TensorFlow入门 | 人脸检测与识别
人脸识别概述
人脸识别,特指利用分析比较人脸视觉特征信息进行身份鉴别的计算机技术。属于生物特征识别技术的一种。
广义的人脸识别实际包括构建人脸识别系统的一系列相关技术,包括人脸图像采集、人脸定位、人脸识别预处理、身份确认以及身份查找等;而狭义的人脸识别特指通过人脸进行身份确认或者身份查找的技术或系统。
人脸识别典型流程
典型流程分为3个步骤:
1)人脸检测: 对图像中人脸位置的检测
2)人脸对齐: 对人脸的位置进行矫正居中
3)人脸特征表示:用深度网络学习高维特征
人脸检测算法简介
人脸检测的目标是找出图像中所有的人脸所对应的位置,算法的输出是人脸外接矩形在图像中的坐标,可能还包括姿态如倾斜角度等信息。
人脸检测算法研究分为3个发展阶段:
- 基于模板匹配的算法
- 基于AdaBoost的框架
- 基于深度学习的算法
一、基于模板匹配的人脸检测算法
用一个人脸模板与被检测图像中的各个位置进行匹配,确定这个位置是否有人脸。即针对图像中某个区域进行人脸-非人脸二分类的判别。
二、基于AdaBoost框架的人脸检测算法
Boost算法是基于PAC(Probably Approximately Correct)学习理论而建立的一套集成算法。Boost的核心思想就是利用多个简单的若干分类器,构建出准确率高的强分类器。
三、基于深度学习算法的人脸检测算法
CNN应用在人脸检测后,在精度上大幅度超越了之前的AdaBoost框架。
Cascade CNN 是传统技术和深度网络结合的一个代表。其包含了多个分类器,这些分类器采用级联结构进行组织,用卷积网络作为每一级的分类器。
人脸识别算法简介
人脸识别算法的研究分为3个发展阶段:
- 早期算法:基于几何特征、模板匹配、子空间等
- 人工特征+分类器
- 基于深度学习的算法
一、早期算法
线性降维:(子空间算法)将人脸图像当作一个高维向量,将其投影到低维空间后,期望得到的低维向量对不同的人具有区分度。
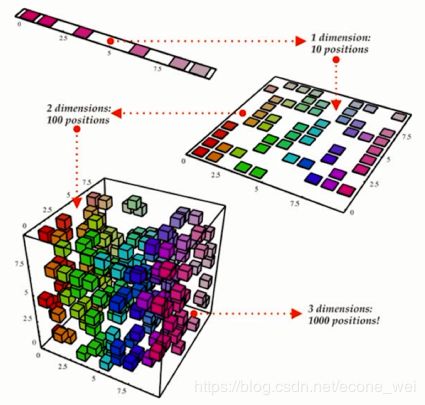
非线性降维:(流形学习)假设向量点在高维空间中的分布具有某些几何形状,然后在保持这些几何形化约束的前提下将向量投影到低维空间中。
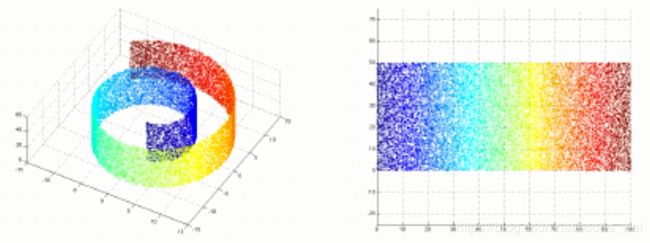
二、人工特征+分类器
比较成熟的分类器如逻辑回归、贝叶斯、支持向量机、神经网络等。用于人脸识别的计算机视觉中描述图像的特征如 HOG、SIFT、Gabor、LBP等。
三、基于深度学习的人脸识别算法
主要两个经典模型:Facebook 在 CVPR 2014 发布的 DeepFace 和 Google 在CVPR 2015 发布的 FaceNet。
DeepFace
DeepFace是深度卷积神经网络在人脸识别领域的奠基之作。使用3D模型来解决人脸对齐问题,同时又使用了9层深度网络来做人脸特征表示。损失函数使用了Softmax Loss,最后通过特征嵌入(Feature Embedding)得到固定的人脸特征向量。DeepFace在LFW上取得了97.35%的准确率。
模型架构如图:

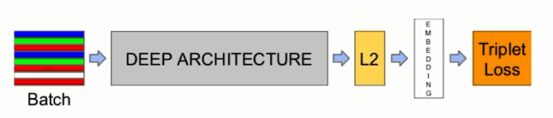
FaceNet
Google提出了使用三元组损失函数(Triplet Loss)代替Softmax Loss。在一个超球空间上进行优化使类内距离更紧凑,类间距离更远,最后得到了一个紧凑的128维人脸特征,其网络使用 GoogleNet 的 Inception 模型,模型参数量更小,精度更高。FaceNet 是一个解决人脸识别和人脸聚类问题的全新深度神经网络架构,其在LFW(Labeled Faces in the Wild)人脸识别数据集上十折平均精度达到99.63%。
模型架构如下:
人脸检测工具介绍
OpenCV
