对LCA、树上倍增、树链剖分(重链剖分&长链剖分)和LCT(Link-Cut Tree)的学习
LCA
what is LCA & what can LCA do
LCA(Lowest Common Ancestors),即最近公共祖先
在一棵树上,两个节点的深度最浅的公共祖先就是 L C A LCA LCA (自己可以是自己的祖先)
很简单,我们可以快速地进入正题了
下图中的树, 4 4 4和 5 5 5的 L C A LCA LCA为2, 1 1 1和 3 3 3的 L C A LCA LCA是1(1也算1的祖先)
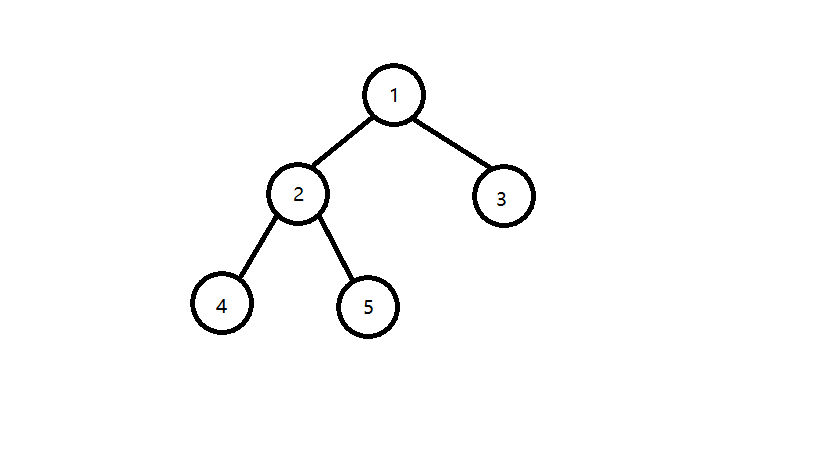
除了是直接求两点的 L C A LCA LCA的模板题,没有题目会叫你打个模板
那么LCA能干嘛?
其实 L C A LCA LCA的用途很广,感觉用 L C A LCA LCA最多的像是这样子的题
-
给你一棵树
(或者是一个图求完MST,这很常见)和树上的两点 -
然后找出这两点之间的路径的极值或权值和或其他东东
这时我们可以借助这两点的LCA作为中转点来轻松地解决这类题目
how to discover LCA
还是这棵树
4 4 4和 3 3 3的 L C A LCA LCA是1,这两点间的路径是下图标红的路径
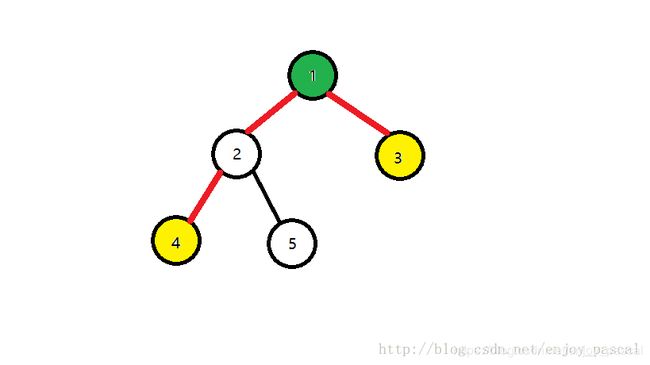
怎么求LCA呢?
method one
暴力dfs一遍,时间复杂度 O ( n ) O(n) O(n)
侮辱智商
(逃)
method two
模拟,从两点开始一起向上跳一步,跳过的点标记一下,时间复杂度 O ( n ) O(n) O(n)
侮辱智商*2
(逃)
method three
用dfs记录每个点的深度,求 L C A LCA LCA时先调至统一深度,再一起向上跳
如果这棵树是一个刚好分成两叉的树,时间复杂度 O ( n ) O(n) O(n)
侮辱智商*3
(逃)
上面的都是小学生都会的东西,不必讲了
想真正用有意义的 L C A LCA LCA,下面才是重点
tarjan算法(离线)求LCA
求 L C A LCA LCA有一种非常容易理解的方法就是tarjan算法预处理离线解决,时间复杂度 O ( n + q ) O(n+q) O(n+q),飞速
仍感觉离线算法不适用于所有题目
(比如某些良心出题人丧病地要你强制在线,GG)
反正在线算法可以解决离线能做出来所有的题
所以,我不讲 t a r j a n tarjan tarjan求 L C A LCA LCA了,推荐一篇写的很棒的blog
接下来的几个在线算法才是搞 L C A LCA LCA的门槛
ST(RMQ)算法(在线)求LCA
这种方法的思想,就是将LCA问题转化成RMQ问题
- 如果不会 R M Q RMQ RMQ问题—— S T ST ST算法的就戳这里吧
可以转化成RMQ问题?
这里有棵树
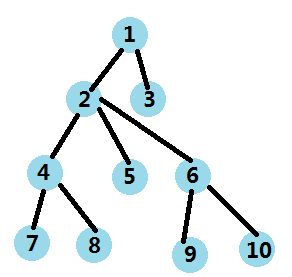
如何预处理呢?
我们用dfs遍历一次,得到一个 d f s dfs dfs序(儿子节点回到父亲节点还要再算一遍)
d f s dfs dfs序就是这样的1->2->4->7->4->8->4->2->5->2->6->9->6->10->6->2->1->3->1
(一开始在 r o o t root root向儿子节点走,到了叶子节点就向另一个儿子走,最后回到 r o o t root root)
d f s dfs dfs预处理的时间复杂度为 O ( n ) O(n) O(n)
dfs序妙啊
设 r [ x ] r[x] r[x]表示 x x x在 d f s dfs dfs序当中第一次出现的位置, d e p t h [ x ] depth[x] depth[x]表示 x x x的深度
如果求 x x x和 y y y的 L C A LCA LCA,r[x]~r[y]这一段区间内一定有 L C A ( x , y ) LCA(x,y) LCA(x,y),而且一定是区间中深度最小的那个点
(比如上面的dfs序中,第一个 7 7 7和第一个 5 5 5之间的序列里的深度最小的点是 2 2 2,而 2 2 2正是 7 7 7和 5 5 5的 L C A LCA LCA!)
-
遍历以 L C A ( x , y ) LCA(x,y) LCA(x,y)为根的树时,不遍历完所有以 L C A ( x , y ) LCA(x,y) LCA(x,y)为根的树的节点是不会回到 L C A ( x , y ) LCA(x,y) LCA(x,y)的
-
还有就是明显地,想到达x再到y,必须上溯经过它们的LCA(两个点之间有且只有一条路径)
-
所以 L C A LCA LCA的深度一定最小
直接用RMQ——ST表维护这个东西,求出来的最小值的点即为 L C A LCA LCA
matters need attention
-
d f s dfs dfs序的长度是 2 n − 1 2n-1 2n−1,用 d f s O ( n ) dfsO(n) dfsO(n)处理出 r r r、 d e p t h depth depth和 d f s dfs dfs序之后直接套上裸的 R M Q RMQ RMQ
-
设 f [ i ] [ j ] f[i][j] f[i][j]表示dfs序中j~j+2^i-1的点当中,depth值最小的是哪个点 即可
-
那么单次询问时间复杂度 O ( 1 ) O(1) O(1)
-
完美
code
这段代码是我co过来的,因为我也是看别人博客学的
但这代码是真的丑
#include 小结
基础的 L C A LCA LCA知识你应该已经会了吧
L C A LCA LCA的运用挺广吧,感觉和线段树的考频有的一比,不掌握是会吃亏的
上面的是比较普通的方法求 L C A LCA LCA,其实树上倍增也能求 L C A LCA LCA
接下来到丧心病狂 (其实很简单) 的树上倍增了
树上倍增
又是什么东东?
倍增这个东东严格来说就是种思想,只可意会不可言传
倍增,是根据已经得到了的信息,将考虑的范围扩大,从而加速操作的一种思想
使用了倍增思想的算法有
- 归并排序
- 快速幂
- 基于ST表的RMQ算法
- 树上倍增找LCA等
- FFT、后缀数组等高级算法
- …… F F T FFT FFT有倍增的么……我可能学了假的 F F T FFT FFT
some advantages
树上倍增和 R M Q RMQ RMQ是比较相似的,都采用了二进制的思想,所以时空复杂度低
其实树上倍增和树链剖分在树题里面都用的很多
-
两个都十分有趣,但倍增有着显而易见的优点——
-
比起树链剖分,树上倍增代码短,查错方便,时空复杂度优(都是 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n))
-
只是功能欠缺了一些不要太在意
即使如此,树上倍增也能够解决大部分的树型题目反正两个都要学
树上倍增(在线)求LCA
preparation
怎么样预处理以达到在线单次询问 O ( l o g 2 n ) O(log_2n) O(log2n)的时间呢?
我们需要构造倍增数组
-
设 a n c [ i ] [ j ] anc[i][j] anc[i][j]表示i节点的第2^j个祖先
-
注意 a n c anc anc数组开到 a n c [ n ] [ l o g 2 n ] anc[n][log_2n] anc[n][log2n],因为树上任意一点最多有 2 l o g 2 n 2^{log_2n} 2log2n个祖先
-
可以发现这个东西可以代替不路径压缩的并查集, ∵ a n c [ i ] [ 0 ] = f a t h e r ( i ) ∵anc[i][0]=father(i) ∵anc[i][0]=father(i)
(若 a n c [ i ] [ j ] = 0 anc[i][j]=0 anc[i][j]=0则说明 i i i的第 2 j 2^j 2j祖先不存在)
然后,倍增的性质 (DP方程) 就清楚地出来了 a n c [ i ] [ j ] = a n c [ a n c [ i ] [ j − 1 ] ] [ j − 1 ] anc[i][j]=anc[anc[i][j-1]][j-1] anc[i][j]=anc[anc[i][j−1]][j−1]
-
用文字来表达它就是这样的
-
i的第 2 j 2^j 2j个父亲是i的第 2 j − 1 2^{j-1} 2j−1个父亲的第 2 j − 1 2^{j-1} 2j−1个父亲
-
神奇不?
