集体智慧编程-分级聚类算法代码理解
首先要明确一个概念,分级聚类算法实际上就是根据节点之间的距离构造一棵二叉树
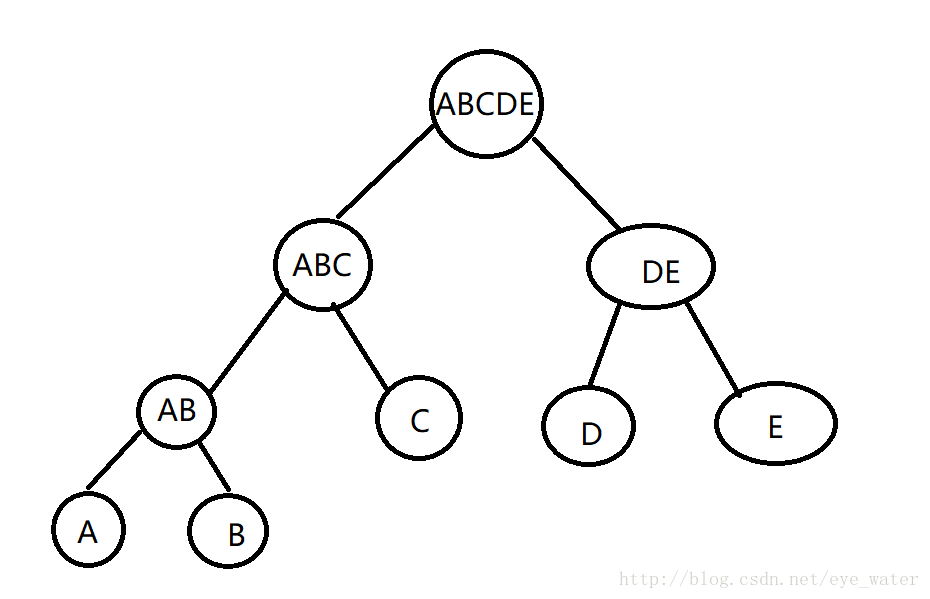
举个例子,根据下图通过距离构造一棵二叉树
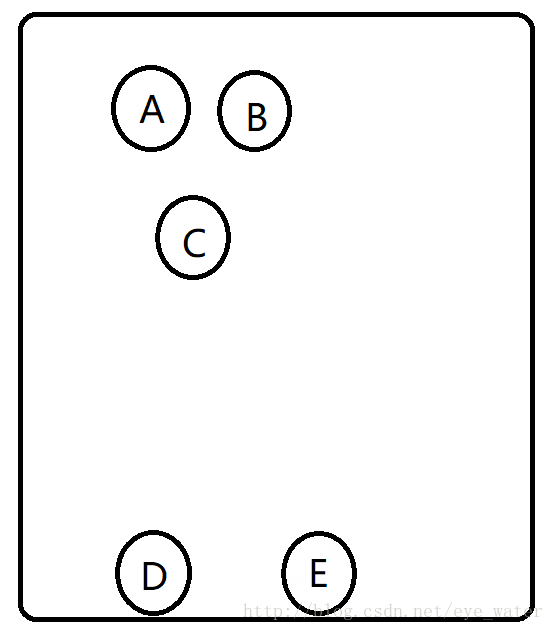
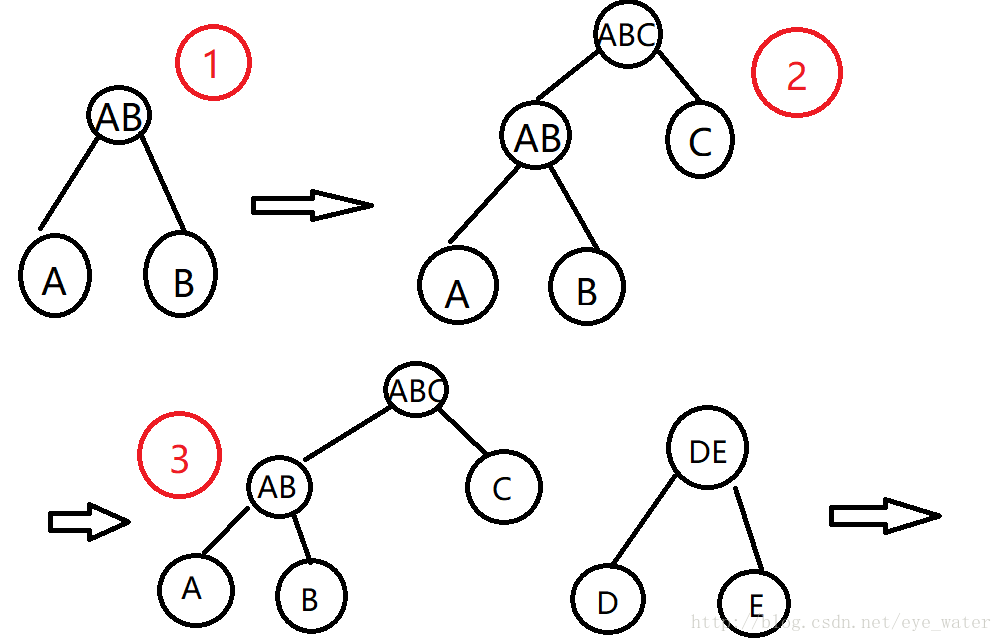
- A和B是图中所有点中距离最近的两点
- 在A和B构成一棵子树AB后,图中最近的两点是AB和C
- AB和C构成子树ABC后,图中最近的两点是D和E
- D和E构成子树DE后,最近的就是ABC和DE,至此,二叉树构造完成
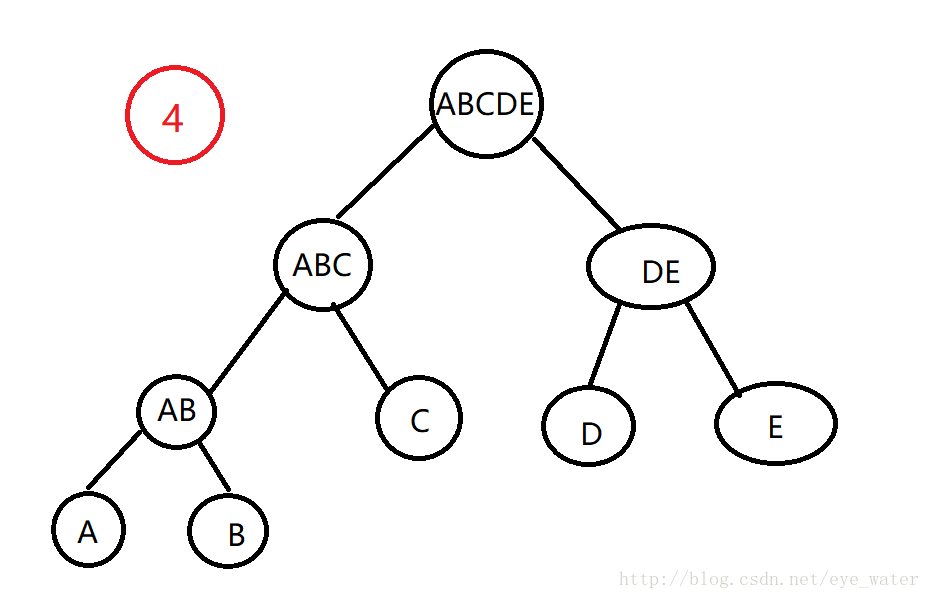
而在书中关于聚类的代码中,叶节点就是博主所用的每个单词的次数
| Blog | app | Android |
|---|---|---|
| people | 100 | 80 |
在上图所示的表中,叶节点就是
['100', '80']关于RSS订阅源的分析存放在了文件中看起来就像下面这样
| Blog | app | Android | … |
|---|---|---|---|
| People1 | 100 | 80 | … |
| People2 | 235 | 150 | … |
| … | … | … | … |
数据集在这里
表格看起来一目了然,但对于程序来说根本不知道输入的是啥,要做一个映射,把博主名映射到一个一维列表,单词映射到一个一维列表,统计的数字映射到一个二维列表。
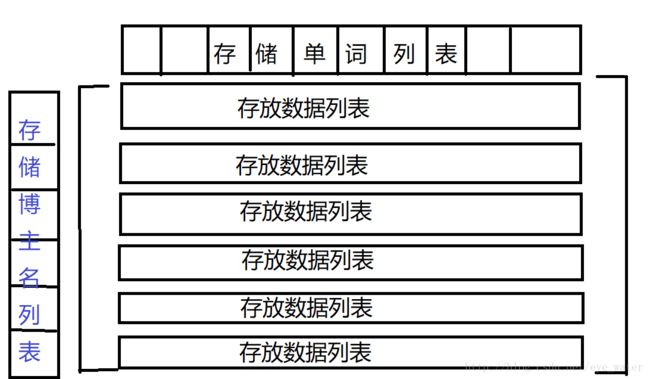
这样我们就可以只通过行下标以及列下标定位到某一位博主使用某个单词的次数,或者二维列表的下标定位到某位博主。
以上就是看懂分级聚类算法的基础知识
代码详解
核心1
用类表示一棵子树
class bicluster(object):
def __init__(self, vec, left=None, right=None, distance=0.0, id=None):
