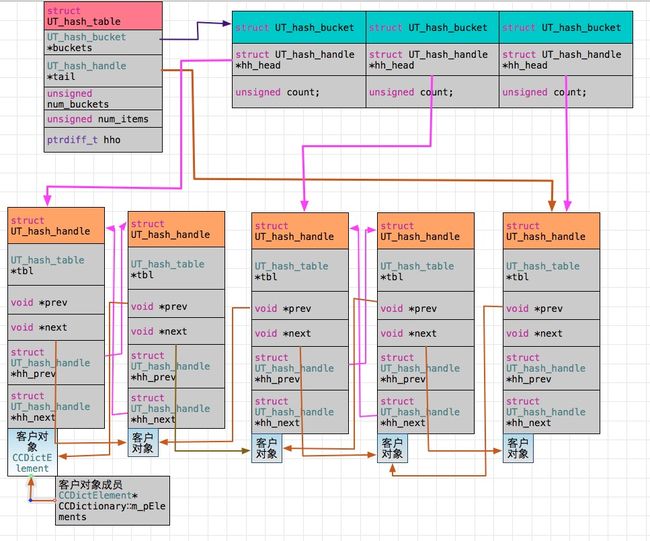
查看下面代码:
void CCDictionary::setObject(CCObject* pObject, const std::string& key)
{
CCAssert(key.length() > 0 && pObject != NULL, "Invalid Argument!");
if (m_eDictType == kCCDictUnknown)
{
m_eDictType = kCCDictStr;
}
CCAssert(m_eDictType == kCCDictStr, "this dictionary doesn't use string as key.");
CCDictElement *pElement = NULL;
HASH_FIND_STR(m_pElements, key.c_str(), pElement);
if (pElement == NULL)
{
setObjectUnSafe(pObject, key);
}
else if (pElement->m_pObject != pObject)
{
CCObject* pTmpObj = pElement->m_pObject;
pTmpObj->retain();
removeObjectForElememt(pElement);
setObjectUnSafe(pObject, key);
pTmpObj->release();
}
}上面先调用HASH_FIND_STR(m_pElements, key.c_str(), pElement);查看m_pElements关联的hash表中是否存在key为key.c_str()的元素,有就写入pElement
下面是uthash中三个最重要结构,uthash采用了拉链法,其中UT_hash_table是hash的表结构,它的主要作用是存放hash数组的指针,每个数组元素保存一个UT_hash_bucket,这个结构就是key对应的一个槽,它保存了具有相同key构成的链表指针,这个链表就是拉链法中为了防止冲突创建的链表。UT_hash_table还保存了每个key对应的对象中的UT_hash_handle类型的元素指针。uthash不直接保存客户的对象指针,而是要求客户对象中必须包含UT_hash_handle这个类型变量。这个变量才是hash表中的散列元素。通过客户给的key找到UT_hash_handle变量,然后根据UT_hash_handle在客户定义的结构中的地址偏移计算出客户对象的地址,然后返回给客户。UT_hash_table还有一个作用,它有一个链表,表尾是tail,所有刚加进来的对象的UT_hash_handle指针都作为这个链表的表尾,它用来快速添加一个元素。加到这个链表后,还要根据key,把UT_hash_handle放到一个对应的槽中。
HASH_FIND_STR(m_pElements, key.c_str(), pElement);中m_pElements与pElement的类型如下:
class CC_DLL CCDictElement
private:
// The max length of string key.
#define MAX_KEY_LEN 256
// char array is needed for HASH_ADD_STR in UT_HASH.
// So it's a pain that all elements will allocate 256 bytes for this array.