开源计算机视觉库(Open Source Computer Vision Library,OpenCV),遵从BSD协议许可,具有C++,Python和Java接口,支持Windows,Linux,Mac OS,iOS 和Android。OpenCV专为提高效率而设计,专注于实时应用。该库以优化的C/C++编写,通过OpenCL可以启用多核处理和硬件加速模式。
安装OpenCV的Python接口:pip3 install opencv-python
实现(基于OpenCV API)
import cv2
import sys
## Get user supplied values
# 获取图片路径
imagePath = sys.argv[1]
# 已经下载好的正面人脸特征值(.xml文件)
cascPath = "haarcascade_frontalface_default.xml"
## Create the haar cascade
# 应用cascade分类器
faceCascade = cv2.CascadeClassifier(cascPath)
## Read the image
# 如果有错误,下面这行代码改成相对路径形式加载图片 "iamge = cv2.imread('./test_face_detection.jpg')"
image = cv2.imread(imagepath)
# 用cv2的COLOR_BGR2GRAY方法转变为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
## Detect faces in the image
# 用分类器的detectMultiScale方法来检测人脸,默认参数
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30)
)
# len(faces):人脸框的个数
print("Found {0} faces!".format(len(faces)))
## Draw a rectangle around the faces
# (x,y):矩形框左上角的坐标,w:矩形框的宽度,h:矩形框的高度
# 利用左上角和右下角的坐标画矩形框,(0,255,0)是RGB三通道,此处表示绿色框
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
# ”Faces found“ 图像文件取名
cv2.imshow("Faces found", image)
# 设置窗口停留(无限长延时)
cv2.waitKey(0)

face_recongnition库进行人脸检测
使用Dlib(一个包含机器学习算法的C++开源工具包)最先进的面部识别功能构建而成,具有深度学习功能。支持批处理。该模型在LFW上的准确率为99.38%。
安装:pip3 install face_recognition
Notes:安装 face_recognition之前需要安装依赖库 cmake、dlib。
实现(基于 face_recognition)
import cv2
import sys
import face_recognition
# Get user supplied values
imagePath = sys.argv[1]
# Load the image with face_recognition
image = face_recognition.load_image_file(imagePath)
# Detect faces in the image(face_location方法)
face_locations = face_recognition.face_locations(image)
print("Found {0} faces!".format(len(face_locations)))
# Read the image with openCV
image = cv2.imread(imagePath)
