Python批量处理文件、图片、视频【干货建议收藏】
文章目录
- 一、批量读
- 1.os读取文件名
- 2.读文件个数和文件名
- 二、批量写
- 1.批量筛选
- 2.批量重命名
- 3.批量复制或移动
- 4.批量保存
- 三、批量修改图片、视频
- 1.批量下载图片
- 2.批量压缩图片
- 3.批量压缩视频
一、批量读
测试目录:


1.os读取文件名
遍历文件夹:os.listdir() ,不会进入子目录:
import os
folder_name = 'D:/test'
test_id = 1
file_names = os.listdir(folder_name)
os.chdir(folder_name)
for name in file_names:
print(name)
test_id += 1
print(test_id)
name:文件名,test_id:遍历次数

文件个数:
import os
folder_name = 'D:/test'
test_id = 0
for i in range(len(os.listdir(folder_name))):
print(i)
test_id += 1
print('遍历次数:',test_id)

提示:我们经常会用 test_id += 1 的方式记录文件个数,len(os.listdir(folder_name)才是更加优雅的哦!
文件名及文件个数:
枚举 enumerate():
import os
folder_name = 'D:/test'
test_id = 0
for i,filename in enumerate(os.listdir(folder_name)):
print(i,filename)
test_id += 1
print('遍历次数:',test_id)
i :是文件数,filename:文件名

提示:别在range()了,推荐枚举真的很好用!!!
2.读文件个数和文件名
多层级用os.walk() ,会进入子目录:
import os
folder_name = 'D:/test'
test_id = 0
for a,b,files in os.walk(folder_name):
print(a,'\n',b,'\n',files)
test_id += 1
print(test_id)
a: 当前目录名称,b:是否有子目录(有则进入),files:文件名称

test_id:是遍历次数
二、批量写
1.批量筛选
-
切片
切片操作基本表达式:object[start_index:end_index:step]import os folder_name = 'D:/test' test_id = 0 for i, name in enumerate(os.listdir(folder_name)): if name == 'good1.jpg': print("\n是否有good1.jpg: ", name) # 直接筛选 if name[:4] == 'good': print("\n包含关键词good: ", name) # 关键词 if name[-4:] == '.jpg': print("格式为.jpg: ", name) # 格式 test_id += 1 print('遍历次数:', test_id)效果:

-
切分
文件路径拼接import os path= 'D:/test' files = [os.path.join(path, file) for file in os.listdir(path)] for i,file in enumerate(files): print(i,file)得到所有文件的完整路径:

单文件完整路径切分os.path.split()import os file_path = "D:/test/good1.jpg" (filepath, tempfilename) = os.path.split(file_path) (filename, extension) = os.path.splitext(tempfilename) print('路径:', filepath, '\n完整名称:', tempfilename, '\n名称:', filename, '\n格式:', extension)
批量提取并筛选:import os path = 'D:/test' files = [os.path.join(path, file) for file in os.listdir(path)] for i, file in enumerate(files): (filepath, tempfilename) = os.path.split(file) (filename, extension) = os.path.splitext(tempfilename) if extension == '.jpg': # 根据后缀筛选 print("路径:", filepath, "名称:", filename)
-
正则
reimport os import re path = 'D:/test' for i, name in enumerate(os.listdir(folder_name)): p = re.findall("(.*)_.*_.*", name) num = re.findall(".*_(.*)_.*", name) e = re.findall(".*_.*_(.*)", name) print(p, num, e)根据_下划线_正则:(这里吧123提炼出来了,后面使用时可以批量操作)


2.批量重命名
重命名:os.rename()
-
直接修改
import os folder_name = 'D:/test' for i, name in enumerate(os.listdir(folder_name)): os.rename(name,'test'+str(i)+'.jpg')手动修改半天,python只需两句话~~