char m_szKey[MAX_KEY_LEN]; // hash key of string type
intptr_t m_iKey; // hash key of integer type
CCObject* m_pObject; // hash value
public:
UT_hash_handle hh; // makes this class hashable
friend class CCDictionary; // declare CCDictionary as friend class
};上面只给出CCDictElement的成员变量,其中包含了UT_hash_handle hh;CCDictElement为客户结构,它必须定义UT_hash_handle变量。
HASH_FIND_STR(m_pElements, key.c_str(), pElement);代码如下:
#define HASH_FIND_STR(head,findstr,out) \
HASH_FIND(hh,head,findstr,strlen(findstr),out)
#define HASH_FIND(hh,head,keyptr,keylen,out) \
do { \
unsigned _hf_bkt,_hf_hashv; \
out=NULL; \
if (head) { \
HASH_FCN(keyptr,keylen, (head)->hh.tbl->num_buckets, _hf_hashv, _hf_bkt); \
if (HASH_BLOOM_TEST((head)->hh.tbl, _hf_hashv)) { \
HASH_FIND_IN_BKT((head)->hh.tbl, hh, (head)->hh.tbl->buckets[ _hf_bkt ], \
keyptr,keylen,out); \
} \
} \
} while (0)HASH_FIND_STR是一个宏,传入的是客户对象head,查找关键字findstr,输出对象out
HASH_FIND则根据ASH_FIND_STR可知,hh是客户对象head的UT_hash_handle类型成员,head,findstr,out如上,strlen(findstr)是关键字长度,所以findstr必须是个字符串
if (head)里面先进行HASH_FCN(keyptr,keylen, (head)->hh.tbl->num_buckets, _hf_hashv, _hf_bkt)查找得到关键字的hash值_hf_hashv,以及对象的链表槽_hf_bkt,代码如下:
#ifdef HASH_FUNCTION
#define HASH_FCN HASH_FUNCTION
#else
#define HASH_FCN HASH_JEN //进入这个分支
#endif
//HASH_JEN定义如下:
#define HASH_JEN(key,keylen,num_bkts,hashv,bkt) \
do { \
unsigned _hj_i,_hj_j,_hj_k; \
unsigned char *_hj_key=(unsigned char*)(key); \
hashv = 0xfeedbeef; \
_hj_i = _hj_j = 0x9e3779b9; \
_hj_k = (unsigned)keylen; \
while (_hj_k >= 12) { \
_hj_i += (_hj_key[0] + ( (unsigned)_hj_key[1] << 8 ) \
+ ( (unsigned)_hj_key[2] << 16 ) \
+ ( (unsigned)_hj_key[3] << 24 ) ); \
_hj_j += (_hj_key[4] + ( (unsigned)_hj_key[5] << 8 ) \
+ ( (unsigned)_hj_key[6] << 16 ) \
+ ( (unsigned)_hj_key[7] << 24 ) ); \
hashv += (_hj_key[8] + ( (unsigned)_hj_key[9] << 8 ) \
+ ( (unsigned)_hj_key[10] << 16 ) \
+ ( (unsigned)_hj_key[11] << 24 ) ); \
\
HASH_JEN_MIX(_hj_i, _hj_j, hashv); \
\
_hj_key += 12; \
_hj_k -= 12; \
} \
hashv += keylen; \
switch ( _hj_k ) { \
case 11: hashv += ( (unsigned)_hj_key[10] << 24 ); \
case 10: hashv += ( (unsigned)_hj_key[9] << 16 ); \
case 9: hashv += ( (unsigned)_hj_key[8] << 8 ); \
case 8: _hj_j += ( (unsigned)_hj_key[7] << 24 ); \
case 7: _hj_j += ( (unsigned)_hj_key[6] << 16 ); \
case 6: _hj_j += ( (unsigned)_hj_key[5] << 8 ); \
case 5: _hj_j += _hj_key[4]; \
case 4: _hj_i += ( (unsigned)_hj_key[3] << 24 ); \
case 3: _hj_i += ( (unsigned)_hj_key[2] << 16 ); \
case 2: _hj_i += ( (unsigned)_hj_key[1] << 8 ); \
case 1: _hj_i += _hj_key[0]; \
} \
HASH_JEN_MIX(_hj_i, _hj_j, hashv); \
