白话JAVA集合类
趁着要毕业,好好的总结了一下,把以前做的笔记放上来,防止自己不小心丢失。
在java中集合的使用很是频繁,要合理的使用还是要明白其中的异同。
1、简介:
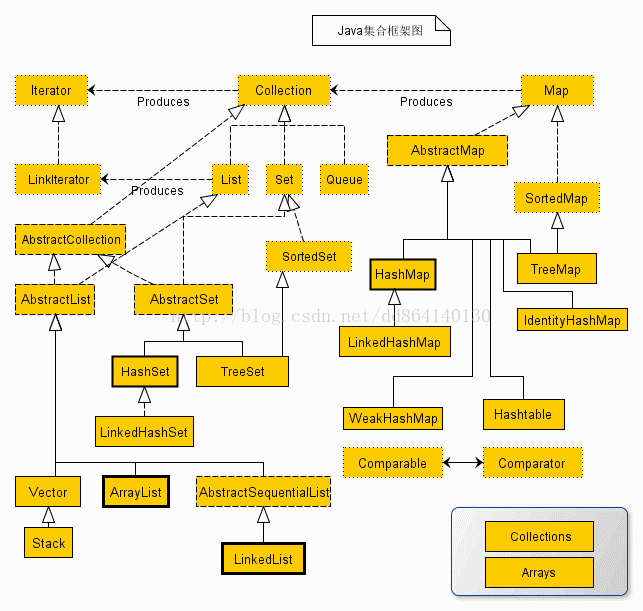
我们发现集合类都实现了Iterator接口,也就意味着所有的集合类都是可迭代输出。同时注意抽象类的使用。如果要自己实现一个集合类,去实现那些抽象的接口(因为接口中方法太多)会非常麻烦,工作量很大。这个时候就可以使用抽象类,这些抽象类中给我们提供了许多方法现成的实现,我们只需要根据自己的需求重写一些方法或者添加一些方法就可以实现自己需要的集合类,工作流昂大大降低。
(一般来说,当一个接口中的方法非常多时,一般会用抽象类实现此接口,并实现其中的一些方法,我们在自己实现集合类的时候只需要继承抽象类,重写少量方法即可)
以Collection为接口的元素集合类型,以Map为接口的映射集合类型 . 所有集合的实现类都不是直接实现集合类接口,而是都继承一个相应的抽象类。
Collection类型又分为两大类Set和List
Java中集合类定义主要是在java.util.*包下面,常用的集合在系统中定义了三大接口,这三类的区别是:
java.util.Set接口及其子类,set提供的是一个无序集;
java.util.List接口及其子类,List提供的是一个有序集;
java.util.Map接口及其子类,Map提供了一个映射关系的集合数据结构;
每种集合都可以理解为用来在内存中存放一组对象的某种“容器”。
2、详细
java.util.List接口的实现类的特点和用法:
List接口提供了多个实现的子类,其实现类有ArrayList,LinkedList,这两个都是非线程安全的,Vector是线程安全的List实现类(sun公司不建议使用了),Stack是vector的子类。ArrayList的内部实现是基于内部数组Object[],所以从概念上讲,它更像数组,但LinkedList的内部实现是基于一组连接的记录,所以它更像一个链表结构。在ArrayList的前面或中间插入数据时,必须将其后的所有数据相应的后移,这样必然要花费较多时间。因此,当你的操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;而访问链表中的某个元素时,就必须从链表的一端开始沿着连接方向一个一个元素地去查找,直到找到所需的元素为止,所以,当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。 Queue也是Collection的子接口,也就是我们所说的队列,默认采用的是先进先出。由于LinkedList实现了Queue和List接口,因此建议直接使用LinkedList。
常用的实现类是java.util.Vector和java.util.ArrayList,现在以java.util.ArrayList为例来说明List的特点及用法,具体代码示例如下:
public class ArrayListTest {
public static void main(String args[]){
java.util.ArrayList list =new java.util.ArrayList();
//向队列中添加元素
for (int i=0;i<10;i++){
String str = "学生"+i;
list.add(str);
}
//遍历1
for (int i=0;i itr =list.iterator();
//判断是否有数据可以迭代
while(itr.hasNext()){
//取出一个元素
String str = itr.next();
System.out.print(str+"\t");
}
System.out.println();
//遍历3
for (Stringstr:list){
System.out.print(str+"\t");
}
}
} 运行结果:
学生0 学生1 学生2 学生3 学生4 学生5 学生6 学生7 学生8 学生9
学生0 学生1 学生2 学生3 学生4 学生5 学生6 学生7 学生8 学生9
学生0 学生1 学生2 学生3 学生4 学生5 学生6 学生7 学生8 学生9
以上程序是先创建一个队列对象list,然后以有序的元素添加到该队列中,随后是通过三种不同的方式遍历该队列的:第一种是通过下标值来遍历队列的,打印出来的队列也是有序的;第二种遍历是通过迭代器依次输出元素,打印出的元素也是有序的。通过第二种遍历方式就可以说明队列是有序的,同时这两种遍历方式也都说明了队列是线性的。第三种遍历方式是在java中特有的遍历方式。
下面再把上面的代码做稍微的修改,如下所示:
public class ArrayListTest {
public static void main(String args[]){
java.util.ArrayList list =new java.util.ArrayList();
//向队列中添加元素
for (int i=0;i<15;i++){
String str = "学生"+i;
list.add(str);
}
list.add("新同学");
list.add("新同学");
list.add("新来的");
//遍历1