# Draw a rectangle around the faces
# (top,right,bottom,left):分别是上、右、底、左的坐标。如左上角坐标(left, top)
for (top, right, bottom, left) in face_locations:
cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2)
cv2.imshow("Faces found", image)
cv2.waitKey(0)

比较
前面用 OpenCV API 实现中的cascade特征是一个正面特质,也就是所用特征就不全,所以检测效果就不太好。face_recognition 的效果就相对好一点。
两种API返回的检测框的坐标也不一样。前者是左上角的坐标和检测框的宽高,后者是检测框上下左右的坐标位置。
FaceNet模型解析
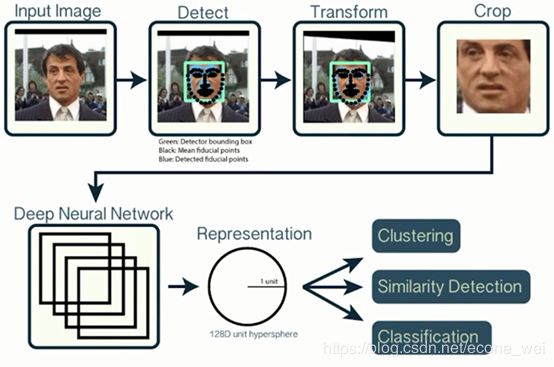
如图是基于深度神经网络搭建的基本框架。首先对输入图像数据的人脸进行检测,然后进行人脸对齐。把得到的人脸图片输入到深度神经网络,通过卷积学习到人脸的特征向量。最后是利用了三元组Loss对比人脸特征向量进行比对(计算距离),如果小于设定阈值,则认为是同一个人,否则不是同一个人。
FaceNet 在复杂光照和姿态下表现也比较出色

上图每行都是同一个人,阈值为1.1。该模型可以准确的检测出每行两个人脸图片(光照和姿态不同)之间的距离小于给定阈值,而从列上来看,距离都大于给定阈值,也就是说列向不是同一个人。
一、The Triplet Loss
核心思想:应用 Triplet Loss 前把人脸图像编码为d维空间向量。训练使得同一人的不同人脸向量间距离小,不同人间向量距离大。
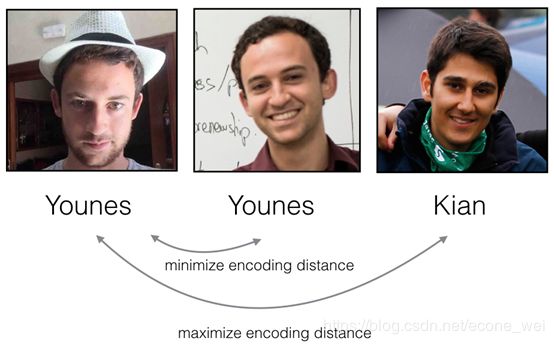
(该图来源于吴恩达深度学习)
Notes: 从左至右称作Anchor(A),Positive§,Negtive(N)。
其中Anchor(基准人脸图像)、Postive(同一人的人脸图像)、Negtive(不同人的人脸图像)
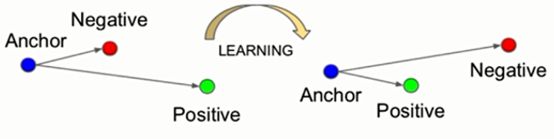
或者也可以通过下图来理解,学习之前 Anchor和Negtive之间的距离进,与Postive之间的距离远。学习之后,Anchor与Negtive之间的距离远,与Postive之间的距离进。
距离需要满足如下公式:
∣ ∣ f ( A ( i ) ) − f ( P ( i ) ) ∣ ∣ 2 2 + α < ∣ ∣ f ( A ( i ) ) − f ( N ( i ) ) ∣ ∣ 2 2 \mid \mid f(A^{(i)}) - f(P^{(i)}) \mid \mid_2^2 + \alpha < \mid \mid f(A^{(i)}) - f(N^{(i)}) \mid \mid_2^2 ∣∣f(A(i))−f(P(i))∣∣22+α<∣∣f(A(i))−f(N(i))∣∣22
左边的距离表示同一人向量之间的距离,右边的距离表示不同人脸向量之间的距离,α是指Postive和Negtive的边界(Margin),
由此定义Triplet Loss(三元组损失函数)如下:
J = ∑ i = 1 m [ ∣ ∣ f ( A ( i ) ) − f ( P ( i ) ) ∣ ∣ 2 2 ⎵ (1) − ∣ ∣ f ( A ( i ) ) − f ( N ( i ) ) ∣ ∣ 2 2 ⎵ (2) + α ] + \mathcal{J} = \sum^{m}_{i=1} \large[ \small \underbrace{\mid \mid f(A^{(i)}) - f(P^{(i)}) \mid \mid_2^2}_\text{(1)} - \underbrace{\mid \mid f(A^{(i)}) - f(N^{(i)}) \mid \mid_2^2}_\text{(2)} + \alpha \large ] \small_+ J=i=1∑m[(1) ∣∣f(A(i))−f(P(i))∣∣22−(2) ∣∣f(A(i))−f(N(i))∣∣22+α]+