就是说暴力求 i i i的第 k k k个祖先的时间复杂度是 O ( k ) O(k) O(k),现在变成了 O ( l o g 2 k ) O(log_2k) O(log2k)
同时,用一个dfs处理出每个点的深度 d e p t h [ x ] depth[x] depth[x]和 a n c [ x ] [ 0 ] anc[x][0] anc[x][0],时间复杂度 O ( n ) O(n) O(n)
预处理的时间复杂度即为 O ( n log 2 n ) O(n\log_2n) O(nlog2n)
code
procedure dfs(x,y:longint);
var
now:longint;
begin
now:=last[x];
while now<>0 do
begin
if b[now]<>y then
begin
anc[b[now],0]:=x;
depth[b[now]]:=depth[x]+1;
dfs(b[now],x);
end;
now:=next[now];
end;
end;
for j:=1 to trunc(ln(n)/ln(2)) do
for i:=1 to n do
anc[i,j]:=anc[anc[i,j-1],j-1];
query
请务必认认真真地阅读以下内容否则树上倍增你就学不会了
树上倍增的运用中,最简单最实用的就是求 L C A LCA LCA了
- 现在我们需要求出 L C A ( x , y ) LCA(x,y) LCA(x,y),怎么倍增做?
还记得前面三种脑残 O ( n ) O(n) O(n)求 L C A LCA LCA的第三个方法吗?
用dfs记录每个点的深度,求LCA时先调至统一深度,再一起向上跳
其实树上倍增运用的就是这个思想!只不过时间复杂度降至了飞快的 O ( log 2 n ) O(\log_2n) O(log2n)
-
对于两个节点 u u u和 v v v,我们先把 u u u和 v v v调至同一深度
-
若此时 u = v u=v u=v,那么原来两点的 L C A LCA LCA即为当前点
-
如果 d e p t h [ u ] = d e p t h [ v ] depth[u]=depth[v] depth[u]=depth[v]但 u ≠ v u≠v u̸=v,就说明 L C A ( u , v ) LCA(u,v) LCA(u,v)在更浅的地方
-
我们同时把 u u u和 v v v向上跳 2 k 2^k 2k步( k = l o g 2 d e p t h [ u ] k=log_2depth[u] k=log2depth[u]),直到 u = v u=v u=v
明显这种方法肯定能求出 L C A LCA LCA,因为 u u u和 v v v一定会相遇
倍增比那种脑残方法优的是,脑残方法一步一步向上跳,倍增一次跳 2 k 2^k 2k步!
- 但还存在着一些问题——如果这样跳,跳到了 L C A LCA LCA的祖先节点怎么搞?
所以如果 u u u和 v v v向上跳 2 k 2^k 2k步到达的节点相同,那我们就不跳,让 u u u和 v v v的第 2 k 2^k 2k祖先不同即可跳
注意每下一次向上跳的距离是上一次跳的 1 2 1 \over 2 21( k = k − 1 k=k-1 k=k−1),直到 u = v u=v u=v, L C A LCA LCA即已被求出
这样使 u u u和 v v v与 L C A LCA LCA的距离每次缩短一半,时间复杂度也就是 O ( log 2 n ) O(\log_2n) O(log2n)的
最后如何把 u u u和 v v v调至同一深度?
其实是一样的,先把较深的那个点调浅就行了
code
- 觉得上面说得抽象的话见标理解一下
function lca(x,y:longint):longint;
var
k:longint;
begin
if depth[x]<depth[y] then swap(x,y);
k:=trunc(ln(depth[x]-depth[y]+1)/ln(2));
while k>=0 do
begin
if depth[anc[x,k]]>depth[y] then x:=anc[x,k];
dec(k);
end;
if depth[x]<>depth[y] then x:=anc[x,0];
k:=trunc(ln(d[x])/ln(2));
while k>=0 do
begin
if anc[x,k]<>anc[y,k] then
begin
x:=anc[x,k];
y:=anc[y,k];
end;
dec(k);
end;
exit(x);
end;
以上三段 c o d e code code已经能解决树上倍增求 L C A LCA LCA了
树上倍增求 L C A LCA LCA的时间复杂度为 O ( n log 2 n + q log 2 n ) O(n\log_2n+q\log_2n) O(nlog2n+qlog2n)
树上倍增的真正意义
比赛里面直接求 L C A LCA LCA是没有什么用处的
其实,树上倍增的真正可怕之处是这个倍增的思想
- 不信? 来看看这种很常见的题目
给你一棵树和两个点 x x x和 y y y,求这两点间路径的路径最大/小的点权/边权
明显我们要先求 x x x和 y y y的 L C A LCA LCA,因为唯一路径必须经过 L C A LCA LCA
求 L C A LCA LCA比如说用 R M Q RMQ RMQ,然后呢?暴力 O ( n ) O(n) O(n)再遍历一次路径?
不可能的
-
这种问题用树上倍增还是能用 O ( log 2 n ) O(\log_2n) O(log2n)的时间解决
-
我们可以设 d i s [ i ] [ j ] dis[i][j] dis[i][j]表示i到他的第 2 j 2^j 2j个祖先的路径最大值,就可以边求 L C A LCA LCA边顺便求出两点距离
-
因为 d i s dis dis也符合
d i s [ i ] [ j ] = m a x ( d i s [ i ] [ j − 1 ] , d i s [ a n c [ i ] [ j − 1 ] ] [ j − 1 ] ) dis[i][j]=max(dis[i][j-1],dis[anc[i][j-1]][j-1]) dis[i][j]=max(dis[i][j−1],dis[anc[i][j−1]][j−1])
还有求两点的路径上路径权值和呢?
- 设 s u m [ i ] [ j ] sum[i][j] sum[i][j]表示i到他的第 2 j 2^j 2j个祖先的路径权值和,同时也可边求 L C A LCA LCA边求和,因为
s u m [ i ] [ j ] = s u m [ i ] [ j − 1 ] + s u m [ a n c [ i ] [ j − 1 ] ] [ j − 1 ] ) sum[i][j]=sum[i][j-1]+sum[anc[i][j-1]][j-1]) sum[i][j]=sum[i][j−1]+sum[anc[i][j−1]][j−1])
这才是树上倍增的真正意义所在,像 R M Q RMQ RMQ求 L C A LCA LCA,是无法解决这类问题的
至此树上倍增讲的差不多了,看例题
例题1:【JZOJ1738】Heatwave
problem
Description 给你N个点的无向连通图,图中有M条边,第j条边的长度为: d_j. 现在有 K个询问。 每个询问的格式是:A
B,表示询问从A点走到B点的所有路径中,最长的边最小值是多少?Input
文件名为heatwave.in 第一行: N, M, K。 第2…M+1行: 三个正整数:X, Y, and D (1 <=
X <=N; 1 <= Y <= N). 表示X与Y之间有一条长度为D的边。 第M+2…M+K+1行: 每行两个整数A
B,表示询问从A点走到B点的所有路径中,最长的边最小值是多少?Output
对每个询问,输出最长的边最小值是多少。
Sample Input
6 6 8 1 2 5 2 3 4 3 4 3 1 4 8 2 5 7 4 6 2 1 2 1 3 1 4 2 3 2 4 5 1 6 2
6 1Sample Output
5 5 5 4 4 7 4 5
Data Constraint
50% 1<=N,M<=3000 其中30% K<=5000 100% 1 <= N <= 15,000 1 <= M <=
30,000 1 <= d_j <= 1,000,000,000 1 <= K <= 20,000Hint
think about other issues
先不考虑其他的,先考虑一下如何搞定题目所给的问题
注意这句话——
从A点走到B点的所有路径中,最长的边的最小值是多少?
想到什么了吗?
