常见集成模型总结
- 简介
- Bagging, Boosting 和 Stacking
- AdaBoost( 待更新)
- 随机森林
- 算法:
- 优点:
- 缺点:
- XGBOOST
- 算法
- 优点
- 缺点
- LGB
简介
Bagging, Boosting 和 Stacking
Bagging(Bootstrap汇总)是一种集成方法。首先,我们创建随机训练数据集样本(训练数据集的子集)。然后我们为每个样本建立分类器。最后,这些多分类器的结果将结合起来,使用平均或多数投票。Bagging有助于降低方差。
Boosting提供了预测模块的连续学习功能。第一个预测模块从整个数据集上学习,下一个预测模块在前一个的性能基础上在训练数据集上学习。首先对原始数据集进行分类,并给每个观测给予同样的权重。如果第一个学习模块错误预测了类,那么将会赋予错误分类观测较高的权重。这个过程将反复迭代,不断添加分类学习模块,直到达到模型数量或者某个准确度。Boosting有比Bagging更好的预测精准度,但它有时也会过度拟合训练数据。
Stacking工作分为两个阶段。首先,我们使用多个基础分类器来预测分类。然后,一个新的学习模块与它们的预测结果结合起来,来降低泛化误差。
AdaBoost( 待更新)
随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。而”Random Forests”是他们的商标。这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合Breimans的”Bootstrap aggregating”想法和Ho的”random subspace method” 以建造决策树的集合。
算法:
用N来表示训练用例(样本)的个数,M表示特征数目。
1. 输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
2. 对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。
3. 每棵树都会完整成长而不会剪枝(Pruning,这有可能在建完一棵正常树状分类器后会被采用)。
优点:
随机森林的优点有:
- 对于很多种数据,它可以产生高准确度的分类器。 它可以处理大量的输入变量。 它可以在决定类别时,评估变量的重要性。
- 在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计。
- 它包含一个好方法可以估计丢失的数据,并且,如果有很大一部分的数据丢失,仍可以维持准确度。 它提供一个实验方法,可以去侦测variable interactions。 对于不平衡的分类数据集来说,它可以平衡误差。
- 它计算各例中的亲近度,对于数据挖掘、侦测离群点(outlier)和将数据可视化非常有用。
- 使用上述。它可被延伸应用在未标记的数据上,这类数据通常是使用非监督式聚类。也可侦测偏离者和观看数据。 学习过程是很快速的。
缺点:
1、随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟
2、对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
XGBOOST
xgboost 的全称是 eXtreme Gradient Boosting。正如其名,它是 Gradient Boosting Machine 的一个 c++ 实现,作者为正在华盛顿大学研究机器学习的大牛陈天奇。他在研究中深感自己受制于现有库的计算速度和精度,因此在一年前开始着手搭建 xgboost 项目,并在去年夏天逐渐成型。xgboost 最大的特点在于,它能够自动利用 CPU 的多线程进行并行,同时在算法上加以改进提高了精度。它的处女秀是 Kaggle 的希格斯子信号识别竞赛,因为出众的效率与较高的预测准确度在比赛论坛中引起了参赛选手的广泛关注,在 1700 多支队伍的激烈竞争中占有一席之地。随着它在 Kaggle 社区知名度的提高,最近也有队伍借助 xgboost 在比赛中夺得第一。
算法
目标函数:
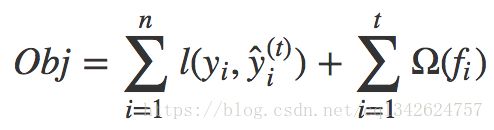
我们要学习的是那些函数 fi f i ,每个函数都包含树的结构和叶子分数。这比传统的你可以找到捷径的优化问题要难得多。在 tree ensemble 中,参数对应了树的结构,以及每个叶子节点上面的预测分数。 一次性训练所有的树并不容易。 相反,我们使用一个附加的策略:优化好我们已经学习完成的树,然后一次添加一棵新的树。 我们通过 ŷ (t)i y ̂ i ( t ) 来关注步骤 t 的预测值,所以我们有
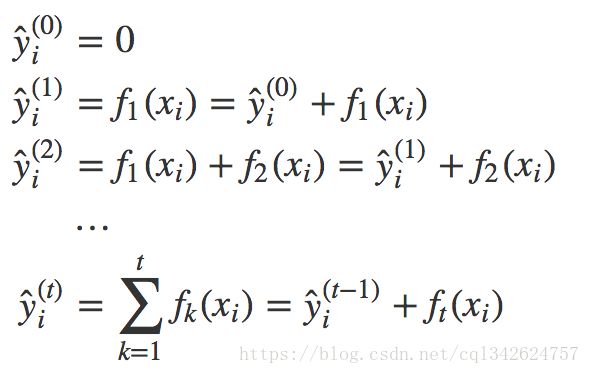
目标方法:
xgboost与gbdt比较大的不同就是目标函数的定义

