深度优先搜索(DFS)学习
概念的理解:
对于一个复杂的问题,以一个子问题作为根节点,把全部的可能都求出来,这其中的一个过程就叫做深度优先搜索,而这种方法叫做穷举法。
二叉搜索树:

二叉搜索树的概念:每个节点都大于它的左节点和小于它的右节点。
从DFS概念的角度说,5->1;5->4->3,5->4->6,这就是这个图全部的解(可能)。
然后就是对于二叉树的操作问题:
构造二叉树的框架:
代码:
struct Node {
Node *parent; //自己的父节点
Node *left;
Node *right;
int val;
Node(int k):val(k),left(NULL),right(NULL) //定义一个新的节点,val为k,左右节点为空;
}遍历:
思路:使用前中后序进行遍历即可;
代码(使用的是前序遍历):
void traversals(Node *root, vector vec) {
vec.push_back(root->val);
traversals(root->left, vec);
traversals(root->right, vec);
} 查找(Find)
找到特定节点k:
目标:找到节点的值为k的节点;
思路:比较节点和目标节点,如果相等返回节点,如果大于就找到节点的左节点,如果小于就找到节点的右节点;
代码:
Node *FindByVal(Node *root,int k) {
Node *tmp=root;
while(tmp!=nullptr) {
if(tmp->val>k) {
tmp=tmp->left;
} else if(tmp->valright;
} else {
return tmp;
}
}
cout<<"can't find k"<val==k) {
return tmp;
}
tmp=kval?tmp=tmp->left?tmp=tmp->right;
}
cout<<"can't find k"< 找到特定节点的前驱和后继:
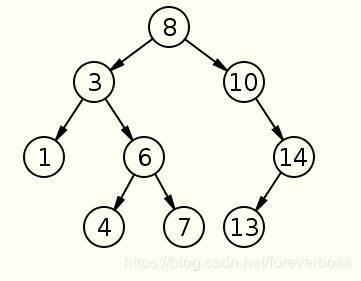
(1).前驱的概念:小于特定节点值中最大值的节点,实例中的理解就是中序排列中特定节点的前一个节点。
思路:
1.如果特定节点有左节点,则找到左节点中的最右的节点,返回即可;
2.如果特定节点中没有左节点,则找到第一个有右节点且左节点中没有特定节点的祖先,即最后一个符合条件的节点。
代码:
Node *findPreNode(Node *n) {
if (n->left) {
n = n->left;
while (n->right) {
n = n->right;
}
return n;
}
while (n->parent&&n->parent->left == n) { //第二种情况时,注意n的位置和n向上移动的时间,很容易错误的返回空值(别问我为什么会知道。。。)
n = n->parent;
}
return n->parent;
}
Node *findPreNodeByVal(int k) {
return findPreNode(FindByVal(k));
}(2).后继的概念:大于特定节点值中的最小值,其余和左节点概念都相反,文字说明略,直接上代码。
代码:
Node *findNextNode(Node *n) {
if (n->right) {
n = n->right;
while (n->left) {
n = n->left;
}
return n;
}
while (n->parent&&n->parent->right == n) {
n = n->parent;
}
return n->parent;
}
Node *findNextNodeByVal(int k) {
return findNextNode(FindByVal(root,k));
}注意:这里前驱后继的概念只适用于二叉搜索树,或者符合二叉搜索树性质的树;
插入(insert)
思路:通过二叉搜素数性质,比较找到插入的位置,也要把新插入的节点的parent赋值(注意的是:二叉搜索树不允许存在相同的数)
代码:
void *insertNode(Node *n) {
Node *tmp = root;
if (tmp == nullptr) {
root = n;
return;
}
while (true) {
if (tmp->val > n->val) {
if (tmp->left) {
tmp = tmp->left;
}
else {
tmp -> left = n;
n->parent = tmp;
return;
}
}
else if(tmp->val > n->val) {
if (tmp->right) {
tmp = tmp->right;
}
else {
tmp->right = n;
n->parent = tmp;
return;
}
}
else {
return;
}
}
}
Node *insertNodeByVal(int k) {
return findPreNode(FindByVal(root,k));
}删除
思路:二叉搜索树的删除比较复杂,要以删除节点的节点数来分情况逐步分析:
- 删除节点没有左右节点:
- 直接删除节点即可
- 删除节点只有一个左节点或者右节点
- 把n左或右节点赋值给tmp,不要忘了parent节点的赋值
- 判断删除节点是否为根节点
- 判断n在其父节点的位置,再进行删除
- 删除节点有左右节点
- 首先需要一个tmp_right来记录tmp的右节点
- 判断tmp在其父节点的哪个位置(左或右节点),再把tmp_right赋值给tmp
- 最后再把tmp的节点值赋值给n,就可以把tmp节点删除了
代码:
void deleteNode(Node *n) {
Node *tmp;