- MST! 既然让最长的边最短,那么我们就求这棵树的最小生成树即可
这样就可以保证两点间最长边最短 ,这里直接用kruskal+并查集艹过去就行了
用邻接表存下即可
analysis
-
求完 M S T MST MST后,这道题是不是就是道裸题?维护 a n c [ i ] [ j ] anc[i][j] anc[i][j]和 d i s [ i ] [ j ] dis[i][j] dis[i][j]即可
照样用一个 d f s dfs dfs遍历整棵树,维护出 d e p t h [ x ] depth[x] depth[x]、 a n c [ x ] [ 0 ] anc[x][0] anc[x][0]和 d i s [ x ] [ 0 ] dis[x][0] dis[x][0],之后 O ( n log 2 n ) O(n\log_2n) O(nlog2n)预处理 -
搞定之后,我们对每一对 ( u , v ) (u,v) (u,v)求 L C A LCA LCA(设 u u u深度更深)注意求 L C A LCA LCA过程中记录每一次的max值即
a n s = m a x ( d i s u , k ) ans=max(dis_{u,k}) ans=max(disu,k) -
a n s ans ans即为答案
时间复杂度为 O ( m l o g 2 m + n l o g 2 n + q l o g 2 n ) O(mlog_2m+nlog_2n+qlog_2n) O(mlog2m+nlog2n+qlog2n)我乱算的
code
var
b,c,next,last,father,depth:array[0..50000]of longint;
anc,dis:array[0..15000,0..16]of longint;
a:array[0..30000,0..3]of longint;
n,m,q,i,j,x,y,tot:longint;
procedure swap(var x,y:longint);
var
z:longint;
begin
z:=x;
x:=y;
y:=z;
end;
function max(x,y:longint):longint;
begin
if x>y then exit(x);
exit(y);
end;
procedure qsort(l,r:longint);
var
i,j,mid:longint;
begin
i:=l;
j:=r;
mid:=a[(l+r)div 2,3];
repeat
while a[i,3]<mid do inc(i);
while a[j,3]>mid do dec(j);
if i<=j then
begin
a[0]:=a[i];
a[i]:=a[j];
a[j]:=a[0];
inc(i);
dec(j);
end;
until i>j;
if l<j then qsort(l,j);
if i<r then qsort(i,r);
end;
function getfather(x:longint):longint;
begin
if father[x]=x then exit(x);
father[x]:=getfather(father[x]);
exit(father[x]);
end;
function judge(x,y:longint):boolean;
begin
exit(getfather(x)=getfather(y));
end;
procedure insert(x,y,z:longint);
begin
inc(tot);
b[tot]:=y;
next[tot]:=last[x];
last[x]:=tot;
c[tot]:=z;
end;
procedure dfs(x,y:longint);
var
now:longint;
begin
now:=last[x];
while now<>0 do
begin
if b[now]<>y then
begin
anc[b[now],0]:=x;
depth[b[now]]:=depth[x]+1;
dis[b[now],0]:=c[now];
dfs(b[now],x);
end;
now:=next[now];
end;
end;
function lca(x,y:longint):longint;
var
k:longint;
begin
lca:=0;
if depth[x]<depth[y] then swap(x,y);
k:=trunc(ln(depth[x]-depth[y]+1)/ln(2));
while k>=0 do
begin
if depth[anc[x,k]]>depth[y] then
begin
lca:=max(lca,dis[x,k]);
x:=anc[x,k];
end;
dec(k);
end;
if depth[x]<>depth[y] then
begin
lca:=max(lca,dis[x,0]);
x:=anc[x,0];
end;
k:=trunc(ln(depth[x])/ln(2));
while k>=0 do
begin
if anc[x,k]<>anc[y,k] then
begin
lca:=max(max(lca,dis[x,k]),dis[y,k]);
x:=anc[x,k];
y:=anc[y,k];
end;
dec(k);
end;
if x=y then exit(lca);
exit(max(lca,max(dis[x,0],dis[y,0])));
end;
begin
readln(n,m,q);
for i:=1 to n do father[i]:=i;
for i:=1 to m do readln(a[i,1],a[i,2],a[i,3]);
qsort(1,m);
for i:=1 to m do
begin
if (not judge(a[i,1],a[i,2])) then
begin
insert(a[i,1],a[i,2],a[i,3]);
insert(a[i,2],a[i,1],a[i,3]);
father[getfather(a[i,1])]:=getfather(a[i,2]);
end;
end;
depth[1]:=1;
dfs(1,0);
for j:=1 to trunc(ln(n)/ln(2)) do
for i:=1 to n do
begin
anc[i,j]:=anc[anc[i,j-1],j-1];
dis[i,j]:=max(dis[i,j-1],dis[anc[i,j-1],j-1]);
end;
for i:=1 to q do
begin
readln(x,y);
writeln(lca(x,y));
end;
end.
例题2:【JZOJ2753】树(tree)
problem
Description
在这个问题中,给定一个值S和一棵树。在树的每个节点有一个正整数,问有多少条路径的节点总和达到S。路径中节点的深度必须是升序的。假设节点1是根节点,根的深度是0,它的儿子节点的深度为1。路径不必一定从根节点开始。Input
第一行是两个整数N和S,其中N是树的节点数。 第二行是N个正整数,第i个整数表示节点i的正整数。 接下来的N-1行每行是2个整数x和y,表示y是x的儿子。Output
输出路径节点总和为S的路径数量。Sample Input
3 3 1 2 3 1 2 1 3
Sample Output
2
Data Constraint
Hint
对于30%数据,N≤100;
对于60%数据,N≤1000;
对于100%数据,N≤100000,所有权值以及S都不超过1000。
analysis
相信这题应该难不住你了吧
正解即为树上倍增+二分
首先还是一样,用 O ( n log 2 n ) O(n\log_2n) O(nlog2n)的时间预处理 a n c anc anc数组
至于权值,你可以顺便维护 d i s dis dis数组,但为何不用简单的前缀和呢?
剩下来的就比较简单啦
-
枚举节点 i i i,二分一个 m i d mid mid表示 i i i的第 m i d mid mid个祖先
-
然后通过 a n c anc anc数组用 O ( log 2 n ) O(\log_2n) O(log2n)的时间求出 i i i的第 m i d mid mid个祖先是哪个节点 (设为是第 k k k号)
-
若 p r e [ i ] − p r e [ k ] > s pre[i]-pre[k]>s pre[i]−pre[k]>s则 r i g h t = m i d − 1 right=mid-1 right=mid−1, p r e [ i ] − p r e [ k ] < s pre[i]-pre[k]<s pre[i]−pre[k]<s则 l e f t = m i d + 1 left=mid+1 left=mid+1
= s =s =s就刚好找到了 -
此时累加答案即可
时间复杂度为 O ( n log 2 2 n ) O(n\log^2_2n) O(nlog22n)
code
#include例题3:【JZOJ5966】【NOIP2018】保卫王国
problem
Description Z国有n座城市,n-1条双向道路,每条双向道路连接两座城市,且任意两座城市都能通过若干条道路相互到达。
Z国的国防部长小Z要在城市中驻扎军队。驻扎军队需要满足如下几个条件: ①一座城市可以驻扎一支军队,也可以不驻扎军队。
②由道路直接连接的两座城市中至少要有一座城市驻扎军队。 ③在城市里驻扎军队会产生花费,在编号为i的城市中驻扎军队的花费是pi。
小Z很快就规划出了一种驻扎军队的方案,使总花费最小。但是国王又给小Z提出了m个要求,每个要求规定了其中两座城市是否驻扎军队。小Z需要针对每个要求逐一给出回答。具体而言,如果国王提出的第j个要求能够满足上述驻扎条件(不需要考虑第j个要求之外的其它要求),则需要给出在此要求前提下驻扎军队的最小开销。如果国王提出的第j个要求无法满足,则需要输出-1(1<=j<=m)
。现在请你来帮助小Z。Input 输入文件名为defense.in。 第1行包含两个正整数n,m 和一个字符串type
,分别表示城市数、要求数和数据类型。type
是一个由大写字母A,B或C和一个数字1,2,3组成的字符串。它可以帮助你获得部分分。你可能不需要用到这个参数。这个参数的含义在【数据规模与约定】中有具体的描述。
第2 行n个整数pi ,表示编号i的城市中驻扎军队的花费。 接下来n-1行,每行两个正整数u,v ,表示有一条u 到v 的双向道路。 接下来
m行,第 j行四个整数a,x,b,y(a<>b)
