NO.43------QQ音乐爬虫
写在前面
之前写过QQ音乐的爬虫,但是近期再次运行,发现已经失效,经分析,是之前的音乐接口已经失效,因此重新操刀,决心与QQ音乐斗智斗勇到底,其实这也是作为程序猿的乐趣嘛。
分析网页
a.音乐播放接口
依然是谷歌浏览器打开qq音乐,可以尝试搜索神曲“卡路里”:
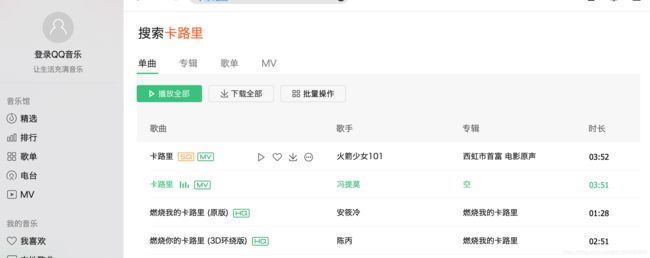
开发者模式下截获各个请求,这里教大家一个技巧,查找Status Code=206的请求,它一般代表音视频的请求。
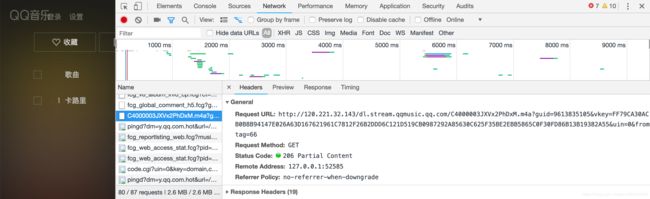
仔细查看这个请求,经过剔除不必要的参数,筛选出音乐下载接口:
http://dl.stream.qqmusic.qq.com/C4000003JXVx2PhDxM.m4a?guid=9613835105&vkey=FF79CA30ACB0B8B94147E026A63D167621961C7812F26B2DDD6C121D519CB0987292A85630C625F35BE2EBB5865C0F30FD86B13B19382A55复制到浏览器打开:
 经过验证,这的确是我们想要的QQ音乐下载接口。
经过验证,这的确是我们想要的QQ音乐下载接口。
分析以上接口,其中有三个参数是未知来源的:
- C400+songmid
- guid
- vkey
现在我们逐个参数进行分析:
搜索mid,看看哪个请求包含这个参数:
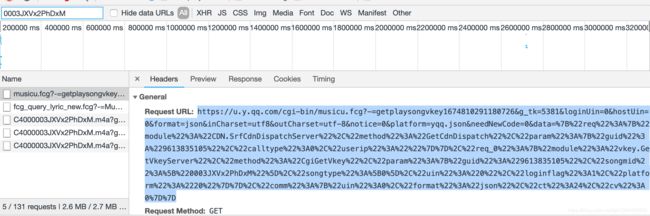
看到这个请求是经过URL编码得到的,这难不倒我们,进行在线的URL解码:
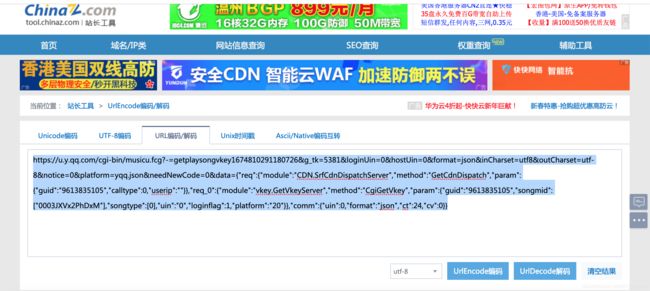
剔除不必要的参数:
https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey21720377094369425&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"9613835105","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"9613835105","songmid":["002MXZNu1GToOk"],"songtype":[0],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":0,"format":"json","ct":24,"cv":0}}复制这个接口打开,没错,是我们想要的数据,这就是我们想要的音乐搜索接口。
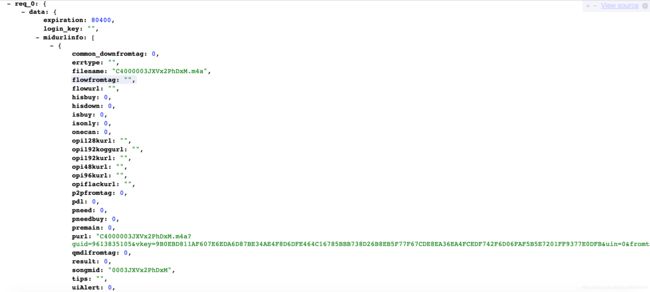
在这里,有额外发现,这个接口里的purl值再组合上sip里的域名 http://dl.stream.qqmusic.qq.com/ 就形成了完整了音乐播放接口。那么我们仔细分析下这个接口,再次打开另一个歌曲,看看音乐搜索接口有什么规律:
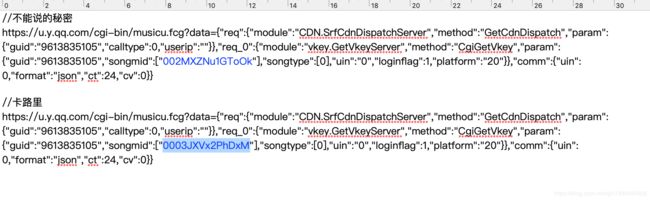
对比两首歌的接口,可见只有一个参数 songmid 是改变的,其余都是常量。现在 已经理清了逻辑,想要下载歌曲,只要将sip+purl即可。sip是已知的,purl需要构建音乐搜索接口即可。构建音乐搜索接口需要songmid和guid两个参数。guid是从cookies中获得,这是一种常见的反爬方式,我们可以通过请求歌手页面获得这个参数,那么假如知道某个歌曲的songmid就能实现歌曲下载。
代码实现
import requests, time
import math
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
# 创建请求头和会话
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