if (n->left == nullptr&&n->right == nullptr) { //没有左右节点的情况
tmp = n;
}
else if (n->left || n->right) { //只有一个节点的情况
tmp = n->left == nullptr:n->right ? n->left;
tmp->parent = n->parent;
}
else { //自然就是两个节点的情况
tmp = findNextNode(n); //找到n后续节点
Node *tmp_right;
tmp_right = tmp->right == nullptr:nullptr ? tmp->right; //被赋值tmp->right
if (tmp_right) {
tmp_right->parent = tmp->right->parent; //不要忘了parent的赋值
}
if (tmp -> parent->left == tmp) { //判断tmp在其父节点的位置
tmp->parent->left = tmp_right;
}
else {
tmp->parent->right = tmp_right;
}
n->val = tmp->val;
delete tmp;
return;
}
if (n->parent != nullptr) { //在不是根节点的处理
if (n->parent->left == n) {
n->parent->left = tmp;
}
else {
n->parent->right = tmp;
}
}
else { //是根节点的处理
root = tmp;
}
delete n; //如果没有节点,直接删除;
return;
}验证二叉树(leetcode-98)
- 直接法(递归思想):直接递归判断是否符合二叉搜索树性质
- 间接法(转化成中序遍历,再判断)
代码:
//直接法
void bool isValidBST(Node* root) {
return isVaild(root, NULL, NULL);
}
bool isVaild(Node *root, int min, int max) {
if (root->val < min) {
return false;
}
if (root->val > max) {
return false;
}
return isVaild(root->left, min, root->val) && isVaild(root->right, root->val, max);
}
//间接法
bool isValidBST(Node* root) {
if (!root) {
return true;
}
vector vec;
inorder(root, vec);
for (int i = 1;i < vec.size();i++) {
if (less(vec[i], vec[i - 1]))
return false;
}
return true;
}
void inorder(Node *root, vector vec) {
if (!root) {
return;
}
inorder(root->left, vec);
vec.push_back(root->val);
inorder(root->right, vec);
} 二叉搜素数中的众数(leetcode-501)
这题看起来很简单,但是对于我这些新手来说还是有很多细节需要注意的
思路:使用中序排列存储数据,然后求出出现频率最多的数,要边存边计算
解析:逻辑很简单,但是要注意一下的细节:
- 空引用
- 部分要使用传引用的方法
- 使用时不能存在空引用(报错)
- 全局变量:如果使用的类型不能使用传引用方法,就可以使用全局变量
- 赋值的位置:pre=root和max=count的位置,当count>=max时就要更新max值,在判断完pre->val==root->val后才能更新pre
- 自增问题:在count=root->val==pre->val?count+1:1中,不要使用count++赋值
- 效率:不要在递归中执行上面的判断,这样效率会很低,同样的思路我用了60ms,别人是12ms
代码:
vector vec;
int max=0,count=1;
vector findMode(TreeNode* root) {
TreeNode* pre=NULL;
SearchNode(root,pre);
return vec;
}
void SearchNode(TreeNode* root,TreeNode* &pre) {
if(!root) {
return;
}
SearchNode(root->left,pre);
if(pre) {
count=root->val==pre->val?count+1:1;
}
if(count>=max) {
if(count>max) {
vec.clear();
}
vec.push_back(root->val);
max=count;
}
pre=root;
SearchNode(root->right,pre);
} 恢复二叉搜索树(leetcode-99)
思路1:一开始我没有看全题目的意思,没有看到只有两个错误的节点,所以我一开始的想法是,每找到一个错误的节点就和根节点进行交换,直至全部节点都正确;但是这个思路最大的问题是如何设置循环,在你递归完左右两边时,你要重新验证一次你是否全部正确了,不正确的话再重新递归;我试过使用标记点法,在递归完一次后,我把树再中序排列一次,再用一个函数判断是否呈递减排列,没有就再递归;(但是事实证明了这个方法是错误的,至于为什么我也不知道。。。)
我的错误代码:
//我的leetcode-99代码
//思路:转化交换,循环判断中序排列是否成立;