,表示第j个要求是在城市a驻扎x支军队,在城市b驻扎y支军队。其中,x、y的取值只有0或1:若x为0,表示城市a不得驻扎军队,若x为1,表示城市a必须驻扎军队;若y为0,表示城市b不得驻扎军队,若y为1,表示城市b必须驻扎军队。
输入文件中每一行相邻的两个数据之间均用一个空格分隔。Output 输出文件名为defense.out。 输出共
行,每行包含1个整数,第j行表示在满足国王第j个要求时的最小开销,如果无法满足国王的第j个要求,则该行输出-1。Sample Input 输入1: 5 3 C3 2 4 1 3 9 1 5 5 2 5 3 3 4 1 0 3 0 2 1 3 1 1 0
5 0Sample Output 输出1: 12 7
-1 【样例解释】 对于第一个要求,在4号和5号城市驻扎军队时开销最小。 对于第二个要求,在1号、2号、3号城市驻扎军队时开销最小。 第三个要求是无法满足的,因为在1号、5号城市都不驻扎军队就意味着由道路直接连接的两座城市中都没有驻扎军队。Data Constraint
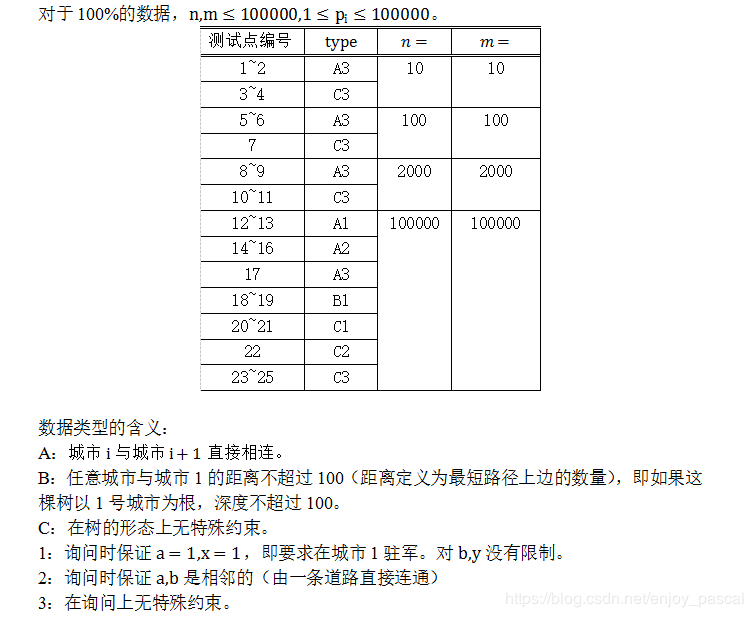
analysis
-
正解倍增+矩乘+树形DP
-
考虑一下 44 p t s 44pts 44pts的树形 D P DP DP,设 f [ i ] [ 0 / 1 ] f[i][0/1] f[i][0/1]表示以 i i i为根的子树中, i i i选或不选的最优解,则
f [ i ] [ 0 ] = ∑ f [ s o n ] [ 1 ] f[i][0]=\sum f[son][1] f[i][0]=∑f[son][1] f [ i ] [ 1 ] = ∑ m i n ( f [ s o n ] [ 0 ] , f [ s o n ] [ 1 ] ) f[i][1]=\sum min(f[son][0],f[son][1]) f[i][1]=∑min(f[son][0],f[son][1]) -
每次把某个 f f f赋值为 ∞ ∞ ∞,暴力重新 D P DP DP,就可以得到 44 p t s 44pts 44pts的好成绩
-
接着考虑另一个 D P DP DP,设 g [ i ] [ 0 / 1 ] g[i][0/1] g[i][0/1]表示以 i i i为根的子树外, i i i选或不选的最优解
-
由于我们已经 D P DP DP出了 f f f数组,我们也可以从一个点的父亲来转移 g g g,则
g [ i ] [ 0 ] = f [ i ] [ 0 ] + g [ f a ] [ 1 ] − m i n ( f [ i ] [ 0 ] , f [ i ] [ 1 ] ) g[i][0]=f[i][0]+g[fa][1]-min(f[i][0],f[i][1]) g[i][0]=f[i][0]+g[fa][1]−min(f[i][0],f[i][1]) g [ i ] [ 1 ] = f [ i ] [ 1 ] + m i n ( g [ f a ] [ 0 ] − f [ i ] [ 1 ] , g [ f a ] [ 1 ] − m i n ( f [ i ] [ 0 ] , f [ i ] [ 1 ] ) ) g[i][1]=f[i][1]+min(g[fa][0]-f[i][1],g[fa][1]-min(f[i][0],f[i][1])) g[i][1]=f[i][1]+min(g[fa][0]−f[i][1],g[fa][1]−min(f[i][0],f[i][1])) -
这个 D P DP DP也满好理解的,接下来是维护的问题
-
注意到其实没有数据更改,那么我们可以用倍增+矩乘的方法来求出一条链上的答案
-
设 d i s [ i ] [ x ] [ 0 / 1 ] [ 0 / 1 ] dis[i][x][0/1][0/1] dis[i][x][0/1][0/1]表示 i i i选或不选且 i i i的 2 x 2^x 2x位祖先选或不选的最优解,则
d i s [ i ] [ 0 ] [ 0 ] [ 0 ] = ∞ dis[i][0][0][0]=∞ dis[i][0][0][0]=∞ d i s [ i ] [ 0 ] [ 1 ] [ 0 ] = f [ f a ] [ 0 ] − f [ i ] [ 1 ] dis[i][0][1][0]=f[fa][0]-f[i][1] dis[i][0][1][0]=f[fa][0]−f[i][1] d i s [ i ] [ 0 ] [ 0 ] [ 1 ] = d i s [ i ] [ 0 ] [ 1 ] [ 1 ] = f [ f a ] [ 1 ] − m i n ( f [ i ] [ 0 ] , f [ i ] [ 1 ] ) dis[i][0][0][1]=dis[i][0][1][1]=f[fa][1]-min(f[i][0],f[i][1]) dis[i][0][0][1]=dis[i][0][1][1]=f[fa][1]−min(f[i][0],f[i][1])
-
这个应该不难理解, i i i和父亲不能都不选,所以是 ∞ ∞ ∞
-
其他的都是用父亲的贡献减去儿子的贡献,应该不太难想
-
而把 d i s dis dis数组维护出来以后,就可以实现倍增了,用矩乘解决 d i s dis dis的后两维
-
注意倍增时的矩乘和平时的不太一样,修改一下才可以
-
对于每一个询问,如果两个点在一条链上,注意一下条件选或不选的判断就行了
-
否则找出两点的 L C A LCA LCA,再倍增跳到 L C A LCA LCA,计算两种不同情况的最优解即可
-
用 g g g减去所求的东西才是最终的答案,不要忘记两个点的 L C A LCA LCA选的时候有不同的情况需要取 m i n min min
-
时间复杂度 O ( n log 2 n ) O(n\log_2n) O(nlog2n)
code
#pragma GCC optimize("O3")
#pragma G++ optimize("O3")
#include一些感想
树上倍增差不多算是那种一定要会的知识了
总之,这一种较为基础的算法,一定要熟练掌握并会运用它
(不要把正解看成暴力……)
接下来是丧心病狂 (其实比树上倍增还简单) 的树链剖分
树链剖分
介绍一下吧
零树剖基础的人,到这里应该还是不懂树剖的
简要地说一下吧——
-
树链剖分的思想是维护树上路径信息
-
树链剖分先通过轻重边剖分将树分为多条链,保证每个点属于且只属于一条链
-
然后再通过数据结构
(树状数组、SBT、splay、线段树等)来维护每一条链
以上就是树链剖分的思想了,很少,学完以后,其实树剖很简单……
问题是怎么分轻重边?怎么维护?
more advantages
既然树上倍增又好打又好调,干嘛还用树链剖分?
但树上倍增的用途还就真没有树链剖分那么广
不信? 再来一类看起来也很常见的题目
在一棵树上进行路径的权值修改,询问路径权值和、路径权值极值
看起来简单,但不简单,线段树、树上倍增根本做不了
why? 后两个操作我们当然可以用树上倍增做
关键是修改操作,树上倍增都预处理好了
- 怎么修改?重新 O ( n log 2 n ) O(n\log_2n) O(nlog2n)暴力预处理?
不可能的
这时我们就要用树链剖分了
由于我们可以用数据结构来维护剖好的树,所以路径权值之类的当然是可以修改的
所以并不是说倍增就能真正完全通用
-
树剖的用处比倍增多,倍增能做的题树剖一定能做,反过来则否
-
树剖的代码复杂度不算特别高,调试也不难
-
在高级的比赛里,树剖是必备知识
其实树剖也是分类别的
-
注意树剖有三种:重链剖分、长链剖分和实虚链剖分
-
实虚链剖分其实就是LCT
-
所以我就分开来写好了
正式进入树链剖分的学习
重链剖分
请务必认认真真地阅读以下内容否则重链剖分你就学不会了
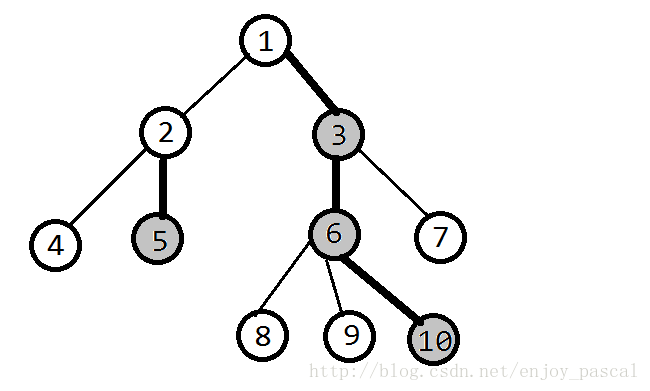
重链剖分的一些概念
轻儿子和重儿子
设 x s i z e x_{size} xsize表示以x为根的子树的节点个数
对于每个非叶子节点y,y的儿子所有中 s i z e size size最大的儿子就是重儿子(两个或以上都最大的话,任意选一个)
而y其它的儿子,都是轻儿子
(轻儿子通常没有用,我们可以不去考虑它)
重边、轻边和重链
重儿子与其父亲之间的路径,就是重边
不是重边的边均为轻边
多条重边相连为一条重链
图中灰色的点为重儿子,加粗的边是重边,其他没有加粗的是轻边
这棵树中的长度大于1的重链有两条:2—5和1—3—6—10
所有轻儿子可视作一个长度为1的重链
something about properties
-
若x是轻儿子,则有 x s i z e < = f a t h e r ( x ) s i z e 2 x_{size}<={father(x)_{size}\over 2} xsize<=2father(x)size
-
从根到某一点的路径上,不超过 l o g 2 n log_2n log2n条重链,不超过 l o g 2 n log_2n log2n条轻链
(不需要证明是因为我不会证)
预处理、维护和在线操作
其实和着概念一起看剩下三种东东,树剖还就真挺水的连模板都不用背
接下来的数据结构维护我们使用简单一点的线段树
预处理
首先用一个dfs遍历,求出每个点的 d e p t h depth depth、 f a t h e r father father、 s i z e size size以及重儿子 h e a v y heavy heavy_ s o n son son
其次再用一个dfs剖分,第二个 d f s dfs dfs维护什么呢?
- 以优先走重边的原则,遍历出来一个dfs序
- x t o p x_{top} xtop表示x位于的重链上的顶端节点编号
- t o to to_ t r e e [ x ] tree[x] tree[x]表示x在线段树中的位置
- 对于线段树中的第y个位置, t o to to_ n u m [ y ] num[y] num[y]为它对应的dfs序中的位置
剖分完以后,每一条重链相当于一个区间,我们维护处理完的数据结构即可
我们把上面那棵树剖分完以后线段树中的点顺序是这样的:
1,3,6,10,8,9,7,2,5,4 (加粗的点是在重链上的点)
在同一条重链上的点,在线段树的顺序中要连在一起(否则怎么维护呢)

剖树的时间复杂度 O ( n ) O(n) O(n)
维护以及在线操作
change
因为已经搞过to_tree了,通过to_tree的标号在线段树中用单点修改即可
不要告诉我你不会单点修改
时间复杂度是线段树修改的 O ( log 2 n ) O(\log_2n) O(log2n)
query
询问 x x x到 y y y路径的极值(或者路径和等等),和求 L C A LCA LCA一样边向上跳边记录答案
这里记录的答案通过查询数据结构得到
关于时间复杂度嘛……
关于时间复杂度?
