(以下内容引用于生信星球)

学习内容
第一个R包--tidyr
准备工作:
1.1. 学会获取一个R包的小抄
方法1:去百度/谷歌XX小抄
方法2:找Rstudio的cheatsheet网站(网速慢)
https://www.rstudio.com/resources/cheatsheets/
方法3.教程里用到的包都可以到生信星球公众号回复相应的包名来获取
1.2. 初步了解tidy
这是一个数据处理的起步,属于R包里简单的。
主要功能:
(1)数据框的变形
(2)处理数据框中的空值
(3)根据一个表格衍生出其他表格
(4)实现行或列的分割和合并
这个包是把你要用的数据处理成标准而统一的数据框(Tidy Data),才能进行进一步的数据处理和作图。
1.3. 学习极简安装R包
- 准备好Rstudio(恭喜你跳过了安装的坑),设置好工作目录。在控制台输入:library(tidyr),如果你没有这个包,就会报错:
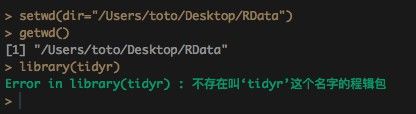
2. 下载和安装tidier
解决方案:换一个国内的镜像(因为前几天设置的时候就已经换上国内的镜像,所以没有报错)
install.packages("tidy")
(这里会默认安装到你的工作目录里,下载很慢,只要控制台不出现>,就一直等着)
可能出现报错:
3. 加载tidier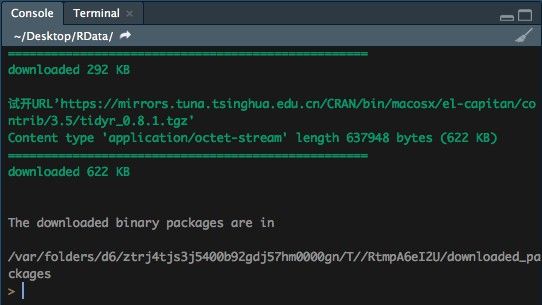
library(tidyr) (没有报错就是成功)
2.1 数据框的小常识
1.新建数据框(这里直接把新建的数据框赋值给了a)
a<-data.frame(GeneId = rep("gene5",times=3),SampleName =paste("Sample",1:3,sep=""),Expression=c(14,19,18))

新建一个数据框并赋值给bioplanet这个变量(赋值符号<-)括号里是“列名”=列值,这里列名要加双引号。这里涉及的几个给列填充数值的函数有
rep重复,括号中填要重复的字符和重复次数。
paste连接两个字符串,括号要填两个代连接字符并指定分隔符(sep),没有分隔符就填sep=“”。
1:3表示从1到三。如需一列中需要填入三个无规律的数字,可以用向量c(1,3,4)同样如果填的是字符串也需要加双引号,例如c("aaa",bbb","ccc")。
2.了解概念
key-value--“键值对” ,表示一种对应关系。“键”和“值”都是列名,如SampleName和Expression的对应。
3.函数后面一般都要加括号,括号里第一个参数是都数据框名
4.字符串要加双引号(行名和列名也是字符串,但是可以不用加),其他单元格里出现的字符串要加。
行 raw
列 column,简化写法为col
3.1 认识Tidy Data
这是一种组织表格数据的方式,提供了一种能够跨包使用的“统一”的数据格式。
什么叫“统一”?
每个变量(variable)占一列,每个情况(case)和观测值(observation)占一行。

1.Reshape Data
gather:把宽度较大的数据转换成一个更长的形式,它类比于从reshape2包中融合函数的功能。
spread:把长的数据转换成一个更宽的形式,它类比于从reshape2包中铸造函数的功能。
(下面的类似截图都是来自小抄)


a<-data.frame(Country=c("A","B","C"),"1999"=paste(c(0.7,37,212),"K",sep=""),"2000"=paste(c(2,80,213),"k",sep=""))

由于它自动加了X,写列名的时候就不能按照小抄上面写,而是:
gather(a,X1999,X2000,key = "year",value = "cases")
gather括号里的分别是:
数据框名,需合并的列名(两个),合并后的key列名,value列名。
其中,需合并的列名也可以列在最后(其实个顺序才是默认的),key=和value=也可以省略),如果按照上面小抄的命令括号里那个顺序,省略了就会报错。
gather(a,"year","cases",X1999,X2000) #推荐的偷懒做法

其中,合并前的列名如果比较多,可以用排除法来偷懒,在上图例子中可用
gather(a,year,cases,-Country) #-Country的意思就是合并除country外剩下的列。
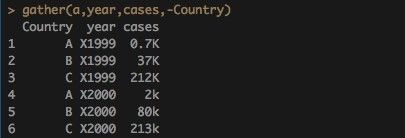
2.Handle Missing Values
处理丢失的数据。就是某些单元格有空值的情况。
三种处理方式:
(1).删除整行
(2).根据上下文(瞎)蒙一个
(3).同一列的空值填上同一个数。

将示例数据放在你的RData文件夹下(重要!)
NA表示空值,所以新建的时候像我一样空着就好。
用以下命令即可获得图示数据框X
X<-read.csv('doudou.txt')
csv的导入和导出方式。
导入:X<-read.csv('doudou.csv')
导出:write.csv(X,'doudou.csv')
drop_na():有空值的,整行删除掉
括号里填数据框名,依据的列名(有空值那一列的列名)
drop_na(X,X2)
fill(),根据上一行的数值填充上(好应付的感觉)
fill(X,X2)
replace_na(),空值填进去特定的一个数值,
括号里填数据框名,要填的列名=要填的值
replace_na(X,list(X2=2))

3. Expand Tables
complete(把空值的位置补全)

可以直接用刚才的数据框X填充一下试试。比如填5
> complete(X,nesting(X1),fill=list(X2=5))

expand
列出每列值所有可能的组合
示例数据(就是刚才新建出来的数据框a):
pin2<-data.frame(GeneId = rep("gene5",times=3),SampleName =paste("Sample",1:3,sep=""),Expression=c(14,19,18))
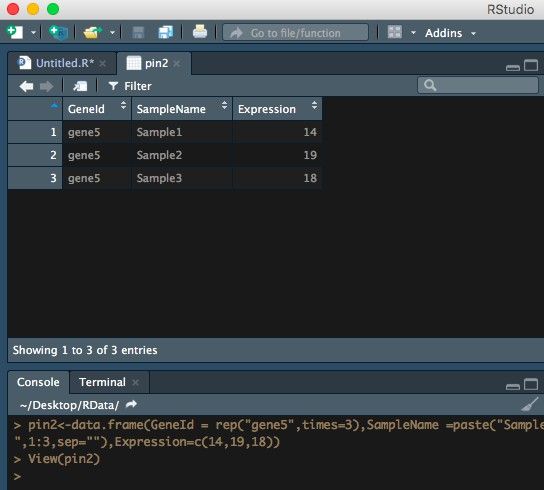

就是选中的列中的值各种组合,成为一个新表。
4.split cells
把一列拆成两列。目测原列必须要有分隔符才行。
separate:按列分割
separate_rows:按行分割

unite:分割完了再合并回去