- Python标准库 subprocess 模块多进程编程详解
好像要长脑子了1
程序员python开发语言
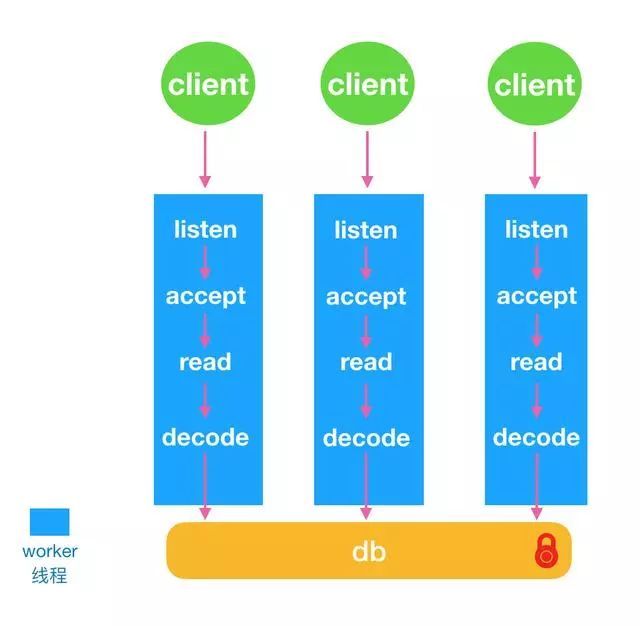
1.1基本功能subprocess模块,允许生成新的进程执行命令行指令,python程序,以及其它语言编写的应用程序,如java,c++,rust应用等。subprocess可连接多个进程的输入、输出、错误管道,并且获取它们的返回码。asyncio也支持subprocess.许多知名库都在使用此模块创建进程,以及做为跨语言粘合工具。典型如ansible,celery,selenium等。1.2与m
- 【计算机组成原理】带符号整数的表示——补码与反码
蒙奇D索大
保姆级教学计算机组成原理(CO)408改行学it笔记经验分享考研
反码与补码导读一、补码1.1原码转补码1.2补码转原码二、反码三、原码、补码、反码的相互转换结语导读大家好,很高兴又和大家见面啦!!!在上一篇内容中我们介绍了有符号整数的原码形式,有符号整数的原码表示法中,我们需要了解以下内容:机器数最高位为符号位——0为正,1为负;除最高位以外的二进制位为数值位原码形式的取值范围:−(2n−1−1)~2n−1−1-(2^{n-1}-1)~2^{n-1}-1−(2
- 我的创作纪念日
蒙奇D索大
年度总结c语言创作纪念日
我的创作纪念日前言一、人生之路的抉择1.1为什么会选计算机呢?1.2为什么开始写博客呢?二、这一年的小结2.1博客开设的专栏2.2这一年的收获2.3每天的日常2.4学习上的成就三、对接下来的学习规划前言大家好,很高兴又和大家见面啦!从2023.8.19到今天一眨眼,一年多就过去了。我从2023.10.01在C站发表了第一篇文章——猜数字,到2024.10.01刚好就满一年了。原本这篇文章应该在20
- 服务器中热备份和冷备份的区别
wanhengidc
服务器运维
服务器中最为常见的两种备份策略为热备份和冷备份,是用于在数据丢失或者是系统出现故障时恢复服务器状态和数据信息的,小编今天主要来为大家介绍一下热备份和冷备份之间的区别都有哪些!热备份通常是指在服务器正常运行的状态下进行的数据备份,在进行热备份的过程中,服务器依旧可以继续接收并处理用户的请求,其中备份程序会将数据信息实时复制到另一个存储位置或者是备份服务器中。冷备份则是指在服务器停止运行后再进行的备份
- 「Py」模块篇 之 Python中的subprocess模块详解
何曾参静谧
「Py」Python程序设计python数据库开发语言
✨博客主页何曾参静谧的博客(✅关注、点赞、⭐收藏、转发)全部专栏(专栏会有变化,以最新发布为准)「Win」Windows程序设计「IDE」集成开发环境「定制」定制开发集合「C/C++」C/C++程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「UG/NX」BlockUI集合「Py」Python程序设计「Math」探秘数学世界「PK」Paras
- GRAPHARG——学习
大哥喝阔落
学习flaskpython
20250106项目git地址:https://github.com/microsoft/graphrag.git版本:1.2.0###Thisconfigfilecontainsrequiredcoredefaultsthatmustbeset,alongwithahandfulofcommonoptionalsettings.###Forafulllistofavailablesettings
- 鸿蒙学习自由流转与分布式运行环境-价值与架构定义(1)
技术分享,共享成长
鸿蒙harmonyos学习架构
文章目录价值与架构定义1、价值2、架构定义随着个人设备数量越来越多,跨多个设备间的交互将成为常态。基于传统OS开发跨设备交互的应用程序时,需要解决设备发现、设备认证、设备连接、数据同步等技术难题,不但开发成本高,还存在安全隐私、兼容性、性能等诸多问题。为了适应万物互联时代的环境变化,鸿蒙系统构建了基于分布式运行环境所需要的基础设施,为开发者提供了基础的分布式框架能力,使开发者可以更方便的实现跨设备
- 【Python】已解决:error: subprocess-exited-with-error
屿小夏
python开发语言linux