对于我们这些蒟蒻来说最关键的还是时间复杂度的问题
用最普通的数据结构线段树来维护树链剖分的时间复杂度是 O ( n + q log 2 2 n ) O(n+q\log_2^2n) O(n+qlog22n)
后面那个 q log 2 2 n q\log^2_2n qlog22n什么东西?
由于求 L C A LCA LCA是 O ( log 2 n ) O(\log_2n) O(log2n)的,统计答案的过程中还要查询数据结构又是 O ( log 2 n ) O(\log_2n) O(log2n)的时间
所以每个查询的时间复杂度就是 O ( log 2 2 n ) O(\log_2^2n) O(log22n)了
- 平常来说,对于树剖,时间应该是比树上倍增那个 O ( n log 2 n ) O(n\log_2n) O(nlog2n)的预处理优的
所以你看树剖还是非常有用的
还有用 L C T LCT LCT维护可以做到 O ( n log 2 n ) O(n\log_2n) O(nlog2n)的时间还有LCT什么的你现在怎么可能会呢
重链剖分(在线)求LCA
树剖当然也能求LCA啦!并且比倍增还好打耶!
具体如下
- 若 x t o p ≠ y t o p x_{top}≠y_{top} xtop̸=ytop,说明 x x x和 y y y不在同一条重链上
- 记 x x x和 y y y两点中top的深度较深的那个点为z
- 把 z z z跳到 z t o p f a t h e r z_{top_{father}} ztopfather
- 重复以上步骤,直到 x x x和 y y y在同一条重链上(即 x t o p = y t o p x_{top}=y_{top} xtop=ytop)
- 此时 x x x和 y y y中 d e p t h depth depth小的点即为 L C A LCA LCA
其实很好理解,跳到 z t o p f a t h e r z_{top_{father}} ztopfather的原因是让z进入另一条重链免得程序卡住
而选择 t o p top top浅的点而不是本身浅的点是防止跳到重链头超过 L C A LCA LCA
不懂面壁去想,倍增你都听懂了,树剖的你听不懂就xxx了
那么时间复杂度 O ( log 2 n ) O(\log_2n) O(log2n)
code
- 当然求 L C A LCA LCA没有各种权,不用打线段树啦!
#include还是看例题吧
例题1:【JZO1738】Heatwave
problem
题目上面有所以就不重新贴了
analysis
我说过了倍增能做的题树剖都能做的嘛,所以树剖当然也能做这道题
其实在树剖里面这题算是模板题,而且树链剖分还看得很清楚
求完了 M S T MST MST后,我们还是照样把这棵 M S T MST MST剖分一下,用线段树维护区间最大值
这里我们求的是边权而不是点权,我们就把边权放到儿子节点上看成点权就可以了
求 L C A LCA LCA时我们是一条重链一条重链地向上跳,这里我们是一样的——
每次跳一条重链的时候,用线段树维护好的区间最大值查询这条重链的点权最大值
(还有不要告诉我你不会线段树)
套上求 L C A LCA LCA的意义也就是这样——
- 若 x t o p ≠ y t o p x_{top}≠y_{top} xtop̸=ytop,记 x x x和 y y y两点中top的深度较深的那个点为z
- t e m p = m a x ( t e m p , t r e e q u e r y m a x ( 1 , 1 , n , a [ a [ z ] . t o p ] . t o t r e e , a [ z ] . t o t r e e ) ) temp=max(temp,tree_{query_{max}}(1,1,n,a[a[z].top].to_{tree},a[z].to_{tree})) temp=max(temp,treequerymax(1,1,n,a[a[z].top].totree,a[z].totree))
- 把 z z z跳到 z t o p f a t h e r z_{top_{father}} ztopfather
最后的 t e m p temp temp即为答案,每个查询是 O ( log 2 2 n ) O(\log^2_2n) O(log22n)的时间复杂度
其实想一想,线段树是把每条重链当做区间来维护,意义十分显然
(注意一点就是求最大值时一定不要算上 L C A ( x , y ) LCA(x,y) LCA(x,y)的值)
code
#include一定读懂这段代码再看下面的题
否则会爽炸天
例题2:【JZO3534】【luoguP1967】货车运输
problem
Description
A 国有 n 座城市,编号从 1 到 n,城市之间有 m 条双向道路。每一条道路对车辆都有重量限制,简称限重。现在有 q
辆货车在运输货物,司机们想知道每辆车在不超过车辆限重的情况下,最多能运多重的货物。Input
第一行有两个用一个空格隔开的整数 n,m,表示 A 国有 n 座城市和 m 条道路。
接下来 m 行每行 3 个整数 x、y、z,每两个整数之间用一个空格隔开,表示从 x 号城市到 y 号城市有一条限重为 z 的道路。注意:x
不等于 y,两座城市之间可能有多条道路。接下来一行有一个整数 q,表示有 q 辆货车需要运货。
接下来 q 行,每行两个整数 x、y,之间用一个空格隔开,表示一辆货车需要从 x 城市运输货物到 y 城市,注意:x 不等于 y。
Output
输出共有 q 行,每行一个整数,表示对于每一辆货车,它的最大载重是多少。如果货车不能到达目的地,输出-1。
Sample Input
4 3
1 2 4
2 3 3
3 1 1
3
1 3
1 4
1 3
Sample Output
3
-1
3
Data Constraint
对于 30%的数据,0 < n < 1,000,0 < m < 10,000,0 < q < 1,000;
对于 60%的数据,0 < n < 1,000,0 < m < 50,000,0 < q < 1,000;
对于 100%的数据,0 < n < 10,000,0 < m < 50,000,0 < q < 30,000,0 ≤ z ≤
100,000。
analysis
又一个套路 M S T MST MST配树链剖分
就是不想上倍增
和上面heatwave不同的是,这里的原图不一定连通,且两城之间有多条边
虽说不一定连通,还是直接上一次最大生成树即可
多条边就把多条边中最大权值的边留下,其他的边不必管
剩下线段树维护点权最小值即和heatwave的一模一样
但必须注意一点:判断联通性的问题
我们不能只从 1 1 1节点开始剖一次树,而是必须从所有未访问到的节点开始剖树
至于判断联通性,一开始我去做洛谷的时候,是在求 L C A LCA LCA途中判断是否连通,但是WA了
其实除了 k r u s k a l kruskal kruskal用的一次并查集外,我们可以再用一次并查集,把 M S T MST MST上的边再搞一次
需要访问 x , y x,y x,y城市时只需询问 g e t f a t h e r ( x ) = g e t f a t h e r ( y ) ? getfather(x)=getfather(y)? getfather(x)=getfather(y)?即可
code
#include例题3:【JZOJ2256】【ZJOI2008】树的统计
problem
Description
一棵树上有n个节点,编号分别为1到n,每个节点都有一个权值w。 我们将以下面的形式来要求你对这棵树完成一些操作:
I. CHANGE u t : 把结点u的权值改为t II. QMAX u v: 询问从点u到点v的路径上的节点的最大权值
III. QSUM u v: 询问从点u到点v的路径上的节点的权值和 注意:从点u到点v的路径上的节点包括u和v本身Input
输入文件的第一行为一个整数n,表示节点的个数。 接下来n – 1行,每行2个整数a和b,表示节点a和节点b之间有一条边相连。
接下来n行,每行一个整数,第i行的整数wi表示节点i的权值。 接下来1行,为一个整数q,表示操作的总数。
接下来q行,每行一个操作,以“CHANGE u t”或者“QMAX u v”或者“QSUM u v”的形式给出。Output
对于每个“QMAX”或者“QSUM”的操作,每行输出一个整数表示要求输出的结果。
Sample Input
QMAX 3 4
QMAX 3 3
QMAX 3 2
QMAX 2 3
QSUM 3 4
QSUM 2 1
CHANGE 1 5
QMAX 3 4
CHANGE 3 6
QMAX 3 4
QMAX 2 4
QSUM 3 4
Sample Output
4 1 2 2 10 6 5 6 5 16
Data Constraint
Hint
【数据说明】
对于100%的数据,保证1<=n<=30000,0<=q<=200000;中途操作中保证每个节点的权值w在-30000到30000之间。
analysis
这题还是树剖经典例题
看懂 h e a t w a v e heatwave heatwave的树剖做法,这题就比较简单啦
这里的线段树要维护和查询两个值了,是区间最大值和区间和
还是一样地,求 L C A LCA LCA的同时用线段树查询整条重链的区间最大值和区间和
我懒得再讲两种查询了
至于 c h a n g e change change操作,由于我们已经把每个点在线段树中的编号(to_tree)处理出来了
所以我们直接用线段树的单点修改就可以在线段树里面直接修改指定节点
修改完以后,推回父亲节点,更新线段树即可,change成功解决
c h a n g e change change的时间复杂度 O ( log 2 n ) O(\log_2n) O(log2n)
code
树剖打250行,醉了
#include例题4:【JZOJ1175】【BZOJ2238】【IOI2008】生成树
problem
Description
给出一个N个点M条边的无向带权图,以及Q个询问,每次询问在图中删掉一条边后图的最小生成树。(各询问间独立,每次询问不对之后的询问产生影响,即被删掉的边在下一条询问中依然存在)
Input
第一行两个正整数N,M(N<=50000,M<=100000)表示原图的顶点数和边数。
下面M行,每行三个整数X,Y,W描述了图的一条边(X,Y),其边权为W(W<=10000)。保证两点之间至多只有一条边。
接着一行一个正整数Q,表示询问数。(1<=Q<=100000)
下面Q行,每行一个询问,询问中包含一个正整数T,表示把编号为T的边删掉(边从1到M按输入顺序编号)。Output
Q行,对于每个询问输出对应最小生成树的边权和的值,如果图不连通则输出“Not connected”
Sample Input
4 4 1 2 3 1 3 5 2 3 9 2 4 1 4 1 2 3 4
Sample Output
15 13 9 Not connected
Data Constraint
Hint
数据规模: 10%的数据N,M,Q<=100。 另外30%的数据,N<=1000 100%的数据如题目。
analysis
- 还有第四道例题
(不要看到“IOI”什么的就不敢做了)
正解还是——MST+树链剖分
奇怪的是静态树上问题MST+树剖是不是万能的…?
