全国行政区划代码到行政村_行政任务
全国行政区划代码到行政村
在你开始前
了解这些教程可以教给您什么以及如何从中获得最大收益。
关于本系列
Linux Professional Institute (LPI)在三个级别上对Linux系统管理员进行认证: 初级 (也称为“认证级别1”), 中级 (也称为“认证级别2”)和高级 (也称为“认证级别3”) )。 要获得1级认证,您必须通过101和102考试; 要获得2级认证,您必须通过201和202考试。要达到3级认证,您必须具有有效的中级认证并通过301考试(“核心”)。 您还可以通过其他高级专业考试。
developerWorks提供了教程,以帮助您准备四个初级和中级认证考试。 每个考试涵盖几个主题,并且每个主题在developerWorks上都有一个相应的自学教程。 对于LPI 102考试,这9个主题和相应的developerWorks教程为:
| LPI 102考试主题 | developerWorks教程 | 教程总结 |
|---|---|---|
| 主题105 | LPI 102考试准备: 核心 |
了解如何安装和维护Linux内核和内核模块。 |
| 主题106 | LPI 102考试准备: 引导,初始化,关闭和运行级别 |
了解如何引导系统,设置内核参数以及关闭或重新引导系统。 请参考“ 学习Linux,101:LPIC-1的路线图 ”。 |
| 主题107 | LPI 102考试准备: 列印 |
了解如何在Linux系统上管理打印机,打印队列和用户打印作业。 |
| 主题108 | LPI 102考试准备: 文献资料 |
了解如何使用和管理本地文档,在Internet上查找文档以及使用自动登录消息将系统事件通知用户。 |
| 主题109 | LPI 102考试准备: Shell,脚本,编程和编译 |
了解如何定制shell环境以满足用户需求,为常用的命令序列编写Bash函数,编写简单的新脚本,使用shell语法进行循环和测试以及定制现有脚本。 |
| 主题111 | LPI 102考试准备: 行政任务 |
(本教程。)了解如何管理用户帐户和组帐户以及调整用户和系统环境,配置和使用系统日志文件,通过安排作业在其他时间运行来自动执行系统管理任务,备份系统以及维护系统时间。 请参阅下面的详细目标 。 |
| 主题112 | LPI 102考试准备: 网络基础 |
快来了。 |
| 主题113 | LPI 102考试准备: 网络服务 |
快来了。 |
| 主题114 | LPI 102考试准备: 安全 |
快来了。 |
要通过考试101和102(并达到1级认证),您应该能够:
- 在Linux命令行上工作
- 执行简单的维护任务:帮助用户,将用户添加到更大的系统,备份和还原以及关闭和重新启动
- 安装和配置工作站(包括X)并将其连接到LAN,或通过调制解调器将独立PC连接到Internet
要继续准备1级认证,请参阅有关LPI考试101和102的developerWorks教程 ,以及整套developerWorks LPI教程 。
Linux Professional Institute不特别认可任何第三方考试准备材料或技术。 有关详细信息,请联系[email protected] 。
关于本教程
欢迎使用“管理任务”,这是为您准备LPI 102考试而设计的九个教程中的第六个。在本教程中,您将学习如何管理用户和组,设置用户配置文件和环境,使用日志文件,安排作业,备份您的数据,并维持系统时间。
本教程根据该主题的LPI目标进行组织。 粗略地说,对于体重较高的目标,应在考试中提出更多问题。
| LPI考试目标 | 客观体重 | 客观总结 |
|---|---|---|
| 1.111.1 用户和组帐户 |
重量4 | 添加,删除,暂停和更改用户帐户。 在密码和组数据库(包括影子数据库)中管理用户和组信息。 创建和管理特殊用途和受限帐户。 |
| 1.111.2 调整用户和系统环境 |
重量3 | 修改全局和用户配置文件。 设置环境变量并维护新用户帐户的框架目录。 设置命令搜索路径。 |
| 1.111.3 配置和使用系统日志文件以满足管理和安全需求 |
重量3 | 配置和管理系统日志,包括日志信息的类型和级别。 扫描和监视日志文件以进行值得注意的活动,并跟踪发现的问题。 旋转和存档日志文件。 |
| 1.111.4 通过安排将来运行的作业来自动执行系统管理任务 |
重量4 | 使用cron或anacron命令定期运行作业,并使用at命令在特定时间运行作业。 |
| 1.111.5 维持有效的数据备份策略 |
重量3 | 规划备份策略,并将文件系统自动备份到各种介质。 |
| 1.111.6 维持系统时间 |
重量4 | 维护系统时间和时区,并通过NTP同步时钟。 将BIOS时钟设置为UTC的正确时间,并配置NTP,包括校正时钟漂移。 |
先决条件
为了从本教程中获得最大收益,您应该具有Linux的基本知识以及可以在其中实践本教程中介绍的命令的Linux系统。
本教程建立在LPI系列以前的教程中介绍的内容的基础上,因此您可能需要首先查看101考试的教程 。 在“ 学习Linux,101:LPIC-1的路线图 ”系列中,有些已经迁移到我们的新格式。 特别是,您应该完全熟悉“ 考试101-主题104:设备,Linux文件系统,文件系统层次结构标准 ”中的内容,其中涵盖了用户,组和文件权限的基本概念。
程序的不同版本可能会不同地格式化输出,因此您的结果可能看起来与本教程中的清单和图不完全相同。
用户和组帐户
本部分介绍了初级管理(LPIC-1)考试102的主题1.111.1的材料。该主题的权重为4。
在本节中,学习如何:
- 添加,修改和删除用户和组
- 暂停和更改用户帐户
- 管理密码数据库和组数据库中的用户和组信息
- 使用正确的工具来管理影子密码数据库和组数据库
- 创建和管理有限和专用帐户
正如您在“ 考试101-主题104:设备,Linux文件系统,文件系统层次结构标准 ”中了解的那样,Linux是一个多用户系统,其中每个用户都属于一个主要组,并且可能属于其他组。 Linux中文件的所有权与用户ID和组密切相关。 回想一下,您可以使用su或sudo -s命令以一个用户身份登录并成为另一个用户,并且可以使用whoami命令检查您当前的有效ID,然后使用groups命令来查找属于哪个组。 在本节中,您将学习如何创建,删除和管理用户和组。 您还将了解/ etc中存储用户和组信息的文件。
添加和删除用户和组
使用useradd命令将用户添加到Linux系统,然后使用userdel命令删除用户。 同样,您可以使用groupadd和groupdel命令添加或删除组。
添加用户或组
现代Linux桌面通常具有用于用户和组管理的图形界面。 通常通过菜单选项访问图形界面,以进行系统管理。 这些接口确实有很大的不同,所以您系统上的接口可能看起来不像这里的示例,但是底层的概念和命令仍然相似。
首先,以图形方式将用户添加到Fedora Core 5系统,然后检查基础命令。 对于带有GNOME桌面的Fedora Core 5,请使用“ 系统”>“管理”>“用户和组” ,然后单击“ 添加用户”按钮。
图1描绘了“用户管理器”面板,其中的“创建新用户”面板显示了名为“ john”的新用户的基本信息。 输入了用户的全名John Doe和密码。 该面板提供了默认的登录外壳程序/ bin / bash。 在Fedora系统上,默认设置是创建一个与用户同名的新组,本例中为'john',主目录为/ home / john。
图1.添加一个用户

清单1显示了使用id命令显示有关新用户的基本信息。 如您所见,john的用户号为503,而匹配的组john的组号为503。这是john所属的唯一组。
清单1.显示用户标识信息
[root@pinguino ~]# id john
uid=503(john) gid=503(john) groups=503(john) 要从命令行完成相同的任务,请使用groupadd和useradd命令创建组和用户,然后使用passwd命令设置新创建的用户的密码。 所有这些命令都需要root权限。 清单2说明了这些命令添加另一个用户jane的基本用法。
清单2.添加用户简
[root@pinguino ~]# groupadd jane
[root@pinguino ~]# useradd -c "Jane Doe" -g jane -m jane
[root@pinguino ~]# passwd jane
Changing password for user jane.
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
[root@pinguino ~]# id jane
uid=504(jane) gid=504(jane) groups=504(jane)
[root@pinguino ~]# ls -ld /home/jane
drwx------ 3 jane jane 4096 Jun 25 18:22 /home/jane 在这两个示例中,用户ID和组ID的值均大于500。请注意,某些较新的系统将用户ID的起始值设为1000,而不是500。这些值通常表示普通用户,而值则小于500(如果小于,则为1000。系统开始于1000普通用户)保留给系统用户 。 系统用户将在本节后面介绍。 实际的截止点在/etc/login.defs中设置为UID_MIN和GID_MIN 。
在上面的清单2中, groupadd命令具有单个参数jane ,这是要添加的组的名称。 组名必须以小写字母或下划线开头,并且通常仅包含这些字符以及连字符或破折号。 您可以指定的选项显示在表3中。
| 选项 | 目的 |
|---|---|
| -F | 如果该组已经存在,则以成功状态退出。 当您无需在尝试创建组之前检查组是否存在时,这对于编写脚本非常方便。 |
| -G | 手动指定组ID。 默认设置是使用至少GID_MIN且也大于任何现有组ID的GID_MIN 。 组ID通常是唯一的,并且必须为非负数 |
| -o | 允许组具有非唯一ID。 |
| -K | 可用于覆盖/etc/login.defs中的默认值。 |
在上面的清单2中, useradd命令具有一个参数jane ,要添加的用户名以及-c , -g和-m选项。 表4显示了useradd命令的常用选项。
| 选项 | 目的 |
|---|---|
| -b --base-dir |
在其中创建用户主目录的默认基本目录。 通常是/ home,用户的主目录是/ home / $ USER。 |
| -C - 评论 |
描述id的文本字符串,例如用户的全名。 |
| -d - 家 |
提供主目录的特定目录名称。 |
| -e - 到期日期 |
帐户到期或被停用的日期,格式为YYYY-MM_DD。 |
| -G --gid |
用户的初始登录组的名称或编号。 该组必须存在,这就是为什么在清单2中的用户jane之前创建组jane的原因。 |
| -G -组 |
用户所属的其他组的逗号分隔列表。 |
| -K | 可用于覆盖/etc/login.defs中的默认值。 |
| -米 -创建首页 |
如果用户的主目录不存在,则创建它。 将框架文件和任何目录从/ etc / skel复制到主目录。 |
| -o -非唯一 |
允许用户使用非唯一ID。 |
| -p - 密码 |
加密的密码。 如果未指定密码,则默认为禁用该帐户。 通常,您将在后续步骤中使用passwd命令,而不是生成加密的密码并在useradd命令上指定它。 |
| -s - 贝壳 |
用户登录外壳程序的名称(如果与默认登录外壳程序不同)。 |
| -u --uid |
非负数字用户标识,如果未指定-o ,则必须唯一。 默认设置是使用至少UID_MIN且也大于任何现有用户ID的最小值。 |
笔记:
- 某些系统(包括Fedora和Red Hat发行版)对用户创建命令进行了扩展。 例如,Fedora和Red Hat的默认行为是为用户创建一个新组,并且
-n选项可用于useradd命令以禁用此功能。 请注意可能存在的系统差异,如有疑问,请参考系统上的手册页。 - 在SUSE系统上,使用YaST或YaST2访问图形用户和组管理界面。
- 图形界面可以执行其他任务,例如在/ var / spool / mail中创建用户的邮件文件。
删除用户或组
删除用户或组要比添加用户或组简单得多,因为选项较少。 实际上,删除组的groupdel命令只需要组名; 它没有选择。 您不能删除作为用户主要组的任何组。 如果使用图形界面删除用户和组,则功能与此处显示的命令非常相似。
使用userdel命令删除用户。 -r或--remove选项请求删除用户的主目录及其包含的所有内容以及用户的邮件后台处理程序。 删除用户时,如果在/etc/login.defs中将USERGROUPS_ENAB设置为yes,则与该用户同名的组也将被删除,但这仅在该组不是另一个用户的主要组时才执行。
在清单3中,您看到一个示例,当多个用户共享同一主要组时,删除组。 在此,先前已将另一个用户jane2与jane具有相同的组添加到系统中。
清单3.删除用户和组
root@pinguino:~# groupdel jane
groupdel: cannot remove user's primary group.