个人简介:某不知名博主,致力于全栈领域的优质博客分享|用最优质的内容带来最舒适的阅读体验!文末获取免费IT学习资料!文末获取更多信息精彩专栏推荐订阅收藏专栏系列直达链接相关介绍书籍分享点我跳转书籍作为获取知识的重要途径,对于IT从业者来说更是不可或缺的资源。不定期更新IT图书,并在评论区抽取随机粉丝,书籍免费包邮到家AI前沿点我跳转探讨人工智能技术领域的最新发展和创新,涵盖机器学习、深度学习、自然
- 智能工厂的设计软件 应用场景的一个例子:为AI聊天工具添加一个知识系统 之6 三端架构的本质/内在/外观:自明性/信念/bank词扇
一水鉴天
软件智能智能制造人工语言人工智能
本文提要一些补充在为前端和后端锁定的两个中心词“概念”(命题“作文”的程序公共逻辑语言)和“描述”(谓词“描述”的自然描述语言)的基础上,暂时将中端的中心词锁定在“环境”(情境“意义”的人工语义网络语言)。三者的共同性--都需要通过“演算”得到(命题演算/谓词演算/情境演算)。每种演算都以本地或局部的this此岸为输入(A-box,最初是一个条件分支符--条件表达式),远处或全局的彼岸that(T
- Stable Diffusion:Python图像生成实战指南
AI绘画咪酱
stablediffusionpython人工智能AI作画AIGCai
前言今天要跟大家分享一个特别有趣的话题-如何使用Python和StableDiffusion来生成AI艺术作品。作为一名Python爱好者,我特别喜欢探索AI领域的新技术,而StableDiffusion则是最近特别火热的AI图像生成工具之一。1.StableDiffusion简介与环境配置StableDiffusion是一个强大的AI图像生成模型,它能够根据文字描述生成高质量的图像。在开始实战之
- 在Eclipse安装时报错:Version 1.8.0_281 of the JVM is not suitable for this product
CheeseZhangz
学习eclipsewindowsjavajdk
近日,在QQ群里看到鹏飞大佬的文章,突然想coding一发,又因为没用过Eclipse,于是开始撸IDE…可谁曾想,前方正有一堆坑…下载是一坑百度搜索Eclipse,打开官网下载,点击下载,官网的下载速度就是…满心欢喜,开局惊喜啊:(So记住这个小海豚,可爱吧~清华大学开源软件镜像站,致力于为国内和校内用户提供高质量的开源软件镜像、Linux镜像源服务,帮助用户更方便地获取开源软件https://
- Node.js 中的中间件:概念与应用
JJCTO袁龙
Node.jsnode.js中间件
Node.js中的中间件:概念与应用在当今的网络开发中,Node.js作为一种高效、可扩展的JavaScript运行环境,正在快速占领开发者的心智。而在Node.js的生态中,中间件(Middleware)是一个不可或缺的概念,它为构建灵活而高效的应用程序提供了强大的支持。在这篇文章中,我们将详细探讨Node.js中的中间件的概念、工作原理以及实际应用,帮助你更好地理解和使用这一强大工具。什么是中
- 系统设计面试题
慢慢慢时光
面试准备面试系统设计
比较开放,需要灵活应对,列出基本的一些思路。文章目录**设计一个短网址服务**:如何将长网址转换为短网址,并支持短网址的生成、存储、解析和重定向等功能**设计一个分布式文件系统**:考虑如何实现文件的存储、访问、备份、容错等功能,以及如何处理大规模数据和高并发访问。**设计一个聊天系统**:包括消息的发送、接收、存储、展示等功能,以及如何处理实时通信、离线消息、群聊等需求设计一个推荐系统:根据用户
- Python无法使用pip
wshngyf
pythonpip
在WIN8下使用Python2.764bit。在pyhton/scripts文件下,pip.exepip2.exe是存在的,在CMD命令行下,pip--version无法参看版本号,这是因为没有配置环境变量的原因。将pip.exe所在的目录配置到环境变量就OK了。
- Python常用的内置函数(会持续增加的)
一个小白hyc
python
Python常用内置函数如下:不是原创,但是都是自己整理的1.abs()函数返回数字的绝对值。print(abs(-45))#返回45print("abs(0.2):",abs(0.2))#返回abs(0.2):0.22.all()函数用于判断给定的参数中的所有元素是否都为TRUE,如果是返回True,否则返回False。元素除了是0、空、None、False外都算True;空元组、空列表返回值为