bkt = hashv & (num_bkts-1); \
} while(0)上面是hash值的计算函数,这里不研究计算hash值得算法。计算最后得到hashv,由hashv计算得到key的槽位置bkt,注意这里是宏,会扩展hashv扩展为_hf_hashv,bkt扩展为_hf_bkt。
if (HASH_BLOOM_TEST((head)->hh.tbl, _hf_hashv))中HASH_BLOOM_TEST代码如下:
#define HASH_BLOOM_TEST(tbl,hashv) (1)//这个是在一个#ifdef #else #endif的#else分支中的定义,所有if (HASH_BLOOM_TEST((head)->hh.tbl, _hf_hashv))永远为trueHASH_FIND_IN_BKT((head)->hh.tbl, hh, (head)->hh.tbl->buckets[ _hf_bkt ], keyptr,keylen,out);是在槽中查找,最后输出out。现在(head)->hh.tbl是客户对象m_pElements中hh的变量tbl,它保指向UT_hash_table,uthash中每一个UT_hash_handle都保存了UT_hash_table的指针。hh是客户对象的hh,(head)->hh.tbl->buckets[ _hf_bkt ]是UT_hash_table存储的UT_hash_bucket中的一个成员(拉链槽),keyptr,keylen,out分别是关键字字符串、字符串长度、最终输出对象。HASH_FIND_IN_BKT代码如下:
#define HASH_FIND_IN_BKT(tbl,hh,head,keyptr,keylen_in,out) \
do { \
if (head.hh_head) DECLTYPE_ASSIGN(out,ELMT_FROM_HH(tbl,head.hh_head)); \
else out=NULL; \
while (out) { \
if ((out)->hh.keylen == keylen_in) { \
if ((HASH_KEYCMP((out)->hh.key,keyptr,keylen_in)) == 0) break; \
} \
if ((out)->hh.hh_next) DECLTYPE_ASSIGN(out,ELMT_FROM_HH(tbl,(out)->hh.hh_next)); \
else out = NULL; \
} \
} while(0)if (head.hh_head) DECLTYPE_ASSIGN(out,ELMT_FROM_HH(tbl,head.hh_head)); 中head.hh_head就是链表槽UT_hash_bucket的成员hh_head,它是拉链表的表头。
ELMT_FROM_HH(tbl,head.hh_head)代码如下:
#define ELMT_FROM_HH(tbl,hhp) ((void*)(((char*)(hhp)) - ((tbl)->hho)))上面hhp是head.hh_head,表示链表槽中第一个元素UT_hash_handle的地址,((tbl)->hho)是UT_hash_table的存储的UT_hash_handle在客户定义的结构对象中的偏移,所有(((char*)(hhp)) - ((tbl)->hho)))将得到客户对象的指针,
这就说明了为什么客户结构中必须定义UT_hash_table的一个原因了。
DECLTYPE_ASSIGN代码如下:
//...省略#ifdef部分
#else
#define DECLTYPE_ASSIGN(dst,src) //进入这个分支 \
do { \
(dst) = DECLTYPE(dst)(src); \
} while(0)
#endif
//DECLTYPE定义
#define DECLTYPE(x) (__typeof(x))上面就是把src转化为dst的类型,因为ELMT_FROM_HH(tbl,hhp) 得到的是void*类型,所以要坐下类型转换。此时out=DECLTYPE(out)ELMT_FROM_HH(tbl,head.hh_head),out将是key对应的客户元素,这个时候还要检查key是否相等,因为不同key计算出的hash值可以得到相同的链表槽位置。
上面while (out)部分就是遍历链表槽,if ((out)->hh.keylen == keylen_in)if ((HASH_KEYCMP((out)->hh.key,keyptr,keylen_in)) == 0) break; 表示key的长度与值一样就把out返回,HASH_KEYCMP代码如下:
#define HASH_KEYCMP(a,b,len) memcmp(a,b,len)上面比较a与b前len字节是否一样。
if ((out)->hh.hh_next) DECLTYPE_ASSIGN(out,ELMT_FROM_HH(tbl,(out)->hh.hh_next));就是把out指向下一个链表槽中元素。
上面是HASH_FIND_STR(m_pElements, key.c_str(), pElement);的代码分析,可以发现它就是根据这个关键字计算出hash值与拉链表的位置,然后遍历这个链表找出key一样的对象返回给客户。需要注意的是客户的对象地址是根据链表中元素的地址减去它在客户定义的结构中的偏移得到的。
下面再继续研究下HASH_ADD_STR,上面如果没有在hash表中找到关键字对应客户对象,则会调用setObjectUnSafe(pObject, key);代码如下:
void CCDictionary::setObjectUnSafe(CCObject* pObject, const std::string& key)
{
pObject->retain();
