YOLO9000: Better, Faster, Stronger
YOLO9000: Better, Faster, Stronger
Joseph Redmon, Ali Farhadi
University of Washington
Allen Institute for AI
https://pjreddie.com/darknet/yolov1/
https://pjreddie.com/darknet/yolov2/
https://pjreddie.com/darknet/yolo/
https://github.com/AlexeyAB/darknet
University of Washington,UW, Washington or U-Dub:华盛顿大学
Facebook Artificial Intelligence Research,Facebook AI Research,FAIR
Allen Institute for Artificial Intelligence,Allen Institute for AI,AI2
Computer Science,CS:计算机科学
Computer Vision,CV:计算机视觉
interpretation [ɪnˌtɜːprəˈteɪʃn]:n. 解释,翻译,演出
intuition [ˌɪntjuˈɪʃn]:n. 直觉,直觉力,直觉的知识
moderation [ˌmɒdəˈreɪʃn]:n. 适度,节制,温和,缓和
arXiv (archive - the X represents the Greek letter chi [χ]) is a repository of electronic preprints approved for posting after moderation, but not full peer review.
Abstract
We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel and drawn from prior work. The improved model, YOLOv2, is state-of-the-art on standard detection tasks like PASCAL VOC and COCO. Using a novel, multi-scale training method the same YOLOv2 model can run at varying sizes, offering an easy tradeoff between speed and accuracy. At 67 FPS, YOLOv2 gets 76.8 mAP on VOC 2007. At 40 FPS, YOLOv2 gets 78.6 mAP, outperforming state-of-the-art methods like Faster RCNN with ResNet and SSD while still running significantly faster. Finally we propose a method to jointly train on object detection and classification. Using this method we train YOLO9000 simultaneously on the COCO detection dataset and the ImageNet classification dataset. Our joint training allows YOLO9000 to predict detections for object classes that don’t have labelled detection data. We validate our approach on the ImageNet detection task. YOLO9000 gets 19.7 mAP on the ImageNet detection validation set despite only having detection data for 44 of the 200 classes. On the 156 classes not in COCO, YOLO9000 gets 16.0 mAP. But YOLO can detect more than just 200 classes; it predicts detections for more than 9000 different object categories. And it still runs in real-time.
我们引入了 YOLO9000,这是一种先进的实时目标检测系统,可以检测 9000 多个目标类别。首先,我们提出对 YOLO 检测方法的各种改进,无论是新颖的还是从以前的工作中得出的。改进的模型 YOLOv2 在诸如 PASCAL VOC 和 COCO 之类的标准检测任务方面是最高水平的。使用新颖的,多尺度的训练方法,相同的 YOLOv2 模型可以在不同的尺寸上运行,从而在速度和准确性之间轻松权衡。以 67 FPS 速度运行时,YOLOv2 在 VOC 2007 上获得 76.8 mAP。以 40 FPS 速度运行时,YOLOv2 获得 78.6 mAP,优于采用 ResNet 的 Faster RCNN 和 SSD 的最新方法,但运行速度仍显著提高。最后,我们提出了一种联合训练目标检测和分类的方法。使用这种方法,我们在 COCO 检测数据集和 ImageNet 分类数据集上同时训练 YOLO9000。通过我们的联合培训,YOLO9000 可以预测没有标记检测数据的物体类别的检测结果。我们在 ImageNet 检测任务上验证我们的方法。尽管仅拥有 200 个类别中的 44 个类别的检测数据,但 YOLO9000 在 ImageNet 检测验证集上获得了 19.7 mAP。在 COCO 以外的 156 个类别中,YOLO9000 获得了 16.0 mAP。但是 YOLO 可以检测到 200 多个类别。它可以预测 9000 多种不同物体类别的检测结果。而且它仍然实时运行。
bounding box:边界框,限位框,检测框
state-of-the-art (cutting edge or leading edge),SOTA:adj. 使用最先进技术的,体现最高水平的
draw [drɔː]:vt. 画,拉,吸引 vi. 拉,拖 n. 平局,抽签
outperform [ˌaʊtpəˈfɔːm]:vt. 胜过,做得比...好
1. Introduction
General purpose object detection should be fast, accurate, and able to recognize a wide variety of objects. Since the introduction of neural networks, detection frameworks have become increasingly fast and accurate. However, most detection methods are still constrained to a small set of objects.
通用目标检测应该快速、准确并且能够识别各种目标。自从引入神经网络以来,检测框架已经变得越来越快和准确。但是,大多数检测方法仍然局限于一小部分目标。
Current object detection datasets are limited compared to datasets for other tasks like classification and tagging. The most common detection datasets contain thousands to hundreds of thousands of images with dozens to hundreds of tags [3] [10] [2]. Classification datasets have millions of images with tens or hundreds of thousands of categories [20] [2].
与其他任务 (classification and tagging) 的数据集相比,当前的目标检测数据集受到限制。最常见的检测数据集包含成千上万的图像以及数十到数百个标签 [3] [10] [2]。分类数据集包含数以百万计的图像,这些图像具有数以万计的类别 [20] [2]。
tag [tæɡ]:n. 标签,名称,结束语,附属物 vt. 尾随,紧随,连接,起浑名,添饰 vi. 紧随
dozen [ˈdʌzn]:n. 十二个,一打 adj. 一打的
We would like detection to scale to level of object classification. However, labelling images for detection is far more expensive than labelling for classification or tagging (tags are often user-supplied for free). Thus we are unlikely to see detection datasets on the same scale as classification datasets in the near future.
我们希望将检测扩展到目标分类的级别。但是,标记要检测的图像要比标记 classification or tagging 要昂贵得多 (标签通常是用户免费提供的)。因此,我们不太可能在不久的将来看到与分类数据集规模相同的检测数据集。
We propose a new method to harness the large amount of classification data we already have and use it to expand the scope of current detection systems. Our method uses a hierarchical view of object classification that allows us to combine distinct datasets together.
我们提出了一种新方法,以利用我们已经拥有的大量分类数据,并使用它来扩展当前检测系统的范围。我们的方法使用目标分类的分层视图,该视图允许我们将不同的数据集组合在一起。
harness [ˈhɑːnɪs]:n. 马具,背带,吊带,甲胄,挽具状带子,降落伞背带,日常工作 v. 治理,利用,套,驾驭,披上甲胄,将 (两只动物) 拴在一起
hierarchical [ˌhaɪəˈrɑːkɪ.kəl]:adj. 分层的,等级体系的
We also propose a joint training algorithm that allows us to train object detectors on both detection and classification data. Our method leverages labeled detection images to learn to precisely localize objects while it uses classification images to increase its vocabulary and robustness.
我们还提出了一种联合训练算法,该算法允许我们在检测和分类数据上训练目标检测器。我们的方法利用标记的检测图像来学习精确定位目标,同时使用分类图像来增加其词汇量和健壮性。
Using this method we train YOLO9000, a real-time object detector that can detect over 9000 different object categories. First we improve upon the base YOLO detection system to produce YOLOv2, a state-of-the-art, real-time detector. Then we use our dataset combination method and joint training algorithm to train a model on more than 9000 classes from ImageNet as well as detection data from COCO.
使用这种方法,我们训练了 YOLO9000,这是一种实时目标检测器,可以检测 9000 多种不同的目标类别。首先,我们对基本的 YOLO 检测系统进行改进,以生产出最先进的实时检测器 YOLOv2。然后,我们使用数据集组合方法和联合训练算法对 ImageNet 上的 9000 多个类别以及 COCO 的检测数据进行训练。
All of our code and pre-trained models are available online at https://pjreddie.com/darknet/yolo/.
leverage [ˈliːvərɪdʒ]:n. 手段,影响力,杠杆作用,杠杆效率 v. 利用,举债经营
vocabulary [vəˈkæbjələri]:n. 词汇,词表,词汇量
robustness [rəʊ'bʌstnɪs]:n. 鲁棒性,稳健性,健壮性
region proposal:候选区域

Figure 1: YOLO9000. YOLO9000 can detect a wide variety of object classes in real-time.
Figure 1: YOLO9000. YOLO9000 可以实时检测各种各样的目标类别。
2. Better
YOLO suffers from a variety of shortcomings relative to state-of-the-art detection systems. Error analysis of YOLO compared to Fast R-CNN shows that YOLO makes a significant number of localization errors. Furthermore, YOLO has relatively low recall compared to region proposal-based methods. Thus we focus mainly on improving recall and localization while maintaining classification accuracy.
与最先进的检测系统相比,YOLO 存在许多缺点。与 Fast R-CNN 相比,YOLO 的错误分析表明,YOLO 会产生大量的定位错误。此外,与基于候选区域的方法相比,YOLO 的召回率相对较低。因此,我们主要致力于改善召回率和定位,同时保持分类准确性。
Recall = T P T P + F N {\text{Recall}} = {\frac {TP}{TP + FN}} Recall=TP+FNTP,样本中的正例有多少被正确的预测,即真正例中被预测正确的样本所占的比例。Recall 较小表明很多本该预测出来的样本没有被预测出来。
Precision = T P T P + F P {\text{Precision}}={\frac {TP}{TP + FP}} Precision=TP+FPTP,预测结果中的正例中有多少 ground truth 就是正例,即真正例占所预测正例的比例。
true positive,TP:eqv. with hit
true negative,TN:eqv. with correct rejection
false positive,FP:eqv. with false alarm, Type I error
false negative,FN:eqv. with miss, Type II error
Computer vision generally trends towards larger, deeper networks [6] [18] [17]. Better performance often hinges on training larger networks or ensembling multiple models together. However, with YOLOv2 we want a more accurate detector that is still fast. Instead of scaling up our network, we simplify the network and then make the representation easier to learn. We pool a variety of ideas from past work with our own novel concepts to improve YOLO’s performance. A summary of results can be found in Table 2.
计算机视觉通常趋向于更大、更深的网络 [6] [18] [17]。更好的性能通常取决于训练大型网络或将多个模型整合在一起。但是,对于 YOLOv2,我们希望使用一种仍能快速运行的更准确的检测器。我们不是扩大我们的网络,而是简化网络,然后让表征更易于学习。我们将过去的工作中的各种想法与我们自己的新颖概念融合在一起,以提高 YOLO 的性能。结果总结可在表 2 中找到。
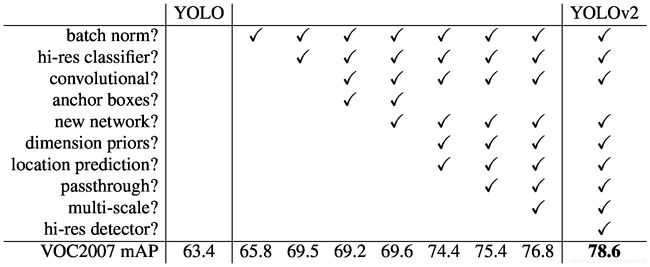
Table 2: The path from YOLO to YOLOv2. Most of the listed design decisions lead to significant increases in mAP. Two exceptions are switching to a fully convolutional network with anchor boxes and using the new network. Switching to the anchor box style approach increased recall without changing mAP while using the new network cut computation by 33%.