- 分布式架构搭建
ManchiBB
分布式架构
搭建分布式架构涉及多个方面,包括系统设计、网络架构、数据存储、服务拆分、负载均衡、容错处理等。基本步骤和考虑因素1、需求分析明确业务需求,包括系统的功能、性能、扩展性、安全性等要求。确定系统的用户规模、数据规模以及可能的增长趋势。2、系统设计微服务架构:将系统拆分为多个独立的服务,每个服务负责特定的业务功能。这有助于提高系统的可维护性和可扩展性。服务治理:使用服务注册与发现、负载均衡、熔断降级等机
- python删除类方法_026.Python面向对象类的相关操作以及对象和类的删除操作
weixin_39708502
python删除类方法
类的相关操作定义的类访问共有成员的成员和方法定义的类动态添加公有成员的属性和方法定义的类删除公有成员的属性和方法1定义一个基本的类#定义一个类classPlane():#添加一个共有成员属性capitain="John"#添加一个私有成员属性__flight_attendant=20#共有绑定方法deffly(self):print("飞机飞行速度更快")#共有普通方法,这个只能是使用类来调用de
- html手机端富文本,移动端富文本踩坑
weixin_39608657
html手机端富文本
最近在做一个vue的项目。之前的前端同事离职了,和女朋友去云南潇洒去了,剩下我一个苦逼坐在电脑前哒哒哒敲代码。刚刚接手就开始做移动端富文本编辑器的需求。主管说压了半个月,尽快做出来。在网上找了不少编辑器,前段时间做过react的后台项目,用了百度的编辑器。功能很多很强,遗憾的是ios不支持flash,在移动端并不适用。因为要兼容ios和Android,而且还要在vue的项目中使用,在网上找了很多编
- 前端js变量踩坑,部分手机浏览器不支持let、const
weixin_34244102
前端python移动开发ViewUI
2019独角兽企业重金招聘Python工程师标准>>>浏览器通过userAgent判断机型是Android还是iOS,很简单的几行代码,总有iOS用户手机判断不出来。刚开始总以为是判断的错误,优化了好几版,鉴于身边一直没有真机,终是治标不治本,今日偶遇真机,恍然大悟。。。var才是简单js的王道,引以为鉴转载于:https://my.oschina.net/AmosWang/blog/301786
- JVM学习总结——十一、JVM的JIT
技术分子
深入理解Java虚拟机jvm
JIT的全称是Justintimecompilation,中文称之为即时编译。JIT编译器作用当虚拟机发现某个方法或代码块运行特别频繁时,就会把这些代码认定为HotSpotCode热点代码,为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各层次的优化。为什么引入JIT?通常Javac将程序源码编译,转换成java字节码,JVM通过解释字节码将其翻译成相
- 探索人工智能在计算机视觉领域的创新应用与挑战
戒了9
人工智能学习方法
一、引言1.1研究背景与意义在科技飞速发展的当下,人工智能(ArtificialIntelligence,AI)已然成为引领新一轮科技革命和产业变革的重要驱动力。作为AI领域的关键分支,计算机视觉(ComputerVision,CV)致力于让计算机具备像人类一样理解和解析图像、视频等视觉信息的能力,近年来取得了令人瞩目的进展。二者的深度融合,更是为众多领域带来了前所未有的变革与机遇。从技术发展历程
- 人工智能前沿技术进展与应用前景探究
戒了9
人工智能搜索引擎百度
一、引言1.1研究背景与意义人工智能作为一门极具变革性的前沿技术,正深刻地改变着人类社会的各个层面。从其诞生之初,人工智能便承载着人类对智能机器的无限遐想与探索。自20世纪中叶起,人工智能踏上了它的发展征程,历经了多个重要阶段,每一阶段都伴随着理论的突破、技术的革新以及应用领域的拓展。在初级阶段(1943-1956),沃伦・麦卡洛克和沃尔特・皮茨提出的人工神经网络基本模型,为人工智能的发展奠定了初
- 自动控制原理二阶系统瞬态响应和稳定性实验研究报告
戒了9
自动化课程设计学习方法