CCDictElement* pElement = new CCDictElement(key.c_str(), pObject);
HASH_ADD_STR(m_pElements, m_szKey, pElement);
}上面会把对象retain,removeObjectForElememt中会release,retain/release必须成对出现,不然内存会泄露。
HASH_ADD_STR(m_pElements, m_szKey, pElement);会将pElement中的的hh插入m_pElements关联的hash表中,代码如下:
#define HASH_ADD_STR(head,strfield,add) \
HASH_ADD(hh,head,strfield,strlen(add->strfield),add)
//HASH_ADD
#define HASH_ADD(hh,head,fieldname,keylen_in,add) \
HASH_ADD_KEYPTR(hh,head,&((add)->fieldname),keylen_in,add)
//HASH_ADD_KEYPTR
#define HASH_ADD_KEYPTR(hh,head,keyptr,keylen_in,add) \
do { \
unsigned _ha_bkt; \
(add)->hh.next = NULL; \
(add)->hh.key = (char*)keyptr; \
(add)->hh.keylen = (unsigned)keylen_in; \
if (!(head)) { \
head = (add); \
(head)->hh.prev = NULL; \
HASH_MAKE_TABLE(hh,head); \
} else { \
(head)->hh.tbl->tail->next = (add); \
(add)->hh.prev = ELMT_FROM_HH((head)->hh.tbl, (head)->hh.tbl->tail); \
(head)->hh.tbl->tail = &((add)->hh); \
} \
(head)->hh.tbl->num_items++; \
(add)->hh.tbl = (head)->hh.tbl; \
HASH_FCN(keyptr,keylen_in, (head)->hh.tbl->num_buckets, \
(add)->hh.hashv, _ha_bkt); \
HASH_ADD_TO_BKT((head)->hh.tbl->buckets[_ha_bkt],&(add)->hh); \
HASH_BLOOM_ADD((head)->hh.tbl,(add)->hh.hashv); \
HASH_EMIT_KEY(hh,head,keyptr,keylen_in); \
HASH_FSCK(hh,head); \
} while(0)直接展开HASH_ADD_KEYPTR(hh,head,keyptr,keylen_in,add)中hh是head的hh,head是m_pElements,keyptr是m_szKey关键字字符串,keylen_in字符串长度,add是pElement。
pElement是由客户建立的对象,(add)->hh.next = NULL; (add)->hh.key = (char*)keyptr; (add)->hh.keylen = (unsigned)keylen_in; 设置pElement的相关变量值。
if (!(head)) 如果m_pElements为NULL,这个时候让m_pElements=pElement,用刚创建的客户对象作为tail表的表头。(head)->hh.prev = NULL;显然表头没有前驱。HASH_MAKE_TABLE(hh,head);构建hash表,代码如下:
#define HASH_MAKE_TABLE(hh,head) \
do { \
(head)->hh.tbl = (UT_hash_table*)uthash_malloc( \
sizeof(UT_hash_table)); \
if (!((head)->hh.tbl)) { uthash_fatal( "out of memory"); } \
memset((head)->hh.tbl, 0, sizeof(UT_hash_table)); \
(head)->hh.tbl->tail = &((head)->hh); \
(head)->hh.tbl->num_buckets = HASH_INITIAL_NUM_BUCKETS; \
(head)->hh.tbl->log2_num_buckets = HASH_INITIAL_NUM_BUCKETS_LOG2; \
(head)->hh.tbl->hho = (char*)(&(head)->hh) - (char*)(head); \
(head)->hh.tbl->buckets = (UT_hash_bucket*)uthash_malloc( \
HASH_INITIAL_NUM_BUCKETS*sizeof(struct UT_hash_bucket)); \
if (! (head)->hh.tbl->buckets) { uthash_fatal( "out of memory"); } \
memset((head)->hh.tbl->buckets, 0, \
HASH_INITIAL_NUM_BUCKETS*sizeof(struct UT_hash_bucket)); \
HASH_BLOOM_MAKE((head)->hh.tbl); \
(head)->hh.tbl->signature = HASH_SIGNATURE; \