Table 2: The path from YOLO to YOLOv2. 列出的大多数设计决策都会导致 mAP 显著增加。两个例外是切换到带有 anchor boxes 的全卷积网络并使用新网络。切换到 anchor box 样式方法可以在不更改 mAP 的情况下增加召回率,同时使用新的网络计算可以减少 33%。
hinge [hɪndʒ]:n. 铰链,折叶,关键,转折点,枢要,中枢 v. 用铰链连接,依...为转移,给...安装铰链,(门等) 装有蝶铰
ensemble [ɒnˈsɒmbl]:n. 全体,总效果,全套服装,全套家具,合奏组 adv. 同时
Batch Normalization. Batch normalization leads to significant improvements in convergence while eliminating the need for other forms of regularization [7]. By adding batch normalization on all of the convolutional layers in YOLO we get more than 2% improvement in mAP. Batch normalization also helps regularize the model. With batch normalization we can remove dropout from the model without overfitting.
Batch Normalization. batch normalization 导致收敛性的显著改善,同时消除了对其他形式的正则化的需求 [7]。 通过在 YOLO 的所有卷积层上添加 batch normalization,我们可以在 mAP 方面获得超过 2% 的改善。batch normalization 还有助于正则化模型。通过 batch normalization,我们可以消除模型中的 dropout 而不会过拟合。
神经网络学习本质是为了学习数据分布,一旦训练数据与测试数据的分布不同,网络的泛化能力将大大降低。每批 (batch) 训练数据的分布各不相同,网络就要在每次迭代去学习适应不同的分布,这样将会大大降低网络的训练速度,这正是要对数据做归一化预处理的原因。对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布。如果训练过程中,训练数据的分布一直在发生变化,将会影响网络的训练速度。
With batch normalization we can remove dropout from the model without overfitting.
regularization [,rɛɡjʊlərɪ'zeʃən]:n. 规则化,调整,合法化
convergence [kənˈvɜːdʒəns]:n. 收敛,会聚,集合
regularize [ˈreɡjələraɪz]:vt. 调整,使有秩序,使合法化
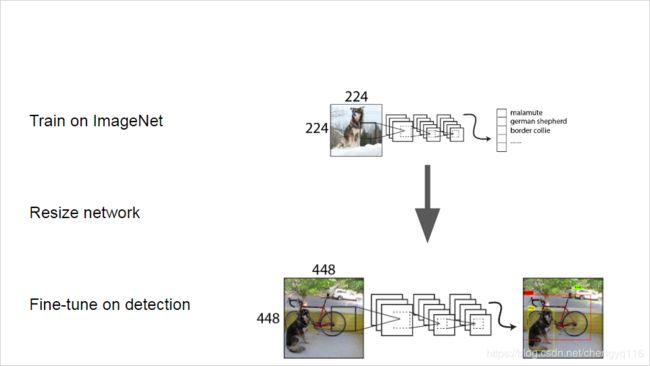
High Resolution Classifier. All state-of-the-art detection methods use classifier pre-trained on ImageNet [16]. Starting with AlexNet most classifiers operate on input images smaller than 256 × \times × 256 [8]. The original YOLO trains the classifier network at 224 × \times × 224 and increases the resolution to 448 for detection. This means the network has to simultaneously switch to learning object detection and adjust to the new input resolution.
High Resolution Classifier. 所有最新的检测方法都使用在 ImageNet [16] 上预先训练的分类器。从 AlexNet 开始,大多数分类器对小于 256 × \times × 256 的输入图像进行操作 [8]。原始的 YOLO 以 224 × \times × 224 训练分类器网络,并将分辨率提高到 448 以进行检测。这意味着网络必须同时切换到学习目标检测并调整为新的输入分辨率。
simultaneously [ˌsɪmlˈteɪniəsli]:adv. 同时地
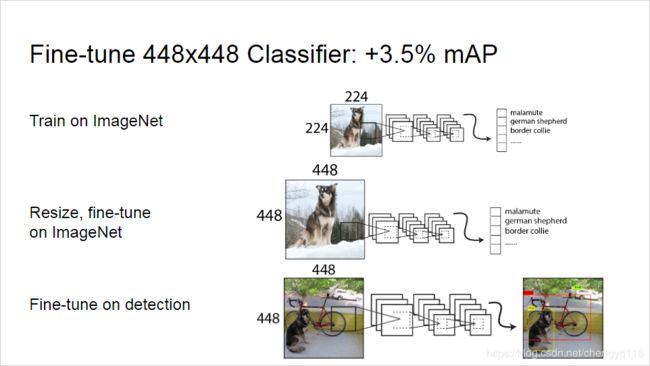
For YOLOv2 we first fine tune the classification network at the full 448 × \times × 448 resolution for 10 epochs on ImageNet. This gives the network time to adjust its filters to work better on higher resolution input. We then fine tune the resulting network on detection. This high resolution classification network gives us an increase of almost 4% mAP.
对于 YOLOv2,我们首先在 ImageNet 上以 448 × \times × 448 的完整分辨率 fine tune 分类网络,持续 10 个 epoch。 这使网络有时间调整其 filter,使其在更高分辨率的输入上更好地工作。然后,我们在检测上 fine tune 得到的网络。这种高分辨率分类网络使我们的 mAP 几乎提高了 4%。
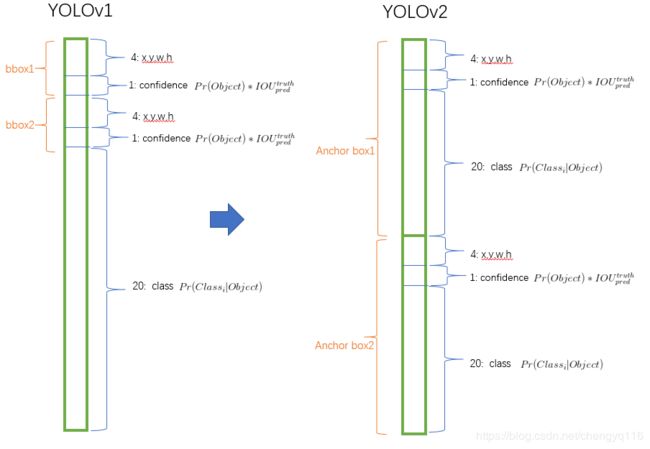
Convolutional With Anchor Boxes. YOLO predicts the coordinates of bounding boxes directly using fully connected layers on top of the convolutional feature extractor. Instead of predicting coordinates directly Faster R-CNN predicts bounding boxes using hand-picked priors [15]. Using only convolutional layers the region proposal network (RPN) in Faster R-CNN predicts offsets and confidences for anchor boxes. Since the prediction layer is convolutional, the RPN predicts these offsets at every location in a feature map. Predicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn.
Convolutional With Anchor Boxes. YOLO 使用卷积特征提取器顶部的全连接层直接预测边界框的坐标。代替直接预测坐标,Faster R-CNN 使用手工挑选的先验来预测边界框 [15]。仅使用卷积层,Faster R-CNN 中的 region proposal network (RPN) 即可预测锚框的偏移量和置信度。由于预测层是卷积的,因此 RPN 会在特征图中的每个位置预测这些偏移。预测偏移量而不是坐标可以简化问题,并使网络更容易学习。
We remove the fully connected layers from YOLO and use anchor boxes to predict bounding boxes. First we eliminate one pooling layer to make the output of the network’s convolutional layers higher resolution. We also shrink the network to operate on 416 input images instead of 448 × \times × 448. We do this because we want an odd number of locations in our feature map so there is a single center cell. Objects, especially large objects, tend to occupy the center of the image so it’s good to have a single location right at the center to predict these objects instead of four locations that are all nearby. YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × \times × 13.
我们从 YOLO 中移除全连接层,并使用 anchor boxes 来预测边界框。首先,我们消除了一个池化层,以使网络卷积层的输出具有更高的分辨率。我们还缩小了网络以处理 416 × \times × 416 输入图像,而不是 448 × \times × 448。之所以这样做,是因为我们希望特征图中的位置数为奇数,因此只有一个中心单元。目标 (尤其是大目标) 往往占据图像的中心,因此最好在中心位置使用一个位置来预测这些目标,而不要使用附近的四个位置。YOLO 的卷积层将图像降采样 32 倍,因此使用 416 × \times × 416 的输入图像,我们得到的输出特征图为 13 × \times × 13。
416 / ( 2 5 ) = 416 / 32 = 13 416 / (2^5) = 416 / 32 = 13 416/(25)=416/32=13
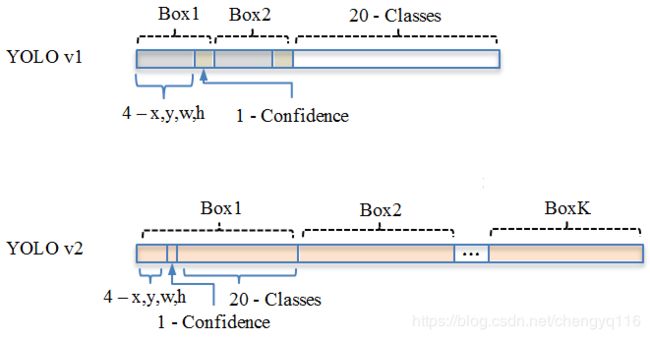
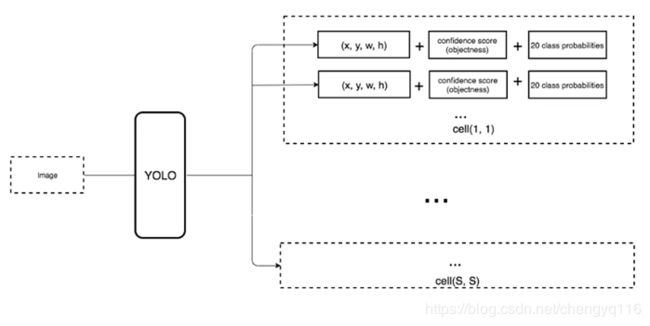
YOLO(v1) 每个 grid cell 预测 2 个 bbox,每个 grid cell 预测 1 个类别。YOLO(v1) 使用全连接层数据进行 bounding box 预测 (要把 1470 × \times × 1 的全链接层 reshape 为 7 × \times × 7 × \times × 30 的最终特征),这会丢失较多的空间信息定位不准。YOLOv1 是一种端到端的目标检测算法。
YOLOv2 class prediction mechanism 与空间位置解耦,每个 anchor box 预测 class and objectness。移除全连接层,以获取更多空间信息。
YOLO(v1) 7 × \times × 7 grid cell.