所要做的就是最小化这个Triplet Loss。
当然因为训练集很庞大,所有可行的三元组也非常多,为了加速收敛,训练时需要选择合适的三元组。
即:给定 A ( i ) A^(i) A(i),求 P ( i ) P^(i) P(i)和 N ( i ) N^(i) N(i),
分别使 a r g m a x P ( i ) ∣ ∣ f ( A ( i ) ) − f ( P ( i ) ) ∣ ∣ 2 2 argmaxP^{(i)}||f(A(i))-f(P(i))||^2_2 argmaxP(i)∣∣f(A(i))−f(P(i))∣∣22 和 a r g m a x N ( i ) ∣ ∣ f ( A ( i ) ) − f ( N ( i ) ) ∣ ∣ 2 2 argmaxN^{(i)}||f(A(i))-f(N(i))||^2_2 argmaxN(i)∣∣f(A(i))−f(N(i))∣∣22.
也就是说先找一张基准的人脸 A ( i ) A^(i) A(i),把错误的人脸找出来。所找到的正确的人脸和我们基准的人脸距离最远,同时找一张错误的人脸,和基准的人脸距离最近。即找最像又不是同一个人的人脸和不像又是同一个人的人脸。
深度网络架构(DEEP ARCHITECTURE)
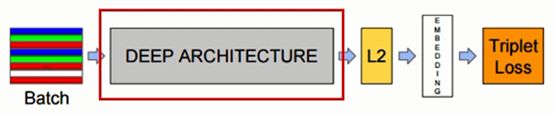
除了Triplet Loss ,效果的好坏就主要看深度网络的架构了,论文采用了两条不同的深度神经网络架构做对比。
FaceNet — NN1
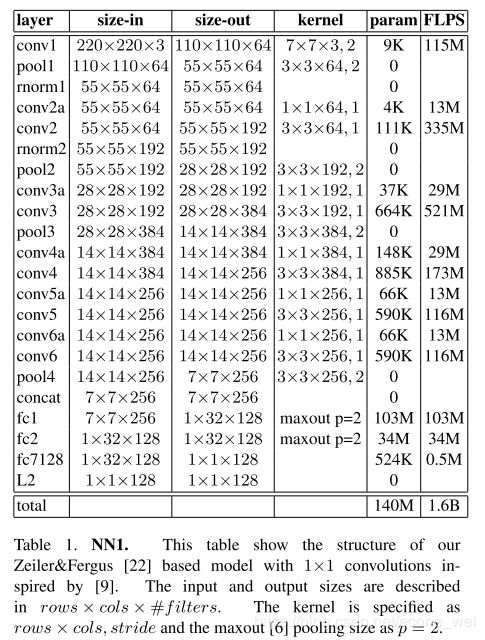
这个模型架构包含有1.4亿个参数,计算量是非常大的。每张图片的浮点数运算有16亿次。
FaceNet — NN2
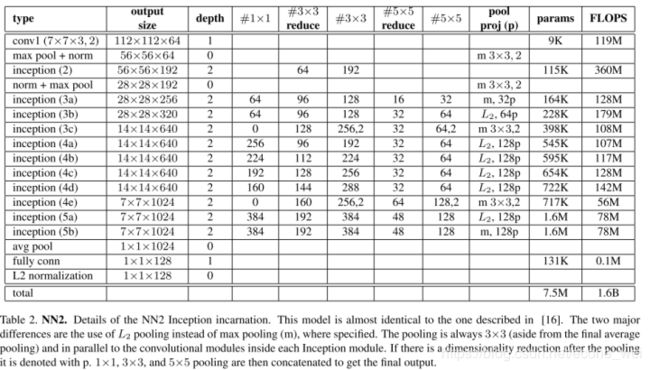
NN2 用的是Google的 Inception 网络,模型参数有750万,相比NN1有大幅度下降。处理一张图片需要的16亿次浮点数运算。
FaceNet计算量(FLOPS)对结果影响
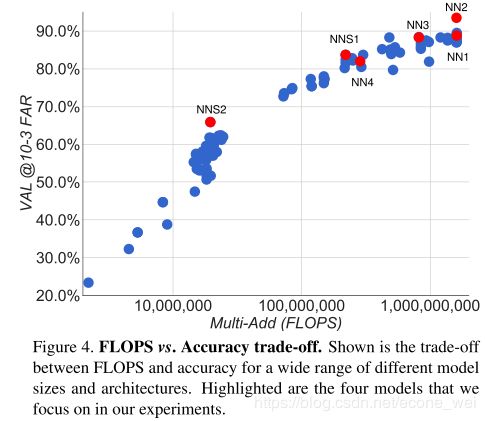
从上图可以看出 NN1 和 NN2 的计算量是一样的,精确度都比较高,NN1和NN2的简化版(如某些模块减少一些卷积,减少模型参数)NNS1(NNSmall1)和NNS2以及NN3、NN4精确度比较小。
FaceNet CNN 架构对结果影响
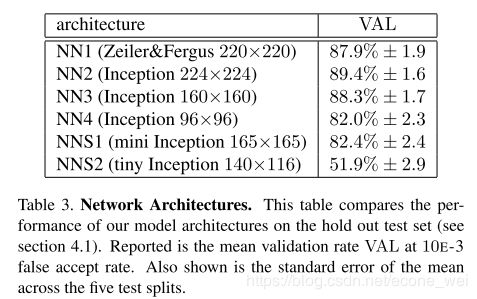
根据上图可以看到从 NN2 到 NNS2 都是采用了Inception架构,如NN3和NN2相比就是减少了图片的像素,相应精度也随之会下降一些。
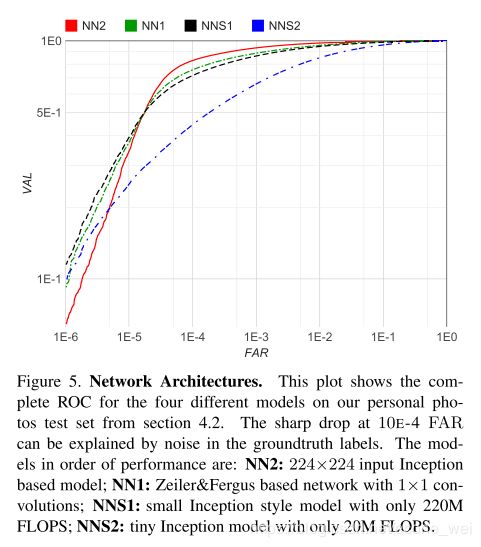
从ROC和网络架构关系来看,NN2 的效果确实是最好的,NNS2表现比较差,不过NNS2计算量相对来说很小,架构也简单。
FaceNet 图像质量对结果影响
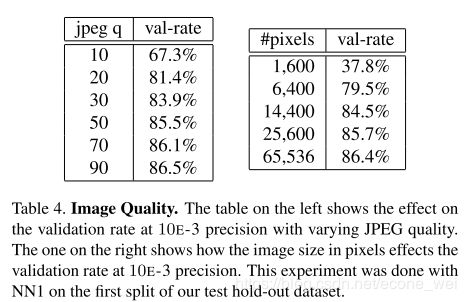
可以看到,在验证集上面图像质量达到90的时候,准确率也最高。同样,像素越高,准确度也越高。
FaceNet 特征空间维度对结果影响
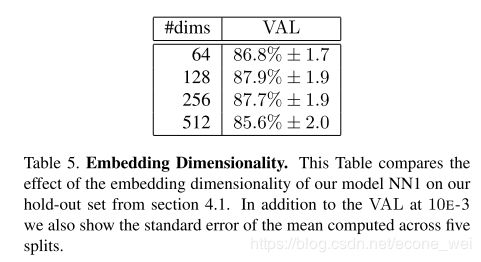
论文最后通过模型最终得到的是128 维的人脸特征向量。选择128也是凭经验得到的一个数值,由上图几种不同维度的影响来看,128维是效果最好。
FaceNet 训练数据量对结果的影响
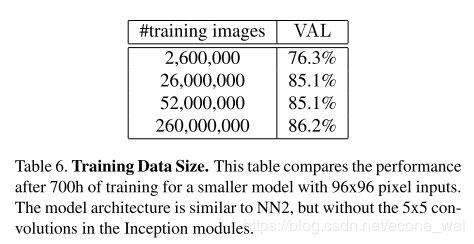
我们知道训练数据量当然越大训练效果越好。不过数据集大训练时间等开销也非常大,所以需要看实际情况选择。
最后再来总结下FaceNet模型的优势之处