想一想即知,如果删去的边不在原图的 M S T MST MST上,对原答案没有影响
但是如果删去了 M S T MST MST上的边,那么其他的 M S T MST MST树边一定不变
那此时要找的只是一条非 M S T MST MST上的边,且要求最短,显然是在树链上
我们在求完 M S T MST MST后,用树链剖分维护每条非MST树边能够使多少条MST树边删去后连通
说着很拗口,但操作还是很 s i m p l e simple simple的,标记永久化一下即可
当然原图就是不连通的话, q q q个操作全都输出**“Not connected”**
时间复杂度为 O ( n log 2 2 n ) O(n\log^2_2n) O(nlog22n)
code
#include长链剖分
- 待填坑
树剖大法好
最近做模拟赛,看到树上问题就开码树剖 (我变成无脑xxxx玄手了么)
但是树剖对付静态树问题基本都能完美解决
树剖用处确实非常非常多,不仅要熟练运用,还要做到触类旁通、用老知识解决新题目
我不是树剖讲师所以树剖学的还是不好
动态树问题呢?树剖GG,祭出 L C T LCT LCT吧
(LCT明明比树剖高级多了)
LCT(Link-Cut Tree)
玄♂妙的动态树问题
静态树问题在前面已经见识过了
就是树的形态不发生变化,只是树上的权值变化,用数据结构随便维护一下的问题罢了
但是树的形态如果会变化呢?(例如添、删树边操作等)
这就是 动态树问题(Dynamic Tree Problem) 了
然而Link-Cut Tree并不能吃
杨哲的《QTREE 解法的一些研究》 你应该听说过
由于百度像csdn一样要XX币才能下载那些文档,就百度云共享一波啦
这里下载,uuq0
LCT(Link-Cut Tree),解决动态树问题的一种算法
LCT≈splay+树剖,是解决动态树问题的一把利器
核心思想就是借鉴树剖的 轻重边 等概念,用比线段树灵活的 s p l a y splay splay来维护一棵树(森林)
意会就好
(但真相是tarjan老爷子是在发明LCT之后才发明的splay)
the most advantages
动态树问题通常要求你对一棵树进行切割和拼接等操作,然后再在上面维护传统数据结构可维护的值
树剖做不了的软肋在于重儿子和重链早就剖分(预处理)好了
怎么添、删边?暴力重构所有重儿子和整个线段树?
100%GG
不用 L C T LCT LCT也能勉强做某些动态树问题了 (注意某些)
如果只有添边或只有删边且不要求强制在线的题目,用离线+树剖+splay/动态开点线段树是可以做的
虽说树剖勉强支持删边操作,但这毕竟不是最通用、最完美的做法
什么东西能真正完美地解决这一类动态树问题呢?
Link-Cut Tree算法
而且 L C T LCT LCT能做的除了动态树问题还有
-
任何树剖题
-
可支持删边的并查集
-
可做不用排序的 k r u s k a l kruskal kruskal(动态加边的 M S T MST MST并查集)
-
等……
我之前不是说过树上倍增能做的题树剖一定能做吗
而树链剖分能做的题 L C T LCT LCT也一定能做
LCA呢?
LCT是不可以求动态树上的LCA的……
为什么不能求?这个等下再说吧
LCT之模样与概念
看看样子先
这就是一个LCT
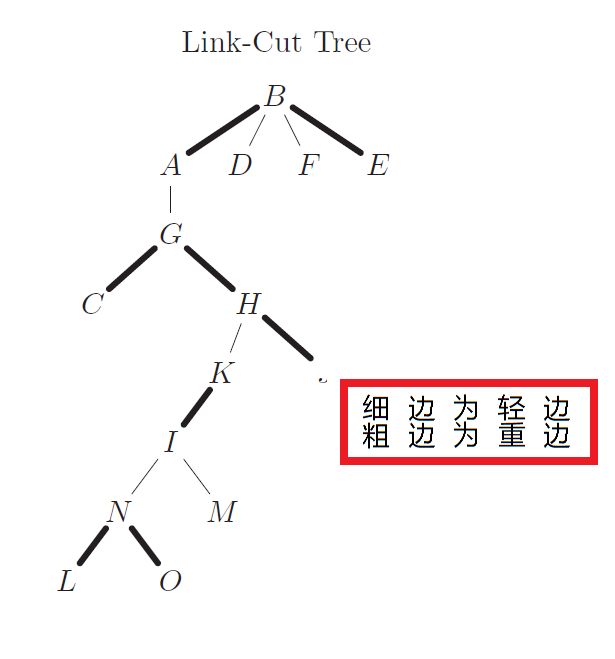
L C T LCT LCT维护的其实算是一个连通性森林
一些概念
- Preferred Child:重儿子,重儿子与父亲节点在同一棵splay中,一个节点至多一个重儿子
- Preferred Edge:重边,连接父亲节点和重儿子的边
- Preferred Path :重链,由重边及重边连接的节点构成的链
你看这个明显和树剖的东东一个鬼样所以可以略过
原来的那些名称都叫什么“偏好”XX的,感觉用树剖名词就可以了
接下来是 L C T LCT LCT里一个独♂特的东西
- Auxiliary Tree:辅助树
- 由一条重链上的所有节点所构成的Splay称作这条链的辅助树
- 每个点的键值为这个点的深度,即这棵Splay的中序遍历是这条链从链顶到链底的所有节点构成的序列
- 辅助树的根节点的父亲指向链顶的父亲节点,然而链顶的父亲节点的儿子并不指向辅助树的根节点
- (也就是说父亲不认轻儿子只认重儿子,儿子都认父亲)
- 这条性质为后来的操作提供了依据
上面框框里面是上网copy的,不知道怎么解释
必须注意辅助树(splay)的根≠原树的根
- 首先不要把LCT 真的当成一棵树
LCT不是树!!!是个森林OK?LCA都求不了这叫做树么?
在同一棵splay里面当然可以暴力求LCA,但这有意义么?
-
其次,为什么LCT里的点不认轻重儿子?
在一个splay里的点不就是父亲和重儿子和重儿子的重儿子……么? -
对上面的定义简单点说,在同一条“重链”里的所有点在一个splay中
不懂就看上面那个 L C T LCT LCT自己理解,如 B B B与 A A A和 E E E是在一个splay里的
这个明明很简单 -
splay过程中,树的形态可以变化如
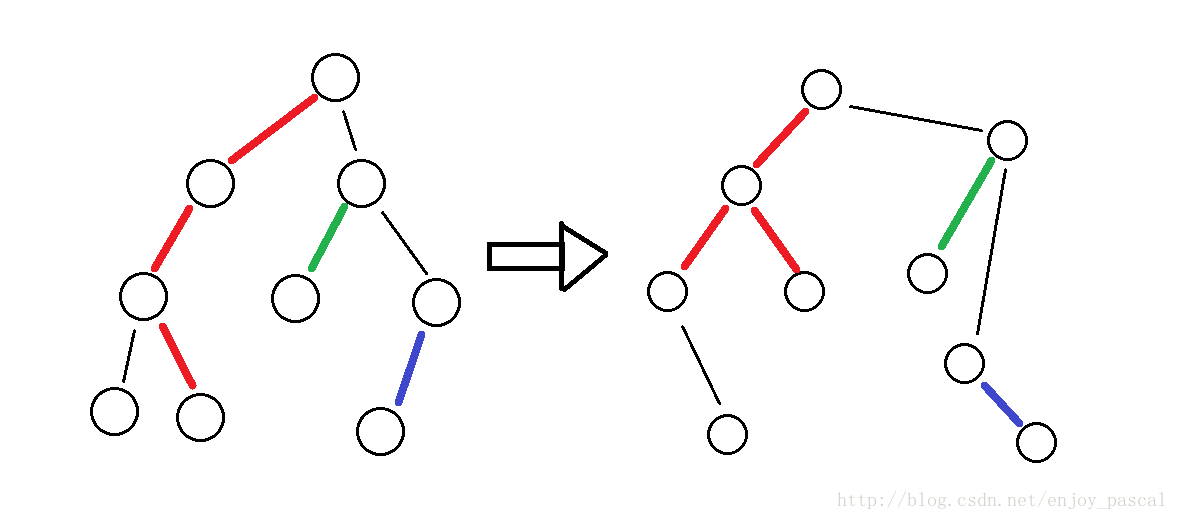
但是原树是不会变的
-
LCT还有个特点,就是不用记录节点编号
因为一个点的右儿子的深度是比它的大的,不像splay一样需要查找什么的:D -
其实更值得一提的是上面提到的虚边(也就是对应树剖的轻边)的那个东西
虚边 p f pf pf储存在一个splay的根节点, p f [ x ] pf[x] pf[x]为 x x x在LCT里的父亲(即在不在当前辅助树里的那个)
而 f a [ x ] fa[x] fa[x]则是splay中 x x x的父亲,不要把这个搞混
例子:图中 p f [ G ] = A pf[G]=A pf[G]=A而 f a [ G ] = 0 fa[G]=0 fa[G]=0, p f [ D ] = 0 pf[D]=0 pf[D]=0而 f a [ D ] = B fa[D]=B fa[D]=B
同样自己去看图理解懒得多说
可以这样想:两个重链是用一条虚边连接的,没有虚边不就成一条重链了么?