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
vector vec;
bool flag=false;
public:
void recoverTree(TreeNode* root) {
while(!flag) {
TreeNode *tmp=root;
changeMin(tmp->left,root);
changeMax(tmp->right,root);
inorder(root,vec);
flag=isVaild(vec);
}
}
void changeMin(TreeNode *tmp,TreeNode *root) {
if(!tmp)
return;
if(tmp->val>root->val) {
swap(tmp->val,root->val);
}
changeMin(tmp->left,root);
changeMin(tmp->right,root);
}
void changeMax(TreeNode *tmp,TreeNode *root) {
if(!tmp)
return;
if(tmp->valval) {
swap(tmp->val,root->val);
}
changeMax(tmp->left,root);
changeMax(tmp->right,root);
}
void inorder(TreeNode *root,vector vec) {
if(!root)
return;
inorder(root->left,vec);
vec.push_back(root->val);
inorder(root->right,vec);
}
bool isVaild(vector vec) {
for(int i=1;ivec[i]) {
return false;
}
}
return true;
}
}; 思路二:在我发现只有两个错误节点的时候就很快就有思路了,从头到尾遍历,找到第一个错误的节点,然后在从尾到头遍历,找到第一个错误的节点,这样两个节点就不会重复,且找到了两个节点,最后就是交换两个错误节点。
解析:思路很简单,但是还要注意一下细节:
- 在中序遍历中,我们存的是树的节点,而不是树的节点值
- 在交换的时候,则是交换节点值不是节点
- 两个错误节点记得不要找错节点了,第一个是vec[i-1],第二个是vec[i]
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
vector vec;
public:
void inorder(TreeNode *root,vector &vec) {
if(!root)
return;
inorder(root->left,vec);
vec.push_back(root);
inorder(root->right,vec);
}
void recoverTree(TreeNode* root) {
inorder(root,vec);
TreeNode *prtOne,*prtTwo;
for(int i=1;ival>vec[i]->val) {
prtOne=vec[i-1];
break;
}
}
for(int i=vec.size()-1;i>=1;i--) {
if(vec[i]->valval) {
prtTwo=vec[i];
break;
}
}
int tmp;
tmp=prtOne->val;
prtOne->val=prtTwo->val;
prtTwo->val=tmp;
}
}; 思路3:我会使用5个节点来完成这个思路,分别存放第一次出现错误节点的位置和它的前驱,第二次出现错误节点的位置和它的前驱(如果有的话),最后一个来寻找错误节点的;
解析:这个思路的效率会比思路2的快,第一次存放的错误节点和他的前驱是为了如果没有第二次的错误节点,就直接交换错误节点和他的前驱节点即可,如果有第二个错误节点,就交换第一个错误节点和第二个错误节点,那第二个错误节点的前驱就是来判断有没有第二个错误节点的根据;
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
static const auto speedUp = []()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
return 0;
}();
class Solution {
TreeNode *p1,*p2,*p3,*p4,*last;
public:
void inorder(TreeNode *root) {
if(!root || p1&&p3) {
return;
}
inorder(root->left);
if(last && last->val>root->val) {
if(!p1) {
p1=last;
p2=root;
} else {
p3=last;
p4=root;
}
}
last=root;
inorder(root->right);
}
void recoverTree(TreeNode* root) {
inorder(root);
TreeNode *tmp1=p1;
TreeNode *tmp2=!p3?p2:p4;
swap(tmp1->val,tmp2->val);
}
};代码前面的static const auto speedUp = []()是为了提高效率的;
相同的树(leetcode-100)
思路:很简单的题,直接用递归就可以完成了
解析:我一开始想到的是用 vector
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
vector vec1,vec2;
public:
bool isSameTree(TreeNode* p, TreeNode* q) {
if(!p&&!q) {
return true;
} else if(p&&!q) {
return false;
} else if(!p&&q) {
return false;
} else {
if(p->val!=q->val) {
return false;
}
}
return isSameTree(p->left,q->left)&&isSameTree(p->right,q->right);
}
}; 对称二叉树(leetocde-101)
思路:先找到判断对称的规律,规律就是在对称的节点,分别比较一个的左节点和另一个的右节点,还有一个的右节点和另一个的左节点即可,这样我们就可以使用递归的方法,判断每个子对称对节点是否符合条件。
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isSymmetric(TreeNode* root) {
if(!root) {
return true;
}
return flag(root->left,root->right);
}
bool flag(TreeNode *root,TreeNode *tmp) {
if(!root&&!tmp) {
return true;
} else if(!root||!tmp) {
return false;
}
return root->val==tmp->val&&flag(root->left,tmp->right) && flag(root->right,tmp->left);
}
};易错点:在递归函数flag中,我们会先判断root和tmp会不会同时为空,再判断会不会其中一个为空。
二叉树的最大,最小深度(leetcode-104,leetcode-111)
我的思路:当然我首先想到的就是使用递归方法,但是在回溯记录深度的地方我卡住了。
网上思路:其实根本就不用记录什么回溯的深度,直接找出左右节点的最大值加一即可。
解析:仔细分析代码的过程就会发现,每次找出分别的左右最大支点时,加一即是它们目前的最大深度。但是当你要找最小深度时就不能直接找左右节点的最小值了,因为如果根节点只有左或右节点时,就会只返回1,没有达到最小深度的定义,所以最小深度的寻找我们还要加一些额外的判断。
最大深度代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
int gen=0;
int pregen=0;
public:
int maxDepth(TreeNode* root) {
if(!root) {
return 0;
}
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};最小深度代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int minDepth(TreeNode* root) {
if(!root) {
return 0;
}
if(root->left&&root->right) {
return min(minDepth(root->left),minDepth(root->right))+1;
} else if(root->left) {
return minDepth(root->left)+1;
} else if (root->right) {
return minDepth(root->right)+1;
} else {
return 1;
}
}
};从前序和中序遍历来构建二叉树(leetcode-105)
在我们实际的计算中,知道前中序来求二叉树,先找出根节点在中序的位置,在根的左边则是左节点,在根的右边就是右节点,那么计算机的总体思路和我们的是差不多的,也是要找到根在中序遍历中的位置,只是位置关系要使用数学归纳法就比较困难一些。
网上的代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* buildTree(vector& preorder, vector& inorder) {
int sz=preorder.size()-1;
return dfs(preorder,inorder,0,0,sz);
}
TreeNode *dfs(vector &preorder,vector &inorder,int pre,int intl,int intr) {
if(intl==intr) {
return new TreeNode(preorder[pre]);
}
if(intl>intr) {
return NULL;
}
TreeNode *root=new TreeNode(preorder[pre]);
int index=intl;
while(preorder[pre]!=inorder[index] && indexleft=dfs(preorder,inorder,pre+1,intl,index-1);
root->right=dfs(preorder,inorder,pre+index-intl+1,index+1,intr);
return root;
}
}; 解析代码:
代码的主要思路是使用pre来表示根节点,intl表示根节点的左边,intr就是右边,当intl==intr时,证明这是叶节点,则直接放回该节点,如果不等,则找到根节点在中序的位置,使用递归遍历根的左右节点。主要的难点是递归时,左右节点位置的定义:
- 左边的根节点表示:pre+1,根节点左边表示:intl,右边表示:index-1;
- 右边的根节点表示:pre+index-intl+1,根节点左边表示:index+1,右边表示:intr;
-待续(更新至3.15 17:00)