YOLOv2 13 × \times × 13 grid cell.
YOLOv2 借鉴了 Faster R-CNN 中的 anchor 思想,在卷积特征图上执行滑窗采样,每个中心预测多种不同大小和比例的建议框。由于都是卷积不需要 reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个 cell 一一对应。预测相对偏移 (offset) 取代直接预测坐标简化了问题,方便网络学习。anchor 是 RPN (region proposal network) 网络在 Faster R-CNN 中的一个关键步骤,是在卷积特征图上进行滑窗操作,每一个中心可以预测 9 种不同大小的候选框。Faster R-CNN 中使用 3 种 scales 和 3 种 aspect ratios 在每个位置产生了 9 个anchor boxes。

shrink [ʃrɪŋk]:v. (使) 缩小,(使) 收缩,(尤指因恐惧而) 退缩,畏缩,回避,(衣服、布料) 缩水 n. 收缩,畏缩,(非正式) 精神病医生,精神病学家,心理学家
decouple [diːˈkʌpl]:vt. 减弱震波,使分离 n. 去耦
When we move to anchor boxes we also decouple the class prediction mechanism from the spatial location and instead predict class and objectness for every anchor box. Following YOLO, the objectness prediction still predicts the IOU of the ground truth and the proposed box and the class predictions predict the conditional probability of that class given that there is an object.
当我们移至 anchor boxes 时,我们还将 class prediction mechanism 与空间位置分离,而是为每个 anchor box 预测 class and objectness。在 YOLO 之后,objectness prediction 仍会预测 the IOU of the ground truth and the proposed box,并且 class prediction 会在存在目标的情况下预测该类别的条件概率。
Using anchor boxes we get a small decrease in accuracy. YOLO only predicts 98 boxes per image but with anchor boxes our model predicts more than a thousand. Without anchor boxes our intermediate model gets 69.5 mAP with a recall of 81%. With anchor boxes our model gets 69.2 mAP with a recall of 88%. Even though the mAP decreases, the increase in recall means that our model has more room to improve.
使用 anchor boxes,准确性会略有下降。YOLO 只预测 98 boxes per image,但使用 anchor boxes 我们的模型预测超过 1000 个以上。如果没有 anchor boxes,我们的中间模型将获得 69.5 mAP,召回率为 81%。使用 anchor boxes,我们的模型获得 69.2 mAP,召回率达到 88%。即使 mAP 降低,召回率的增加也意味着我们的模型还有更多的改进空间。
pick [pɪk]:vi. 挑选,采摘,挖 vt. 拾取,精选,采摘,掘 n. 选择,鹤嘴锄,挖,掩护
intermediate [ˌɪntəˈmiːdiət];adj. 中间的,过渡的,中级的,中等的 n. 中级生,(化合物) 中间体,中间物,中介,媒介 v. 充当调解人,起媒介作用
Dimension Clusters. We encounter two issues with anchor boxes when using them with YOLO. The first is that the box dimensions are hand picked. The network can learn to adjust the boxes appropriately but if we pick better priors for the network to start with we can make it easier for the network to learn to predict good detections.
Dimension Clusters. 在 YOLO 上使用 anchor boxes 时,我们会遇到两个问题。首先是 anchor boxes 尺寸是手工挑选的。网络可以学习适当地调整框,但是如果我们为网络选择更好的先验条件,则可以使网络更容易学习预测良好的检测。
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors. If we use standard k-means with Euclidean distance larger boxes generate more error than smaller boxes. However, what we really want are priors that lead to good IOU scores, which is independent of the size of the box. Thus for our distance metric we use:
无需手动选择先验,我们在训练集边界框上运行 k-means 聚类,以自动找到良好的先验。如果我们使用 standard k-means with Euclidean distance,则较大的 boxes 会比较小的 boxes 产生更多的误差。但是,我们真正想要的是能够获得良好 IOU 分数的先验值,而这与 box 的大小无关。因此,对于我们的距离度量,我们使用:
d = ( box , centroid ) = 1 − I O U ( box , centroid ) d = (\text{box}, \text{centroid}) = 1 - IOU(\text{box}, \text{centroid}) d=(box,centroid)=1−IOU(box,centroid)
We run k-means for various values of k k k and plot the average IOU with closest centroid, see Figure 2. We choose k k k = 5 as a good tradeoff between model complexity and high recall. The cluster centroids are significantly different than hand-picked anchor boxes. There are fewer short, wide boxes and more tall, thin boxes.
我们运行各种 k k k 值的 k-means,并绘制具有最接近质心的平均 IOU,请参见图 2。我们选择 k k k = 5 作为模型复杂度和高召回率之间的良好折衷。聚类质心与手工挑选的 anchor boxes 明显不同。短而宽的 anchor boxes 较少,而高而细的 anchor boxes 较多。
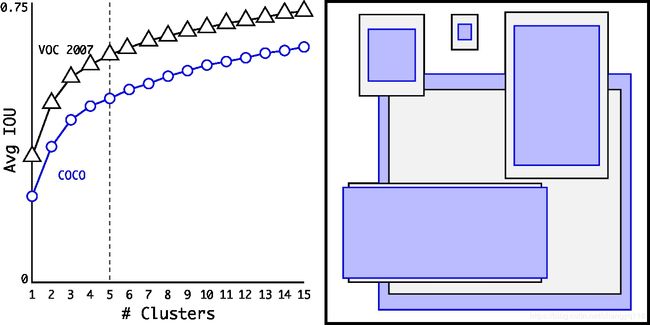
Figure 2: Clustering box dimensions on VOC and COCO. We run k-means clustering on the dimensions of bounding boxes to get good priors for our model. The left image shows the average IOU we get with various choices for k k k. We find that k k k = 5 gives a good tradeoff for recall vs. complexity of the model. The right image shows the relative centroids for VOC and COCO. Both sets of priors favor thinner, taller boxes while COCO has greater variation in size than VOC.
我们在 bounding boxes 的维度上运行 k-means clustering,以获得模型的良好先验。左图显示了我们在 k k k 的各种选择下获得的平均 IOU。我们发现 k k k = 5 在召回率与模型复杂度之间取得了很好的权衡。右图显示了 VOC 和 COCO 的相对质心。两组先验技术都倾向于使用更细、更高的 boxes,而 COCO 的尺寸差异要大于 VOC。
We compare the average IOU to closest prior of our clustering strategy and the hand-picked anchor boxes in Table 1. At only 5 priors the centroids perform similarly to 9 anchor boxes with an average IOU of 61.0 compared to 60.9. If we use 9 centroids we see a much higher average IOU. This indicates that using k-means to generate our bounding box starts the model off with a better representation and makes the task easier to learn.
我们将平均 IOU 与我们的聚类策略最接近的先验样本以及表 1 中的手工选择的 anchor boxes 进行比较。在仅 5 个先验样本时,平均 IOU 为 61.0,质心的表现与 9 个 anchor boxes (平均为 60.9) 相似。如果使用 9 个质心,则平均 IOU 会更高。这表明使用 k-means 生成边界框可以更好地表示模型,从而使任务更易于学习。
centroid ['sentrɔɪd]:n. 质心,重心,中心,图心
occlude [əˈkluːd]:v. 阻塞 (口、孔等),(使) 闭塞,遮盖 (一只眼睛) 使看不见,(固体) 吸收 (气体、杂质),(上下齿) 咬合
Cluster SSE - Euclidean distance based
Cluster IOU - IOU based
Anchor Boxes - Faster R-CNN
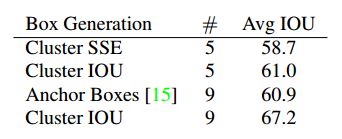
Table 1: Average IOU of boxes to closest priors on VOC 2007. The average IOU of objects on VOC 2007 to their closest, unmodified prior using different generation methods. Clustering gives much better results than using hand-picked priors.
在 VOC 2007 上目标的平均 IOU 与其最接近的、使用不同生成方法产生的未经修改的先验值。聚类结果比使用手工选择的先验结果要更好。与使用人工挑选的先验值相比,聚类值提供了更好的结果。
Direct location prediction. When using anchor boxes with YOLO we encounter a second issue: model instability, especially during early iterations. Most of the instability comes from predicting the ( x , y ) (x, y) (x,y) locations for the box. In region proposal networks the network predicts values t x t_{x} tx and t y t_{y} ty and the ( x , y ) (x, y) (x,y) center coordinates are calculated as:
Direct location prediction. 当在 YOLO 中使用 anchor boxes 时,我们会遇到第二个问题:模型不稳定,尤其是在早期迭代期间。大多数不稳定性来自于预测 box 的 ( x , y ) (x, y) (x,y) 位置。在区域提议网络中,网络预测值 t x t_{x} tx and t y t_{y} ty,并且中心位置的 ( x , y ) (x, y) (x,y) 计算如下:
x = ( t x ∗ w a ) − x a y = ( t y ∗ h a ) − y a \begin{aligned} & {x = (t_{x} * w_{a}) - x_{a}}\\ & {y = (t_{y} * h_{a}) - y_{a}} \end{aligned} x=(tx∗wa)−xay=(ty∗ha)−ya
请参考 Faster-RCNN 论文公式。
x = ( t x ∗ w a ) + x a y = ( t y ∗ h a ) + y a \begin{aligned} & {x = (t_{x} * w_{a}) + x_{a}}\\ & {y = (t_{y} * h_{a}) + y_{a}} \end{aligned} x=(tx∗wa)+xay=(ty∗ha)+ya
For example, a prediction of t x = 1 t_{x} = 1 tx=1 would shift the box to the right by the width of the anchor box, a prediction of t x = − 1 t_{x} = −1 tx=−1 would shift it to the left by the same amount.
例如,预测 t x = 1 t_{x} = 1 tx=1 将使框向右移动 anchor box 的宽度,预测 t x = − 1 t_{x} = −1 tx=−1 会将其向左移相同的位置量。
This formulation is unconstrained so any anchor box can end up at any point in the image, regardless of what location predicted the box. With random initialization the model takes a long time to stabilize to predicting sensible offsets.
此公式不受限制,因此任何 anchor box 都可以终止于图像中的任何点,而不管预测该框的位置如何。通过随机初始化,该模型需要很长时间才能稳定以预测合理的偏移量。
network predicts values t x t_{x} tx and t y t_{y} ty 可为任意大小,将导致每个 anchor box 的预测框都可以出现在图中任意位置,导致模型的不稳定,需要很长时间才能稳定以预测合理的 offsets。
stabilize ['steɪbəlaɪz]:vt. 使稳固,使安定 vi. 稳定,安定
offset [ˈɒfset]:n. 抵消,补偿,偏离量,(测绘) 支距,(电子) 偏离,侧枝,(山的) 支脉,(建筑) 壁阶,弯管,支管,平版印刷 v. 抵消,弥补,衬托出,使偏离直线方向,用平版印刷术印刷,转印下一页,装支管 adj. 胶印的
Instead of predicting offsets we follow the approach of YOLO and predict location coordinates relative to the location of the grid cell. This bounds the ground truth to fall between 0 and 1. We use a logistic activation to constrain the network’s predictions to fall in this range.