root@pinguino:~# userdel -r jane
userdel: Cannot remove group jane which is a primary group for another user.
root@pinguino:~# userdel -r jane2
root@pinguino:~# groupdel jane笔记:
- 有一个
userdel选项-f或--force,可用于删除用户及其组。 此选项很危险,因此您只能将其用作最后的选择。 在开始之前,请仔细阅读手册页。 - 请注意,如果删除用户或组,并且文件系统上存在属于该用户或组的文件,则不会自动删除文件或将文件分配给其他用户或组。
暂停和更改帐户
现在您可以创建或删除用户ID或组,您可能还需要修改一个ID。
修改用户帐号
假设用户john希望将tcsh shell作为其默认值。 通常,从图形界面中,您将找到一种编辑用户(或组)或检查对象属性的方法。 图2显示了我们先前在Fedora Core 5系统上创建的用户john的属性对话框。
图2.修改用户帐户

在命令行中,可以使用usermod命令来修改用户帐户。 您可以使用与useradd一起使用的大多数选项,但不能为用户创建或填充新的主目录。 如果需要更改用户名,请使用新名称指定-l或--login选项。 您可能需要重命名主目录以匹配用户ID。 您可能还需要重命名其他项目,例如邮件假脱机文件。 最后,如果更改了登录外壳,则可能需要更改某些关联的配置文件。 清单4显示了将用户john更改为john2并使用/ bin / tcsh作为默认外壳并重命名主目录/ home / john2时可能需要执行的操作的示例。
清单4.修改用户
[root@pinguino ~]# usermod -l john2 -s /bin/tcsh -d /home/john2 john
[root@pinguino ~]# ls -d ~john2
ls: /home/john2: No such file or directory
[root@pinguino ~]# mv /home/john /home/john2
[root@pinguino ~]# ls -d ~john2
/home/john2笔记:
- 如果需要修改用户的其他组,则必须指定其他组的完整列表。 没有命令可以简单地为用户添加或删除单个组。
- 在更改已登录用户或正在运行进程的用户的名称或ID上有限制。 检查手册页以获取详细信息。
- 如果更改用户号,则可能需要更改该用户拥有的文件和目录以匹配新的号码。
修改组
毫不奇怪, groupmod命令用于修改组信息。 您可以使用-g选项更改组号,并使用-n选项更改名称。
清单5.重命名组
[root@pinguino ~]# ls -ld ~john2
drwx------ 3 john2 john 4096 Jun 26 18:29 /home/john2
[root@pinguino ~]# groupmod -n john2 john
[root@pinguino ~]# ls -ld ~john2
drwx------ 3 john2 john2 4096 Jun 26 18:29 /home/john2 注意,在清单5中,当我们使用groupmod更改组名时,john2主目录的组名发生了神奇的变化。 你惊喜吗? 因为组在文件系统inode中是通过编号而不是名称来表示的,所以这并不奇怪。 但是,如果更改组的编号,则应更新该组为主要组的所有用户,并且您可能还希望更新属于该组的文件和目录以匹配新编号(采用与上述相同的方法)以上用于更改用户号码)。 清单6显示了如何将john2的组号更改为505,更新用户帐户以及对/ home文件系统中所有受影响的文件进行适当的更改。 如果可能的话,您可能希望重新编号用户和组。
清单6.重新编号组
[root@pinguino ~]# groupmod -g 505 john2
[root@pinguino ~]# ls -ld ~john2
drwx------ 3 john2 503 4096 Jun 26 18:29 /home/john2
[root@pinguino ~]# id john2
uid=503(john2) gid=503 groups=503
[root@pinguino ~]# usermod -g john2 john2
[root@pinguino ~]# id john2
uid=503(john2) gid=505(john2) groups=505(john2)
[root@pinguino ~]# ls -ld ~john2
drwx------ 3 john2 503 4096 Jun 26 18:29 /home/john2
[root@pinguino ~]# find /home -gid 503 -exec chgrp john2 {} \;
[root@pinguino ~]# ls -ld ~john2
drwx------ 3 john2 john2 4096 Jun 26 18:29 /home/john2用户和组密码
您已经看到了passwd命令,该命令用于更改用户密码。 密码对用户是唯一的(或应该是),并且可以由用户更改。 正如我们已经看到的那样,root用户可以更改任何用户的密码。
组也可能具有密码,并且使用gpasswd命令设置它们。 拥有组密码后,如果用户知道组密码,则可以使用newgrp命令临时加入组。 当然,让多个人知道密码有些问题,因此您必须权衡使用usermod将用户添加到组中的优点,而不是让太多人知道组密码的安全性问题。
暂停或锁定帐户
如果需要阻止用户登录,则可以使用usermod命令的-L选项暂停或锁定帐户。 要解锁该帐户,请使用-U选项。 清单7显示了如何锁定帐户john2以及如果john2尝试登录系统会发生什么。 请注意,当john2帐户被解锁时,将恢复相同的密码。
清单7.锁定帐户
[root@pinguino ~]# usermod -L john2
[root@pinguino ~]# ssh john2@pinguino
john2@pinguino's password:
Permission denied, please try again. 您可能已经在图2中注意到,对话框上有几个带有其他用户属性的选项卡。 我们简要提到过使用passwd命令设置用户密码,但是它和usermod命令都可以执行许多与用户帐户有关的任务,而另一个命令chage命令也可以。 表5中显示了其中一些选项。有关这些选项和其他选项的更多详细信息,请参见相应的手册页。
| 命令选项 | 目的 | ||
|---|---|---|---|
| 用户模组 | 密码 | 诗句 | |
| -L | -l | 不适用 | 锁定或暂停帐户。 |
| -U | -u | 不适用 | 解锁帐户。 |
| 不适用 | -d | 不适用 | 通过将其设置为无密码来禁用该帐户。 |
| -e | -F | -E | 设置帐户的到期日期。 |
| 不适用 | -n | -米 | 密码的最小生存期(天)。 |
| 不适用 | -X | -M | 最大密码有效期(天)。 |
| 不适用 | -w | -W | 必须更改密码之前的警告天数。 |
| -F | -一世 | -一世 | 密码过期后直到禁用帐户为止的天数。 |
| 不适用 | -S | -l | 输出有关当前帐户状态的短消息。 |
管理用户和组数据库
用户和组信息的主要存储库是/ etc中的四个文件。
- / etc / passwd
- 是包含有关用户基本信息的密码文件
- / etc / shadow
- 是包含加密密码的影子密码文件
- / etc / group
- 是包含有关组及其基本用户的基本信息的组文件
- / etc / gshadow
- 是包含加密的组密码的影子组文件
这些文件将通过您在本教程中已经看到的命令进行更新,并且在我们讨论文件本身之后,您还会遇到更多使用它们的命令。 所有这些文件都是纯文本文件。 通常,您不应该直接编辑它们。 使用提供的工具进行更新,以使其正确锁定并保持同步。
您会注意到passwd和group文件都被遮盖了 。 这是出于安全原因。 passwd和group文件本身必须是世界可读的,但是加密的密码应该不是世界可读的。 因此,影子文件包含加密的密码,并且这些文件只能由root用户读取。 必需的身份验证访问由具有root权限的suid程序提供,但任何人都可以运行。 确保您的系统具有适当设置的权限。 清单8显示了一个示例。
清单8.用户和组数据库权限
[ian@pinguino ~]$ ls -l /etc/passwd /etc/shadow /etc/group /etc/gshadow
-rw-r--r-- 1 root root 701 Jun 26 19:04 /etc/group
-r-------- 1 root root 580 Jun 26 19:04 /etc/gshadow
-rw-r--r-- 1 root root 1939 Jun 26 19:43 /etc/passwd
-r-------- 1 root root 1324 Jun 26 19:50 /etc/shadow注意:尽管从技术上讲,仍然可以在没有阴影的密码和组文件的情况下运行,但这几乎从未完成,因此不建议这样做。
/ etc / passwd文件
/ etc / passwd文件为系统中的每个用户包含一行。 清单9显示了一些示例行。
清单9. / etc / password条目
root:x:0:0:root:/root:/bin/bash
jane:x:504:504:Jane Doe:/home/jane:/bin/bash
john2:x:503:505:John Doe:/home/john2:/bin/tcsh每行包含七个用冒号(:)分隔的字段,如表6所示。
| 领域 | 目的 |
|---|---|
| 用户名 | 登录系统的名称。 例如,john2。 |
| 密码 | 加密的密码。 使用影子密码时,它包含单个x字符。 |
| 用户身份 (UID) |
在系统中用来表示此用户名的数字。 例如,用户john2的503。 |
| 群组编号 (GID) |
用于代表系统中该用户的主要组的数字。 例如,用户john2的505。 |
| 评论 (GECOS) |
用于描述用户的可选字段。 例如,“ John Doe”。 该字段可能包含多个逗号分隔的条目。 它也被诸如finger的程序使用。 GECOS名称具有历史意义。 请参见man 5 passwd详细信息。 |
| 家 | 用户主目录的绝对路径。 例如,/ home / john2 |
| 贝壳 | 当用户登录系统时,该程序会自动启动。 这通常是交互式外壳程序,例如/ bin / bash或/ bin / tcsh,但可以是任何程序,不一定是交互式外壳程序。 |
/ etc / group文件
/ etc / group文件包含系统中每个组的一行。 清单10中显示了一些示例行。
清单10. / etc / group条目
root:x:0:root
jane:x:504:john2
john2:x:505:每行包含四个用冒号(:)分隔的字段,如表7所示。
| 领域 | 目的 |
|---|---|
| 团队名字 | 该组的名称。 例如,john2。 |
| 密码 | 加密的密码。 使用影子组密码时,它包含单个x字符。 |
| 群组编号 (GID) |
在系统中用来表示该组的数字。 例如,组john2的505。 |
| 会员 | 以逗号分隔的组成员列表,但此成员是主要组的成员除外。 |
影子文件
/ etc / shadow文件只能由root读取。 它包含加密的密码以及密码和帐户到期信息。 有关字段布局的信息,请参见手册页( man 5 shadow )。 密码可以使用DES加密,但更常见的是使用MD5加密。 DES算法使用用户密码的前8个字符的低7位作为56位密钥,而MD5算法使用整个密码。 在任一情况下,密码盐腌使得两个其他方面相同的密码不生成相同的加密值。 清单11显示了如何为用户jane和john2设置相同的密码,然后在/ etc / shadow中显示了生成的编码MD5密码。
清单11. / etc / shadow中的密码
[root@pinguino ~]# echo lpic1111 |passwd jane --stdin
Changing password for user jane.
passwd: all authentication tokens updated successfully.
[root@pinguino ~]# echo lpic1111 |passwd john2 --stdin
Changing password for user john2.
passwd: all authentication tokens updated successfully.