self.vec = vec
self.left = left
self.right = right
self.distance = distance
self.id = id变量意义
vec
博主使用单词的次数的列表如['80', '100']
left
左子树,初始为None,初始都是叶节点
right
右子树,初始为None
distance
最近两点之间的距离,初始为0.0
id
二维列表的下标,用来标识当前叶节点
核心2
找最短距离,构造子树,子树构造完成后,在初始构造的叶节点中删除构造子树所用的节点,再把子树加入到初始构造的叶节点当中
构造完子树再把子树加入到叶节点中,并不意味着子树就是叶节点,子树包含了左子树或者叶节点以及右子树或者叶节点,把子树加入到叶节点中是为了寻找最短距离
给出一棵二叉树
抽象为列表
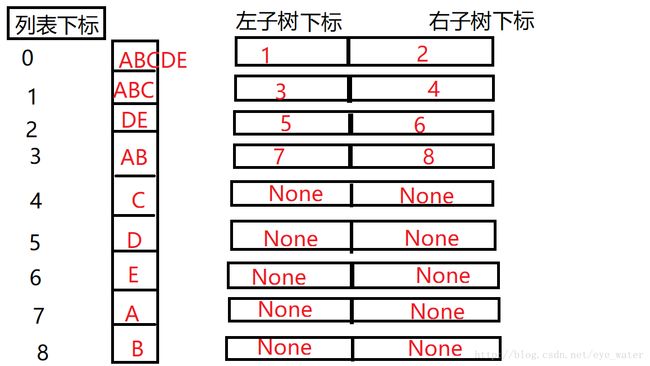
Tree = [['1', '2'], ['3', '4'], ['5', '6'], ['7', '8'], ['None', 'None'], ['None', 'None'], ['None', 'None'], ['None', 'None']]如何找最短距离
利用二重循环,把当前叶节点与所有的叶节点之间的距离进行比较,找出最短,在二重循环之前,要假设一个最小值,以及取这个最小值时叶节点分别是二维列表下标0和1所对应的列表,这样便于比较。
为了减少二重循环的计算量,每次计算一个距离都把它保存在一个字典中
distances = {}字典的键为两个叶节点在二维列表里的下标
distances[(clusters[i].id, clusters[j].id)]对于新生成的子树,需要为子树设置一个标识符id,每进行一轮循环,都会生成一个子树,标识符即id依次设为-1,-2,-3…
currentclustid = -1
for i in range(len(clust)):
...
currentclustid -= 1对于整个函数,传入的是二维列表
def hcluster(rows, distance=person):
distances = {}
currentclustid = -1
clust = [bicluster(rows[i], id=i) for i in range(len(rows))]
while len(clust) > 1:
lowestpair = (0, 1)
closest = distance(clust[0].vec, clust[1].vec)
for i in range(len(clust)):
for j in range(i+1, len(clust)):
if (clust[i].id, clust[j].id) not in distances:
distances[(clust[i].id, clust[j].id)] = distance(clust[i].vec, clust[j].vec)
d = distances[(clust[i].id, clust[j].id)]
if d < closest:
closest = d
lowestpair = (i, j)
mergevec = [
(clust[lowestpair[0]].vec[i] + clust[lowestpair[1]].vec[i])/2.0
for i in range(1542)]
newclust = bicluster(mergevec, left=clust[lowestpair[0]],
right=clust[lowestpair[1]], distance=closest, id=currentclustid)
currentclustid -= 1
clust.pop(lowestpair[1])
clust.pop(lowestpair[0])
clust.append(newclust)
return clust[0]在计算时应注意叶节点所表示的列表长度不一定一样,因为在存储数据时难免会发生错误,因此取两个列表长最短的那一个作为长度即可