代替预测偏移量,我们遵循 YOLO 的方法,而是预测相对于网格单元位置的位置坐标。这将 ground truth 限制在 0 到 1 之间。我们使用 logistic activation 将网络的预测限制在此范围内。
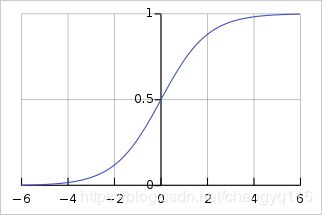
The standard logistic function is the logistic function with parameters ( k = 1 , x 0 = 0 , L = 1 k = 1, x_{0} = 0, L = 1 k=1,x0=0,L=1) which yields
f ( x ) = 1 1 + e − x = e x e x + 1 = 1 2 + 1 2 tanh ( x 2 ) \begin{aligned} f(x) = {\frac {1}{1+e^{-x}}} = {\frac {e^{x}}{e^{x}+1}} = {\tfrac {1}{2}}+{\tfrac {1}{2}}\tanh({\tfrac {x}{2}}) \end{aligned} f(x)=1+e−x1=ex+1ex=21+21tanh(2x)
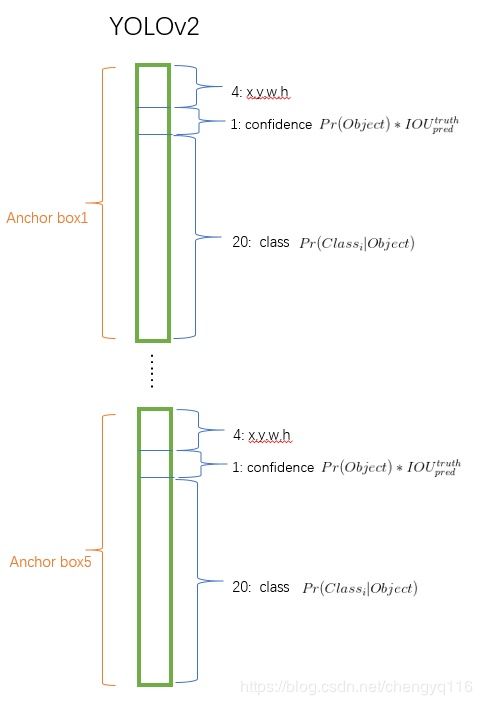
The network predicts 5 bounding boxes at each cell in the output feature map. The network predicts 5 coordinates for each bounding box, t x , t y , t w , t h t_{x}, t_{y}, t_{w}, t_{h} tx,ty,tw,th, and t o t_{o} to. If the cell is offset from the top left corner of the image by ( c x , c y ) (c_{x}, c_{y}) (cx,cy) and the bounding box prior has width and height p w , p h p_{w}, p_{h} pw,ph, then the predictions correspond to:
网络在输出 feature map 中的每个 cell 上预测 5 个边界框。网络为每个边界框预测 5 个坐标, t x , t y , t w , t h t_{x}, t_{y}, t_{w}, t_{h} tx,ty,tw,th, and t o t_{o} to。如果 cell 从图像的左上角偏移了 ( c x , c y ) (c_{x}, c_{y}) (cx,cy),并且边界框先验的宽度和高度为 p w , p h p_{w}, p_{h} pw,ph,那么预测对应:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h P r ( object ) ∗ I O U ( b , object ) = σ ( t o ) \begin{aligned} b_{x} &= \sigma(t_{x}) + c_{x}\\ b_{y} &= \sigma(t_{y}) + c_{y}\\ b_{w} &= p_{w}e^{t_{w}}\\ b_{h} &= p_{h}e^{t_{h}}\\ Pr(\text{object}) ∗ IOU(b, \text{object}) &= \sigma(t_{o}) \end{aligned} bxbybwbhPr(object)∗IOU(b,object)=σ(tx)+cx=σ(ty)+cy=pwetw=pheth=σ(to)
Since we constrain the location prediction the parametrization is easier to learn, making the network more stable. Using dimension clusters along with directly predicting the bounding box center location improves YOLO by almost 5% over the version with anchor boxes.
由于我们限制了位置预测,因此参数化更易于学习,从而使网络更加稳定。与使用 anchor boxes 的版本相比,使用尺寸聚类以及直接预测边界框中心位置可使 YOLO 提升近 5%。
( c x , c y ) (c_{x}, c_{y}) (cx,cy) 是 cell 左上角的坐标,相对于图像左上角的偏移,数值是相对于特征图大小的,每个 cell 尺度为 1。 p w , p h p_{w}, p_{h} pw,ph 是 bounding box prior (anchor box) 的宽和高,数值是相对于特征图大小的。YOLOv2 预测框中心相对于对应 cell 左上角位置的相对偏移、为了将预测边界框的中心值约束在当前 cell 中,防止偏移过多,使用 logistic activation 处理预测值 t x , t y t_{x}, t_{y} tx,ty,这样预测偏移值在 (0, 1) 范围内 (每个 cell 看作 1)。
如果特征图的大小为 ( W featuremap , H featuremap ) (W_{\text{featuremap}}, H_{\text{featuremap}}) (Wfeaturemap,Hfeaturemap),bbox 相对于整张图片的位置和大小计算如下 (4 个值均在 0 和 1 之间):
b ^ x = ( σ ( t x ) + c x ) / W featuremap b ^ y = ( σ ( t y ) + c y ) / H featuremap b ^ w = ( p w e t w ) / W featuremap b ^ h = ( p h e t h ) / H featuremap \begin{aligned} \hat{b}_{x} &= (\sigma(t_{x}) + c_{x}) / W_{\text{featuremap}}\\ \hat{b}_{y} &= (\sigma(t_{y}) + c_{y}) / H_{\text{featuremap}} \\ \hat{b}_{w} &= (p_{w}e^{t_{w}}) / W_{\text{featuremap}}\\ \hat{b}_{h} &= (p_{h}e^{t_{h}}) / H_{\text{featuremap}} \end{aligned} b^xb^yb^wb^h=(σ(tx)+cx)/Wfeaturemap=(σ(ty)+cy)/Hfeaturemap=(pwetw)/Wfeaturemap=(pheth)/Hfeaturemap
将上面的四个值分别乘以图片的长宽就可以得到 bbox 的位置和大小了。
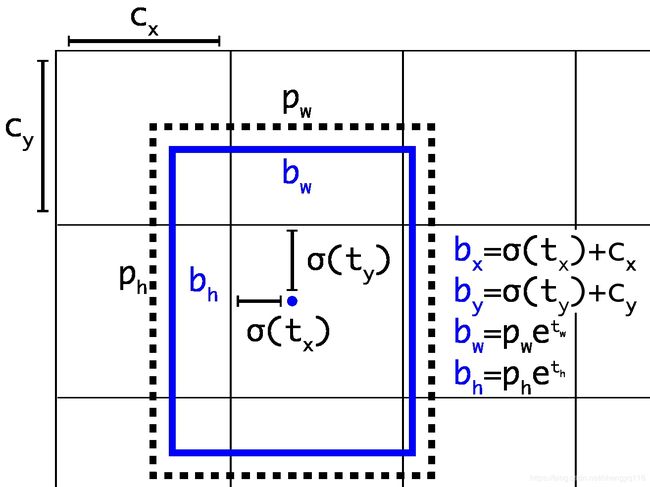
Figure 3: Bounding boxes with dimension priors and location prediction. We predict the width and height of the box as offsets from cluster centroids. We predict the center coordinates of the box relative to the location of filter application using a sigmoid function.
我们预测 box 的宽度和高度作为与聚类质心的偏移量。我们使用 sigmoid function 预测相对于 filter 应用位置的 box 中心坐标。
Fine-Grained Features. This modified YOLO predicts detections on a 13 × \times × 13 feature map. While this is sufficient for large objects, it may benefit from finer grained features for localizing smaller objects. Faster R-CNN and SSD both run their proposal networks at various feature maps in the network to get a range of resolutions. We take a different approach, simply adding a passthrough layer that brings features from an earlier layer at 26 × \times × 26 resolution.
Fine-Grained Features. 修改后的 YOLO 在 13 × \times × 13 的 feature map 上预测检测结果。虽然这对于大型目标已经足够,但它可以从用于定位较小目标的更细粒度的特征中受益。Faster R-CNN 和 SSD 都在网络的各种 feature map 上运行他们提出的网络,以获得一系列的分辨率。我们采用不同的方法,只需添加一个 passthrough layer,该层从 26 × \times × 26 分辨率的早期层中提取特征。
The passthrough layer concatenates the higher resolution features with the low resolution features by stacking adjacent features into different channels instead of spatial locations, similar to the identity mappings in ResNet. This turns the 26 × \times × 26 × \times × 512 feature map into a 13 × \times × 13 × \times × 2048 feature map, which can be concatenated with the original features. Our detector runs on top of this expanded feature map so that it has access to fine grained features. This gives a modest 1% performance increase.
passthrough layer 通过将相邻特征堆叠到不同的通道而不是空间位置中,从而将高分辨率特征与低分辨率特征连接起来,类似于 ResNet 中的 identity mapping。这会将 26 × \times × 26 × \times × 512 feature map 转换为一个 13 × \times × 13 × \times × 2048 feature map,可以将其与原始特征连接在一起。我们的检测器在此扩展的特征图上运行,因此可以访问细粒度的特征。这会适度提高 1% 的性能。
passthrough layer 是特征重排 (不涉及到参数学习),26 × \times × 26 × \times × 512 feature map 使用按行和按列隔行采样的方法,就可以得到 4 个新的特征图,维度都是 13 × \times × 13 × \times × 512 feature map,然后执行 concatenate 操作,得到 13 × \times × 13 × \times × 2048 feature map,相当于一次特征融合。然后同后面的 13 × \times × 13 × \times × 1024 特征图连接在一起形成 13 × \times × 13 × \times × 3072 的特征图,最后在该特征图上卷积做预测,有利于检测小目标。
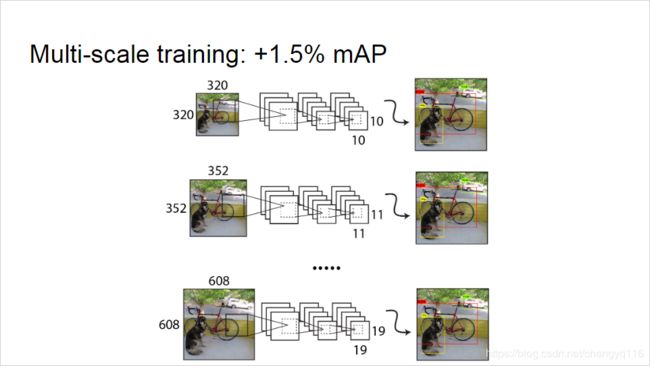
Multi-Scale Training. The original YOLO uses an input resolution of 448 × \times × 448. With the addition of anchor boxes we changed the resolution to 416 × \times × 416. However, since our model only uses convolutional and pooling layers it can be resized on the fly. We want YOLOv2 to be robust to running on images of different sizes so we train this into the model.