[root@pinguino ~]# grep "^j" /etc/shadow
jane:$1$eG0/KGQY$ZJl.ltYtVw0sv.C5OrqUu/:13691:0:99999:7:::
john2:$1$grkxo6ie$J2muvoTpwo3dZAYYTDYNu.:13691:0:180:7:29:: 前导$1$表示MD5密码,而salt是可变长度字段,最多8个字符,以下一个$符号结尾。 加密的密码是剩余的22个字符的字符串。
用户和组的工具
您已经看到了一些操作帐户和组文件及其阴影的命令。 在这里您将了解:
- 组管理员
- 编辑密码和组文件的命令
- 转换程序
组管理员
在某些情况下,您可能希望除root用户以外的其他用户能够通过添加或删除组成员来管理一个或多个组。 清单12显示了root用户如何将用户jane添加为组john2的管理员,然后jane又可以将用户ian添加为成员。
清单12.添加组管理员和成员
[root@pinguino ~]# gpasswd -A jane john2
[root@pinguino ~]# su - jane
[jane@pinguino ~]$ gpasswd -a ian john2
Adding user ian to group john2
[jane@pinguino ~]$ id ian;id jane
uid=500(ian) gid=500(ian) groups=500(ian),505(john2)
uid=504(jane) gid=504(jane) groups=504(jane)您可能会惊讶地注意到,尽管jane是john2组的管理员,但她不是该组的成员。 对/ etc / gshadow的结构进行检查即可了解原因。 / etc / gshadow文件的每个条目包含四个字段,如表8所示。请注意,第三个字段是该组的管理员的逗号分隔列表。
| 领域 | 目的 |
|---|---|
| 团队名字 | 该组的名称。 例如,john2。 |
| 密码 | 如果该组具有密码,则该字段用于包含加密密码。 如果没有密码,您可能会看到“ x”,“!” 要么 '!!' 这里。 |
| 管理员 | 以逗号分隔的组管理员列表。 |
| 会员 | 以逗号分隔的组成员列表。 |
如您所见,管理员列表和成员列表是两个不同的字段。 gpasswd的-A选项允许root用户将管理员添加到组,而-M选项允许root用户添加成员。 -a (注意小写)选项允许管理员添加成员,而-d选项允许管理员删除成员。 其他选项允许删除组密码。 有关详细信息,请参见手册页。
编辑密码和组文件的命令
尽管未在LPI目标中列出,但您还应该注意用于安全编辑/ etc / passwd的vipw命令和用于安全编辑/ etc / group的vigr 。 使用vi编辑器进行更改时,这些命令将锁定必要的文件。 如果对/ etc / passwd进行更改,则vipw将提示您是否还需要更新/ etc / shadow。 同样,如果使用vigr更新/ etc / group,将提示您更新/ etc / gshadow。 如果您需要删除组管理员,您可能需要使用vigr ,因为gpasswd只允许此外管理员。
转换程序
LPI目标中也未列出其他四个相关命令。 它们是pwconv , pwunconv , grpconv和grpunconv 。 它们用于在带阴影的和非带阴影的密码和组文件之间进行转换。 您可能永远不需要这些,但要意识到它们的存在。 有关详细信息,请参见手册页。
专用帐户
按照惯例,系统用户的ID通常小于100,根的ID为0。普通用户从UID_MIN设置的UID_MIN值开始自动编号,该值通常设置为500或1000。
除了常规用户帐户和系统上的root帐户外,您通常还会有几个特殊用途的帐户,用于守护程序,例如FTP,SSH,邮件,新闻等。 清单13显示了/ etc / passwd中的一些条目。
清单13.有限和专用帐户
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
news:x:9:13:news:/etc/news:
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
apache:x:48:48:Apache:/var/www:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin此类帐户经常控制文件,但不能通过常规登录访问。 因此,它们通常具有指定为/ sbin / nologin或/ bin / false的登录shell,因此登录尝试将失败。
环境调整
本部分介绍了初中级管理(LPIC-1)考试102的主题1.111.2的材料。该主题的权重为3。
在本节中,学习如何调整用户环境,包括以下任务:
- 设置和取消设置环境变量
- 维护新用户帐户的框架目录
- 设置命令搜索路径
设置和取消设置环境变量
创建新用户时,通常会根据本地需求初始化许多变量。 这些通常是在您为新用户提供的概要文件中设置的,例如.bash_profile和.bashrc,或者在系统范围的概要文件/ etc / profile和/ etc / bashrc中进行设置。 清单14显示了如何在Ubuntu 7.04系统上的/ etc / profile中设置PS1系统提示的示例。 第一个if语句检查PS1变量是否已设置(指示交互式外壳程序),因为非交互式外壳程序不需要提示。 第二条if语句检查是否设置了BASH环境变量。 如果是这样,它将设置一个复杂的提示符并显示/etc/bash.bashrc的来源(请注意点)。 如果未设置BASH变量,则检查root(id = 0),然后将提示相应地设置为#或$。
清单14.设置环境变量
if [ "$PS1" ]; then
if [ "$BASH" ]; then
PS1='\u@\h:\w\$ '
if [ -f /etc/bash.bashrc ]; then
. /etc/bash.bashrc
fi
else
if [ "`id -u`" -eq 0 ]; then
PS1='# '
else
PS1='$ '
fi
fi
fiLPI 102考试准备教程:Shell,脚本,编程和编译具有有关用于设置和取消设置环境变量的命令的详细信息,以及有关如何以及何时使用各种配置文件的信息。
为用户自定义环境时,请注意两点:
- / etc / profile在登录时是只读的,因此在创建每个新的shell时都不会执行。
- 函数和别名不会被新的shell继承。 因此,通常将在/ etc / bashrc或用户自己的配置文件中设置这些变量和环境变量。
除了系统概要文件/ etc / profile和/ etc / bashrc之外,Linux标准库(LSB)还指定可以将其他脚本放置在目录/etc/profile.d中。 这些脚本是在创建交互式登录外壳时提供的。 它们提供了一种方便的方式来分离针对不同程序的自定义。 清单15显示了一个示例。
清单15. Fedora 7上的/etc/profile.d/vim.sh
[if [ -n "$BASH_VERSION" -o -n "$KSH_VERSION" -o -n "$ZSH_VERSION" ]; then
[ -x //usr/bin/id ] || return
[ `//usr/bin/id -u` -le 100 ] && return
# for bash and zsh, only if no alias is already set
alias vi >/dev/null 2>&1 || alias vi=vim
fi 请记住,通常应该export在配置文件中设置的所有变量。 否则,它们将不适用于在新Shell中运行的命令。
为新用户维护框架目录
您在“ 添加和删除用户和组 ”一节中了解到,可以为用户创建或填充新的主目录。 这个新目录的源是根于/ etc / skel的子树。 清单16显示了Fedora 7系统的该子树中的文件。 请注意,大多数文件都以点(点)开头,因此您需要使用-a选项列出它们。 -R选项以递归方式列出子目录, -L选项跟随任何符号链接。
清单16. Fedora 7上的/ etc / skel
[ian@lyrebird ~]$ ls -aRL /etc/skel
/etc/skel:
. .. .bash_logout .bash_profile .bashrc .emacs .xemacs
/etc/skel/.xemacs:
. .. init.el除了Bash shell可能需要的.bash_logout,.bash_profile和.bashrc之外,请注意,此示例还包含emacs和xemacs编辑器的配置文件信息。 如果需要查看各种配置文件的功能,请参阅LPI 102考试准备课程:Shell,脚本,编程和编译 。
清单17显示了上述系统中的/etc/skel/.bashrc。 此文件在不同的发行版或不同的发行版上可能会有所不同,但是它使您了解如何完成默认用户设置。
清单17. Fedora 7上的/etc/skel/.bashrc
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific aliases and functions如您所见,全局/ etc / bashrc是源代码,然后可以添加任何用户特定的指令。 清单18显示了/ etc / bashrc的一部分,来自/etc/profile.d的.sh脚本来自该部分。
清单18.从/etc/profile.d获取.sh脚本
for i in /etc/profile.d/*.sh; do
if [ -r "$i" ]; then
. $i
fi
done
unset i请注意,变量i在循环后未设置。
设置命令搜索路径
您的默认配置文件通常包括本地功能或您可能已安装的产品的PATH变量。 您可以在/ etc / skel的框架文件中设置这些文件,修改/ etc / profile,/ etc / bashrc,或者在系统使用的情况下在/etc/profile.d中创建文件。 如果您确实修改了系统文件,请确保在任何系统更新后检查您的更改是否完整。 清单19显示了如何在现有PATH的前面或后面添加新目录/ opt / productxyz / bin。
清单19.添加路径目录
PATH="$PATH${PATH:+:}/opt/productxyz/bin"
PATH="/opt/productxyz/bin${PATH:+:}$PATH" 尽管不是严格要求,但是表达式${PATH:+:}仅在PATH变量未设置或为null时才插入路径分隔符(冒号)。
系统日志文件
本部分介绍了初级管理(LPIC-1)考试102的主题1.111.3的材料。该主题的权重为3。
在本节中,学习如何配置和管理系统日志,包括以下任务:
- 管理记录的信息的类型和级别
- 自动旋转和存档日志文件
- 扫描日志文件以进行重要活动
- 监视日志文件
- 跟踪日志文件中报告的问题
管理记录的信息的类型和级别
Linux系统上的系统日志记录工具提供系统日志记录和内核消息陷阱。 日志记录可以在本地系统上完成,也可以发送到远程系统,并且可以通过/etc/syslog.conf配置文件很好地控制日志记录的级别。 日志由syslogd守护进程执行,该守护进程通常通过/ dev / log套接字接收输入,如清单20所示。
清单20. / dev / log是一个套接字
ian@pinguino:~$ ls -l /dev/log
srw-rw-rw- 1 root root 0 2007-07-05 15:42 /dev/log对于本地日志记录,主文件通常是/ var / log / messages,但是大多数安装中使用了许多其他文件,您可以广泛地自定义这些文件。 例如,您可能想要一个单独的日志来记录来自邮件系统的消息。
syslog.conf配置文件
syslog.conf文件是syslogd守护程序的主要配置文件。 日志基于功能和优先级的组合。 定义的功能包括auth(或安全性),authpriv,cron,daemon,ftp,kern,lpr,mail,mark,news,syslog,user,uucp和local0到local7。 应该使用关键字auth而不是security ,关键字mark仅供内部使用。
优先级(升序)为:
- 调试
- 信息
- 注意
- 警告(或警告)
- 错误(或错误)
- 暴击
- 警报
- 紧急(或恐慌)
现在不建议使用带括号的关键字(警告,错误和紧急)。
syslog.conf中的条目指定日志记录规则。 每个规则都有一个选择器字段和一个操作字段,它们由一个或多个空格或制表符分隔。 选择器字段标识该规则适用的设施和优先级,而操作字段标识该设施和优先级的日志记录操作。 尽管可以将日志记录限制为特定级别,但是默认行为是对指定级别和所有更高级别执行操作。 每个选择器都包括一个功能和一个由句点(点)分隔的优先级。 可以通过用逗号分隔指定给定动作的多种功能。 可以通过使用分号将给定操作的多个设施/优先级对分开来指定它们。 清单21显示了一个简单的syslog.conf的示例。
清单21. syslog.conf示例
# Log all kernel messages to the console.
# Logging much else clutters up the screen.
#kern.* /dev/console
# Log anything (except mail) of level info or higher.
# Don't log private authentication messages!
*.info;mail.none;authpriv.none;cron.none /var/log/messages
# The authpriv file has restricted access.
authpriv.* /var/log/secure
# Log all the mail messages in one place.
mail.* -/var/log/maillog
# Log cron stuff
cron.* /var/log/cron
# Everybody gets emergency messages
*.emerg *
# Save news errors of level crit and higher in a special file.
uucp,news.crit /var/log/spooler
# Save boot messages also to boot.log
local7.* /var/log/boot.log笔记:
- 与许多配置文件一样,将忽略以#开头的行和空白行。
- *可以用来表示所有设施或所有优先级。
- The special priority keyword
noneindicates that no logging for this facility should be done with this action. - The hyphen before a file name (such as -/var/log/maillog, in this example) indicates that the log file should not be synchronized after every write. You might lose information after a system crash, but you might gain performance by doing this.