一、引言1.1研究背景与目的在自动控制领域,二阶系统作为一类典型且基础的系统,广泛应用于众多实际工程场景,如航空航天中飞行器的姿态控制、工业自动化里的电机调速系统以及机器人运动控制等。对二阶系统的深入研究,在自动控制理论与实践中占据着举足轻重的地位。二阶系统的动态特性直接关乎整个控制系统的性能表现。瞬态响应能够直观反映系统在受到输入信号激励后,从初始状态过渡到稳定状态的动态过程;稳定性则是确保系统
- Ts extends 泛型约束
TA_WORLD
TypeScriptTstypescriptextends泛型约束
extends泛型约束我们一般使用extends来继承接口或者类,但是extends还可以用来泛型约束functiongetCnames(entities:T[]):string[]{returnentities.map(entity=>entity.cname)}比如,以上代码对传入的参数进行了约束,传入的参数必须要有name这个属性,否则就会出错条件类型与高阶类型extends还有一大用途就是
- 【JVM】调优
日月星宿~
#jvmjvmjava开发语言
目的:减少minorgc、fullgc的次数,也就是减少STW的时间,因为java虚拟机在做后台垃圾收集线程的时候,会停掉其他线程,专门做垃圾收集,这样会影响网站的性能,以及用户的体验。调优位置:1%的调优在方法区,99%的调优在堆内存。JVM常见调优参数-Xms初始堆大小-Xmx最大堆大小-Xss设置每个线程的堆栈大小-XX:NewSize设置新生代最小空间大小-XX:MaxNewSize设置新
- JVM学习-垃圾收集器
TyuIn
JVMjavajvmjvm.gc
一、初识垃圾收集器在学习完垃圾回收的一些基本知识之后,我们要进入到具体的垃圾收集器的学习,其他内容可以翻阅博主前面的博客文章进行了解。下面是垃圾收集器的搭配组合情况:二、基本知识的补充1、垃圾收集器中的并行与并发并行(Parallel):并行描述的是多条垃圾收集器线程之间的关系,说明同一个时间有多条这样的线程在协调工作,通常默认此时用户线程处在等待状态。并发(Concurrent):并发描述的是垃
- JVM 堆内存分配过程
富士康质检员张全蛋
运维必须知道的JVM知识jvm
设置堆内存大小和OOMJava堆用于存储Java对象实例,那么堆的大小在JVM启动的时候就确定了,我们可以通过-Xmx和-Xms来设定-Xms用来表示堆的起始内存,等价于-XX:InitialHeapSize-Xmx用来表示堆的最大内存,等价于-XX:MaxHeapSize如果堆的内存大小超过-Xmx设定的最大内存,就会抛出OutOfMemoryError异常。我们通常会将-Xmx和-Xms两个参
- JVM CMS垃圾收集器详解
NewBird_jhone
jvm
CMS定义和使用CMS(ConcurrentMarkSweep)垃圾收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。CMS垃圾收集器是一种基于“标记-清除”算法实现。在jdk8中使用CMS相关的核心参数:-XX:+UseConcMarkSweepGC:启用cms-XX:ConcGCThreads:并发的GC线程数-XX:+UseCMSCompactAtFul
- 真实互联网线上系统JVM内存溢出排查流程(文末彩蛋)
程序健跑人生
JVM多线程高并发工作感悟jvmjava架构后端分布式
起因:近期在工作中发生因jvm内存溢出导致线上应用进程崩溃,导致服务瞬间瘫痪。期间发现集群中每台应用服务器JVM内存使用率高达96%左右,存在瞬间内存打满,导致服务瘫痪情况。根据经验分析,大概率是由于JVM中存在长期无法回收的(大)对象(此问题属代码本身问题)或瞬间流量激增导致垃圾收集器来不及回收(可调整JVM参数或横向增加服务器)导致。排查过程:1.通过命令(jmap-dump:format=b
- IDEA JVM 性能优化 相关参数设置
简简单单OnlineZuozuo
m3IntelliJIDEA实用指南intellij-idea性能优化java
文章目录IDEAJVM性能优化相关参数设置IDEAJVM性能优化相关参数设置点击Help-EditCustomVMOptions-Xms256m-Xmx2048m-XX:ReservedCodeCacheSize=480m-XX:+UseConcMarkSweepGC-XX:
- ztree异步加载
3213213333332132
JavaScriptAjaxjsonWebztree