for (int i=0;i itr =list.iterator();
//判断是否有下一个数据可以迭代
while(itr.hasNext()){
//取出一个元素
String str = itr.next();
System.out.print(str+"\t");
}
System.out.println();
//遍历3
for (String str:list){
System.out.print(str+"\t");
}
}
} 运行结果:
学生0 学生1 学生2 学生3 学生4 学生5 学生6 学生7 学生8 学生9 学生10 学生11 学生12 学生13 学生14 新同学 新同学 新来的
学生0 学生1 学生2 学生3 学生4 学生5 学生6 学生7 学生8 学生9 学生10 学生11 学生12 学生13 学生14 新同学 新同学 新来的
学生0 学生1 学生2 学生3 学生4 学生5 学生6 学生7 学生8 学生9 学生10 学生11 学生12 学生13 学生14 新同学 新同学 新来的
以上程序添加是在队列中添加了新的元素,并且有添加相同的元素,从运行结果可知,队列是长度可变的,可以有相同重复的元素。
队列的特点是线性的,有序的,长度可变的,有下标值的,元素可重复的。
Java.util.Set接口的实现类的特点及用法:
Set接口也是Collection接口的子接口,与Collection或List接口不同的是,Set接口中不能加入重复元素,同时Set接口的实例无法像List接口(Collection本身就不能进行双向输出)一样双向输出。Set接口常用的子类有java.util.HashSet(散列存放)、java.util.TreeSet(有序存放);两者都是非线程安全的。
TreeSet实际上也是SortedSet接口的子类,此接口的所有类都是可以排序的。以后遇到Sorted开头的基本上都是可以排序的。
这里以HashSet为例说明它的特点及用法,请看下面代码示例:
public class HashSetTest {
//主函数
public static void main(String args[]){
java.util.HashSet set = newjava.util.HashSet();
//向集合中添加元素
for (int i=0;i<10;i++){
String str = "学生"+i;
set.add(str);
}
//遍历1
java.util.Iterator iter =set.iterator();
while(iter.hasNext()){
String str = iter.next();
System.out.print(str+"\t");
}
System.out.println();
//遍历2
for (String str:set){
System.out.print(str+"\t");
}
}
} 运行结果:
学生0 学生9 学生7 学生8 学生5 学生6 学生3 学生4 学生1 学生2
学生0 学生9 学生7 学生8 学生5 学生6 学生3 学生4 学生1 学生2
通过第一种遍历方式打印出来的元素是无序的,说明集合的特点是无序的。下面再在上面的代码的基础上添加新的元素,代码如下:
public class HashSetTest {
public static void main(String args[]){
java.util.HashSet set = newjava.util.HashSet();
//向集合中添加元素
for (int i=0;i<10;i++){
String str = "学生"+i;
set.add(str);
}
set.add("新来的");
set.add("新同学");
//遍历1
java.util.Iterator iter =set.iterator();
while(iter.hasNext()){
String str = iter.next();
System.out.print(str+"\t");
}
System.out.println();
//遍历2
for (String str:set){
System.out.print(str+"\t");
}
}
} 学生0 新同学 学生9 学生7 学生8 新来的 学生5 学生6 学生3 学生4 学生1 学生2
学生0 新同学 学生9 学生7 学生8 新来的 学生5 学生6 学生3 学生4 学生1 学生2
从运行结果中可知集合和队列一样,长度也是可以变的。
下面在修改以上代码,向集合中添加相同的元素,如下所示:
public class HashSetTest {
public static void main(String args[]){
java.util.HashSet set = newjava.util.HashSet();
for (int i=0;i<10;i++){
String str = "学生"+i;
set.add(str);
}
set.add("新来的");
set.add("新同学");
set.add("新同学");
//遍历1
java.util.Iterator iter =set.iterator();
while(iter.hasNext()){
String str = iter.next();
System.out.print(str+"\t");