The actions are generically referred to as "logfiles," although they do not have to be real files. Table 9 describe the possible logfiles.
| 行动 | 目的 |
|---|---|
| Regular File | Specify the full pathname, beginning with a slash (/). Prefix it with a hyphen (-) to omit syncing the file after each log entry. This may cause information loss if a crash occurs, but may improve performance. |
| Named Pipes | A fifo or named pipe can be used as a destination for log messages by putting a pipe symbol (|) before the filename. You must create the fifo using the mkfifo command before starting (or restarting) syslogd . Fifos are sometimes used for debugging. |
| Terminal and Console | A terminal such as /dev/console. |
| Remote Machine | To forward messages to another host, put an at (@) sign before the hostname. Note that messages are not forwarded from the receiving host. |
| List of Users | A comma-separated list of users to receive a message (if the user is logged in). The root user is frequently included here. |
| Everyone logged on | Specify an asterisk (*) to have everyone logged on notified using the wall command. |
You may prefix ! to a priority to indicate that the action should not apply to this level and higher. Similarly you may prefix it with = to indicate that the rule applies only to this level or with != to indicate that the rule applies to all except this level. Listing 22 shows some examples, and the man page for syslog.conf has many more examples.
Listing 22. More syslog.conf examples
# Store all kernel messages in /var/log/kernel.
# Send critical and higher ones to remote host pinguino and to the console
# Finally, Send info, notice and warning messages to /var/log/kernel-info
#
kern.* /var/log/kernel
kern.crit @pinguino
kern.crit /dev/console
kern.info;kern.!err /var/log/kernel-info
# Store all mail messages except info priority in /var/log/mail.
mail.*;mail.!=info /var/log/mailRotate and archive log files automatically
With the amount of logging that is possible, you need to be able to control the size of log files. This is done using the logrotate command, which is usually run as a cron job. Cron jobs are covered later in this tutorial in the section Scheduling jobs . The general idea behind the logrotate command is that log files are periodically backed up and a new log is started. Several generations of log are kept, and when a log ages to the last generation, it may be archived. For example, it might be mailed to an archival user.
You use the /etc/logrotate.conf configuration file to specify how your log rotating and archiving should happen. You can specify different frequencies, such as daily, weekly, or monthly, for different log files, and you can control the number of generations to keep and when or whether to mail copies to an archival user. Listing 23 shows a sample /etc/logrotate.conf file.
Listing 23. Sample /etc/logrotate.conf
# rotate log files weekly
weekly
# keep 4 weeks worth of backlogs
rotate 4
# create new (empty) log files after rotating old ones
create
# uncomment this if you want your log files compressed
#compress
# packages drop log rotation information into this directory
include /etc/logrotate.d
# no packages own wtmp, or btmp -- we'll rotate them here
/var/log/wtmp {
missingok
monthly
create 0664 root utmp
rotate 1
}
/var/log/btmp {
missingok
monthly
create 0664 root utmp
rotate 1
}
# system-specific logs may be configured hereThe logrotate.conf file has global options at the beginning. These are the defaults if nothing more specific is specified elsewhere. In this example, log files are rotated weekly, and four weeks worth of backups are kept. Once a log file is rotated, a new one is automatically created in place of the old one. Note that the logrotate.conf file may include specifications from other files. Here, all the files in /etc/logrotate.d are included.
This example also includes specific rules for /var/log/wtmp and /var/log/btmp, which are rotated monthly. No error message is issued if the files are missing. A new file is created, and only one backup is kept.
In this example, when a backup reaches the last generation, it is deleted because there is no specification of what else to do with it.
Note: The files /var/log/wtmp and /var/log/btmp record successful and unsuccessful login attempts, respectively. Unlike most log files, these are not clear text files. You may examine them using the last or lastb commands. See the man pages for these commands for details.
Log files may also be backed up when they reach a specific size, and commands may be scripted to run either prior to or after the backup operation. Listing 24 shows a more complex example.
Listing 24. Another logrotate configuration example
/var/log/messages {
rotate 5
mail logsave@pinguino
size 100k
postrotate
/usr/bin/killall -HUP syslogd
endscript
} In this example, /var/log/messages is rotated after it reaches 100KB in size. Five backups are kept, and when the oldest backup ages out, it is mailed to logsave@pinguino. The postrotate introduces a script that restarts the syslogd daemon after the rotation is complete, by sending it the HUP signal. The endscript statement is required to terminate the script and is also required if a prerotate script is present. See the logrotate man page for more complete information.
Scan log files for notable activity
Log files entries are usually time stamped and contain the hostname of the reporting process, along with the process name. Listing 25 shows a few lines from /var/log/messages, containing entries from gconfd, ntpd, init, and yum.
Listing 25. Sample log file entries
Jul 5 15:28:24 lyrebird gconfd (root-2832): Exiting
Jul 5 15:31:06 lyrebird ntpd[2063]: synchronized to 87.98.219.90, stratum 2
Jul 5 15:31:06 lyrebird ntpd[2063]: kernel time sync status change 0001
Jul 5 15:31:24 lyrebird init: Trying to re-exec init
Jul 5 15:31:24 lyrebird yum: Updated: libselinux.i386 2.0.14-2.fc7
Jul 5 15:31:24 lyrebird yum: Updated: libsemanage.i386 2.0.3-4.fc7
Jul 5 15:31:25 lyrebird yum: Updated: cups-libs.i386 1.2.11-2.fc7
Jul 5 15:31:25 lyrebird yum: Updated: libXfont.i386 1.2.9-2.fc7
Jul 5 15:31:27 lyrebird yum: Updated: NetworkManager.i386 0.6.5-7.fc7
Jul 5 15:31:27 lyrebird yum: Updated: NetworkManager-glib.i386 0.6.5-7.fc7 You can scan log files using a pager, such as less , or search for specific entries (such as kernel messages from host lyrebird) using grep as shown in Listing 26.
Listing 26. Scanning log files
[root@lyrebird ~]# less /var/log/messages
[root@lyrebird ~]# grep "lyrebird kernel" /var/log/messages | tail -n 9
Jul 5 15:26:46 lyrebird kernel: Bluetooth: HCI socket layer initialized
Jul 5 15:26:46 lyrebird kernel: Bluetooth: L2CAP ver 2.8
Jul 5 15:26:46 lyrebird kernel: Bluetooth: L2CAP socket layer initialized
Jul 5 15:26:46 lyrebird kernel: Bluetooth: RFCOMM socket layer initialized
Jul 5 15:26:46 lyrebird kernel: Bluetooth: RFCOMM TTY layer initialized
Jul 5 15:26:46 lyrebird kernel: Bluetooth: RFCOMM ver 1.8
Jul 5 15:26:46 lyrebird kernel: Bluetooth: HIDP (Human Interface Emulation) ver 1.2
Jul 5 15:26:59 lyrebird kernel: [drm] Initialized drm 1.1.0 20060810
Jul 5 15:26:59 lyrebird kernel: [drm] Initialized i915 1.6.0 20060119 on minor 0Monitor log files
Occasionally you may need to monitor log files for events. For example, you might be trying to catch an infrequently occurring event at the time it happens. In such a case, you can use the tail command with the -f option to follow the log file. Listing 27 shows an example.
Listing 27. Following log file updates
[root@lyrebird ~]# tail -n 1 -f /var/log/messages
Jul 6 15:16:26 lyrebird syslogd 1.4.2: restart.
Jul 6 15:16:26 lyrebird kernel: klogd 1.4.2, log source = /proc/kmsg started.
Jul 6 15:19:35 lyrebird yum: Updated: samba-common.i386 3.0.25b-2.fc7
Jul 6 15:19:35 lyrebird yum: Updated: procps.i386 3.2.7-14.fc7
Jul 6 15:19:36 lyrebird yum: Updated: samba-client.i386 3.0.25b-2.fc7
Jul 6 15:19:37 lyrebird yum: Updated: libsmbclient.i386 3.0.25b-2.fc7
Jul 6 15:19:46 lyrebird gconfd (ian-3267): Received signal 15, shutting down cleanly
Jul 6 15:19:46 lyrebird gconfd (ian-3267): Exiting
Jul 6 15:19:57 lyrebird yum: Updated: bluez-gnome.i386 0.8-1.fc7Track down problems reported in log files
When you find problems in log files, you will want to note the time, the hostname, and the process that generated the problem. If the message identifies the problem specifically enough for you to resolve it, you are done. If not, you might need to update syslog.conf to specify that more messages be logged for the appropriate facility. For example, you might need to show informational messages instead of warning messages or even debug level messages. Your application may have additional facilities that you can use.
Finally, if you need to put marks in the log file to help you know what messages were logged at what stage of your debugging activity, you can use the logger command from a terminal window or shell script to send a message of your choice to the syslog daemon for logging according to the rules in syslog.conf.
Scheduling jobs
This section covers material for topic 1.111.4 for the Junior Level Administration (LPIC-1) exam 102. The topic has a weight of 4.
在本节中,学习如何:
- Use the
cronoranacroncommands to run jobs at regular intervals - Use the
atcommand to run jobs at a specific time - Manage cron and at jobs
- Configure user access to the cron and at services
In the previous section, you learned about the logrotate command and saw the need to run it periodically. You will see the same need to run commands regularly in the next two sections on backup and network time services. These are only some of the many administrative tasks that have to be done frequently and regularly. In this section, you learn about the tools that are used to automate periodic job scheduling and also the tools used to run a job at some specific time.
Run jobs at regular intervals
Running jobs at regular intervals is managed by the cron facility, which consists of the crond daemon and a set of tables describing what work is to be done and with what frequency. The daemon wakes up every minute and checks the crontabs to determine what needs to be done. Users manage crontabs using the crontab command. The crond daemon is usually started by the init process at system startup.
To keep things simple, let's suppose that you want to run the command shown in Listing 28 on a regular basis. This command doesn't actually do anything except report the day and the time, but it illustrates how to use crontab to set up cron jobs, and we'll know when it was run from the output. Setting up crontab entries requires a string with escaped shell metacharacters, so it is best done with simple commands and parameters, so in this example, the echo command will be run from within a script /home/ian/mycrontab.sh, which takes no parameters. This saves some careful work with escape characters.
Listing 28. A simple command example.
[ian@lyrebird ~]$ cat mycrontest.sh
#!/bin/bash
echo "It is now $(date +%T) on $(date +%A)"
[ian@lyrebird ~]$ ./mycrontest.sh
It is now 18:37:42 on FridayCreating a crontab
To create a crontab, you use the crontab command with the -e (for "edit") option. This will open the vi editor unless you have specified another editor in the EDITOR or VISUAL environment variable.
Each crontab entry contains six fields:
- 分钟
- 小时
- Day of the month
- Month of the year
- Day of the week
- String to be executed by
sh
Minutes and hours range from 0-59 and 0-23, respectively, while day or month and month of year range from 1-31 and 1-12, respectively. Day of week ranges from 0-6 with 0 being Sunday. Day of week may also be specified as sun, mon, tue, and so on. The sixth field is everything after the fifth field, is interpreted as a string to pass to sh . A percent sign (%) will be translated to a newline, so if you want a % or any other special character, precede it with a backslash (\). The line up to the first % is passed to the shell, while any line(s) after the % are passed as standard input.
The various time-related fields can specify an individual value, a range of values, such as 0-10 or sun-wed, or a comma-separated list of individual values and ranges. So a somewhat artificial crontab entry for our example command might be as shown in Listing 29.
Listing 29. A simple crontab example.
0,20,40 22-23 * 7 fri-sat /home/ian/mycrontest.shIn this example, our command is executed at the 0th, 20th, and 40th minutes (every 20 minutes), for the hours between 10 PM and midnight on Fridays and Saturdays during July. See the man page for crontab(5) for details on additional ways to specify times.
What about the output?
You may be wondering what happens to any output from the command. Most commands designed for use with the cron facility will log output using the syslog facility that you learned about in the previous section. However any output that is directed to stdout will be mailed to the user. Listing 30 shows the output you might receive from our example command.
Listing 30. Mailed cron output
From [email protected] Fri Jul 6 23:00:02 2007
Date: Fri, 6 Jul 2007 23:00:01 -0400
From: [email protected] (Cron Daemon)
To: [email protected]
Subject: Cron /home/ian/mycrontest.sh
Content-Type: text/plain; charset=UTF-8
Auto-Submitted: auto-generated
X-Cron-Env:
X-Cron-Env:
X-Cron-Env:
X-Cron-Env:
X-Cron-Env:
It is now 23:00:01 on Friday Where is my crontab?