session = requests.session()
# 下载歌曲
def download(guid, songmid,cookie_dict):
# 参数guid来自cookies的pgv_pvid
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey11136773093082608&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"'+guid+'","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"'+guid+'","songmid":["'+songmid+'"],"songtype":[0],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":0,"format":"json","ct":24,"cv":0}}'
print(url)
r = session.get(url, headers=headers,cookies=cookie_dict)
purl = r.json()['req_0']['data']['midurlinfo'][0]['purl']
# 下载歌曲
if purl:
url = 'http://isure.stream.qqmusic.qq.com/%s' %(purl)
r = requests.get(url, headers=headers)
f = open('song/' + songmid + '.m4a', 'wb')
f.write(r.content)
f.close()
return True
else:
return False
def getCookies():
# 某个歌手的歌曲信息,用于获取Cookies,因为不是全部请求地址都有Cookies
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.top&searchid=20194704345758042&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%86%AF%E6%8F%90%E8%8E%AB&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
chrome_options = Options()
# 设置浏览器参数
# --headless是不显示浏览器启动以及执行过程
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options)
# 访问两个URL,QQ网站才能生成Cookies
driver.get('https://y.qq.com/')
time.sleep(5)
driver.get(url)
time.sleep(5)
one_cookie = driver.get_cookies()
driver.quit()
# Cookies格式化
cookie_dict = {}
for i in one_cookie:
cookie_dict[i['name']] = i['value']
print(cookie_dict['pgv_pvid'])
return cookie_dict
# 源码更新后可以与书本的源码对比分析,更新后的爬虫代码只修改了部分代码
# 变动最大是歌曲下载的代码,同时注意函数之间调用的参数都比之前的源码有所变化。
if __name__=='__main__':
songmid='004Mkw5K1oI9K9'
cookie_dict = getCookies()
download(cookie_dict['pgv_pvid'],songmid,cookie_dict)
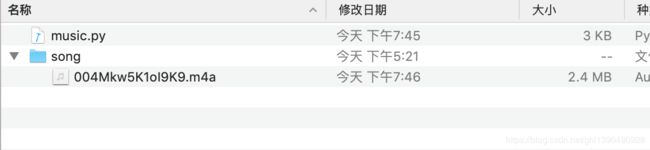
OK实现!