Java HashMap底层实现和原理分析(三)
文章目录
- Java HashMap Infinite Loop
- 单线程下HashMap resize的过程
- 多线程下HashMap resize的过程
- 参考
Java HashMap Infinite Loop
首先我先说明HashMap是非线程安全的,应该用ConcurrentHashMap。
但在JDK1.7的时候,HahsMap在多线程使用的时候会产生Infinite Loop,之后在JDK1.8中进行了enhancement,但是不要认为这是线程安全了,它依旧存在线程安全问题。如果你想要线程安全,请使用ConcurrentHashMap。
我们这一篇章就来探讨一下再JDK1.7中在多线程中HashMap是怎么产生死循环的。
上一篇章中我们已经分析了JDK1.7中HashMap的源码。那么这个产生死循环的地方在哪里呢?
产生死循环的代码就是在resize方法中调用的transfer方法中
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
*/
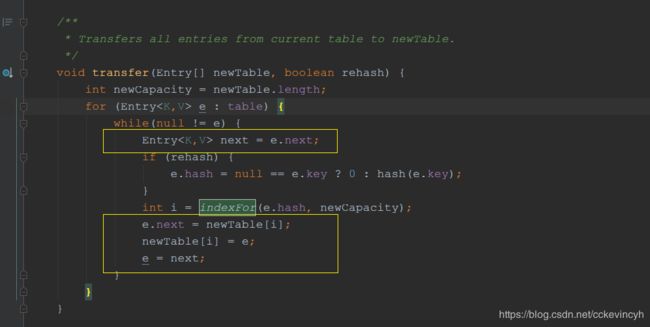
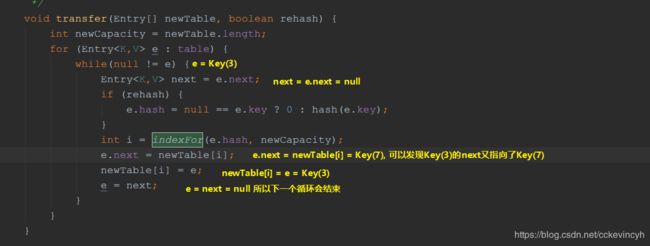
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
单线程下HashMap resize的过程
接下来我们来通过流程图来模拟单线程中HahsMap resize的过程。
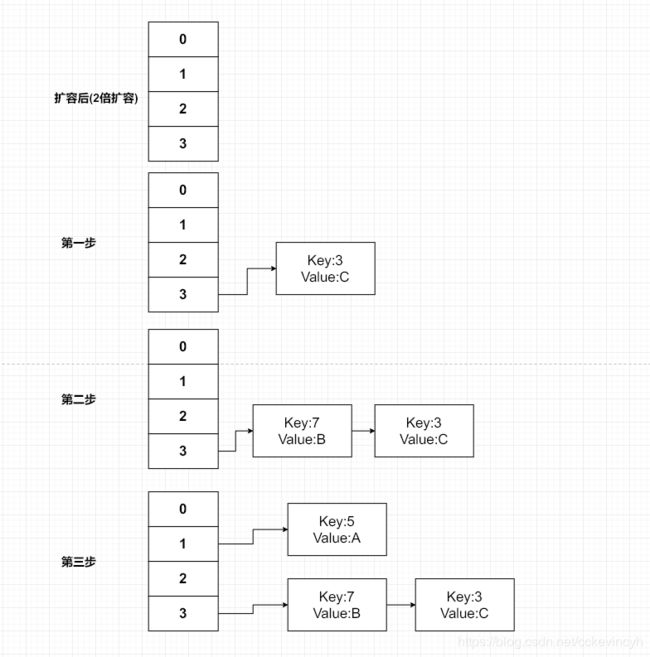
假设在单线程环境下,我们初始化的时候,给定的table(数组)容量是2,分别添加3个元素,内容如下:
- key=5,value=A;
- key=7,value=B;
- key=3,value=C;
然后假设简单通过key的hash值 % length得到一个数组的下标,我们假设key的值和key的hash值一样,那么我们就可以算出他们的下标
- key=5,value=A; – 下标 5 % 2 = 1
- key=7,value=B; – 下标 7 % 2 = 1
- key=3,value=C; – 下标 3 % 2 = 1
然后我们就可以画出扩容前table的存储情况,因为是头插法,所以最终结果如下:

接下来是将HashMap 进行两倍容量的resize,也就是得到容量为4的HashMap,这个时候需要进行重新的hash计算,计算新的数组下标
- key=5,value=A; – 下标 5 % 4 = 1
- key=7,value=B; – 下标 7 % 4 = 3
- key=3,value=C; – 下标 3 % 4 = 3
然后接下来开始把旧的table的元素transfer到新的table中。
在单线程环境下,一切看起来都很正常,扩容过程也相当顺利。接下来我们看下并发情况下的扩容。
多线程下HashMap resize的过程
假设我们有两个线程
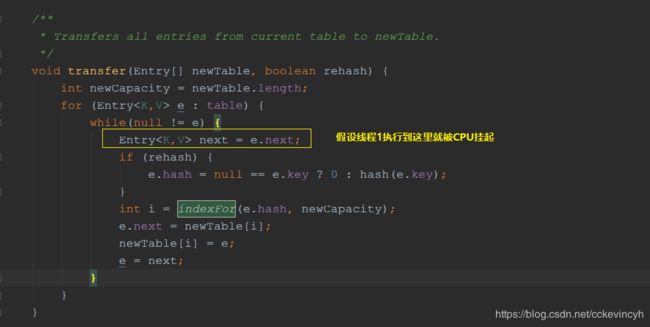
假设我们的线程1执行到上面黄色框中的代码就被CPU挂起,而我们的线程2执行完成了。
因为新创建出来的table并不是线程共享的(因为是方法的局部变量去声明创建的),而旧的table对象是线程共享的(因为是两个线程往同一个HashMap对象去put值,而且是在成员变量中所以是共享的),所以会有下面这个样子。
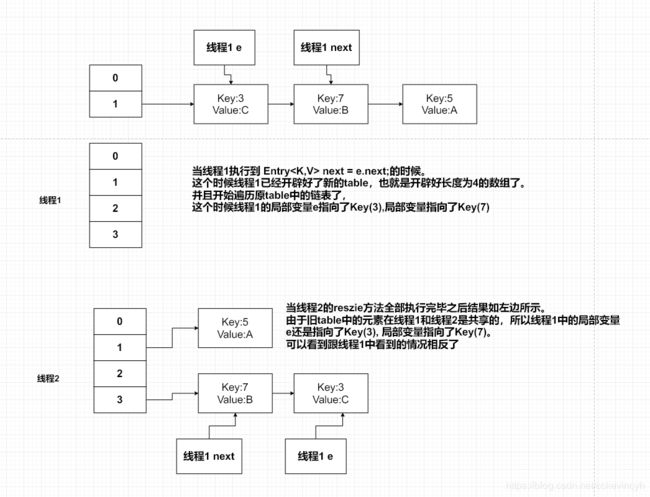
所以我们目前Key(7)的next是Key(3),而在线程1中当前的局部变量e是指向Key(3),而局部变量next是指向Key(7)。
然后现在线程1继续执行。。
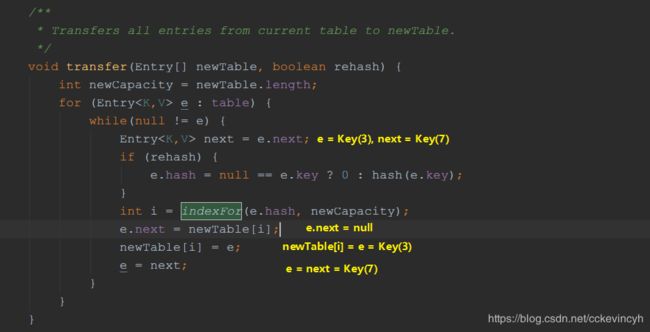
然后我们可以画出线程1当前的图。
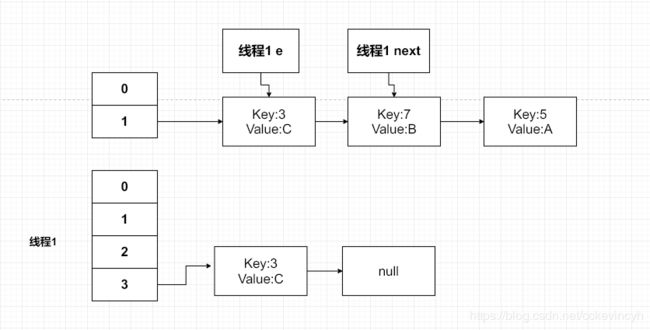
然后接下来下一个循环,这个时候线程1的局部变量e已经指向Key(7)了,我们继续带入。。
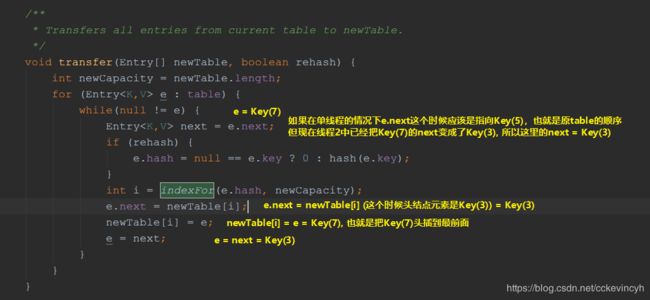
这个时候的HashMap的图如下:
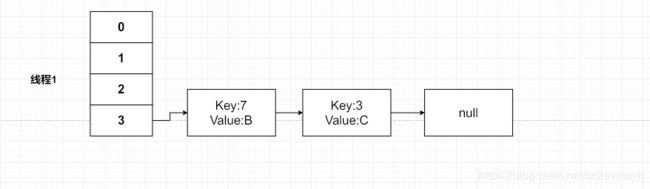
然后我们继续带入下一个循环,这个时候e=Key(3)
所以这个时候就产生了环链了。。
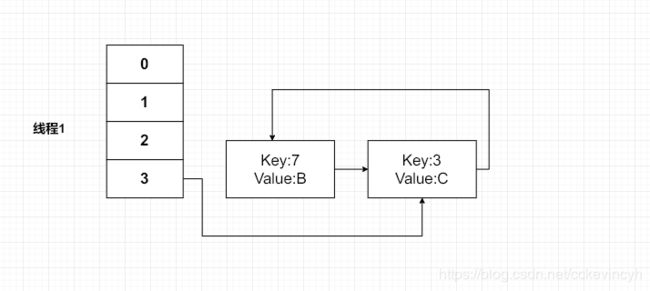
当我们的线程1调用到HashTable.get(11)时,悲剧就出现了——Infinite Loop。
参考
你是否听说过 HashMap 在多线程环境下操作可能会导致程序死循环?
疫苗:JAVA HASHMAP的死循环