Multi-Scale Training. 原始 YOLO 使用的输入分辨率为 448 × \times × 448。添加 anchor boxes 后,我们将分辨率更改为 416 × \times × 416。但是,由于我们的模型仅使用卷积和池化层,因此可以在其上调整大小。我们希望 YOLOv2 能够在不同尺寸的图像上运行,因此我们将其训练到模型中。
Multi-Scale Training 使 YOLOv2 能够适应 images of different sizes,可以在速度和准确性之间轻松地权衡。
Instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size. Since our model downsamples by a factor of 32, we pull from the following multiples of 32: {320, 352, …, 608}. Thus the smallest option is 320 × \times × 320 and the largest is 608 × \times × 608. We resize the network to that dimension and continue training.
不是固定输入图像的大小,我们每隔几次迭代就改变网络。每 10 batches,我们的网络就会随机选择一个新的图像尺寸。由于我们的模型下采样了 32 倍,因此我们从以下 32 的倍数中提取:{320, 352, …, 608}。因此,最小的选择是 320 × \times × 320,最大的选择是 608 × \times × 608。我们将网络调整为该尺寸并继续训练。
YOLOv2 和 SSD one-stage 模型与 RPN 网络本质上无异。RPN 不做类别的预测,只是简单地区分物体与背景。在 two-stage 方法中,RPN 起到的作用是给出 region proposals,其实就是完成粗糙的检测。增加了一个 stage,即采用 R-CNN 网络来进一步提升检测的准确度 (包括给出类别预测)。对于 one-stage 方法,想要一步到位,直接采用 RPN 网络作出精确的预测,要在网络设计上做很多的 tricks。YOLOv2 采用 Multi-Scale Training 策略,同一个模型其实就可以适应多种大小的图片。
This regime forces the network to learn to predict well across a variety of input dimensions. This means the same network can predict detections at different resolutions. The network runs faster at smaller sizes so YOLOv2 offers an easy tradeoff between speed and accuracy.
这种制度迫使网络学会在各种输入维度上进行良好的预测。这意味着同一网络可以预测不同分辨率的检测。网络在较小的尺寸下运行速度更快,因此 YOLOv2 可以在速度和准确性之间轻松地权衡。
regime [reɪˈʒiːm]:n. 政权,政体,社会制度,管理体制
At low resolutions YOLOv2 operates as a cheap, fairly accurate detector. At 288 × \times × 288 it runs at more than 90 FPS with mAP almost as good as Fast R-CNN. This makes it ideal for smaller GPUs, high framerate video, or multiple video streams.
在低分辨率下,YOLOv2 可以用作便宜、相当准确的检测器。288 × \times × 288 运行速度超过 90 FPS,mAP 几乎与 Fast R-CNN 一样好。这使其非常适合较小的 GPU,高帧率视频或多个视频流。
At high resolution YOLOv2 is a state-of-the-art detector with 78.6 mAP on VOC 2007 while still operating above real-time speeds. See Table 3 for a comparison of YOLOv2 with other frameworks on VOC 2007. Figure 4
在高分辨率下,YOLOv2 是在 VOC 2007 上具有 78.6 mAP 的最新检测器,同时仍以实时速度运行。See Table 3 for a comparison of YOLOv2 with other frameworks on VOC 2007. Figure 4
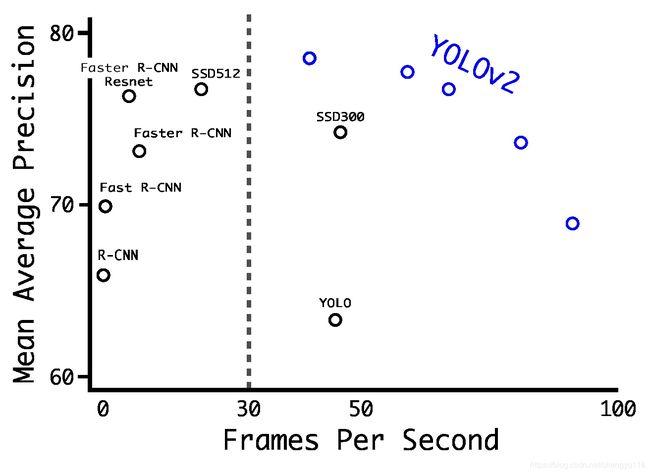
Figure 4: Accuracy and speed on VOC 2007.
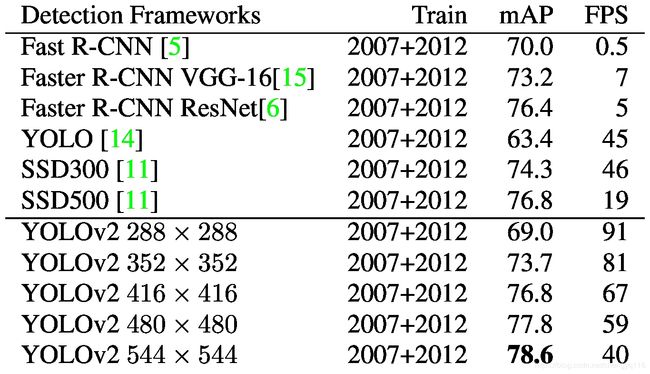
Table 3: Detection frameworks on PASCAL VOC 2007. YOLOv2 is faster and more accurate than prior detection methods. It can also run at different resolutions for an easy tradeoff between speed and accuracy. Each YOLOv2 entry is actually the same trained model with the same weights, just evaluated at a different size. All timing information is on a Geforce GTX Titan X (original, not Pascal model).
YOLOv2 比以前的检测方法更快、更准确。它还可以在不同的分辨率下运行,以便在速度和准确性之间轻松折中。每个 YOLOv2 条目实际上都是具有相同权重的相同训练模型,只是以不同的大小进行了评估。所有时间信息均在 Geforce GTX Titan X (original, not Pascal model) 上测得的。
Further Experiments. We train YOLOv2 for detection on VOC 2012. Table 4 shows the comparative performance of YOLOv2 versus other state-of-the-art detection systems. YOLOv2 achieves 73.4 mAP while running far faster than competing methods. We also train on COCO and compare to other methods in Table 5. On the VOC metric (IOU = .5) YOLOv2 gets 44.0 mAP, comparable to SSD and Faster R-CNN.
Further Experiments. 我们训练了 YOLOv2 在 VOC 2012 上进行检测。表 4 显示了 YOLOv2 与其他最新检测系统的比较性能。YOLOv2 达到 73.4 mAP,同时运行速度远远超过竞争方法。我们还对 COCO 进行了训练,并与表 5 中的其他方法进行了比较。在 VOC 度量标准 (IOU = 0.5) 上,YOLOv2 获得 44.0 mAP,与 SSD 和 Faster R-CNN 相当。

Table 4: PASCAL VOC2012 test detection results. YOLOv2 performs on par with state-of-the-art detectors like Faster R-CNN with ResNet and SSD512 and is 2 - 10 × \times × faster.
par [pɑː(r)]:n. 标准,票面价值,平均数量 adj. 标准的,票面的
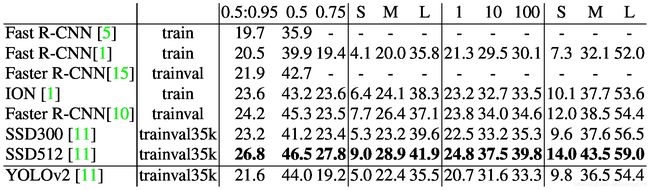
Table 5: Results on COCO test-dev2015. Table adapted from [11]
3. Faster
We want detection to be accurate but we also want it to be fast. Most applications for detection, like robotics or self-driving cars, rely on low latency predictions. In order to maximize performance we design YOLOv2 to be fast from the ground up.
我们希望检测是准确的,但我们也希望它是快速的。大多数检测应用程序,例如机器人技术或自动驾驶汽车,都依赖于低延迟预测。为了最大限度地提高性能,我们将 YOLOv2 设计为从零开始。
Most detection frameworks rely on VGG-16 as the base feature extractor [17]. VGG-16 is a powerful, accurate classification network but it is needlessly complex. The convolutional layers of VGG-16 require 30.69 billion floating point operations for a single pass over a single image at 224 × \times × 224 resolution.
大多数检测框架都依赖 VGG-16 作为基本特征提取器 [17]。VGG-16 是一个功能强大、准确的分类网络,但它不必要地复杂。在 224 × \times × 224 分辨率下对单个图像进行单次运算,VGG-16 的卷积层需要 30.69 billion floating point operations。
The YOLO framework uses a custom network based on the Googlenet architecture [19]. This network is faster than VGG-16, only using 8.52 billion operations for a forward pass. However, it’s accuracy is slightly worse than VGG-16. For single-crop, top-5 accuracy at 224 × \times × 224, YOLO’s custom model gets 88.0% ImageNet compared to 90.0% for VGG-16.
YOLO 框架使用基于 Googlenet 架构的自定义网络 [19]。该网络比 VGG-16 更快,仅使用 8.52 billion 操作进行正向传递。但是,它的准确性比 VGG-16 稍差。在 ImageNet 上,对于单张裁剪图像,224 × \times × 224 分辨率下的 top-5 accuracy,YOLO 的自定义模型获得了 88.0%,而 VGG-16 则为 90.0%。
Darknet-19. We propose a new classification model to be used as the base of YOLOv2. Our model builds off of prior work on network design as well as common knowledge in the field. Similar to the VGG models we use mostly 3 × \times × 3 filters and double the number of channels after every pooling step [17]. Following the work on Network in Network (NIN) we use global average pooling to make predictions as well as 1 × \times × 1 filters to compress the feature representation between 3 × \times × 3 convolutions [9]. We use batch normalization to stabilize training, speed up convergence, and regularize the model [7].