The crontab that you created with the crontab command is stored in /etc/spool/cron under the name of the user who created it. So the above crontab is stored in /etc/spool/cron/ian. Given this, you will not be surprised to learn that the crontab command, like the passwd command you learned about earlier, is an suid program that runs with root authority.
/etc/crontab
In addition to the user crontab files in /var/spool/cron, cron also checks /etc/crontab and files in the /etc/cron.d directory. These system crontabs have one additional field between the fifth time entry (day) and the command. This additional field specifies the user for whom the command should be run, normally root. A /etc/crontab might look like the example in Listing 31.
Listing 31. /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
# run-parts
01 * * * * root run-parts /etc/cron.hourly
02 4 * * * root run-parts /etc/cron.daily
22 4 * * 0 root run-parts /etc/cron.weekly
42 4 1 * * root run-parts /etc/cron.monthly In this example, the real work is done by the run-parts command, which runs scripts from /etc/cron.hourly, /etc/cron.daily, and so on; /etc/crontab simply controls the timing of the recurring jobs. Note that the commands here all run as root. Note also that the crontab can include shell variables assignments that will be set before the commands are run.
Anacron
The cron facility works well for systems that run continuously. For systems that may be turned off much of the time, such as laptops, another facility, the anacron (for "anachronistic cron") can handle scheduling of the jobs usually done daily, weekly, or monthly by the cron facility. Anacron does not handle hourly jobs.
Anacron keeps timestamp files in /var/spool/anacron to record when jobs are run. When anacron runs, it checks to see if the required number of days has passed since the job was last run and runs it if necessary. The table of jobs for anacron is stored in /etc/anacrontab, which has a slightly different format than /etc/crontab. As with /etc/crontab, /etc/anacrontab may contain environment settings. Each job has four fields.
- 期
- 延迟
- job-identifier
- 命令
The period is a number of days, but may be specified as @monthly to ensure that a job runs only once per month, regardless of the number of days in the month. The delay is the number of minutes to wait after the job is due to run before actually starting it. You can use this to prevent a flood of jobs when a system first starts. The job identifier can contain any non-blank character except slashes (/).
Both /etc/crontab and /etc/anacrontab are updated by direct editing. You do not use the crontab command to update these files or files in the /etc/cron.d directory.
Run jobs at specific times
Sometimes you may need to run a job just once, rather than regularly. For this you use the at command. The commands to be run are read from a file specified with the -f option, or from stdin if -f is not used. The -m option sends mail to the user even if there is no stdout from the command. The -v option will display the time at which the job will run before reading the job. The time is also displayed in the output. Listing 32 shows an example of running the mycrontest.sh script that you used earlier. Listing 33 shows the output that is mailed back to the user after the job runs. Notice that it is somewhat more compact than the corresponding output from the cron job.
Listing 32. Using the at command
[ian@lyrebird ~]$ at -f mycrontest.sh -v 10:25
Sat Jul 7 10:25:00 2007
job 5 at Sat Jul 7 10:25:00 2007Listing 33. Job output from at
From [email protected] Sat Jul 7 10:25:00 2007
Date: Sat, 7 Jul 2007 10:25:00 -0400
From: Ian Shields
Subject: Output from your job 5
To: [email protected]
It is now 10:25:00 on Saturday Time specifications can be quite complex. Listing 34 shows a few examples. See the man page for at or the file /usr/share/doc/at/timespec or a file such as /usr/share/doc/at-3.1.10/timespec, where 3.1.10 in this example is the version of the at package.
Listing 34. Time values with the at command
[ian@lyrebird ~]$ at -f mycrontest.sh 10pm tomorrow
job 14 at Sun Jul 8 22:00:00 2007
[ian@lyrebird ~]$ at -f mycrontest.sh 2:00 tuesday
job 15 at Tue Jul 10 02:00:00 2007
[ian@lyrebird ~]$ at -f mycrontest.sh 2:00 july 11
job 16 at Wed Jul 11 02:00:00 2007
[ian@lyrebird ~]$ at -f mycrontest.sh 2:00 next week
job 17 at Sat Jul 14 02:00:00 2007 The at command also has a -q option. Increasing the queue increases the nice value for the job. There is also a batch command, which is similar to the at command except that jobs are run only when the system load is low enough. See the man pages for more details on these features.
Manage scheduled jobs
Listing scheduled jobs
You can manage your cron and at jobs. Use the crontab command with the -l option to list your crontab, and use the atq command to display the jobs you have queued using the at command, as shown in Listing 35.
Listing 35. Displaying scheduled jobs
[ian@lyrebird ~]$ crontab -l
0,20,40 22-23 * 7 fri-sat /home/ian/mycrontest.sh
[ian@lyrebird ~]$ atq
16 Wed Jul 11 02:00:00 2007 a ian
17 Sat Jul 14 02:00:00 2007 a ian
14 Sun Jul 8 22:00:00 2007 a ian
15 Tue Jul 10 02:00:00 2007 a ian If you want to review the actual command scheduled for execution by at , you can use the at command with the -c option and the job number. You will notice that most of the environment that was active at the time the at command was issued is saved with the scheduled job. Listing 36 shows part of the output for job 15.
Listing 36. Using at -c with a job number
#!/bin/sh
# atrun uid=500 gid=500
# mail ian 0
umask 2
HOSTNAME=lyrebird.raleigh.ibm.com; export HOSTNAME
SHELL=/bin/bash; export SHELL
HISTSIZE=1000; export HISTSIZE
SSH_CLIENT=9.67.219.151\ 3210\ 22; export SSH_CLIENT
SSH_TTY=/dev/pts/5; export SSH_TTY
USER=ian; export USER
...
HOME=/home/ian; export HOME
LOGNAME=ian; export LOGNAME
...
cd /home/ian || {
echo 'Execution directory inaccessible' >&2
exit 1
}
${SHELL:-/bin/sh} << `(dd if=/dev/urandom count=200 bs=1 \
2>/dev/null|LC_ALL=C tr -d -c '[:alnum:]')`
#!/bin/bash
echo "It is now $(date +%T) on $(date +%A)"Note that the contents of our script file have been copied in as a here-document that will be executed by the shell specified by the SHELL variable or /bin/sh if the SHELL variable is not set.
Deleting scheduled jobs
You can delete all scheduled cron jobs using the cron command with the -r option as illustrated in Listing 37.
Listing 37. Displaying and deleting cron jobs
[ian@lyrebird ~]$ crontab -l
0,20,40 22-23 * 7 fri-sat /home/ian/mycrontest.sh
[ian@lyrebird ~]$ crontab -r
[ian@lyrebird ~]$ crontab -l
no crontab for ianTo delete system cron or anacron jobs, edit /etc/crontab, /etc/anacrontab, or edit or delete files in the /etc/cron.d directory.
You can delete one or more jobs that were scheduled with the at command by using the atrm command with the job number. Multiple jobs should be separated by spaces. Listing 38 shows an example.
Listing 38. Displaying and removing jobs with atq and atrm
[ian@lyrebird ~]$ atq
16 Wed Jul 11 02:00:00 2007 a ian
17 Sat Jul 14 02:00:00 2007 a ian
14 Sun Jul 8 22:00:00 2007 a ian
15 Tue Jul 10 02:00:00 2007 a ian
[ian@lyrebird ~]$ atrm 16 14 15
[ian@lyrebird ~]$ atq
17 Sat Jul 14 02:00:00 2007 a ianConfigure user access to job scheduling
If the file /etc/cron.allow exists, any non-root user must be listed in it in order to use crontab and the cron facility. If /etc/cron.allow does not exist, but /etc/cron.deny does exist, a non-root user who is listed in it cannot use crontab or the cron facility. If neither of these files exists, only the super user will be allowed to use this command. An empty /etc/cron.deny file allows all users to use the cron facility and is the default.
The corresponding /etc/at.allow and /etc/at.deny files have similar effects for the at facility.
Data backup
This section covers material for topic 1.111.5 for the Junior Level Administration (LPIC-1) exam 102. The topic has a weight of 3.
在本节中,学习如何:
- Plan a backup strategy
- Dump a raw device to a file or restore a raw device from a file
- Perform partial and manual backups
- Verify the integrity of backup files
- Restore filesystems partially or fully from backups
Plan a backup strategy
Having a good backup is a necessary part of system administration, but deciding what to back up and when and how can be complex. Databases, such as customer orders or inventory, are usually critical to a business and many include specialized backup and recovery tools that are beyond the scope of this tutorial. At the other extreme, some files are temporary in nature and no backup is needed at all. In this section, we focus on system files and user data and discuss some of the considerations, methods, and tools for backup of such data.
There are three general approaches to backup:
- A full backup is a complete backup, usually of a whole filesystem, directory, or group of related files. This takes the longest time to create, so it is usually used with one of the other two approaches.
- A differential or cumulative backup is a backup of all things that have changed since the last full backup. Recovery requires the last full backup plus the latest differential backup.
- An incremental backup is a backup of only those changes since the last incremental backup. Recovery requires the last full backup plus all of the incremental backups (in order) since the last full backup.
What to back up
When deciding what to back up, you should consider how volatile the data is. This will help you determine how often it should be backed up. Similarly, critical data should be backed up more often than non-critical data. Your operating system will probably be relatively easy to rebuild, particularly if you use a common image for several systems, although the files that customize each system would be more important to back up.
For programming staff, it may be sufficient to keep backups of repositories such as CVS repositories, while individual programmers' sandboxes may be less important. Depending on how important mail is to your operation, it may suffice to have infrequent mail backups, or it may be necessary to be able to recover mail to the most recent date possible. You may want to keep backups of system cron files, but may not be so concerned about scheduled jobs for individual users.
The Filesystem Hierarchy Standard provides a classification of data that may help you with your backup choices. For details, " Exam 101 - Topic 104: Devices, Linux filesystems, Filesystem Hierarchy Standard ".
Once you have decided what to back up, you need to decide how often to do a full backup and whether to do differential or incremental backups in between those full backups. Having made those decisions, the following suggestions will help you choose appropriate tools.
Automating backups
In the previous section, you learned how to schedule jobs, and the cron facility is ideal for helping to automate the scheduling of your backups. However, backups are frequently made to removable media, particularly tape, so operator intervention is probably going to be needed. You should create and use backup scripts to ensure that the backup process is as automatic and repeatable as possible.
Dump and restore raw devices
One way to make a full backup of a filesystem is to make an image of the partition on which it resides. A raw device , such as /dev/hda1 or /dev/sda2, can be opened and read as a sequential file. Similarly, it can be written from a backup as a sequential file. This requires no knowledge on the part of the backup tool as to the filesystem layout, but does require that the restore be done to space that is at least as large as the original. Some tools that handle raw devices are filesystem aware , meaning that they understand one or more of the Linux filesystems. These utilities can dump from a raw device but do not dump unused parts of the partition. They may or may not require restoration to the same or larger sized partition. The dd command is an example of the first type, while the dump command is an example of the second type that is specific to the ext2 and ext3 filesystems.
The dd command
In its simplest form, the dd command copies an input file to an output file, where either file may be a raw device. For backing up a raw device, such as /dev/hda1 or /dev/sda2, the input file would be a raw device. Ideally, the filesystem on the device should be unmounted, or at least mounted read only, to ensure that data does not change during the backup. Listing 39 shows an example.
Listing 39. Backup a partition using dd
[root@lyrebird ~]# dd if=/dev/sda3 of=backup-1
2040255+0 records in
2040255+0 records out
1044610560 bytes (1.0 GB) copied, 49.3103 s, 21.2 MB/s The if and of parameters specify the input and output files respectively. In this example, the input file is a raw device, dev/sda3, and the output file is a file, backup-1, in the root user's home directory. To dump the file to tape or floppy disk, you would specify something like of=/dev/fd0 or of=/dev/st0 .