- 使用Triplet Loss 代替 Softmax Loss
- 模型输出128维人脸特征向量,而不是人脸分类结果(FaceID)
- 准确率高,LFW上达99.63%
- 简化模型,减少了参数和计算量
- 通用性好,可应用到人脸验证、识别、分类、搜索和跟踪等多种场景。
FaceNet人脸识别实战
OpenFace介绍
OpenFace是用python和Torch实现的基于深度神经网络的人脸识别模型FaceNet,目前也有Keras和TensorFlow(low-level API)版本的FaceNet。
使用基于 NN4 改造的 CNN 模型训练和提取特征
nn4.small2.v1 是 FaceNet 论文中描述的 NN4 模型的变体,在 OpenFace 的模型列表中有 nn4.small2 详细介绍。
模型列表
| Model | Number of Parameters |
|---|---|
| nn4.small2 | 3733968 |
| nn4.small1 | 5579520 |
| nn4 | 6959088 |
| nn2 | 7472144 |
本教程使用其 Keras版本 的一种实现,模型定义在 model.py ,
Retrain 人脸识别模型工作流程
- 加载训练数据集
- 人脸检测、对齐和提取(使用 OpenFace 的人脸对齐工具 AlignDlib)
- 人脸特征向量学习(使用预训练的 nn4.small1.v1 模型)
- 人脸分类(使用 KNN 或 SVM)
加载训练数据集
训练数据集组织形式
- 每人一个文件目录,目录以人名命名,如”Fan_Bingbing“
- 每个人的文件目录下包含10张图像(最好是1:1比例),图像文件以"人名_序号"命名,仅支持.jpg和.jpeg 两种格式。如”Fan_Bingbing_0001.jpg“。
import numpy as np
import cv2
import os.path
# 定义一个加载文件的类
class IdentityMetadata():
def __init__(self, base, name, file):
self.base = base # 数据集根目录
self.name = name # 目录名
self.file = file # 图像文件名
def __repr__(self):
return self.image_path()
def image_path(self):
return os.path.join(self.base, self.name, self.file)
# 获取根目录所有图像文件的位置,返回一个根目录列表
def load_metadata(path):
metadata = []
for i in os.listdir(path):
for f in os.listdir(os.path.join(path, i)):
# 检查文件名后缀,仅支持 jpg 和 jpeg 两种文件格式
ext = os.path.splitext(f)[1]
if ext == '.jpg' or ext == '.jpeg':
metadata.append(IdentityMetadata(path, i, f))
return np.array(metadata)
def load_image(path):
img = cv2.imread(path, 1)
# OpenCV 默认使用 BGR 通道加载图像,转换为 RGB 图像
return img[...,::-1]
人脸检测、对齐和提取
从原图提取 96x96 RGB人脸图像。如果原图不是 1:1 比例,提取后的人脸会进行拉伸变换。
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from align import AlignDlib