Darknet-19. 我们提出了一种新的分类模型作为 YOLOv2 的基础。我们的模型建立在网络设计的先前工作以及该领域的常识的基础上。与 VGG 模型类似,在每个 pooling 步骤 [17] 之后,我们主要使用 3 × \times × 3 滤波器,并使通道数增加一倍。遵循 Network in Network (NIN) 的工作,我们使用 global average pooling 进行预测以及使用 1 × \times × 1 filters 来压缩 3 × \times × 3 卷积之间的特征表示 [9]。我们使用 batch normalization 来稳定训练,加快收敛速度并正则化模型 [7]。
Our final model, called Darknet-19, has 19 convolutional layers and 5 maxpooling layers. For a full description see Table 6. Darknet-19 only requires 5.58 billion operations to process an image yet achieves 72.9% top-1 accuracy and 91.2% top-5 accuracy on ImageNet.
我们的最终模型称为 Darknet-19,具有 19 个卷积层和 5 个 maxpooling 层。有关完整说明,请参见表 6。Darknet-19 仅需要 5.58 billion 操作来处理图像,但在 ImageNet 上达到 72.9% 的 top-1 精度和 91.2% 的 top-5 精度。
Darknet-19 包含 19 个卷积层。
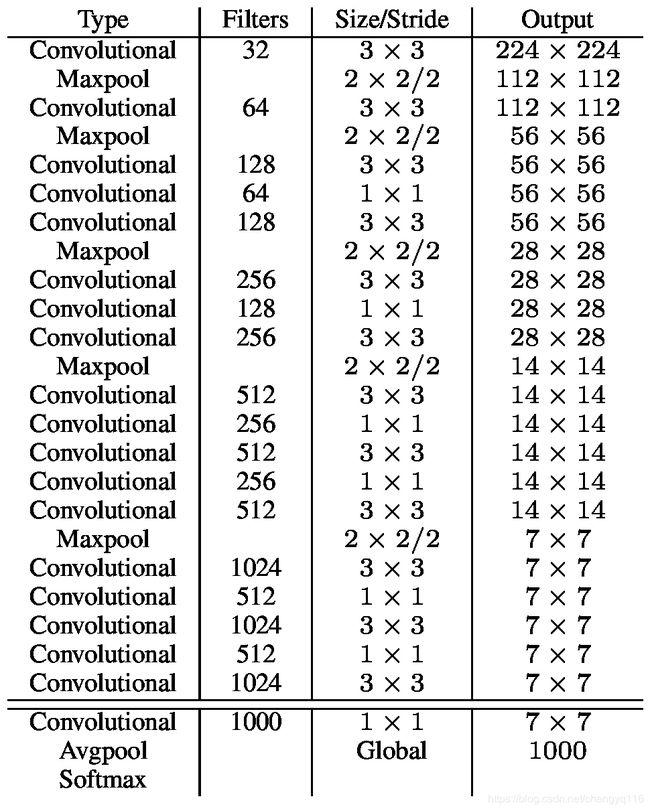
Table 6: Darknet-19.
Training for classification. We train the network on the standard ImageNet 1000 class classification dataset for 160 epochs using stochastic gradient descent with a starting learning rate of 0.1, polynomial rate decay with a power of 4, weight decay of 0.0005 and momentum of 0.9 using the Darknet neural network framework [13]. During training we use standard data augmentation tricks including random crops, rotations, and hue, saturation, and exposure shifts.
Training for classification. 我们使用 Darknet 神经网络框架,using stochastic gradient descent with a starting learning rate of 0.1, polynomial rate decay with a power of 4, weight decay of 0.0005 and momentum of 0.9,在标准 ImageNet 1000 类别分类数据集对网络进行 160 个 epochs 的训练 [13]。在训练过程中,我们使用标准数据增强技巧,包括随机裁剪、旋转以及色相、饱和度和曝光偏移。
As discussed above, after our initial training on images at 224 × \times × 224 we fine tune our network at a larger size, 448. For this fine tuning we train with the above parameters but for only 10 epochs and starting at a learning rate of 1 0 − 3 10^{-3} 10−3. At this higher resolution our network achieves a top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%.
如上所述,在 224 × \times × 224 分辨率下对图像进行初步训练后,我们将以更大的尺寸对网络进行 fine tune,即 448。对于这种 fine tune,我们使用上述参数进行训练,但只有 10 epochs,并以的 1 0 − 3 10^{-3} 10−3 学习率开始。在这个更高的分辨率下,我们的网络实现了 a top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%。
YOLOv1 Training
YOLOv2 Training
polynomial [.pɒli'nəʊmiəl]:adj. 多项式的,多词学名的 n. 多项式,多词学名
Training for detection. We modify this network for detection by removing the last convolutional layer and instead adding on three 3 × \times × 3 convolutional layers with 1024 filters each followed by a final 1 × \times × 1 convolutional layer with the number of outputs we need for detection. For VOC we predict 5 boxes with 5 coordinates each and 20 classes per box so 125 filters. We also add a passthrough layer from the final 3 × \times × 3 × \times × 512 layer to the second to last convolutional layer so that our model can use fine grain features.
Training for detection. 我们修改此网络以进行检测,方法是删除最后一个卷积层,加上了三个具有 1024 filters 的 3 × \times × 3 卷积层,然后添加最后 1 × \times × 1 卷积层,其中包含我们需要检测的输出数量。对于 VOC,我们预测 5 个边界框,每个边界框有 5 个坐标和 20 个类别,所以有 125 个 filters。我们还从最后的 3 × \times × 3 × \times × 512 layer 到倒数第二个卷积层添加一个 passthrough layer,以便我们的模型可以使用细粒度特征。
boxes × \times × (coordinates + classes) = 5 × \times × (5 + 20) = 125 filters

YOLOv1 S × S × ( B × 5 + C ) S \times S \times (B \times 5 + C) S×S×(B×5+C) tensor.
YOLOv2 S × S × ( B × ( 5 + C ) ) S \times S \times (B \times (5 + C)) S×S×(B×(5+C)) tensor.
We train the network for 160 epochs with a starting learning rate of 1 0 − 3 10^{-3} 10−3, dividing it by 10 at 60 and 90 epochs. We use a weight decay of 0.0005 and momentum of 0.9. We use a similar data augmentation to YOLO and SSD with random crops, color shifting, etc. We use the same training strategy on COCO and VOC.
我们训练网络 160 epochs,起始学习率为 1 0 − 3 10^{-3} 10−3,在 60 和 90 epochs 将其除以 10。我们使用 0.0005 的权重衰减和 0.9 的动量。我们使用与 YOLO 和 SSD 类似的数据增强方法,并进行随机裁剪、颜色偏移等。我们对 COCO 和 VOC 使用相同的训练策略。
4. Stronger
We propose a mechanism for jointly training on classification and detection data. Our method uses images labelled for detection to learn detection-specific information like bounding box coordinate prediction and objectness as well as how to classify common objects. It uses images with only class labels to expand the number of categories it can detect.
我们提出了一种联合训练分类和检测数据的机制。我们的方法使用标记为检测的图像来学习特定于检测的信息,例如边界框坐标预测和 objectness 以及如何对常见目标进行分类。它使用仅带有类别标签的图像来扩展它可以检测到的类别数量。
During training we mix images from both detection and classification datasets. When our network sees an image labelled for detection we can backpropagate based on the full YOLOv2 loss function. When it sees a classification image we only backpropagate loss from the classification-specific parts of the architecture.
在训练期间,我们混合了来自检测和分类数据集的图像。当我们的网络看到标记为检测的图像时,我们可以基于完整的 YOLOv2 loss function 向后传播。当它看到分类的图像时,我们仅从特定于分类架构的部分反向传播 loss。
This approach presents a few challenges. Detection datasets have only common objects and general labels, like “dog” or “boat”. Classification datasets have a much wider and deeper range of labels. ImageNet has more than a hundred breeds of dog, including “Norfolk terrier”, “Yorkshire terrier”, and “Bedlington terrier”. If we want to train on both datasets we need a coherent way to merge these labels.
这种方法提出了一些挑战 检测数据集仅具有通用目标和通用标签,例如狗或船。分类数据集具有更广泛和更深层次的标签。ImageNet 有一百多种犬,其中包括 Norfolk terrier, Yorkshire terrier, and Bedlington terrier。 如果要对两个数据集进行训练,则需要一种一致的方式来合并这些标签。
breed [briːd]:v. (使) 动物繁殖,(动物) 交配,(为某种目的而) 培育 (动、植物),培养,滋生,(通过核反应) 增殖可裂变物质 n. 品种,(人或物的) 类型,种类,养殖,繁殖
terrier ['teriə(r)]:n.㹴,㹴犬 (gēng quǎn)
coherent [kəʊˈhɪərənt]:adj. 连贯的,一致的,明了的,清晰的,凝聚性的,互相耦合的,粘在一起的
mutually [ˈmjuːtʃuəli]:adv. 互相地,互助
exclusive [ɪkˈskluːsɪv]:adj. 独有的,排外的,专一的 n. 独家新闻,独家经营的项目,排外者
Most approaches to classification use a softmax layer across all the possible categories to compute the final probability distribution. Using a softmax assumes the classes are mutually exclusive. This presents problems for combining datasets, for example you would not want to combine ImageNet and COCO using this model because the classes “Norfolk terrier” and “dog” are not mutually exclusive.
大多数分类方法在所有可能的类别中使用 softmax 层来计算最终概率分布。使用 softmax 假定类是互斥的。这带来了合并数据集的问题,例如,您不希望使用此模型将 ImageNet 和 COCO 合并,因为 Norfolk terrier and dog 不是互斥的。
We could instead use a multi-label model to combine the datasets which does not assume mutual exclusion. This approach ignores all the structure we do know about the data, for example that all of the COCO classes are mutually exclusive.
我们可以使用多标签模型来组合不假定互斥的数据集。这种方法忽略了我们已知的关于数据的所有结构,例如所有 COCO 类都是互斥的。
Hierarchical classification. ImageNet labels are pulled from WordNet, a language database that structures concepts and how they relate [12]. In WordNet, “Norfolk terrier” and “Yorkshire terrier” are both hyponyms of “terrier” which is a type of “hunting dog”, which is a type of “dog”, which is a “canine”, etc. Most approaches to classification assume a flat structure to the labels however for combining datasets, structure is exactly what we need.
Hierarchical classification. ImageNet 标签是从 WordNet 中提取的,WordNet 是一个语言库,它构造概念以及它们之间的关系 [12]。在 WordNet 中,Norfolk terrier and Yorkshire terrier 都是 terrier 的下位词,terrier 是 hunting dog 的一种,hunting dog 是 dog 的一种,dog 是 canine 的一种,等等。分类假定标签的结构平坦,但是对于组合数据集,结构正是我们所需要的。
WordNet is structured as a directed graph, not a tree, because language is complex. For example a “dog” is both a type of “canine” and a type of “domestic animal” which are both synsets in WordNet. Instead of using the full graph structure, we simplify the problem by building a hierarchical tree from the concepts in ImageNet.