Note that 1,044,610,560 bytes of data was copied and the output file is indeed that large, even though only about 3% of this particular partition is actually used. Unless you are copying to a tape with hardware compression, you will probably want to compress the data. Listing 40 shows one way to accomplish this, along with the output of ls and df commands, which show you the file sizes and the usage percentage of the filesystem on /dev/sda3.
Listing 40. Backup with compression using dd
[root@lyrebird ~]# dd if=/dev/sda3 | gzip > backup-2
2040255+0 records in
2040255+0 records out
1044610560 bytes (1.0 GB) copied, 117.723 s, 8.9 MB/s
[root@lyrebird ~]# ls -l backup-[12]
-rw-r--r-- 1 root root 1044610560 2007-07-08 15:17 backup-1
-rw-r--r-- 1 root root 266932272 2007-07-08 15:56 backup-2
[root@lyrebird ~]# df -h /dev/sda3
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 972M 28M 944M 3% /grubfileThe gzip compression reduced the file size to about 20% of the uncompressed size. However, unused blocks may contain arbitrary data, so even the compressed backup may be much larger than the total data on the partition.
If you divide the size by the number of records processed by dd , you will see that dd is writing 512-byte blocks of data. When copying to a raw output device such as tape, this can result in a very inefficient operation, so dd can read or write data in much larger blocks. Specify the obs option to change the output size or the ibs option to specify the input block size. You can also specify just bs to set both input and output block sizes to a common value.
If you need multiple tapes or other removable storage to store your backup, you will need to break it into smaller pieces using a utility such as split .
If you need to skip blocks such as disk or tape labels, you can do so with dd . See the man page for examples.
Besides just copying data, the dd command can do several conversions, such as between ASCII and EBCDIC, between big-endian and little-endian, or between variable-length data records and fixed-length data records. Obviously these conversions are likely to be useful when copying real files rather than raw devices. Again, see the man page for details.
The dump command
The dump command can be used for full, differential, or incremental backups on ext2 or ext3 filesystems. Listing 41 shows an example.
Listing 41. Backup with compression using dump
[root@lyrebird ~]# dump -0 -f backup-4 -j -u /dev/sda3
DUMP: Date of this level 0 dump: Sun Jul 8 16:47:47 2007
DUMP: Dumping /dev/sda3 (/grubfile) to backup-4
DUMP: Label: GRUB
DUMP: Writing 10 Kilobyte records
DUMP: Compressing output at compression level 2 (bzlib)
DUMP: mapping (Pass I) [regular files]
DUMP: mapping (Pass II) [directories]
DUMP: estimated 12285 blocks.
DUMP: Volume 1 started with block 1 at: Sun Jul 8 16:47:48 2007
DUMP: dumping (Pass III) [directories]
DUMP: dumping (Pass IV) [regular files]
DUMP: Closing backup-4
DUMP: Volume 1 completed at: Sun Jul 8 16:47:57 2007
DUMP: Volume 1 took 0:00:09
DUMP: Volume 1 transfer rate: 819 kB/s
DUMP: Volume 1 12260kB uncompressed, 7377kB compressed, 1.662:1
DUMP: 12260 blocks (11.97MB) on 1 volume(s)
DUMP: finished in 9 seconds, throughput 1362 kBytes/sec
DUMP: Date of this level 0 dump: Sun Jul 8 16:47:47 2007
DUMP: Date this dump completed: Sun Jul 8 16:47:57 2007
DUMP: Average transfer rate: 819 kB/s
DUMP: Wrote 12260kB uncompressed, 7377kB compressed, 1.662:1
DUMP: DUMP IS DONE
[root@lyrebird ~]# ls -l backup-[2-4]
-rw-r--r-- 1 root root 266932272 2007-07-08 15:56 backup-2
-rw-r--r-- 1 root root 266932272 2007-07-08 15:44 backup-3
-rw-r--r-- 1 root root 7554939 2007-07-08 16:47 backup-4 In this example, -0 specifies the dump level which is an integer, historically from 0 to 9, where 0 specifies a full dump. The -f option specifies the output file, which may be a raw device. Specify - to direct the output to stdout. The -j option specifies compression, with a default level of 2, using bzlib compression. You can use the -z option to specify zlib compression if you prefer. The -u option causes the record of dump information, normally /etc/dumpdates, to be updated. Any parameters after the options represent a file or list of files, where the file may also be a raw device, as in this example. Notice how much smaller the backup is when the backup program is aware of the filesystem structure and can avoid the saving of unused blocks on the device.
If output is to a device such as tape, the dump command will prompt for another volume as each volume is filled. You can also provide multiple file names separated by commas. For example, if you wanted an unattended dump that required two tapes, you could load the tapes on /dev/st0 and /dev/st1, schedule the dump command specifying both tapes as output, and go home to sleep.
When you specify a dump level greater than 0, an incremental dump is performed of all files that are new or have changed since the last dump at a lower level was taken. So a dump at level 1 will be a differential dump, even if a dump at level 2 or higher has been taken in the meantime. Listing 42 shows the result of updating the time stamp of an existing file on /dev/sda3 and creating a new file, then taking a dump at level 2. After that, another new file is created and a dump at level 1 is taken. The information from /etc/dumpdates is also shown. For brevity, part of the second dump output has been omitted.
Listing 42. Backup with compression using dump
[root@lyrebird ~]# dump -2 -f backup-5 -j -u /dev/sda3
DUMP: Date of this level 2 dump: Sun Jul 8 16:55:46 2007
DUMP: Date of last level 0 dump: Sun Jul 8 16:47:47 2007
DUMP: Dumping /dev/sda3 (/grubfile) to backup-5
DUMP: Label: GRUB
DUMP: Writing 10 Kilobyte records
DUMP: Compressing output at compression level 2 (bzlib)
DUMP: mapping (Pass I) [regular files]
DUMP: mapping (Pass II) [directories]
DUMP: estimated 91 blocks.
DUMP: Volume 1 started with block 1 at: Sun Jul 8 16:55:47 2007
DUMP: dumping (Pass III) [directories]
DUMP: dumping (Pass IV) [regular files]
DUMP: Closing backup-5
DUMP: Volume 1 completed at: Sun Jul 8 16:55:47 2007
DUMP: 90 blocks (0.09MB) on 1 volume(s)
DUMP: finished in less than a second
DUMP: Date of this level 2 dump: Sun Jul 8 16:55:46 2007
DUMP: Date this dump completed: Sun Jul 8 16:55:47 2007
DUMP: Average transfer rate: 0 kB/s
DUMP: Wrote 90kB uncompressed, 15kB compressed, 6.000:1
DUMP: DUMP IS DONE
[root@lyrebird ~]# echo "This data is even newer" >/grubfile/newerfile
[root@lyrebird ~]# dump -1 -f backup-6 -j -u -A backup-6-toc /dev/sda3
DUMP: Date of this level 1 dump: Sun Jul 8 17:08:18 2007
DUMP: Date of last level 0 dump: Sun Jul 8 16:47:47 2007
DUMP: Dumping /dev/sda3 (/grubfile) to backup-6
...
DUMP: Wrote 100kB uncompressed, 16kB compressed, 6.250:1
DUMP: Archiving dump to backup-6-toc
DUMP: DUMP IS DONE
[root@lyrebird ~]# ls -l backup-[4-6]
-rw-r--r-- 1 root root 7554939 2007-07-08 16:47 backup-4
-rw-r--r-- 1 root root 16198 2007-07-08 16:55 backup-5
-rw-r--r-- 1 root root 16560 2007-07-08 17:08 backup-6
[root@lyrebird ~]# cat /etc/dumpdates
/dev/sda3 0 Sun Jul 8 16:47:47 2007 -0400
/dev/sda3 2 Sun Jul 8 16:55:46 2007 -0400
/dev/sda3 1 Sun Jul 8 17:08:18 2007 -0400 Notice that backup-6 is, indeed, larger than backup 5. The level 1 dump illustrates the use of the -A option to create a table of contents that can be used to determine if a file is on an archive without actually mounting the archive. This is particularly useful with tape or other removable archive volumes. You will see these examples again when we discuss restoring data later in this section.
The dump command can dump files or subdirectories, but you cannot update /etc/dumpdates and only level 0, of full dump, is supported.
Listing 43 illustrates the dump command dumping a directory, /usr/include/bits, and its contents to floppy disk. In this case, the dump will not fit on a single floppy, so a new volume is required. The prompt and response are shown in bold.
Listing 43. Backup a directory to multiple volumes using dump
[root@lyrebird ~]# dump -0 -f /dev/fd0 /usr/include/bits
DUMP: Date of this level 0 dump: Mon Jul 9 16:03:23 2007
DUMP: Dumping /dev/sdb9 (/ (dir usr/include/bits)) to /dev/fd0
DUMP: Label: /
DUMP: Writing 10 Kilobyte records
DUMP: mapping (Pass I) [regular files]
DUMP: mapping (Pass II) [directories]
DUMP: estimated 2790 blocks.
DUMP: Volume 1 started with block 1 at: Mon Jul 9 16:03:30 2007
DUMP: dumping (Pass III) [directories]
DUMP: End of tape detected
DUMP: Closing /dev/fd0
DUMP: Volume 1 completed at: Mon Jul 9 16:04:49 2007
DUMP: Volume 1 1470 blocks (1.44MB)
DUMP: Volume 1 took 0:01:19
DUMP: Volume 1 transfer rate: 18 kB/s
DUMP: Change Volumes: Mount volume #2
DUMP: Is the new volume mounted and ready to go?: ("yes" or "no") y
DUMP: Volume 2 started with block 1441 at: Mon Jul 9 16:05:10 2007
DUMP: Volume 2 begins with blocks from inode 2
DUMP: dumping (Pass IV) [regular files]
DUMP: Closing /dev/fd0
DUMP: Volume 2 completed at: Mon Jul 9 16:06:28 2007
DUMP: Volume 2 1410 blocks (1.38MB)
DUMP: Volume 2 took 0:01:18
DUMP: Volume 2 transfer rate: 18 kB/s
DUMP: 2850 blocks (2.78MB) on 2 volume(s)
DUMP: finished in 109 seconds, throughput 26 kBytes/sec
DUMP: Date of this level 0 dump: Mon Jul 9 16:03:23 2007
DUMP: Date this dump completed: Mon Jul 9 16:06:28 2007
DUMP: Average transfer rate: 18 kB/s
DUMP: DUMP IS DONE If you back up to tape, remember that the tape will usually be rewound after each job. Devices with a name like /dev/st0 or /dev/st1 automatically rewind. The corresponding non-rewind equivalent devices are /dev/nst0 and /dev/nst1. In any event, you can always use the mt command to perform magnetic tape operations such as forward spacing over files and records, back spacing, rewinding, and writing EOF marks. See the man pages for mt and st for additional information.
If you select the dump levels judiciously, you can minimize the number of archives you need to restore to any particular level. See the man pages for dump for a suggestion based on the Towers of Hanoi puzzle.
As with the dd command, there are many options that are not covered in this brief introduction. See the man pages for more details.
Partial and manual backups
So far, you have learned about tools that work well for backing up whole filesystems. Sometimes your backup needs to target selected files or subdirectories without backing up the whole filesystem. For example, you might need a weekly backup of most of your system, but daily backups of your mail files. Two other programs, cpio and tar , are more commonly used for this purpose. Both can write archives to files or to devices such as tape or floppy disk, and both can restore from such archives. Of the two, tar is more commonly used today, possibly because it handles complete directories better, and GNU tar supports both gzip and bzip compression.
Using cpio
The cpio command operates in copy-out mode to create an archive, copy-in mode to restore an archive, or copy-pass mode to copy a set of files from one location to another. You use the -o or --create option for copy-out mode, the -i or --extract option for copy-in mode, and the -p or --pass-through option for copy-pass mode. Input is a list of files provided on stdin. Output is either to stdout or to a device or file specified with the -f or --file option.