}
System.out.println();
//遍历2
for (String str:set){
System.out.print(str+"\t");
}
}
}
运行结果:
学生0 新同学 学生9 学生7 学生8 新来的 学生5 学生6 学生3 学生4 学生1 学生2
学生0 新同学 学生9 学生7 学生8 新来的 学生5 学生6 学生3 学生4 学生1 学生2
运行结果是和上面一样的,说明重复的元素只能够添加一个,但是到底添加了哪一个呢?我们通过打印来看,代码如下:
public class HashSetTest {
public static void main(String args[]){
ava.util.HashSet set = newjava.util.HashSet();
for (int i=0;i<10;i++){
String str = "学生"+i;
set.add(str);
}
set.add("新来的");
boolean st1 = set.add("新同学");
boolean st2 = set.add("新同学");
System.out.println(st1+"<>"+st2);
//遍历1
java.util.Iterator iter =set.iterator();
while(iter.hasNext()){
String str = iter.next();
System.out.print(str+"\t");
}
System.out.println();
//遍历2
for (String str:set){
System.out.print(str+"\t");
}
}
} 运行结果:
true<>false
学生0 新同学 学生9 学生7 学生8 新来的 学生5 学生6 学生3 学生4 学生1 学生2
学生0 新同学 学生9 学生7 学生8 新来的 学生5 学生6 学生3 学生4 学生1 学生2
从运行结果来看,添加的是第一个相同的元素。
从以上的代码运行的结果中可知道,集合的特点是长度可变的,无序的,元素是不重复的。
Java.util.Map接口的特点及用法:
Java提供了专门的集合类用来存放映射对象的,即Java.util.Map接口。Map中存入的对象是一对一对的,即每个对象和它的一个键关联在一起。从API文档中可知,Map中存放的是两种对象,一种称为key(键),一种称为value(值),他们在Map中是一一对应关系。Map中的键是不能重复的,但值是可以重复的。Map中key的集合本质上为Set。Map是一个接口,有多种具体的实现类,常用的有
HashMap:无序存放,key不许重复
Hashtable:无序存放,key不许重复,是线程安全的,不建议使用了
TreeMap:可以排序,按照key排序,key不许重复
WeakHashMap:弱引用的map集合,集合中某些数据不使用时,可以自动清除掉无用数据,可使用gc进行回收
IdentityHashMap:key可以重复的map集合
(注意:如果使用自定义类作为Map中的key时,则必须重写Object类中的hashCode和equals两个方法。)
下面以java.util.HashMap为例说明它的特点及用法,请看下面的示例代码:
public class HashMapTest {
//主函数
public static void main(String args[]){
//创建一个映射对象
java.util.HashMap map= new java.util.HashMap();
//装入键值对
for (int i=0;i<10;i++){
int key = i*1000;
String value = "学生"+i;
map.put(key,value);
}
//遍历
//得到K的set集合
java.util.Set set = map.keySet();
//遍历K的集合,得到K的迭代器对象
java.util.Iterator iter =set.iterator();
while(iter.hasNext()){
int num = iter.next();
String str = map.get(num);
System.out.println(num+"\t"+str);
}
}
} 运行结果:
0 学生0
1000 学生1
2000 学生2
3000 学生3
4000 学生4
5000 学生5
6000 学生6
7000 学生7
8000 学生8
9000 学生9
上面的程序是向映射中添加入有序的元素,打印出的也是有序的元素,从运行的结果看,认为映射是有序的,但是稍微改一下程序,元素顺序结果就不一样了,代码如下:
public class HashMapTest {
//主函数
public static void main(String args[]){
//创建一个映射对象
java.util.HashMap map= new java.util.HashMap();
//装入键值对
for (int i=0;i<15;i++){
int key = i*1000;
String value = "学生"+i;
map.put(key, value);
}
//遍历
//得到K的set集合
java.util.Set set =map.keySet();