相信新手用ztree的时候,对异步加载会有些困惑,我开始的时候也是看了API花了些时间才搞定了异步加载,在这里分享给大家。
我后台代码生成的是json格式的数据,数据大家按各自的需求生成,这里只给出前端的代码。
设置setting,这里只关注async属性的配置
var setting = {
//异步加载配置
- thirft rpc 具体调用流程
BlueSkator
中间件rpcthrift
Thrift调用过程中,Thrift客户端和服务器之间主要用到传输层类、协议层类和处理类三个主要的核心类,这三个类的相互协作共同完成rpc的整个调用过程。在调用过程中将按照以下顺序进行协同工作:
(1) 将客户端程序调用的函数名和参数传递给协议层(TProtocol),协议
- 异或运算推导, 交换数据
dcj3sjt126com
PHP异或^
/*
* 5 0101
* 9 1010
*
* 5 ^ 5
* 0101
* 0101
* -----
* 0000
* 得出第一个规律: 相同的数进行异或, 结果是0
*
* 9 ^ 5 ^ 6
* 1010
* 0101
* ----
* 1111
*
* 1111
* 0110
* ----
* 1001
- 事件源对象
周华华
JavaScript
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml&q
- MySql配置及相关命令
g21121
mysql
MySQL安装完毕后我们需要对它进行一些设置及性能优化,主要包括字符集设置,启动设置,连接优化,表优化,分区优化等等。
一 修改MySQL密码及用户
- [简单]poi删除excel 2007超链接
53873039oycg
Excel
采用解析sheet.xml方式删除超链接,缺点是要打开文件2次,代码如下:
public void removeExcel2007AllHyperLink(String filePath) throws Exception {
OPCPackage ocPkg = OPCPac
- Struts2添加 open flash chart
云端月影
准备以下开源项目:
1. Struts 2.1.6
2. Open Flash Chart 2 Version 2 Lug Wyrm Charmer (28th, July 2009)
3. jofc2,这东西不知道是没做好还是什么意思,好像和ofc2不怎么匹配,最好下源码,有什么问题直接改。
4. log4j
用eclipse新建动态网站,取名OFC2Demo,将Struts2 l
- spring包详解
aijuans
spring
下载的spring包中文件及各种包众多,在项目中往往只有部分是我们必须的,如果不清楚什么时候需要什么包的话,看看下面就知道了。 aspectj目录下是在Spring框架下使用aspectj的源代码和测试程序文件。Aspectj是java最早的提供AOP的应用框架。 dist 目录下是Spring 的发布包,关于发布包下面会详细进行说明。 docs&nb
- 网站推广之seo概念
antonyup_2006
算法Web应用服务器搜索引擎Google
持续开发一年多的b2c网站终于在08年10月23日上线了。作为开发人员的我在修改bug的同时,准备了解下网站的推广分析策略。
所谓网站推广,目的在于让尽可能多的潜在用户了解并访问网站,通过网站获得有关产品和服务等信息,为最终形成购买决策提供支持。
网站推广策略有很多,seo,email,adv
- 单例模式,sql注入,序列
百合不是茶
单例模式序列sql注入预编译
序列在前面写过有关的博客,也有过总结,但是今天在做一个JDBC操作数据库的相关内容时 需要使用序列创建一个自增长的字段 居然不会了,所以将序列写在本篇的前面
1,序列是一个保存数据连续的增长的一种方式;
序列的创建;
CREATE SEQUENCE seq_pro
2 INCREMENT BY 1 -- 每次加几个
3
- Mockito单元测试实例
bijian1013
单元测试mockito
Mockito单元测试实例:
public class SettingServiceTest {
private List<PersonDTO> personList = new ArrayList<PersonDTO>();
@InjectMocks
private SettingPojoService settin