Listing 44 shows how to generate a list of files using the find command. Note the use of the -print0 option on find to generate null-terminate strings for file names, and the corresponding --null option on cpio to read this format. This will correctly handle file names that have embedded blank or newline characters.
Listing 44. Back up a home directory using cpio
[root@lyrebird ~]# find ~ian -depth -print0 | cpio --null -o >backup-cpio-1
18855 blocks If you'd like to see the files listed as they are archived, add the -v option to cpio .
As with other commands that can archive to tape, the block size may be specified. For details on this and other options, see the man page.
使用tar
The tar (originally from Tape ARchive ) creates an archive file, or tarfile or tarball , from a set of input files or directories; it also restores files from such an archive. If a directory is given as input to tar , all files and subdirectories are automatically included, which makes tar very convenient for archiving subtrees of your directory structure.
As with the other archiving commands we have discussed, output can be to a file, a device such as tape or diskette, or stdout. The output location is specified with the -f option. Other common options are -c to create an archive, -x to extract an archive, -v for verbose output, which lists the files being processed, -z to use gzip compression, and -j to use bzip2 compression. Most tar options have a short form using a single hyphen and a long form using a pair of hyphens. The short forms are illustrated here. See the man pages for the long form and for additional options.
Listing 45 shows how to create a backup of the system cron jobs using tar .
Listing 45. Backup of system cron jobs using tar
[root@lyrebird ~]# tar -czvf backup-tar-1 /etc/*crontab /etc/cron.d
tar: Removing leading `/' from member names
/etc/anacrontab
/etc/crontab
/etc/cron.d/
/etc/cron.d/sa-update
/etc/cron.d/smolt In the first line of output, you are told that tar will remove the leading slash (/) from member names. This allows files to be restored to some other location for verification before replacing system files. It is a good idea to avoid mixing absolute path names with relative path names when creating an archive, since all will be relative when restoring from the archive.
The tar command can append additional files to an archive using the -r or --append option. This may cause multiple copies of a file in the archive. In such a case, the last one will be restored during a restore operation. You can use the --occurrence option to select a specific file among multiples. If the archive is on a regular filesystem instead of tape, you may use the -u or --update option to update an archive. This works like appending to an archive, except that the time stamps of the files in the archive are compared with those on the filesystem, and only files that have been modified since the archived version are appended. As mentioned, this does not work for tape archives.
As with the other commands you have studied here, there are many options that are not covered in this brief introduction. See the man or info pages for more details.
Backup file integrity
Backup file integrity is extremely important. There is no point in having a backup if it is bad. A good backup strategy also involves checking your backups.
The first step to ensuring backup integrity is to ensure that you have properly captured the data you are backing up. If the filesystem is unmounted or mounted read only, this is usually straightforward as the data you are backing up cannot change during your backup. If you must back up filesystems, directories, or files that are subject to modification while you are taking the backup, you should verify that no changes have been made during your backup. If changes were made, you will need to have a strategy for capturing them, either by repeating the backup, or perhaps by replacing or superseding the affected files in your backup. Needless to say, this will also affect your restore procedures.
Assuming you took good backups, you will periodically need to verify your backups. One way is to restore the backup to a spare volume and verify that it matches what you backed up. This is easiest to do right before you allow updates on the filesystem you are backing up. If you back up to media such as CD or DVD, you may be able to use the diff command as part of your backup procedure to ensure that your backup is good. Remember that even good backups can deteriorate in storage, so you should check periodically, even if you do verify at the time of backup. Keeping digests using programs such as md5sum or sha1sum is also a good check on the integrity of a backup file.
Restore filesystems from backups
A counterpart to backing up files is the ability to restore them when needed. Occasionally you will want to restore an entire filesystem, but it is far more common to need to restore only specific files or perhaps a set of directories. Almost always you will restore to some temporary space and verify that what you have restored is indeed what you want and is consistent with the current state of your system before actually making the restored files live.
A related issue is the need to verify that the items you want happen to be on a particular backup, as often happens when a user needs access to a version of a file that was modified or perhaps deleted "sometime in the last week or two." With these thoughts in mind, let's look at some of the restoration options.
Restoring a dd archive
Recall that the dd command was not filesystem aware, so you will need to restore a dump of a partition to find out what is on it. Listing 46 shows how to restore the partition that was dumped back in Listing 39 to a partition, /dev/sdc7, that was specially created on a removable USB drive just for this purpose.
Listing 46. Restoring a partition using dd
[root@lyrebird ~]# dd if=backup-1 of=/dev/sdc7
2040255+0 records in
2040255+0 records out
1044610560 bytes (1.0 GB) copied, 44.0084 s, 23.7 MB/s Recall that we added some files to the filesystem on /dev/sda3 after this backup was taken. If you mount the newly restore partition and compare it with the original, you will see that this is indeed the case, as shown in Listing 47. Note that the file whose timestamp was updated using touch is not shown here, as you would expect.
Listing 47. Comparing the restored partition with current state
[root@lyrebird ~]# mount /dev/sdc7 /mnt/temp-dd/
[root@lyrebird ~]# diff -rq /grubfile/ /mnt/temp-dd/
Only in /grubfile/: newerfile
Only in /grubfile/: newfileRestoring a dump archive using restore
Recall that our final use of dump was a differential backup and that we created a table of contents. Listing 48 shows how to use restore to check the files in the archive created by dump , using the archive itself (backup-5) or the table of contents (backup-6-toc).
Listing 48. Checking the contents of archives
[root@lyrebird ~]# restore -t -f backup-5
Dump tape is compressed.
Dump date: Sun Jul 8 16:55:46 2007
Dumped from: Sun Jul 8 16:47:47 2007
Level 2 dump of /grubfile on lyrebird.raleigh.ibm.com:/dev/sda3
Label: GRUB
2 .
100481 ./ibshome
100482 ./ibshome/index.html
16 ./newfile
[root@lyrebird ~]# restore -t -A backup-6-toc
Dump date: Sun Jul 8 17:08:18 2007
Dumped from: Sun Jul 8 16:47:47 2007
Level 1 dump of /grubfile on lyrebird.raleigh.ibm.com:/dev/sda3
Label: GRUB
Starting inode numbers by volume:
Volume 1: 2
2 .
100481 ./ibshome
100482 ./ibshome/index.html
16 ./newfile
17 ./newerfile The restore command can also compare the contents of an archive with the contents of the filesystem using the -C option. In Listing 49 we updated newerfile and then compared the backup with the filesystem.
Listing 49. Comparing an archive with a filesystem using restore
[root@lyrebird ~]# echo "something different" >/grubfile/newerfile
[root@lyrebird ~]# restore -C -f backup-6
Dump tape is compressed.
Dump date: Sun Jul 8 17:08:18 2007
Dumped from: Sun Jul 8 16:47:47 2007
Level 1 dump of /grubfile on lyrebird.raleigh.ibm.com:/dev/sda3
Label: GRUB
filesys = /grubfile
./newerfile: size has changed.
Some files were modified! 1 compare errors The restore command can restore interactively or automatically. Listing 50 shows how to restore newerfile to root's home directory (so you could examine it before replacing the updated file if needed), then replace the updated file with the backup copy. This example illustrates interactive restoration.
Listing 50. Restoring a file using restore
[root@lyrebird ~]# restore -i -f backup-6
Dump tape is compressed.
restore > ?
Available commands are:
ls [arg] - list directory
cd arg - change directory
pwd - print current directory
add [arg] - add `arg' to list of files to be extracted
delete [arg] - delete `arg' from list of files to be extracted
extract - extract requested files
setmodes - set modes of requested directories
quit - immediately exit program
what - list dump header information
verbose - toggle verbose flag (useful with ``ls'')
prompt - toggle the prompt display
help or `?' - print this list
If no `arg' is supplied, the current directory is used
restore > ls new*
newerfile
newfile
restore > add newerfile
restore > extract
You have not read any volumes yet.
Unless you know which volume your file(s) are on you should start
with the last volume and work towards the first.
Specify next volume # (none if no more volumes): 1
set owner/mode for '.'? [yn] y
restore > q
[root@lyrebird ~]# mv -f newerfile /grubfileRestoring a cpio archive
The cpio command in copy-in mode (option -i or --extract ) can list the contents of an archive or restore selected files. When you list the files, specifying the --absolute-filenames option reduces the number of extraneous messages that cpio will otherwise issue as it strips any leading / characters from each path that has one. Partial output from listing our previous archive is shown in Listing 51.
Listing 51. Restoring selected files using cpio
[root@lyrebird ~]# cpio -id --list --absolute-filenames Listing 52 shows how to restore all the files with "samp" in their path name or file name. The output has been piped through uniq to reduce the number of "Removing leading '/' ..." messages. You must specify the -d option to create directories; otherwise, all files are created in the current directory. Furthermore, cpio will not replace any newer files on the filesystem with archive copies unless you specify the -u or --unconditional option.
Listing 52. Restoring selected files using cpio
[root@lyrebird ~]# cpio -ivd "*samp*" < backup-cpio-1 2>&1 |uniq
cpio: Removing leading `/' from member names
home/ian/crontab.samp
cpio: Removing leading `/' from member names
home/ian/sample.file
cpio: Removing leading `/' from member names
18855 blocksRestoring a tar archive
The tar command can also compare archives with the current filesystem as well as restore files from archives. Use the -d , --compare , or --diff option to perform comparisons. The output will show files whose contents differ as well as files whose time stamps differ. Listing 53 shows verbose output (using option -v ), from a comparison of the file created earlier and the files in /etc after /etc/crontab has been touched to alter its time stamp. The option directory / instructs tar to perform the comparison starting from the root directory rather than the current directory.
Listing 53. Comparing archives and files using tar
[root@lyrebird ~]# touch /etc/crontab
[root@lyrebird ~]# tar --diff -vf backup-tar-1 --directory /
etc/anacrontab
etc/crontab
etc/crontab: Mod time differs
etc/cron.d/
etc/cron.d/sa-update
etc/cron.d/smoltListing 54 shows how to extract just /etc/crontab and /etc/anacrontab into the current directory.
Listing 54. Extracting archive files using tar
[root@lyrebird ~]# tar -xzvf backup-tar-1 "*tab"
etc/anacrontab
etc/crontab Note that tar , in contrast to cpio creates the directory hierarchy for you automatically.
The next section of this tutorial shows you how to maintain system time.
System time
This section covers material for topic 1.111.6 for the Junior Level Administration (LPIC-1) exam 102. The topic has a weight of 4.
在本节中,学习如何:
- Set the system date and time
- Set the BIOS clock to the correct UTC time
- Configure your time zone
- Configure the Network Time Protocol (NTP) service, including correcting for clock drift
Set the system date and time
System time on a Linux system is very important. You saw earlier how the cron and anacron facilities do things based on time, so they need an accurate time to base decisions on. Most of the backup and restore tools discussed in the previous section, along with development tools such as make , also depend on reliable time measurements. Most computers built since around 1980 include some kind of clock mechanism, and most built since 1984 or so have a persistent clock mechanism that keeps time even if the computer is turned off.
If you installed a Linux system graphically, you probably set the clock and chose a time zone suitable for your needs. You may have elected to use the Network Time Protocol (NTP) to set your clock, and you may or may not have elected to keep the system clock using Coordinated Universal Time or UTC. If you subsequently went to set the clock using graphical tools on a Fedora or Red Hat or similar system, you may have seen a dialog box like that in Figure 3.
Figure 3. Updating the date and time
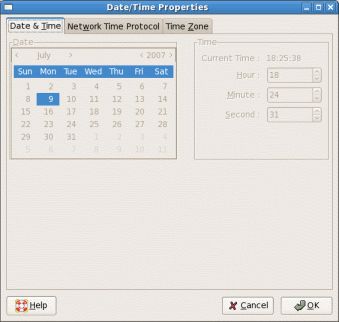
惊喜! You can't actually set the clock yourself using this dialog. In this section you learn more about the difference between local clocks and NTP and how to set your system time.