所以在一般情况下,我们把损失函数的泰勒展开到二阶:
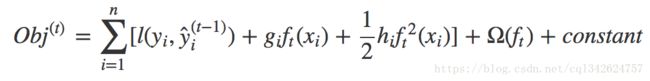

这个定义的一个重要优点是它只依赖于 gi 和 hi 。这就是 xgboost 如何支持自定义损失函数。 我们可以使用完全相同的使用 gi 和 hi 作为输入的 solver(求解器)来对每个损失函数进行优
模型复杂度:
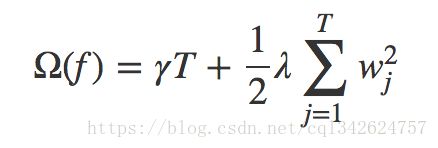
这里 w 是树叶上的分数向量,q 是将每个数据点分配给叶子的函数,T 是树叶的数量。
结构分数 (衡量一棵树有多好):
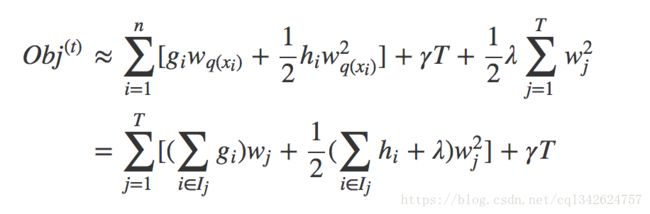
在这个等式中 wj w j 是相互独立的,形式 Gjwj+12(Hj+λ)w2j 是二次的,对于给定的结构 q(x) 的最好的 wj w j ,我们可以得到最好的客观规约:

学习树结构
尽量一次优化树的一个层次。 具体来说,将一片叶子分成两片,并得到分数:

这个公式可以分解为 1) 新左叶上的得分 2) 新右叶上的得分 3) 原始叶子上的得分 4) additional leaf(附加叶子)上的正则化。 我们可以在这里看到一个重要的事实:如果增益小于 γ,我们最好不要添加那个分支。这正是基于树模型的 pruning(剪枝) 技术!
论文算法

xgboost相比传统gbdt有何不同
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
优点
缺点
不能用类似 mini batch 的方式来训练,需要对数据进行无数次的遍历。如果想要速度,就需要把数据都预加载在内存中,但这样数据就会受限于内存的大小;如果想要训练更多的数据,就要使用外存版本的决策树算法。虽然外存算法也有较多优化,SSD 也在普及,但在频繁的 IO 下,速度还是比较慢的。
LGB
参考:
https://www.csdn.net/article/2015-10-20/2825965
https://zh.wikipedia.org/wiki/%E9%9A%8F%E6%9C%BA%E6%A3%AE%E6%9E%97
https://cosx.org/2015/03/xgboost/
机器学习算法中 GBDT 和 XGBOOST 的区别有哪些? - wepon的回答 - 知乎
https://www.zhihu.com/question/41354392/answer/98658997
如何看待微软新开源的LightGBM? - 柯国霖的回答 - 知乎
https://www.zhihu.com/question/51644470/answer/130946285