- 精通Oracle10编程SQL(9)使用游标
bijian1013
oracle数据库plsql
/*
*使用游标
*/
--显示游标
--在显式游标中使用FETCH...INTO语句
DECLARE
CURSOR emp_cursor is
select ename,sal from emp where deptno=1;
v_ename emp.ename%TYPE;
v_sal emp.sal%TYPE;
begin
ope
- 【Java语言】动态代理
bit1129
java语言
JDK接口动态代理
JDK自带的动态代理通过动态的根据接口生成字节码(实现接口的一个具体类)的方式,为接口的实现类提供代理。被代理的对象和代理对象通过InvocationHandler建立关联
package com.tom;
import com.tom.model.User;
import com.tom.service.IUserService;
- Java通信之URL通信基础
白糖_
javajdkwebservice网络协议ITeye
java对网络通信以及提供了比较全面的jdk支持,java.net包能让程序员直接在程序中实现网络通信。
在技术日新月异的现在,我们能通过很多方式实现数据通信,比如webservice、url通信、socket通信等等,今天简单介绍下URL通信。
学习准备:建议首先学习java的IO基础知识
URL是统一资源定位器的简写,URL可以访问Internet和www,可以通过url
- 博弈Java讲义 - Java线程同步 (1)
boyitech
java多线程同步锁
在并发编程中经常会碰到多个执行线程共享资源的问题。例如多个线程同时读写文件,共用数据库连接,全局的计数器等。如果不处理好多线程之间的同步问题很容易引起状态不一致或者其他的错误。
同步不仅可以阻止一个线程看到对象处于不一致的状态,它还可以保证进入同步方法或者块的每个线程,都看到由同一锁保护的之前所有的修改结果。处理同步的关键就是要正确的识别临界条件(cri
- java-给定字符串,删除开始和结尾处的空格,并将中间的多个连续的空格合并成一个。
bylijinnan
java
public class DeleteExtraSpace {
/**
* 题目:给定字符串,删除开始和结尾处的空格,并将中间的多个连续的空格合并成一个。
* 方法1.用已有的String类的trim和replaceAll方法
* 方法2.全部用正则表达式,这个我不熟
* 方法3.“重新发明轮子”,从头遍历一次
*/
public static v
- An error has occurred.See the log file错误解决!
Kai_Ge
MyEclipse
今天早上打开MyEclipse时,自动关闭!弹出An error has occurred.See the log file错误提示!
很郁闷昨天启动和关闭还好着!!!打开几次依然报此错误,确定不是眼花了!
打开日志文件!找到当日错误文件内容:
--------------------------------------------------------------------------
- [矿业与工业]修建一个空间矿床开采站要多少钱?
comsci
地球上的钛金属矿藏已经接近枯竭...........
我们在冥王星的一颗卫星上面发现一些具有开采价值的矿床.....
那么,现在要编制一个预算,提交给财政部门..
- 解析Google Map Routes
dai_lm
google api
为了获得从A点到B点的路劲,经常会使用Google提供的API,例如
[url]
http://maps.googleapis.com/maps/api/directions/json?origin=40.7144,-74.0060&destination=47.6063,-122.3204&sensor=false
[/url]
从返回的结果上,大致可以了解应该怎么走,但
- SQL还有多少“理所应当”?
datamachine
sql
转贴存档,原帖地址:http://blog.chinaunix.net/uid-29242841-id-3968998.html、http://blog.chinaunix.net/uid-29242841-id-3971046.html!