-
根据规则重命名
结合前面的筛选条件,把之前的 if 条件下 加上 os.rename即可。
3.批量复制或移动
-
移动
shutil.move()import os import shutil path = os.walk("D:/test") # walk可以移动子目录 for root, dirs, files in path: for f in files: shutil.move(os.path.join(root, f), os.path.join( 'D:/movefile', f)) # 移动文件 -
复制
shutil.copy()import os import shutil source_file = 'D:/test' target_dir = 'D:/movefile' # 没有则创建目标文件夹 if not os.path.exists(target_dir): os.makedirs(target_dir) path = os.walk(source_file) for root, dirs, files in path: for f in files: # source_file:源路径文件, target_dir:目标路径文件 shutil.copy(os.path.join(root, f), os.path.join( 'D:/movefile', f))
4.批量保存
-
保存图片
opencv、pillow -
保存txt
-
保存到csv
-
保存数据库mysql
三、批量修改图片、视频
1.批量下载图片
timeout=10 为下载图片数量,输入关键词,利用百度图片接口下载。
关键词搜索百度图片并保存到本地
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import requests # http客户端
import re # 正则表达式模块
import random # 随机数
import os # 创建文件夹
def mkdir(path): # 创建文件夹
is_exists = os.path.exists(path)
if not is_exists:
print('创建名字叫做', path, '的文件夹')
os.makedirs(path)
print('创建成功!')
else:
print(path, '文件夹已经存在了,不再创建')
def getPic(html, keyword, path):
print("正在查找:" + keyword + ' 对应的图片,正在从百度图库重下载: ')
for addr in re.findall(str('"objURL":"(.*?)"'), html, re.S):
print("现在正在爬取的URL地址:" + addr)
try:
pics = requests.get(addr, timeout=10) #下载图片数量
except requests.exceptions.ConnectionError:
print("当前Url请求错误")
continue
# 假设产生的随机数不重复
fq = open(path + '//' + str(random.randrange(1000, 2000)) + '.jpg', 'w+b')
fq.write(pics.content)
fq.close()
print('写入完成')
if __name__ == "__main__":
word = input("请输入关键词:")
result = requests.get(
"http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=" + word)
# print(result.text)
print("写入完毕")
path = 'pic' # 保存图片文件夹名称
mkdir(path)
getPic(result.text, word, path)
2.批量压缩图片
出处:使用Python轻松批量压缩图片
png格式压缩效果较好,其中注意(int(w/2), int(h/2),如果不想压缩分辨率,可以修改。
from PIL import Image
import os
import shutil
# 图片压缩批处理
def compressImage(srcPath, dstPath):
for filename in os.listdir(srcPath):
# 如果不存在目的目录则创建一个,保持层级结构
if not os.path.exists(dstPath):
os.makedirs(dstPath)
# 拼接完整的文件或文件夹路径
srcFile = os.path.join(srcPath, filename)
dstFile = os.path.join(dstPath, filename)
# 如果是文件就处理
if os.path.isfile(srcFile):
try:
# 打开原图片缩小后保存,可以用if srcFile.endswith(".jpg")或者split,splitext等函数等针对特定文件压缩
sImg = Image.open(srcFile)
w, h = sImg.size
# 设置压缩尺寸和选项,注意尺寸要用括号
dImg = sImg.resize((int(w/2), int(h/2)), Image.ANTIALIAS)
# 也可以用srcFile原路径保存,或者更改后缀保存,save这个函数后面可以加压缩编码选项JPEG之类的
dImg.save(dstFile)
print(dstFile+" 成功!")
except Exception:
print(dstFile+"失败!")
# 如果是文件夹就递归
if os.path.isdir(srcFile):
compressImage(srcFile, dstFile)
if __name__ == '__main__':
# 遍历待加入图片
path = os.walk("D:/Data/img")
for root, dirs, files in path:
for f in files:
shutil.move(os.path.join(root, f), os.path.join(
'D:/Data/finish', f)) # 移动文件
# 遍历删除压缩图片
path = os.walk("D:/Data/compress")
for root, dirs, files in path:
for f in files:
os.remove(os.path.join(root, f))
# 遍历压缩图片
compressImage("D:/Data/finish",
"D:/Data/compress")
img:原图、compress:缩略图、finish:原图
3.批量压缩视频
视频压缩,需要安装ffmpeg并把安装目录的bin路径添加到环境变量。
使用时cmd进入mp4所在位置的目录即可,压缩且不破坏分辨率使用:
ffmpeg -i 1.mp4 -b:v 2000k 1_ffmpeg.mp4
去掉音频
ffmpeg -i 1.mp4 -vcodec copy -an 2.mp4
批量处理需要写一个bat:
参考:[视频转换]python+ffmpeg批量转换一个目录里的所有视频–路人乙小明
import os
from os import path
wdr = path.normpath(r'D:/myworkspace/dataset/video')
videoList = os.listdir(wdr)
#获取文件夹下所有文件列表
"""
压缩:
ffmpeg -i 1.mp4 -b:v 2000k 1_ffmpeg.mp4
去掉声音:
ffmpeg -i 1.mp4 -vcodec copy -an 2.mp4
"""
ffmpegCmd = 'ffmpeg -i {} -b:v 2000k {}_conv.mp4 '
#设置ffmpeg命令模板
cmd = f'cd "{wdr}"\n{path.splitdrive(wdr)[0]}\npause\n'
#第1步,进入目标文件夹
def comprehensionCmd(e):
#手写一个小函数方便后面更新命令
root,ext = path.splitext(e)
return ffmpegCmd.format(e,root)
videoList = [comprehensionCmd(e) for e in videoList if not('conv' in e)]
#第3和第4步
cmd += '\n'.join(videoList)
# 将各个ffmpeg命令一行放一个
cmd += '\npause'
output = open('videoConv.bat','w')
output.write(cmd)
output.close()
#命令写入文件
![]() bat是可执行文件:
bat是可执行文件:

运行效果就是:进入目录,确认执行,就可以批量处理啦!
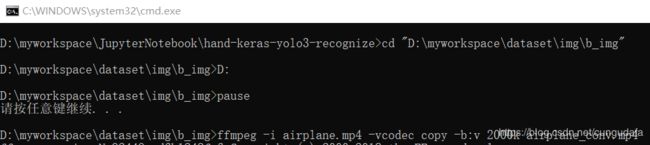
美滋滋~
如果想要批量移动到一个文件夹就用到前面的积累:
import os
import shutil
import re
path = os.walk("D:/myworkspace/dataset/img/b_img") # walk可以移动子目录
for root, dirs, files in path:
for f in files:
if 'conv' in f:
print(f)
shutil.copy(os.path.join(root, f), os.path.join(
'D:/myworkspace/dataset/img/compress', f)) # move移动文件,copy复制文件
# 重命名
folder_name = 'D:/myworkspace/dataset/img/compress'
for i, name in enumerate(os.listdir(folder_name)):
e = re.findall("(.*)_.*", name)
os.rename(os.path.join(folder_name, name),os.path.join(folder_name, str(e[0])+'.mp4'))
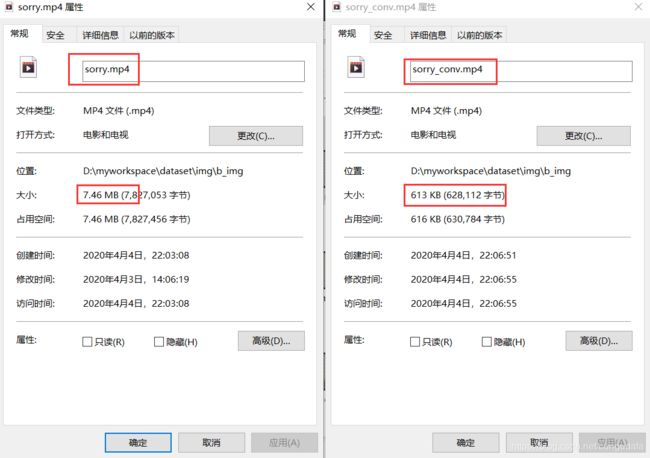
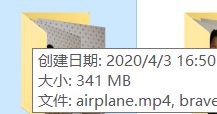
压缩前341M,压缩后18.6M:

当然去掉声音也是这样,修改python中:
ffmpegCmd = 'ffmpeg -i {} -b:v 2000k {}_conv.mp4 '改为:
ffmpegCmd = 'ffmpeg -i {} -vcodec copy -an {}_conv.mp4
批量美滋滋!
ffmpeg用法参考:
- 视频压缩–快速压缩方法
- ffmpeg 常用命令总结:(avi转MP4、MP4转ts、视频压缩、去除视频声音、合并音频和视频)