# AlignDlib是OpenFace自带的人脸检测工具,人脸关键点文件"landmarks.dat"
# 初始化 OpenFace 人脸对齐工具,使用 Dlib 提供的 68 个关键点
alignment = AlignDlib('face_detection/landmarks.dat')
# 加载一张训练图像
img = load_image(metadata[0].image_path())
# 检测人脸并返回边框
bb = alignment.getLargestFaceBoundingBox(img)
# 使用指定的人脸关键点转换图像并截取 96x96 的人脸图像
# AlignDlib.OUTER_EYES_AND_NOSE 对应的就是 nn4.small2.v1 模型
aligned_img = alignment.align(96, img, bb, landmarkIndices=AlignDlib.OUTER_EYES_AND_NOSE)
# 绘制原图
plt.subplot(131)
plt.imshow(img)
plt.xticks([])
plt.yticks([])
# 绘制带人脸边框的原图
plt.subplot(132)
plt.imshow(img)
plt.gca().add_patch(patches.Rectangle((bb.left(), bb.top()), bb.width(), bb.height(), fill=False, color='red'))
plt.xticks([])
plt.yticks([])
# 绘制对齐后截取的 96x96 人脸图像
plt.subplot(133)
plt.imshow(aligned_img)
plt.xticks([])
plt.yticks([])

加载 nn4.small2.v1 模型
from model import create_model
nn4_small2 = create_model()
from keras.models import Model
from keras.layers import Input, Layer
# 输入 anchor, positive and negative 96x96 RGB图像
in_a = Input(shape=(96, 96, 3))
in_p = Input(shape=(96, 96, 3))
in_n = Input(shape=(96, 96, 3))
# 输出对应的人脸特征向量
emb_a = nn4_small2(in_a)
emb_p = nn4_small2(in_p)
emb_n = nn4_small2(in_n)
from keras.utils.vis_utils import plot_model
plot_model(nn4_small2, to_file='nn4_small2_model.png', show_shapes=True)
模型部分截图如下(完整模型图片给博主留言,或到公众号获取)
通过模型实现,最后就得到图像的特征向量。特征向量需要用Triplit Loss来实现。
Triplet Loss Layer
Triplet Loss 前面已经说过,通过最小化Triplet loss L L L可以学习到我们想要的模型:
L = ∑ i = 1 m [ ∣ ∣ f ( A ( i ) ) − f ( P ( i ) ) ∣ ∣ 2 2 ⎵ (1) − ∣ ∣ f ( A ( i ) ) − f ( N ( i ) ) ∣ ∣ 2 2 ⎵ (2) + α ] + \mathcal{L} = \sum^{m}_{i=1} \large[ \small \underbrace{\mid \mid f(A^{(i)}) - f(P^{(i)}) \mid \mid_2^2}_\text{(1)} - \underbrace{\mid \mid f(A^{(i)}) - f(N^{(i)}) \mid \mid_2^2}_\text{(2)} + \alpha \large ] \small_+ L=i=1∑m[(1) ∣∣f(A(i))−f(P(i))∣∣22−(2) ∣∣f(A(i))−f(N(i))∣∣22+α]+