看完这些,其实LCT还是很简单的……
那么,不看懂概念怎么可以去学LCT的操作呢?
LCT之核心操作
请务必认认真真地阅读以下内容否则LCT你就学不会了
一句话说了N遍
operation 1:access
access操作是LCT里最基础、最重要的操作
定义 a c c e s s ( x ) access(x) access(x)操作就是把 x x x的重儿子与 x x x断开,然后把从整个LCT的根到 x x x之间的路径都变为重边
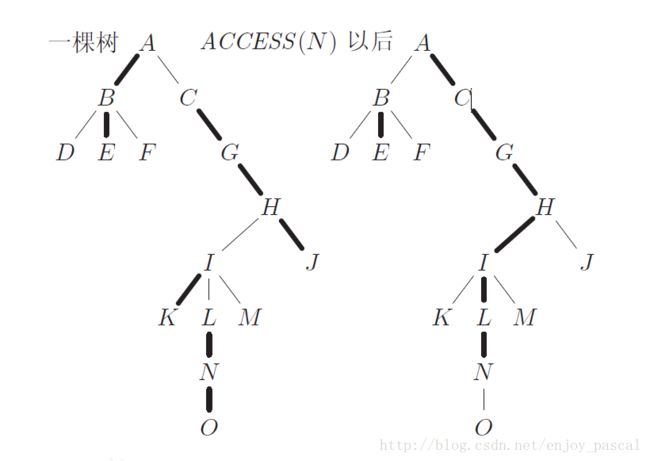
access操作其实是很简单的
-
若现在要 a c c e s s access access节点 x x x,每一次把 x x x旋转到当前辅助树的根
-
此时 x x x的右儿子深度比 x x x大,即右儿子是重儿子,我们自然而然的就要把它给删掉
-
把 x x x连上 p f [ x ] pf[x] pf[x]所在的辅助树 (splay) 里,然后 p f [ t [ x ] [ 1 ] ] = x , f a [ t [ x ] [ 1 ] ] = 0 pf[t[x][1]]=x,fa[t[x][1]]=0 pf[t[x][1]]=x,fa[t[x][1]]=0
-
简单点说就是把 x x x的右儿子作为辅助树的新根,并连一条向 x x x的虚边
-
重复以上操作,直到 p f [ x ] = f a [ x ] = 0 pf[x]=fa[x]=0 pf[x]=fa[x]=0
这个不简单吗?
时间复杂度呢?
-
tarjan老爷子说, s p l a y splay splay一次的时间复杂度是 O ( log 2 n ) O(\log_2n) O(log2n)
-
整个 a c c e s s access access要进行几次旋转操作呢?
-
把若干个小辅助树合并为一个大辅助树,只进行一次 s p l a y splay splay操作
-
由于 s p l a y splay splay均摊 O ( log 2 n ) O(\log_2n) O(log2n),又因为每次只对一个大的辅助树 s p l a y splay splay,我们可以
大胆想象得出只有 O ( log 2 n ) O(\log_2n) O(log2n)的时间 -
所以 a c c e s s access access操作的均摊时间是 O ( log 2 n ) O(\log_2n) O(log2n)
以后任何对access操作时间复杂度有疑问的请去找tarjan老爷子喝茶
问我没用
code
cc人生赢家的LCT好漂亮啊
void down(int x)
{
if (a[x].rev)
{
reverse(t[x][0]),reverse(t[x][1]);
a[x].rev=0;
}
}
void update(int x)
{
if(x)
{
a[x].size=a[t[x][0]].size+a[t[x][1]].size+1;
}
}
void downdata(int x)
{
while (x)st[++st[0]]=x,x=fa[x];
while (st[0])down(st[st[0]--]);
}
//从x到辅助树的根的整条路径上的边都要下传翻转标记
//……其实也就是暴力下传标记
int lr(int x)
{
return t[fa[x]][1]==x;
}
void rotate(int x)
{
int y=fa[x],k=lr(x);
t[y][k]=t[x][!k];
if(t[x][!k])fa[t[x][!k]]=y;
fa[x]=fa[y];
if(fa[y])t[fa[y]][lr(y)]=x;
t[x][!k]=y;
fa[y]=x;
pf[x]=pf[y];
update(y),update(x);
}
void splay(int x,int y)
{
//downdata(x);
while(fa[x]!=y)
{
if(fa[fa[x]]!=y)
{
if(lr(x)==lr(fa[x]))rotate(fa[x]);
else rotate(x);
}
rotate(x);
}
}
void access(int x)
{
for (int y=0;x;update(x),y=x,x=pf[x])
{
splay(x,0);
fa[t[x][1]]=0;
pf[t[x][1]]=x;
t[x][1]=y;
fa[y]=x;
pf[y]=0;
}
}
operation 2:makeroot
makeroot操作和access操作是LCT的最核心的操作
其他操作视题而定,但makeroot和access必不可少
定义 m a k e r o o t ( x ) makeroot(x) makeroot(x)操作就是将 x x x所在的splay翻转,使 x x x变为原LCT树的根
大概这样吧……
不算 a c c e s s access access的话 m a k e r o o t makeroot makeroot只有splay一次的时间复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n)
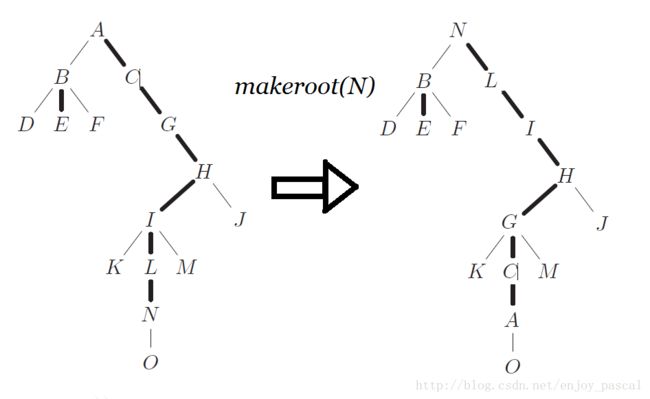
makeroot不就更简单了?
-
首先 a c c e s s ( x ) access(x) access(x)后,此时的 x x x是辅助树中深度最大的点,接着把 x x x旋转(splay)到LCT的根
-
而此时在辅助树中,除了 x x x的其他点都是其父亲的左儿子
-
然后再splay区间翻转即可,打上lazy-tag标记
-
然后 m a k e r o o t makeroot makeroot才成功解决,如上图的那种样子
code
void swap(int &x,int &y)
{
int z=x;
x=y;
y=z;
}
void reverse(int x)
{
if(x)
{
a[x].rev^=1;
swap(t[x][0],t[x][1]);
}
}
void down(int x)
{
if (a[x].rev)
{
reverse(t[x][0]),reverse(t[x][1]);
a[x].rev=0;
}
}
void makeroot(int x)
{
access(x);
splay(x,0);
reverse(x);
}
operation 3:link
link和cut嘛……所以LCT要叫Link-Cut Tree啊
定义 l i n k ( x , y ) link(x,y) link(x,y)操作就是将节点 x x x连到节点 y y y的儿子
link太简单了不想放图
link操作就太简单了
-
m a k e r o o t ( x ) makeroot(x) makeroot(x)后,此时 x x x是原LCT的根
-
此时 x x x没有 f a fa fa,而从 y y y连向 x x x会冲掉原来 y y y的 f a fa fa
-
所以从 x x x向 y y y连一条虚边,即 p f [ x ] = y pf[x]=y pf[x]=y
code
void link(int x,int y)
{
makeroot(x);
pf[x]=y;
}
operation 4:cut
定义 c u t ( x , y ) cut(x,y) cut(x,y)操作就是将节点 x x x(x是y的儿子)与父亲 y y y断开
cut太简单了也不想放图
cut和link其实很类似
-
m a k e r o o t ( x ) makeroot(x) makeroot(x)且 a c c e s s ( y ) access(y) access(y)后, x x x是原树的根,且 x x x和 y y y在同一splay里
-
然后 s p l a y ( x , 0 ) splay(x,0) splay(x,0),保证 x x x是根,又由于 x , y x,y x,y连通,所以此时 y y y是 x x x的右儿子
-
所以 t r e e [ x ] [ 1 ] = p f [ y ] = f a [ y ] = 0 tree[x][1]=pf[y]=fa[y]=0 tree[x][1]=pf[y]=fa[y]=0就好了
code
void cut(int x,int y)
{
makeroot(x);
access(y);
splay(x,0);
t[x][1]=fa[y]=pf[y]=0;
update(x);
}
operation 5:getroot
定义 g e t r o o t ( x ) getroot(x) getroot(x)为 x x x节点当前辅助树的根
退化版并查集路径压缩
g e t r o o t getroot getroot小学生级别难度
-
暴力把 x x x向上跳,直到 f a [ x ] = 0 fa[x]=0 fa[x]=0
-
没了
code
int getroot(int x)
{
while (fa[x])x=fa[x];
return x;
}
operation 6:judge
定义 j u d g e ( x , y ) judge(x,y) judge(x,y),若 x , y x,y x,y联通则为 T r u e True True,否则为 F a l s e False False
退化版并查集集合查询
比 g e t r o o t getroot getroot稍微难一丁点
-
m a k e r o o t ( x ) , a c c e s s ( y ) makeroot(x),access(y) makeroot(x),access(y)后, x x x为原树根, y y y打通到了最顶上的点(不一定是原树根)
-
若 x , y x,y x,y间联通,则 g e t r o o t ( y ) = x getroot(y)=x getroot(y)=x
-
所以询问 g e t r o o t ( y ) = x ? getroot(y)=x? getroot(y)=x?即可
code
bool judge(int x,int y)
{
makeroot(x);
access(y);
splay(x,0);
return getroot(y)==x;
}
Link-Cut Tree常规套路
和树剖的差不多, L C T LCT LCT的题目还是问你 x x x点到 y y y点间的路径路径和或者极值什么的
树剖很好做静态树的嘛
LCT怎么解决这类问题呢?