//遍历K的集合,得到K的迭代器对象
java.util.Iterator iter =set.iterator();
while(iter.hasNext()){
int num = iter.next();
String str = map.get(num);
System.out.println(num+"\t"+str);
}
}
} 运行结果:
0 学生0
11000 学生11
13000 学生13
2000 学生2
4000 学生4
6000 学生6
8000 学生8
10000 学生10
1000 学生1
12000 学生12
3000 学生3
14000 学生14
5000 学生5
7000 学生7
9000 学生9
从上面的运行结果可知,映射也是种无序的集合。
像上面的集合一样向映射中添加重复相同的元素,代码如下:
public class HashMapTest {
//主函数
public static void main(String args[]){
//创建一个映射对象
java.util.HashMap map= new java.util.HashMap();
//装入键值对
for (int i=0;i<10;i++){
int key = i*1000;
String value = "学生"+i;
map.put(key, value);
}
map.put(1234,"新同学");
map.put(1234,"新来的");
map.put(4321,"新来的");
map.put(4321,"新同学");
//遍历
//得到K的set集合
java.util.Set set = map.keySet();
//遍历K的集合,得到K的迭代器对象
java.util.Iterator iter =set.iterator();
while(iter.hasNext()){
int num = iter.next();
String str = map.get(num);
System.out.println(num+"\t"+str);
}
}
} 运行结果:
0 学生0
1000 学生1
2000 学生2
3000 学生3
4000 学生4
1234 新来的
5000 学生5
6000 学生6
7000 学生7
8000 学生8
9000 学生9
4321 新同学
从运行结果来看,映射的元素也是不可重复的如果加入相同的键值对时,则会替换掉原来的键值对。总结来说,映射的特点是:一个K对应一个V,K是一个set集合,是不可重复的,无序的,如果加入相同K的键值对时,则会替换原来的键值对。
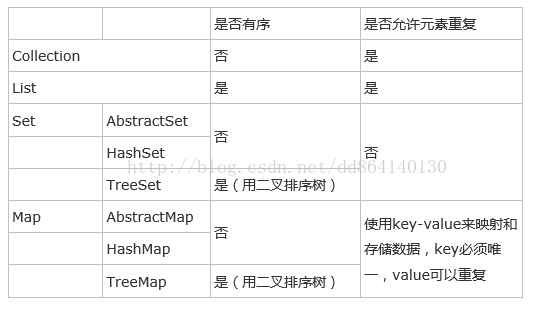
最后我们做一下比较,见下图:
另外我们来简单的说一下集合元素输出方式
1、 Iteartor
2、 ListIterator
3、 Foreache输出
4、 Enumeration输出
(注意使用集合元素的标准输出是使用Iterator接口)
Iterrator使用迭代方式(从前往后,单向输出)输出,即每次判断下一个元素是否存在,存在则取出。由于其本事是一个接口,所以实例化必须依靠Collection接口完成。Iterator本身提供了remove()方法,而List集合中同样提供了remove()方法,但是在迭代过程中只能使用Iterator接口提供的remover方法,否则将出错。值得注意的是Iterator主要的功能就是迭代输出,在迭代的时候最好不要删除数据。
ListIterator是Iterator的子接口,扩充了Iterator的功能,主要提供了双向输出:由前往后或者由后往前(注意如果要执行由后往前输出,必须先进行由前往后输出,才可以)。但是Collection接口中没有定义ListIterator的实例化操作,只有List接口中才定义了ListIterator接口的实例化操作。
Jdk 1.5之后增加了foreach,既支持数组输出也支持集合的输出操作。Enumeration输出只存在早起的jdk当中,旧的的接口。实际上Iterator属于一个新的输出接口,用来代替Enumeration。注意Enumeration一般用来执行Vector的输出。(现在基本不再使用)
在实际开发过程中,往往会遇到在遍历List的过程中需要删除符合某种业务规则的数据元素,如果不了解其中里边的机制就容易导致程序错误。下面通过代码分析一下:
采用遍历下标的方式: public class ListRemoveTest {
public static void main(String[] args) { List list = new ArrayList();
list.add(1);
list.add(2);
list.add(2);
list.add(3);
list.add(4);
for (int i = 0; i < list.size(); i++) {
if (2 == list.get(i)) {
list.remove(i);
}
System.out.println(list.get(i));
}
System.out.println("最后结果=" + list.toString());
}
}
运行结果:
1
2
3
4
最后结果=[1, 2, 3, 4]
我们想删除List中所有等于2的元素,但结果显示只删除了一个2,另一个2被遗漏了,这是为什么呢?