} while(0)上面展开head为m_pElements。(head)->hh.tbl = (UT_hash_table*)uthash_malloc(sizeof(UT_hash_table));为UT_hash_tab分配内存。m_pElements此时指向刚创建的pElement,即(pElement)->hh.tbl = (UT_hash_table*)uthash_malloc(sizeof(UT_hash_table));
(head)->hh.tbl->tail = &((head)->hh); 设置hash表的tail为第一个hash元素的指针,之前讲过UT_hash_table用tail来快速添加节点,tail维持了所有元素构成的一个链表,这里tail保存的是hh的指针,是uthash中UT_hash_handle类型指针,而不是客户类型指针。
(head)->hh.tbl->num_buckets = HASH_INITIAL_NUM_BUCKETS;表示初始链表槽数,#define HASH_INITIAL_NUM_BUCKETS 32,所有初始大小为32
(head)->hh.tbl->hho = (char*)(&(head)->hh) - (char*)(head); 得到hh在head中的偏移值,就是根据它计算客户对象地址的,因为hash只保存UT_hash_handle指针,客户指针并不保存。
(head)->hh.tbl->buckets = (UT_hash_bucket*)uthash_malloc(HASH_INITIAL_NUM_BUCKETS*sizeof(struct UT_hash_bucket)); 为链表槽数组分配内存
HASH_BLOOM_MAKE((head)->hh.tbl); 进入#define HASH_BLOOM_MAKE(tbl) 不做任何事
(head)->hh.tbl->signature = HASH_SIGNATURE; 这里用不到,用于额外分析。
到此一个UT_hash_tab创建好了。
HASH_ADD_KEYPTR的else部分表示UT_hash_tab已经存在,此时不需要创建UT_hash_tab,代码分析如下:
(head)->hh.tbl->tail->next = (add); 把add这个客户对象加到UT_hash_tab的tail链表表尾,next是void*类型,存放的客户类型
(add)->hh.prev = ELMT_FROM_HH((head)->hh.tbl, (head)->hh.tbl->tail);新添的客户对象前驱为链表尾对象关联的客户对象,prev类型也是void*
上面可以看到,UT_hash_table的tail存储的是客户对象中hh的指针,然后加入的对象之间next、pre保存的是客户对象指针。通过tail可以获得客户对象链表,只需要由ELMT_FROM_HH((*tail).tbl, tail)可以得到最后一个客户对象,然后通过pre指针就可以进行遍历了。另外客户变量m_pElements也保存了所有对象构成的链表,它与tail不同之处在于,tail指向链表最后一个元素,并且是客户对象的hh成员,而m_pElements指向表头,并且直接指向客户对象,而不是hh成员,它由客户保存。
(head)->hh.tbl->num_items++; 表示hash表元素加一
(add)->hh.tbl = (head)->hh.tbl;设置客户对象hh成员保存hash表的指针。
HASH_FCN(keyptr,keylen_in, (head)->hh.tbl->num_buckets,(add)->hh.hashv, _ha_bkt);上面介绍过,它计算元素对象的key的hash值,以及链表槽位置。
HASH_ADD_TO_BKT((head)->hh.tbl->buckets[_ha_bkt],&(add)->hh); 代码如下:
#define HASH_ADD_TO_BKT(head,addhh) \
do { \
head.count++; \
(addhh)->hh_next = head.hh_head; \
(addhh)->hh_prev = NULL; \
if (head.hh_head) { (head).hh_head->hh_prev = (addhh); } \
(head).hh_head=addhh; \
if (head.count >= ((head.expand_mult+1) * HASH_BKT_CAPACITY_THRESH) \
&& (addhh)->tbl->noexpand != 1) { \
HASH_EXPAND_BUCKETS((addhh)->tbl); \
} \
} while(0)上面head是(head)->hh.tbl->buckets[_ha_bkt],表示链表槽。addhh是客户对象的hh成员。
head.count++; 表示链表槽元素计数增一
(addhh)->hh_prev = NULL; 前驱为NULL
if (head.hh_head) { (head).hh_head->hh_prev = (addhh); } 与 (head).hh_head=addhh; 让addhh成为表头元素
后面的if (head.count >= ((head.expand_mult+1) * HASH_BKT_CAPACITY_THRESH) 是扩展hash表大小,这次暂不分析。
HASH_BLOOM_ADD((head)->hh.tbl,(add)->hh.hashv); 空宏
HASH_EMIT_KEY(hh,head,keyptr,keylen_in);也是空宏
HASH_FSCK(hh,head); 也是空宏
为什么多好多进入的宏定义是空宏呢?因为uthash提供的功能不止简单的以上分析的内容,还有其它一些对hash表的扩展,有时间可以分析下,这里不再分析。
uthash暂且分析完毕,虽然分析的外部接口就一个查找,一个添加。但是其它接口都是类似分析方法,可以根据上面的内容继续分析其它接口。