由于语言很复杂,WordNet 的结构是有向图,而不是树。例如,狗既是犬的类型,又是家畜的类型,它们都是 WordNet中的同义词集。我们不使用完整的图结构,而是通过根据 ImageNet 中的概念构建层次树来简化问题。
To build this tree we examine the visual nouns in ImageNet and look at their paths through the WordNet graph to the root node, in this case “physical object”. Many synsets only have one path through the graph so first we add all of those paths to our tree. Then we iteratively examine the concepts we have left and add the paths that grow the tree by as little as possible. So if a concept has two paths to the root and one path would add three edges to our tree and the other would only add one edge, we choose the shorter path.
为了构建该树,我们检查 ImageNet 中的视觉名词,并查看它们通过 WordNet 图形到根节点 (在本例中为 physical object) 的路径。许多同义词集在图中只有一条路径,因此首先我们将所有这些路径添加到树中。然后,我们迭代检查剩下的概念,并添加使树长得尽可能小的路径。因此,如果一个概念有两个到根的路径,一个路径会在树上添加三个边,而另一个路径只会添加一个边,那么我们选择较短的路径。
hierarchical [ˌhaɪəˈrɑːkɪ.kəl]:adj. 分层的,等级体系的
hyponym [ˈhaɪpənɪm]:n. 下义词,下位词
canine [ˈkeɪnaɪn]:adj. 犬的,犬齿的,犬科的,似犬的 n. 犬,犬齿
domestic [dəˈmestɪk]:adj. 国内的,家庭的,驯养的,一心只管家务的 n. 国货,佣人
synset:同义词集合
noun [naʊn]:n. 名词
The final result is WordTree, a hierarchical model of visual concepts. To perform classification with WordTree we predict conditional probabilities at every node for the probability of each hyponym of that synset given that synset. For example, at the “terrier” node we predict:
最终结果是 WordTree,这是视觉概念的分层模型。为了用 WordTree 执行分类,我们在给定同义集的情况下,针对该同义集的每个下位词的概率,预测每个节点的条件概率。例如,在 terrier 节点,我们预测:
P r ( Norfolk terrier ∣ terrier ) P r ( Yorkshire terrier ∣ terrier ) P r ( Bedlington terrier ∣ terrier ) . . . \begin{aligned} Pr(\text{Norfolk terrier} &| \text{terrier}) \\ Pr(\text{Yorkshire terrier} &| \text{terrier}) \\ Pr(\text{Bedlington terrier} &| \text{terrier}) \\ ... \end{aligned} Pr(Norfolk terrierPr(Yorkshire terrierPr(Bedlington terrier...∣terrier)∣terrier)∣terrier)
If we want to compute the absolute probability for a particular node we simply follow the path through the tree to the root node and multiply to conditional probabilities. So if we want to know if a picture is of a Norfolk terrier we compute:
如果要计算特定节点的绝对概率,我们只需沿着树到根节点的路径,再乘以条件概率。因此,如果我们想知道图片是否为 Norfolk terrier,我们可以计算:
P r ( N o r f o l k t e r r i e r ) = P r ( N o r f o l k t e r r i e r ∣ t e r r i e r ) ∗ P r ( t e r r i e r ∣ h u n t i n g d o g ) ∗ . . . ∗ ∗ P r ( m a m m a l ∣ P r ( a n i m a l ) ∗ P r ( a n i m a l ∣ p h y s i c a l o b j e c t ) \begin{aligned} Pr(Norfolk terrier) = P r(Norfolk terrier | terrier)\\ ∗Pr(terrier | hunting dog)\\ ∗ ... ∗\\ ∗Pr(mammal | P r(animal)\\ ∗Pr(animal | physical object)\\ \end{aligned}\\ Pr(Norfolkterrier)=Pr(Norfolkterrier∣terrier)∗Pr(terrier∣huntingdog)∗...∗∗Pr(mammal∣Pr(animal)∗Pr(animal∣physicalobject)
For classification purposes we assume that the the image contains an object: P r ( physical object ) = 1 Pr(\text{physical object}) = 1 Pr(physical object)=1.
为了分类,我们假设图像包含一个目标: P r ( physical object ) = 1 Pr(\text{physical object}) = 1 Pr(physical object)=1
To validate this approach we train the Darknet-19 model on WordTree built using the 1000 class ImageNet. To build WordTree1k we add in all of the intermediate nodes which expands the label space from 1000 to 1369. During training we propagate ground truth labels up the tree so that if an image is labelled as a “Norfolk terrier” it also gets labelled as a “dog” and a “mammal”, etc. To compute the conditional probabilities our model predicts a vector of 1369 values and we compute the softmax over all synsets that are hyponyms of the same concept, see Figure 5.
为了验证这种方法,我们在使用 1000 类 ImageNet 构建的 WordTree 上训练 Darknet-19 模型。为了构建 WordTree1k,我们添加了所有中间节点,这将标签空间从 1000 扩展到了 1369。在训练过程中,我们在树上传播了 ground truth 标签,因此,如果图像被标记为 Norfolk terrier,则它也将被标记为狗和哺乳动物等。为计算条件概率,我们的模型预测了一个 1369 个值的向量,并且我们计算了所有属于同一概念的下义词的同义集的 softmax,请参见图 5。
建立 WordTree1k 模型,在构建 WordTree 时添加 369 个中间节点以便构成一个完整的 WordTree1k 模型。YOLO9000 是一个多标签分类的模型,例如一个含有 1369 个标签的的数据,其 one-hot 编码的形式为在多个位置处为 1,其余的位置均为 0。
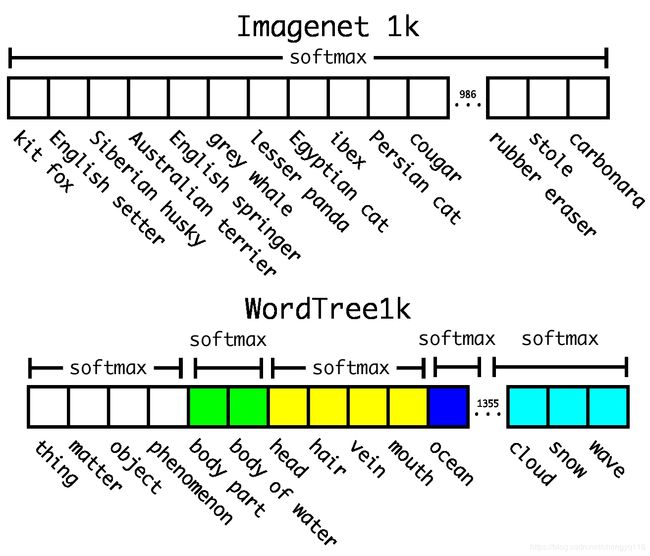
Figure 5: Prediction on ImageNet vs WordTree. Most ImageNet models use one large softmax to predict a probability distribution. Using WordTree we perform multiple softmax operations over co-hyponyms.
大多数 ImageNet 模型使用一个较大的 softmax 来预测概率分布。使用 WordTree,我们对同义词执行多个 softmax 操作。
mammal [ˈmæml]:n. 哺乳动物
hyponym [ˈhaɪpənɪm]:n. 下义词,下位词
co-hyponyms:并列下义词
synset:同义词集合
Using the same training parameters as before, our hierarchical Darknet-19 achieves 71.9% top-1 accuracy and 90.4% top-5 accuracy. Despite adding 369 additional concepts and having our network predict a tree structure our accuracy only drops marginally. Performing classification in this manner also has some benefits. Performance degrades gracefully on new or unknown object categories. For example, if the network sees a picture of a dog but is uncertain what type of dog it is, it will still predict “dog” with high confidence but have lower confidences spread out among the hyponyms.
使用与以前相同的训练参数,我们的分层 Darknet-19 达到 71.9% 的 top-1 准确性和 90.4% 的 top-5 准确性。尽管添加了 369 个其他概念,并且我们的网络预测了树结构,但我们的准确性仅下降了一点。以这种方式执行分类也有一些好处。在新的或未知的目标类别上,性能会正常降低。例如,如果网络看到一条狗的图片,但不确定它是哪种类型的狗,它仍将以较高的置信度预测狗,但在下义词中会散布较低的置信度。
marginally [ˈmɑːdʒɪnəli]:adv. 稍微,略微地,轻微地,很少地,边缘地,在页边,最低限度地
gracefully [ˈɡreɪsfəli]:adv. 优雅地,温文地
This formulation also works for detection. Now, instead of assuming every image has an object, we use YOLOv2’s objectness predictor to give us the value of P r ( physical object ) Pr(\text{physical object}) Pr(physical object). The detector predicts a bounding box and the tree of probabilities. We traverse the tree down, taking the highest confidence path at every split until we reach some threshold and we predict that object class.
该表达方式也可用于检测。现在,我们不用假设每个图像都有一个目标,而是使用 YOLOv2 的目标预测器为我们提供 P r ( physical object ) Pr(\text{physical object}) Pr(physical object) 的值。检测器预测边界框和概率树。我们向下遍历树,在每次拆分时采用最高的置信度,直到达到某个阈值并预测该目标类。
在预测物体的类别时,我们遍历整个 WordTree,在每个拆分中采用最高的置信度路径,直到分类概率小于某个阈值 (thresh = .6) 时,然后预测结果。
traverse ['trævɜːs; trə'vɜːs]:v. 穿过,来回移动,反驳,阻挠,详细研究,旋转 n. 穿过,横挡,(大炮等的) 横转装置,测量导线,(壕沟的) 土护墙 adj. 横贯的
Dataset combination with WordTree. We can use WordTree to combine multiple datasets together in a sensible fashion. We simply map the categories in the datasets to synsets in the tree. Figure 6 shows an example of using WordTree to combine the labels from ImageNet and COCO. WordNet is extremely diverse so we can use this technique with most datasets.
Dataset combination with WordTree. 我们可以使用 WordTree 以明智的方式将多个数据集组合在一起。我们仅将数据集中的类别映射到树中的同义词集。图 6 显示了使用 WordTree 组合 ImageNet 和 COCO 的标签的示例。WordNet 非常多样化,因此我们可以对大多数数据集使用此技术。
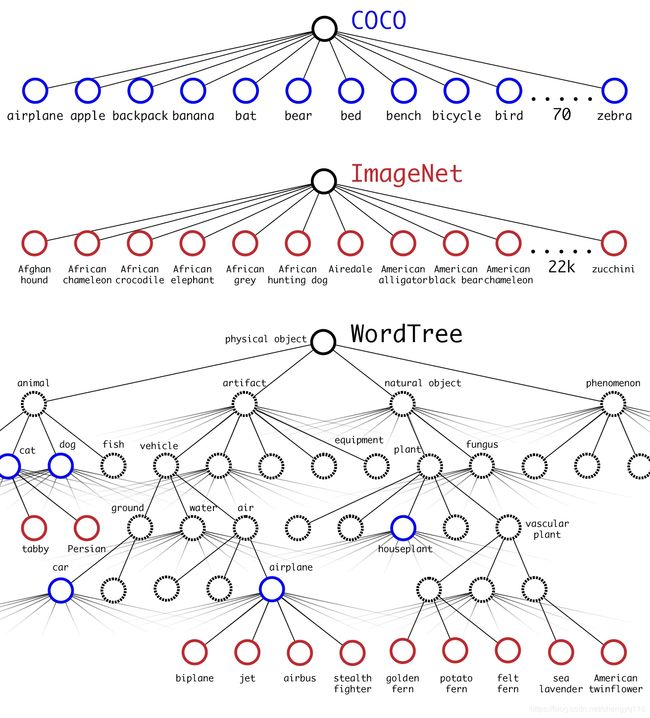
Figure 6: Combining datasets using WordTree hierarchy. Using the WordNet concept graph we build a hierarchical tree of visual concepts. Then we can merge datasets together by mapping the classes in the dataset to synsets in the tree. This is a simplified view of WordTree for illustration purposes.