------------------------------------华丽的分割线--------------------------------
- Yii使用Ajax验证时,如何设置某些字段不需要验证
dcj3sjt126com
Ajaxyii
经常像你注册页面,你可能非常希望只需要Ajax去验证用户名和Email,而不需要使用Ajax再去验证密码,默认如果你使用Yii 内置的ajax验证Form,例如:
$form=$this->beginWidget('CActiveForm', array( 'id'=>'usuario-form',&
- 使用git同步网站代码
dcj3sjt126com
crontabgit
转自:http://ued.ctrip.com/blog/?p=3646?tn=gongxinjun.com
管理一网站,最开始使用的虚拟空间,采用提供商支持的ftp上传网站文件,后换用vps,vps可以自己搭建ftp的,但是懒得搞,直接使用scp传输文件到服务器,现在需要更新文件到服务器,使用scp真的很烦。发现本人就职的公司,采用的git+rsync的方式来管理、同步代码,遂
- sql基本操作
蕃薯耀
sqlsql基本操作sql常用操作
sql基本操作
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年6月1日 17:30:33 星期一
&
- Spring4+Hibernate4+Atomikos3.3多数据源事务管理
hanqunfeng
Hibernate4
Spring3+后不再对JTOM提供支持,所以可以改用Atomikos管理多数据源事务。Spring2.5+Hibernate3+JTOM参考:http://hanqunfeng.iteye.com/blog/1554251Atomikos官网网站:http://www.atomikos.com/ 一.pom.xml
<dependency>
<
- jquery中两个值得注意的方法one()和trigger()方法
jackyrong
trigger
在jquery中,有两个值得注意但容易忽视的方法,分别是one()方法和trigger()方法,这是从国内作者<<jquery权威指南》一书中看到不错的介绍
1) one方法
one方法的功能是让所选定的元素绑定一个仅触发一次的处理函数,格式为
one(type,${data},fn)
&nb
- 拿工资不仅仅是让你写代码的
lampcy
工作面试咨询
这是我对团队每个新进员工说的第一件事情。这句话的意思是,我并不关心你是如何快速完成任务的,哪怕代码很差,只要它像救生艇通气门一样管用就行。这句话也是我最喜欢的座右铭之一。
这个说法其实很合理:我们的工作是思考客户提出的问题,然后制定解决方案。思考第一,代码第二,公司请我们的最终目的不是写代码,而是想出解决方案。
话粗理不粗。
付你薪水不是让你来思考的,也不是让你来写代码的,你的目的是交付产品
- 架构师之对象操作----------对象的效率复制和判断是否全为空
nannan408
架构师
1.前言。
如题。
2.代码。
(1)对象的复制,比spring的beanCopier在大并发下效率要高,利用net.sf.cglib.beans.BeanCopier
Src src=new Src();
BeanCopier beanCopier = BeanCopier.create(Src.class, Des.class, false);
- ajax 被缓存的解决方案
Rainbow702
JavaScriptjqueryAjaxcache缓存
使用jquery的ajax来发送请求进行局部刷新画面,各位可能都做过。
今天碰到一个奇怪的现象,就是,同一个ajax请求,在chrome中,不论发送多少次,都可以发送至服务器端,而不会被缓存。但是,换成在IE下的时候,发现,同一个ajax请求,会发生被缓存的情况,只有第一次才会被发送至服务器端,之后的不会再被发送。郁闷。
解决方法如下:
① 直接使用 JQuery提供的 “cache”参数,
- 修改date.toLocaleString()的警告
tntxia
String
我们在写程序的时候,经常要查看时间,所以我们经常会用到date.toLocaleString(),但是date.toLocaleString()是一个过时 的API,代替的方法如下:
package com.tntxia.htmlmaker.util;
import java.text.SimpleDateFormat;
import java.util.
- 项目完成后的小总结
xiaomiya
js总结项目
项目完成了,突然想做个总结但是有点无从下手了。
做之前对于客户端给的接口很模式。然而定义好了格式要求就如此的愉快了。
先说说项目主要实现的功能吧
1,按键精灵
2,获取行情数据
3,各种input输入条件判断
4,发送数据(有json格式和string格式)
5,获取预警条件列表和预警结果列表,
6,排序,
7,预警结果分页获取
8,导出文件(excel,text等)
9,修