自己动手写编译器之TINY编译器词法分析
TINY是《编译原理与实践》一书中介绍的教学编程语言,该语言缺少真正程序设计语言的主要特征,但足以例证编译器的主要特征了。本文将介绍该编译器的实现过程,完整的实现代码loucomp_linux中,供编译原理初学者参考。
小试牛刀:
下载源码后,进入loucomp_linux, 在命令行输入
$make
便生成tiny程序,然后输入
$tiny sample.tny
tiny 将sample.tny中的TINY源码生成tm指令。tm指令是TM虚拟机的汇编代码,TM虚拟机的源码在tm.c中,输入如下指令进行编译:
$gcc tm.c -o tm
有了tm,便可执行上面生成的sample.tm指令:
$tm sample.tm
该命令装入对了tm汇编,接着就可以交互的运行TM模拟程序了。
sample.tny是用TINY编写的求阶乘代码,按以下命令就可得到7的阶乘了
$tm sample.tm
TM simulation (enter h for help)...
Enter command: go
Enter value for IN instruction: 7
OUT instruction prints: 5040
HALT: 0,0,0
Halted
Enter command: quit
Simulation done.
接下来几篇文件讲一步步介绍该编译器和虚拟机的实现。
TINY语言的特证
1、TINY语言无过程,无声明,所有的变量都是整形。
2、它只有两个控制语句:if语句和repeat语句。if语句有一个可选的else部分且必须由关键字end结束。
3、read和write完成输入和输出
4、"{"和"}"中的语句为注释,但注释不能嵌套
程序清单1是该语言的一个求阶乘的编程示例。
程序清单1
{ Sample program
in TINY language -
computes factorial
}
read x; { input an integer }
if 0 < x then { don't compute if x <= 0 }
fact := 1;
repeat
fact := fact * x;
x := x - 1
until x = 0;
write fact { output factorial of x }
end本文的开发环境为Ubuntu, 使用lex进行词法分析,yacc进行语法分析,gcc来作为编译器。
词法分析
1、关键字: if, then, else, end, repeat, until, read, write.
所有的关键字都是保留字,且全部小写。
2、专用符号: + - * / = < ( ) ; :=
这里只用了<, 没有使用>,:=为赋值符号
3、其它标记是ID和NUM, 通过下列正则表达式定义:
ID = letter+
NUM = digit+
letter = [a-zA-Z]
digit = [0-9]
大写和小写是有区别的
4、空格是由空白、制表符和新行组成。它通常被忽略,除了它必须分开ID、NUM关键字
5、注释用{...}围起来,且不能嵌套。
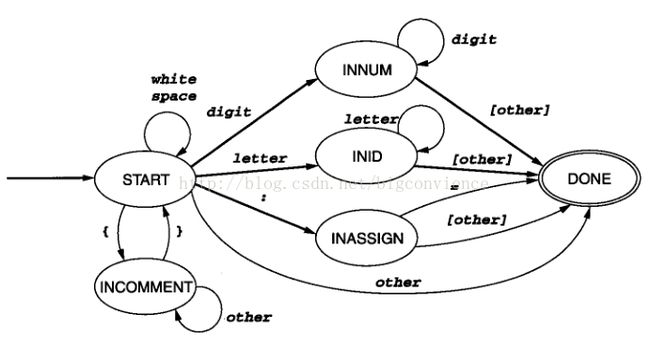
DFA
TINY扫描程序的DFA如下图所示:
词法扫描程序的实现:
1、定义记号,globals.h:
typedef enum
/* book-keeping tokens */
{ENDFILE,ERROR,
/* reserved words */
IF,THEN,ELSE,END,REPEAT,UNTIL,READ,WRITE,
/* multicharacter tokens */
ID,NUM,
/* special symbols */
ASSIGN,EQ,LT,PLUS,MINUS,TIMES,OVER,LPAREN,RPAREN,SEMI
} TokenType;
%{
#include "globals.h"
#include "util.h"
#include "scan.h"
/* lexeme of identifier or reserved word */
char tokenString[MAXTOKENLEN+1];
%}
%option noyywrap
digit [0-9]
number {digit}+
letter [a-zA-Z]
identifier {letter}+
newline \n
whitespace [ \t]+
%%
"if" {return IF;}
"then" {return THEN;}
"else" {return ELSE;}
"end" {return END;}
"repeat" {return REPEAT;}
"until" {return UNTIL;}
"read" {return READ;}
"write" {return WRITE;}
":=" {return ASSIGN;}
"=" {return EQ;}
"<" {return LT;}
"+" {return PLUS;}
"-" {return MINUS;}
"*" {return TIMES;}
"/" {return OVER;}
"(" {return LPAREN;}
")" {return RPAREN;}
";" {return SEMI;}
{number} {return NUM;}
{identifier} {return ID;}
{newline} {lineno++;}
{whitespace} {/* skip whitespace */}
"{" { char c;
do
{ c = input();
if (c == EOF) break;
if (c == '\n') lineno++;
} while (c != '}');
}
. {return ERROR;}
%%
TokenType getToken(void)
{ static int firstTime = TRUE;
TokenType currentToken;
if (firstTime)
{ firstTime = FALSE;
lineno++;
yyin = source;
yyout = listing;
}
currentToken = yylex();
strncpy(tokenString,yytext,MAXTOKENLEN);
if (TraceScan) {
fprintf(listing,"\t%d: ",lineno);
printToken(currentToken,tokenString);
}
return currentToken;
}编译运行词法分析程序
词法扫描部分包含以下C文件, 左边为头文件,右边为代码文件
globals.h main.c
util.h util.c
scan.h tiny.l
sample.tny为tiny语言编写的求阶乘函数,本文及后续文章都以该文件作为测试文件。
globas.h头文件包含了数据类型的定义和编译器使用的全局变量。main.c为编译器的主程序,分配和初始化全程变量。
输入命令:
$make
$./tiny.out sample.tny
输出:
TINY COMPILATION: sample.tny
5: reserved word: read
5: ID, name= x
5: ;
6: reserved word: if
6: NUM, val= 0
6: <
6: ID, name= x
6: reserved word: then
7: ID, name= fact
7: :=
7: NUM, val= 1
7: ;
8: reserved word: repeat
9: ID, name= fact
9: :=
9: ID, name= fact
9: *
9: ID, name= x
9: ;
10: ID, name= x
10: :=
10: ID, name= x
10: -
10: NUM, val= 1
11: reserved word: until
11: ID, name= x
11: =
11: NUM, val= 0
11: ;
12: reserved word: write
12: ID, name= fact
13: reserved word: end
14: EOF有了词法分析程序,下一篇文章将介绍TINY的语法分析。