其实有常规套路
-
比如询问 x x x到 y y y间路径和
-
m a k e r o o t ( y ) makeroot(y) makeroot(y)后,再 a c c e s s ( x ) , s p l a y ( x , 0 ) access(x),splay(x,0) access(x),splay(x,0),此时 x x x和 y y y就在同一棵splay里了
-
然后这条路径不就任你摆布了?
注意事项
可以求LCA……才怪……
不考虑LCT求LCA的话会发现 L C T LCT LCT 很有某些优势
-
代码复杂度的排序,应该是倍增优、LCT稍劣一点、树剖很差
-
功能的排序当然是LCT最多、树剖少、倍增最少
突然发现LCT很好打、很好用?
- 时间复杂度的排序就是树剖最快、倍增较快、LCT龟速……
由于splay带来的巨大常数因子, L C T LCT LCT的时间大约是树剖的几倍……
比如这个
这是【ZJOI2008】树的统计
上面是树剖下面LCT,比对一下代码长度和时间
所以不要听tarjan那家伙BB说LCT时间很好
而且还有一个硬伤是求不了LCA
静态树上的两个点,LCA是唯一确定的,维护的值怎么变都没有影响LCA
splay的LCA是确定的么……
所以比赛里有动态树求LCA就赶快弃掉
点权、边权
由于 L C T LCT LCT使用灵活的 s p l a y splay splay维护数据,维护点权易如反掌
怎么维护LCT的边权呢?
可能先想到的是采取树剖思想,边权看成儿子的点权
- LCT也可以这么做么?
不行
由于 L C T LCT LCT的 s p l a y splay splay旋转,儿子旋转后就成为了父亲
那维护的权值不都乱套了?
解决方法很简单
把一条连接 x , y x,y x,y的边看成一个点,再把这个点和 x , y x,y x,y分别连起来
如此就可以维护LCT的边权了
必须注意要开两倍空间!
事实证明LCT非常好用
所以需要海量例题来让你刻骨铭心
例题1:【BZOJ2049】【luoguP2147】[SDOI2008]洞穴勘测
problem
题目描述
辉辉热衷于洞穴勘测。
某天,他按照地图来到了一片被标记为JSZX的洞穴群地区。经过初步勘测,辉辉发现这片区域由n个洞穴(分别编号为1到n)以及若干通道组成,并且每条通道连接了恰好两个洞穴。假如两个洞穴可以通过一条或者多条通道按一定顺序连接起来,那么这两个洞穴就是连通的,按顺序连接在一起的这些通道则被称之为这两个洞穴之间的一条路径。
洞穴都十分坚固无法破坏,然而通道不太稳定,时常因为外界影响而发生改变,比如,根据有关仪器的监测结果,123号洞穴和127号洞穴之间有时会出现一条通道,有时这条通道又会因为某种稀奇古怪的原因被毁。辉辉有一台监测仪器可以实时将通道的每一次改变状况在辉辉手边的终端机上显示:
如果监测到洞穴u和洞穴v之间出现了一条通道,终端机上会显示一条指令 Connect u v
如果监测到洞穴u和洞穴v之间的通道被毁,终端机上会显示一条指令 Destroy u v
经过长期的艰苦卓绝的手工推算,辉辉发现一个奇怪的现象:无论通道怎么改变,任意时刻任意两个洞穴之间至多只有一条路径。
因而,辉辉坚信这是由于某种本质规律的支配导致的。因而,辉辉更加夜以继日地坚守在终端机之前,试图通过通道的改变情况来研究这条本质规律。
然而,终于有一天,辉辉在堆积成山的演算纸中崩溃了……他把终端机往地面一砸(终端机也足够坚固无法破坏),转而求助于你,说道:“你老兄把这程序写写吧”。辉辉希望能随时通过终端机发出指令 Query u v,向监测仪询问此时洞穴u和洞穴v是否连通。现在你要为他编写程序回答每一次询问。
已知在第一条指令显示之前,JSZX洞穴群中没有任何通道存在。输入输出格式
输入格式: 第一行为两个正整数n和m,分别表示洞穴的个数和终端机上出现过的指令的个数。
以下m行,依次表示终端机上出现的各条指令。每行开头是一个表示指令种类的字符串s("Connect”、”Destroy”或者”Query”,区分大小写),之后有两个整数u和v
(1≤u, v≤n且u≠v) 分别表示两个洞穴的编号。输出格式: 对每个Query指令,输出洞穴u和洞穴v是否互相连通:是输出”Yes”,否则输出”No”。(不含双引号)
输入输出样例
输入样例#1: 复制 200 5 Query 123 127 Connect 123 127 Query 123 127 Destroy
127 123 Query 123 127 输出样例#1: 复制 No Yes No 输入样例#2: 复制 3 5 Connect 1 2
Connect 3 1 Query 2 3 Destroy 1 3 Query 2 3 输出样例#2: 复制 Yes No 说明数据说明
10%的数据满足n≤1000, m≤20000
20%的数据满足n≤2000, m≤40000
30%的数据满足n≤3000, m≤60000
40%的数据满足n≤4000, m≤80000
50%的数据满足n≤5000, m≤100000
60%的数据满足n≤6000, m≤120000
70%的数据满足n≤7000, m≤140000
80%的数据满足n≤8000, m≤160000
90%的数据满足n≤9000, m≤180000
100%的数据满足n≤10000, m≤200000
保证所有Destroy指令将摧毁的是一条存在的通道
本题输入、输出规模比较大,建议c\c++选手使用scanf和printf进行I\O操作以免超时
analysis
-
……智障题
-
这题是最普通的link、cut操作和判断联通
-
m a k e r o o t ( x ) , a c c e s s ( y ) makeroot(x),access(y) makeroot(x),access(y)后,判断 g e t r o o t ( y ) = x ? getroot(y)=x? getroot(y)=x?即可
-
不要告诉我说不知道怎么link和cut
code
#include例题2:【luoguP3203】 [HNOI2010]弹飞绵羊
problem
题目描述
某天,Lostmonkey发明了一种超级弹力装置,为了在他的绵羊朋友面前显摆,他邀请小绵羊一起玩个游戏。游戏一开始,Lostmonkey在地上沿着一条直线摆上n个装置,每个装置设定初始弹力系数ki,当绵羊达到第i个装置时,它会往后弹ki步,达到第i+ki个装置,若不存在第i+ki个装置,则绵羊被弹飞。绵羊想知道当它从第i个装置起步时,被弹几次后会被弹飞。为了使得游戏更有趣,Lostmonkey可以修改某个弹力装置的弹力系数,任何时候弹力系数均为正整数。
输入输出格式
输入格式: 第一行包含一个整数n,表示地上有n个装置,装置的编号从0到n-1。
接下来一行有n个正整数,依次为那n个装置的初始弹力系数。
第三行有一个正整数m,
接下来m行每行至少有两个数i、j,若i=1,你要输出从j出发被弹几次后被弹飞,若i=2则还会再输入一个正整数k,表示第j个弹力装置的系数被修改成k。
输出格式: 对于每个i=1的情况,你都要输出一个需要的步数,占一行。
输入输出样例
输入样例#1: 复制 4 1 2 1 1 3 1 1 2 1 1 1 1 输出样例#1: 复制 2 3 说明
对于20%的数据n,m<=10000,对于100%的数据n<=200000,m<=100000
analysis
-
LCT板子题
-
我们可以建一个 n + 1 n+1 n+1号节点, x x x号节点连到表示 n + 1 n+1 n+1号节点就表示被弹飞
-
若要更改,直接先 c u t cut cut再 l i n k link link一波,关键怎么询问弹飞几次呢?暴力splay?
-
我们可以 m a k e r o o t ( n + 1 ) makeroot(n+1) makeroot(n+1),使 n + 1 n+1 n+1号节点变为原LCT的根
-
接着我们 a c c e s s ( x ) access(x) access(x)后 s p l a y ( x , 0 ) splay(x,0) splay(x,0),也就是把 x x x旋转到原树的根
-
那么 x x x号节点会弹 x s i z e − 1 x_{size}-1 xsize−1次被弹飞,但是为什么呢?
-
由于辅助树按照深度关键字排序,所以x的子树大小-1就是要被弹飞几次了
-
所以明显正确
code
#include例题3:【JZOJ2256】【ZJOI2008】树的统计
problem
题目上面有所以就不重新贴了
analysis
-
前面是用树剖做的,现在用LCT重做了一次
-
其实LCT的代码复杂度简直秒杀树剖好伐 -
都说了LCT能做所有树剖题,然而这题连cut操作都没有
-
那不就简单了?
-
像普通套路一样,询问 x , y x,y x,y间的路径极值或权值和,就 m a k e r o o t ( y ) , a c c e s s ( x ) , s p l a y ( x , 0 ) makeroot(y),access(x),splay(x,0) makeroot(y),access(x),splay(x,0)
-
然后直接输出 a [ x ] . X X X a[x]._{XXX} a[x].XXX就好了
-
至于修改 x x x节点的操作,把 x x x旋到根,直接修改即可
然而WA90
-
为什么呢?
-
每次输入的时候,都要把当前节点旋到根,读入后再 u p d a t e update update
-
这样才终于切了
code
#include