[ z ] + [z]_+ [z]+ 即 m a x ( z , 0 ) max(z,0) max(z,0) , m m m 是三元组集合的基数。
下面使用 Keras 的自定义 Loss 来实现 Triplet Loss
from keras import backend as K
# 定义一个Triplet Loss 类,也就是一层
class TripletLossLayer(Layer):
def __init__(self, alpha, **kwargs):
self.alpha = alpha
super(TripletLossLayer, self).__init__(**kwargs)
def triplet_loss(self, inputs):
a, p, n = inputs
p_dist = K.sum(K.square(a-p), axis=-1)
n_dist = K.sum(K.square(a-n), axis=-1)
return K.sum(K.maximum(p_dist - n_dist + self.alpha, 0), axis=0)
def call(self, inputs):
loss = self.triplet_loss(inputs)
self.add_loss(loss)
return loss
# 定义完整的网络模型
triplet_loss_layer = TripletLossLayer(alpha=0.2, name='triplet_loss_layer')([emb_a, emb_p, emb_n])
nn4_small2_train = Model([in_a, in_p, in_n], triplet_loss_layer)
plot_model(nn4_small2_train, to_file='nn4_small2_train.png', show_shapes=True)
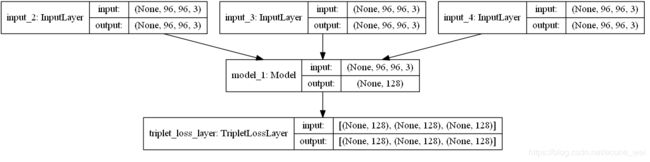
以上是定义了可以训练的模型 ,实际只需要展示预训练模型如何实现人脸识别
加载预训练模型 nn4.small2.v1
我们从 OpenFace 提供的 预训练模型 中选择 nn4.small2.v1。
这些模型使用公开数据集 FaceScrub 和 CASIA-WebFace进行训练。Keras-OpenFace 项目将这些模型文件转换为 csv 文件,然后我们将其转换为 Keras h5 模型文件 nn4.small2.v1.h5。
预训练模型
| Model | alignment landmarkIndices |
|---|---|
| nn4.v1 | openface.AlignDlib.INNER_EYES_AND_BOTTOM_LIP |
| nn4.v2 | openface.AlignDlib.OUTER_EYES_AND_NOSE |
| nn4.small1.v1 | openface.AlignDlib.OUTER_EYES_AND_NOSE |
| nn4.small2.v1 | openface.AlignDlib.OUTER_EYES_AND_NOSE |
nn4_small2_pretrained = create_model()
nn4_small2_pretrained.load_weights('models/nn4.small2.v1.h5')
# 定义一个人脸对齐的方法
def align_image(img):
return alignment.align(96, img, alignment.getLargestFaceBoundingBox(img),
landmarkIndices=AlignDlib.OUTER_EYES_AND_NOSE)