Figure 6: Combining datasets using WordTree hierarchy. 使用 WordNet 概念图,我们可以构建视觉概念的层次树。 然后,我们可以通过将数据集中的类映射到树中的同义词集来将数据集合并在一起。这是 WordTree 的简化视图,用于说明目的。
WordTree 文件 darknet/data/9k.tree
在 darknet/data/9k.tree 中,第一列表示类别的标签,标签对应的类别可以在 darknet/data/9k.names 通过行数 (从 0 开始计数) 对应上。
在 darknet/data/9k.tree 中,第二列表示该节点的父节点,值为 -1 的话表示父节点为空。
sensible [ˈsensəbl]:adj. 明智的,通情达理的,合乎情理的,意识到的,能感觉到的 n. 可感觉到的东西,敏感的人
diverse [daɪˈvɜːs]:adj. 不同的,相异的,多种多样的,形形色色的
versus [ˈvɜːsəs]:prep. 对,对抗,与......相对,与......相比
Joint classification and detection. Now that we can combine datasets using WordTree we can train our joint model on classification and detection. We want to train an extremely large scale detector so we create our combined dataset using the COCO detection dataset and the top 9000 classes from the full ImageNet release. We also need to evaluate our method so we add in any classes from the ImageNet detection challenge that were not already included. The corresponding WordTree for this dataset has 9418 classes. ImageNet is a much larger dataset so we balance the dataset by oversampling COCO so that ImageNet is only larger by a factor of 4:1.
Joint classification and detection. 现在我们可以使用 WordTree 合并数据集,我们可以在分类和检测上训练我们的联合模型。我们想训练一个超大型检测器,因此我们使用 COCO 检测数据集和完整 ImageNet 版本中的前 9000 个类来创建组合数据集。我们还需要评估我们的方法,以便我们添加 ImageNet 检测挑战中尚未包含的所有类。此数据集的相应 WordTree 具有 9418 个类。ImageNet 是一个更大的数据集,因此我们通过对 COCO 进行过采样来平衡数据集,以使 ImageNet 仅以 4:1 的系数扩大。
Using this dataset we train YOLO9000. We use the base YOLOv2 architecture but only 3 priors instead of 5 to limit the output size. When our network sees a detection image we backpropagate loss as normal. For classification loss, we only backpropagate loss at or above the corresponding level of the label. For example, if the label is “dog” we do assign any error to predictions further down in the tree, “German Shepherd” versus “Golden Retriever”, because we do not have that information.
使用此数据集,我们训练 YOLO9000。我们使用基本的 YOLOv2 架构,但是仅使用 3 priors 而不是 5 priors 来限制输出大小。当我们的网络看到检测图像时,我们会像往常一样反向传播 loss。对于分类损失,我们仅反向传播等于或高于标签相应水平的损失。例如,如果标签为 dog,则我们确实会将任何错误分配给树中 “German Shepherd” versus “Golden Retriever” 的预测,因为我们没有该信息。
When it sees a classification image we only backpropagate classification loss. To do this we simply find the bounding box that predicts the highest probability for that class and we compute the loss on just its predicted tree. We also assume that the predicted box overlaps what would be the ground truth label by at least .3 IOU and we backpropagate objectness loss based on this assumption.
当看到分类图像时,我们仅反向传播分类损失。为此,我们只需找到预测该类别最高概率的边界框,然后仅在其预测树上计算损失即可。我们还假设,预测框与 ground truth 标签的重叠量至少为 0.3 IOU,并且我们根据此假设反向传播目标损失。
Using this joint training, YOLO9000 learns to find objects in images using the detection data in COCO and it learns to classify a wide variety of these objects using data from ImageNet.
通过这次联合训练,YOLO9000 学会了使用 COCO 中的检测数据来查找图像中的目标,并且学会了使用 ImageNet 中的数据对这些目标进行各种各样的分类。
We evaluate YOLO9000 on the ImageNet detection task. The detection task for ImageNet shares on 44 object categories with COCO which means that YOLO9000 has only seen classification data for the majority of the test images, not detection data. YOLO9000 gets 19.7 mAP overall with 16.0 mAP on the disjoint 156 object classes that it has never seen any labelled detection data for. This mAP is higher than results achieved by DPM but YOLO9000 is trained on different datasets with only partial supervision [4]. It also is simultaneously detecting 9000 other object categories, all in real-time.
我们在 ImageNet 检测任务上评估 YOLO9000。ImageNet 的检测任务与 COCO 共享 44 个目标类别,这意味着 YOLO9000 仅看到了大多数测试图像的分类数据,而不是检测数据。YOLO9000 整体上获得了 19.7 mAP,在从未见过任何标记的检测数据的情况下,在不相交的 156 个目标类别中获得了 16.0 mAP。该 mAP 高于 DPM 所获得的结果,但是 YOLO9000 仅在部分监督下就在不同的数据集上进行了训练 [4]。它还可以同时实时检测 9000 个其他目标类别。
simultaneously [ˌsɪmlˈteɪniəsli]:adv. 同时地
conversely [ˈkɒnvɜːsli]:adv. 相反地
trunks [trʌŋks]:n. 中继线,运动短裤,男式游泳裤
When we analyze YOLO9000’s performance on ImageNet we see it learns new species of animals well but struggles with learning categories like clothing and equipment. New animals are easier to learn because the objectness predictions generalize well from the animals in COCO. Conversely, COCO does not have bounding box label for any type of clothing, only for person, so YOLO9000 struggles to model categories like “sunglasses” or “swimming trunks”.
当我们在 ImageNet 上分析 YOLO9000 的性能时,我们会看到它很好地学习了新的动物种类,但是在学习服装和设备等类别时却遇到了困难。新动物更容易学习,因为 objectness prediction 可以从 COCO 中的动物得到很好的概括。相反,COCO 没有任何类型的服装的边界框标签,仅针对人,因此 YOLO9000 很难为太阳镜或游泳裤等类别建模。
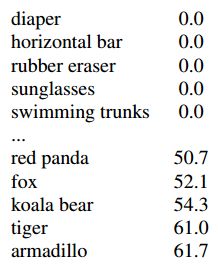
Table 7: YOLO9000 Best and Worst Classes on ImageNet. The classes with the highest and lowest AP from the 156 weakly supervised classes. YOLO9000 learns good models for a variety of animals but struggles with new classes like clothing or equipment.
Table 7: YOLO9000 Best and Worst Classes on ImageNet. 156 个弱监督类别中具有最高和最低 AP 的类别。YOLO9000 为各种动物学习良好的模型,但在服装或装备等新类上却执行困难。
diaper [ˈdaɪpə(r)]:n. 尿布 vt. 给孩子换尿布
eraser [ɪˈreɪzə(r)]:n. 橡皮,擦除器,清除器
rubber [ˈrʌbə(r)]:n. 橡胶,橡皮,合成橡胶,避孕套 adj. 橡胶制成的 vt. 涂橡胶于,用橡胶制造 vi. 扭转脖子看,好奇地引颈而望
panda [ˈpændə]:n. 熊猫,猫熊
koala [kəʊˈɑːlə]:n. 树袋熊,无尾熊 (产于澳大利亚,又名考拉)
armadillo [ˌɑːməˈdɪləʊ]:n. 犰狳
5. Conclusion
We introduce YOLOv2 and YOLO9000, real-time detection systems. YOLOv2 is state-of-the-art and faster than other detection systems across a variety of detection datasets. Furthermore, it can be run at a variety of image sizes to provide a smooth tradeoff between speed and accuracy.
我们将介绍实时检测系统 YOLOv2 和 YOLO9000。YOLOv2 是最先进的,并且在各种检测数据集中比其他检测系统要快。此外,它可以在各种图像尺寸下运行,以在速度和精度之间提供平滑的折中。
YOLO9000 is a real-time framework for detection more than 9000 object categories by jointly optimizing detection and classification. We use WordTree to combine data from various sources and our joint optimization technique to train simultaneously on ImageNet and COCO. YOLO9000 is a strong step towards closing the dataset size gap between detection and classification.
YOLO9000 是一个实时框架,可通过联合优化检测和分类来检测 9000 多个目标类别。我们使用 WordTree 合并来自各种来源的数据,并使用联合优化技术在 ImageNet 和 COCO 上同时进行训练。YOLO9000 是朝着缩小检测和分类之间的数据集大小差距迈出的重要一步。
Many of our techniques generalize outside of object detection. Our WordTree representation of ImageNet offers a richer, more detailed output space for image classification. Dataset combination using hierarchical classification would be useful in the classification and segmentation domains. Training techniques like multi-scale training could provide benefit across a variety of visual tasks.
我们的许多技术都在目标检测之外进行了概括。ImageNet 的 WordTree 表示形式为图像分类提供了更丰富、更详细的输出空间。使用分层分类的数据集组合在分类和分割领域中将很有用。诸如多尺度训练之类的训练技术可以在各种视觉任务中提供益处。
For future work we hope to use similar techniques for weakly supervised image segmentation. We also plan to improve our detection results using more powerful matching strategies for assigning weak labels to classification data during training. Computer vision is blessed with an enormous amount of labelled data. We will continue looking for ways to bring different sources and structures of data together to make stronger models of the visual world.
对于将来的工作,我们希望使用类似的技术进行弱监督的图像分割。我们还计划使用更强大的匹配策略 (在训练过程中为分类数据分配弱标签) 来改善检测结果。计算机视觉拥有大量的标记数据。我们将继续寻找方法,将不同的数据源和数据结构整合在一起,以建立更强大的视觉世界模型。
enormous [ɪˈnɔːməs]:adj. 庞大的,巨大的,凶暴的,极恶的
References
[7] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
[11] SSD: Single Shot MultiBox Detector
WORDBOOK
KEY POINTS
https://pjreddie.com/publications/yolo/
https://pjreddie.com/publications/yolo9000/
https://pjreddie.com/publications/