实际上我们删除了第一个2后,集合里的元素个数减1,后面的元素往前移了1位,导致了第二个2被遗漏了,因此这种方式不能准确的删除元素。
采用For循环遍历的方式 public class ListRemoveTest {
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(2);
list.add(3);
list.add(4);
for (Integer value : list) {
if (2 == value) {
list.remove(value);
}
System.out.println(value);
}
System.out.println("最后结果=" + list.toString());
}
}
运行结果:
1
2
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:819)
at java.util.ArrayList$Itr.next(ArrayList.java:791)
at ListRemoveTest.main(ListRemoveTest.java:12)
从运行结果看到程序抛ConcurrentModificationException。
JDK的API中对该异常描述道:
public class ConcurrentModificationException extendsRuntimeException当方法检测到对象的并发修改,但不允许这种修改时,抛出此异常。
例如,某个线程在 Collection 上进行迭代时,通常不允许另一个线性修改该 Collection。通常在这些情况下,迭代的结果是不确定的。如果检测到这种行为,一些迭代器实现(包括 JRE 提供的所有通用 collection 实现)可能选择抛出此异常。执行该操作的迭代器称为快速失败 迭代器,因为迭代器很快就完全失败,而不会冒着在将来某个时间任意发生不确定行为的风险。
注意,此异常不会始终指出对象已经由不同 线程并发修改。如果单线程发出违反对象协定的方法调用序列,则该对象可能抛出此异常。例如,如果线程使用快速失败迭代器在 collection 上迭代时直接修改该 collection,则迭代器将抛出此异常。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败操作会尽最大努力抛出 ConcurrentModificationException。因此,为提高此类操作的正确性而编写一个依赖于此异常的程序是错误的做法,正确做法是:ConcurrentModificationException 应该仅用于检测 bug。
Java中的For each实际上使用的是iterator进行处理的。而iterator是不允许集合在iterator使用期间删除的。所以导致了iterator抛出了ConcurrentModificationException 。
public class ListRemoveTest {
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(2);
list.add(3);
list.add(4);
Iterator it = list.iterator();
while (it.hasNext()) {
Integer value = it.next();
if (2 == value) {
it.remove();
}
System.out.println(value);
}
System.out.println("最后结果=" + list.toString());
}
}
最后结果=[1, 3, 4]
这时候我么发现两个2全部被删除了,最后结果剩下1,3,4完全正确。这意味着我们如果需要在遍历的过程删除元素,应该使用Iterator。但Iterator真的安全么?
在使用iterator的remove()方法,需要注意一下几点:
1、每调用一次iterator.next()方法,只能调用一次remove()方法。
2、remove()必须放在next()方法之后。
3、使用的Iterator中的remove()方法,而不是list中的remove()方法,否则会出错。
查看一下JDK-API中对于remove()方法的描述:
void remove()
- 从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。每次调用 next 只能调用一次此方法。如果进行迭代时用调用此方法之外的其他方式修改了该迭代器所指向的 collection,则迭代器的行为是不确定的。
-
- 抛出:
-
UnsupportedOperationException- 如果迭代器不支持 remove 操作。 -
IllegalStateException- 如果尚未调用 next 方法,或者在上一次调用 next 方法之后已经调用了 remove 方法
总结:遍历过程中删除元素是危险的,只能采用Iterator的方式进行删除。(注意:强烈不建议在遍历一个集合的过程中删除元素)
集合工具类Collections
Collections常用的方法:
a、验证 空集合的操作:
emptyList();
emptySet();
b、为集合添加元素:
add(Collection c,T…elements);
c、二分检索:
BinarySearch(List> list,T key);
List all =newArrayList();
Collections.addAll(all,”cao”,”nima”,”caodang”,”hah”);
Int point=Collections.binarySearch(all,”LXH”);
System.out.println(“检索结果:”+point); d、替换内容:
ReplaceAll(List
e、排序操作:
sort(List
(注意如果要进行排序的话,则对象所在的类必须实现Comparable)
[i] 对象的引用强度说明
从jdk1.2开始,java将对象的引用分为四种级别:
1、 强引用:当内存不足时,jvm宁可出现OutOfMemeryError错误从而使程序终止,也不会回收对象来释放空间。
代码中普遍存在,类似”ObjectobjectRef=new Object”这种引用
2、 软引用:内存不足(内存溢出之前)时,会回收这些对象的内存,用来实现内存敏感的告诉缓存。
通过SoftReference类来实现软引用,SoftReference很适合来实现缓存。当gc扫描到某个SoftReference不经常使用时,可能会进行回收。
User user = new User();
SoftReference3、 弱引用:无论内存是否紧张,一被垃圾回收器发现就立即回收。
通过WeakReference类来实现
User user = new User();
WeakReferenceweakReference = new WeakReference(user);
weakReference.get();
ReferenceQueuereferenceQueue = new ReferenceQueue();
WeakReferenceweakReference2 = new WeakReference(user, referenceQueue);
//当引用对象被标识为可回收时 返回true, 即当user对象标识为可回收时,返回true
weakReference.isEnqueued(); 4、 虚引用:和没有任何引用一样