metadata = load_metadata('orig_images')
embedded = np.zeros((metadata.shape[0], 128)) # 图像对应的人脸特征向量初始化
for i, m in enumerate(metadata):
img = load_image(m.image_path())
img = align_image(img)
# 数据规范化
img = (img / 255.).astype(np.float32)
# 人脸特征向量
embedded[i] = nn4_small2_pretrained.predict(np.expand_dims(img, axis=0))[0]

人脸分类
用KNN和SVM分类器做对比
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
targets = np.array([m.name for m in metadata])
encoder = LabelEncoder()
encoder.fit(targets)
# Numerical encoding of identities
y = encoder.transform(targets)
# 奇数图像做训练数据
train_idx = np.arange(metadata.shape[0]) % 2 != 0
# 偶数图像做测试数据
test_idx = np.arange(metadata.shape[0]) % 2 == 0
# 50 train examples of 10 identities (5 examples each)
X_train = embedded[train_idx]
# 50 test examples of 10 identities (5 examples each)
X_test = embedded[test_idx]
y_train = y[train_idx]
y_test = y[test_idx]
knn = KNeighborsClassifier(n_neighbors=1, metric='euclidean')
svc = LinearSVC()
knn.fit(X_train, y_train)
svc.fit(X_train, y_train)
acc_knn = accuracy_score(y_test, knn.predict(X_test))
acc_svc = accuracy_score(y_test, svc.predict(X_test))
print(f'KNN accuracy = {acc_knn}, SVM accuracy = {acc_svc}')
KNN accuracy = 0.96, SVM accuracy = 0.98
随便找一张图片测试一下
import warnings
warnings.filterwarnings('ignore')
example_idx = 26
example_image = load_image(metadata[example_idx].image_path())
example_prediction = svc.predict([embedded[example_idx]])
example_identity = encoder.inverse_transform(example_prediction)[0]
plt.imshow(example_image)
plt.title(f'Recognized as {example_identity}');
plt.xticks([])
plt.yticks([])

识别正确。
当然在欧美人种和亚洲人种识别的准确率是不一样的,因为数据集用的就是欧美人种的图像数据,学习出来的特征都是和亚洲人脸特征都是不一样的。所以不管现在人脸识别算法有多少,其中壁垒还是在有数据的公司手中。还是与适用场景有很大关系。