No matter whether you live in New York, Budapest, Nakhodka, Ulan Bator, Bangkok, or Canberra, most of your Linux time computations are related to Coordinated Universal Time or UTC. If you run a dedicated Linux system, it is customary to keep the hardware clock set to UTC, but if you also boot another operating system such as Windows, you may need to set the hardware clock to local time. It really doesn't matter as far as Linux is concerned, except that there happen to be two different methods of keeping track of time zones internally in Linux, and if they don't agree, you can wind up with some odd time stamps on FAT filesystems, among other things. Listing 55 shows you how to use the date command to display the current date and time. The display is always in local time, even if your hardware clock keeps UTC time.
Listing 55. Displaying the current date and time
[root@lyrebird ~]# date;date -u
Mon Jul 9 22:40:01 EDT 2007 The date command supports a wide variety of possible output formats, some of which you already saw back in Listing 28 . See the man page for date if you'd like to learn more about the various date formats.
If you need to set the date, you can do this by providing a date and time as an argument. The required format is historical and is somewhat odd even to Americans and truly odd to the rest of the world. You must specify at least month, day, hour, and minute in MMDDhhmm format, and you may also append a two- or four-digit year (CCYY or YY) and optionally a period (.) followed by a two-digit number of seconds. Listing 56 shows an example that alters the system date by a little over a minute.
Listing 56. Setting the system date and time
[root@lyrebird ~]# date; date 0709221407;date
Mon Jul 9 23:12:37 EDT 2007
Mon Jul 9 22:14:00 EDT 2007
Mon Jul 9 22:14:00 EDT 2007Set the BIOS clock to UTC time
Your Linux system, along with most other current operating systems, actually has two clocks. The first is the hardware clock, sometimes called the Real Time Clock, RTC, or BIOS clock, which is usually tied to an oscillating quartz crystal that is accurate to within a few seconds per day. It is subject to variations such as ambient temperature. The second is the internal software clock, which is driven by counting system interrupts. It is subject to variations caused by high system load and interrupt latency. Nevertheless, your system typically reads the hardware clock at startup and from then on uses the software clock. The date command that you just learned about sets the software clock, not the hardware clock.
If you use the Network Time Protocol (NTP), you may possibly set the hardware clock when you first install the system and never worry about it again. If not, this part of the tutorial will show you how to display and set the hardware clock time.
You can use the hwclock command to display the current value of the hardware clock. Listing 57 shows the current value of both the system and hardware clocks.
Listing 57. System and hardware clock values
[root@lyrebird ~]# date;hwclock
Mon Jul 9 22:16:11 EDT 2007
Mon 09 Jul 2007 11:14:49 PM EDT -0.071616 seconds Notice that the two values are different. You can synchronize the hardware clock from the system clock using the -w or --systohc option of hwclock , and you can synchronize the system clock from the hardware clock using the -s or --hctosys option, as shown in Listing 58.
Listing 58. Setting the system clock from the hardware clock
[root@lyrebird ~]# date;hwclock;hwclock -s;date
Mon Jul 9 22:20:23 EDT 2007
Mon 09 Jul 2007 11:19:01 PM EDT -0.414881 seconds
Mon Jul 9 23:19:02 EDT 2007 You may specify either the --utc or the --localtime option to have the system clock kept in UTC or local time. If no value is specified, the value is taken from the third line of /etc/adjtime.
The Linux kernel has a mode that copies the system time to the hardware clock every 11 minutes. This is off by default, but is turned on by NTP. Running anything that set the time the old fashioned way, such as hwclock --hctosys , turns it off, so it's a good idea to just let NTP do its work if you are using NTP. See the man page for adjtimex to find out how to check whether the clock is being updated every 11 minutes or not. You may need to install the adjtimex package as it is not always installed by default.
The hwclock command keeps track of changes made to the hardware clock in order to compensate for inaccuracies in the clock frequency. The necessary data points are kept in /etc/adjtime, which is an ASCII file. If you are not using the Network Time Protocol, you can use the adjtimex command to compensate for clock drift. Otherwise, the hardware clock will be adjusted approximately every 11 minutes by NTP. Besides showing whether your hardware clock is in local or UTC time, the first value in /etc/adjtime shows the amount of hardware clock drift per day (in seconds). Listing 59 shows two examples.
Listing 59. /etc/adjtime showing clock drift and local or UTC time.
[root@lyrebird ~]# cat /etc/adjtime
0.000990 1184019960 0.000000
1184019960
LOCAL
root@pinguino:~# cat /etc/adjtime
-0.003247 1182889954 0.000000
1182889954
LOCALNote that both these systems keep the hardware clock in local time, but the clock drifts are different — 0.000990 on lyrebird and -0.003247 on pinguino.
Configure your time zone
Your time zone is a measure of how far your local time differs from UTC. Information on available time zones that can be configured is kept in /usr/share/zoneinfo. Traditionally, /tec/localtime was a link to one of the time zone files in this directory tree, for example, /usr/share/zoneinfo/Eire or /usr/share/zoneinfo/Australia/Hobart. On modern systems it is much more likely to be a copy of the appropriate time zone data file since the /usr/share filesystem may not be mounted when the local time zone information is needed early in the boot process.
Similarly, another file, /etc/timezone was traditionally a link to /etc/default/init and was used to set the time zone environment variable TZ, and several locale-related environment variables. The file may or may not exist on your system. If it does, it may simply contain the name of the current time zone. You may also find time zone information in /etc/sysconfig/clock. Listing 60 shows these files from a Ubuntu 7.04 and a Fedora 7 system.
Listing 60. Time zone information in /etc
root@pinguino:~# cat /etc/timezone
America/New_York
[root@lyrebird ~]# cat /etc/sysconfig/clock
# The ZONE parameter is only evaluated by system-config-date.
# The timezone of the system is defined by the contents of /etc/localtime.
ZONE="America/New York"
UTC=false
ARC=false Some systems such as Debian and Ubuntu have a tzconfig command to set the time zone. Others such as Fedora use system-config-date to set the time zone and to indicate whether the clock uses UTC or not. Listing 61 illustrates the use of the tzconfig command to display the current time zone.
Listing 61. Setting time zone with tzconfig
root@pinguino:~# tzconfig
Your current time zone is set to America/New_York
Do you want to change that? [n]:
Your time zone will not be changedConfigure the Network Time Protocol
The Network Time Protocol ( NTP ) is a protocol to synchronize computer clocks over a network. Synchronization is usually to UTC.
NTP version 3 is an Internet draft standard, formalized in RFC 1305. The current development version, NTP version 4 is a significant revision, which has not been formalized in an RFC. RFC 4330 describes Simple NTP (SNTP) version 4.
Time synchronization is accomplished by sending messages to time servers . The time returned is adjusted by an offset of half the round-trip delay. The accuracy of the time is therefore dependent on the network latency and the extent to which the latency is the same in both directions. The shorter the path to a time server, the more accurate the time is likely to be. See Related topics for more detailed information than this simplistic description can provide.
There is a huge number of computers on the Internet, so time servers are organized into strata . A relatively small number of stratum 1 servers maintain very accurate time from a source such as an atomic clock. A larger number of stratum 2 servers get their time from stratum 1 servers and make it available to an even larger number of stratum 3 servers, and so on. To ease the load on time servers, a large number of volunteers donate time services through pool.ntp.org (see Related topics for a link). Round robin DNS servers accomplish NTP load balancing by distributing NTP server requests among a pool of available servers.
If you use a graphical interface, you might be able to set your NTP time servers using a dialog similar to that in Figure 4. The fact that this system has enabled automatic time updates using NTP is why the dialog in Figure 3 did not allow the date and time to be changed.
Figure 4. Setting NTP servers
NTP configuration information is kept in /etc/ntp.conf, so you can also edit that file and then restart the ntpd daemon after you save it. Listing 62 shows an example /etc/ntp.conf file using the time servers from Figure 4.
Listing 62. Setting time zone with tzconfig
[root@lyrebird ~]# cat /etc/ntp.conf
# Permit time synchronization with our time source, but do not
# permit the source to query or modify the service on this system.
restrict default kod nomodify notrap nopeer noquery
# Permit all access over the loopback interface. This could
# be tightened as well, but to do so would effect some of
# the administrative functions.
restrict 127.0.0.1
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#broadcast 192.168.1.255 key 42 # broadcast server
#broadcastclient # broadcast client
#broadcast 224.0.1.1 key 42 # multicast server
#multicastclient 224.0.1.1 # multicast client
#manycastserver 239.255.254.254 # manycast server
#manycastclient 239.255.254.254 key 42 # manycast client
# Undisciplined Local Clock. This is a fake driver intended for backup
# and when no outside source of synchronized time is available.
#server 127.127.1.0 # local clock
#fudge 127.127.1.0 stratum 10
# Drift file. Put this in a directory which the daemon can write to.
# No symbolic links allowed, either, since the daemon updates the file
# by creating a temporary in the same directory and then rename()'ing
# it to the file.
driftfile /var/lib/ntp/drift
# Key file containing the keys and key identifiers used when operating
# with symmetric key cryptography.
keys /etc/ntp/keys
# Specify the key identifiers which are trusted.
#trustedkey 4 8 42
# Specify the key identifier to use with the ntpdc utility.
#requestkey 8
# Specify the key identifier to use with the ntpq utility.
#controlkey 8
server 0.us.pool.ntp.org
restrict 0.us.pool.ntp.org mask 255.255.255.255 nomodify notrap noquery
server 1.us.pool.ntp.org
restrict 1.us.pool.ntp.org mask 255.255.255.255 nomodify notrap noquery
server 2.us.pool.ntp.org
restrict 2.us.pool.ntp.org mask 255.255.255.255 nomodify notrap noqueryIf you are using the pool.ntp.org time servers, these may be anywhere in the world. You will usually get better time by restricting your servers as in this example where us.pool.ntp.org is used, resulting in only US servers being chosen. See Related topics for more information on the ntp.pool.org project.
NTP commands
You can use the ntpdate command to set your system time from an NTP time server as shown in Listing 63.
Listing 63. Setting system time from an NTP server using ntpdate
[root@lyrebird ~]# ntpdate 0.us.pool.ntp.org
10 Jul 10:27:39 ntpdate[15308]: adjust time server 66.199.242.154 offset -0.007271 sec Because the servers operate in round robin mode, the next time you run this command you will probably see a different server. Listing 64 shows the first few DNS responses for 0.us.ntp.pool.org a few moments after the above ntpdate command was run.
Listing 64. Round robin NTP server pool
[root@lyrebird ~]# dig 0.pool.ntp.org +noall +answer | head -n 5
0.pool.ntp.org. 1062 IN A 217.116.227.3
0.pool.ntp.org. 1062 IN A 24.215.0.24
0.pool.ntp.org. 1062 IN A 62.66.254.154
0.pool.ntp.org. 1062 IN A 76.168.30.201
0.pool.ntp.org. 1062 IN A 81.169.139.140 The ntpdate command is now deprecated as the same function can be done using ntpq with the -q option, as shown in Listing 65.
Listing 65. Setting system time using ntpd -q
[root@lyrebird ~]# ntpd -q
ntpd: time slew -0.014406s Note that the ntpd command uses the time server information from /etc/ntp.conf, or a configuration file provided on the command line. See the man page for more information and for information about other options for ntpd . Be aware also that if the ntpd daemon is running, ntpd -q will quietly exit, leaving a failure message in /var/log/messages.
Another related command is the ntpq command, which allows you to query the NTP daemon. See the man page for more details.
This brings us to the end of this tutorial. We have covered a lot of material on system administration.
翻译自: https://www.ibm.com/developerworks/linux/tutorials/l-lpic1111/index.html
全国行政区划代码到行政村