JVM学习总结——十一、JVM的JIT
JIT的全称是Just in time compilation,中文称之为即时编译。
JIT编译器作用
当虚拟机发现某个方法或代码块运行特别频繁时,就会把这些代码认定为 Hot Spot Code 热点代码,为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,
并进行各层次的优化。
为什么引入JIT?
通常Javac将程序源码编译,转换成java字节码,JVM通过解释字节码将其翻译成相应的机器指令,逐条读入,逐条解释翻译。
经过解释运行,其运行速度必定会比可运行的二进制字节码程序慢。为了提高运行速度,引入了JIT技术。
JVM读入.class文件解释后将其发给JIT编译器,JIT编译器将字节码编译成本机机器代码。机器码保存起来,已备下次使用,因此从理论上来说,采用该JIT技术能够,能够接近曾经纯编译技术。
怎么判断是否是热点代码?
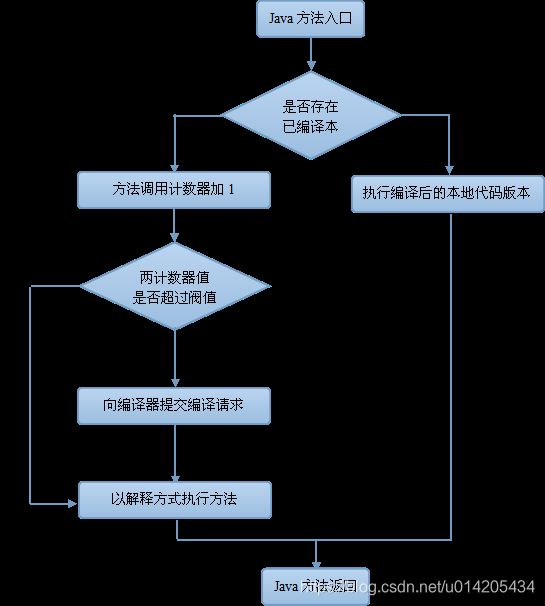
HotSpot虚拟机基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器和回边计数器。
方法调用计数器
方法调用计数器用来统计方法调用的次数,在默认设置下,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间内方法被调用的次数。
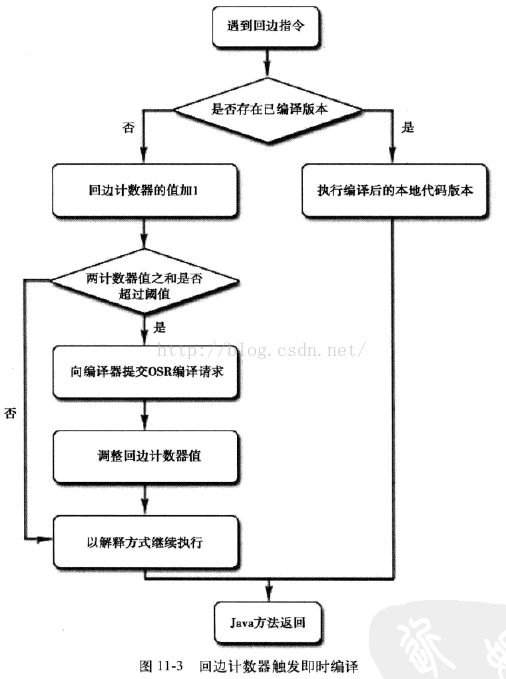
回边计数器
用于统计一个方法中循环体代码执行的次数(准确地说,应该是回边的次数,因为并非所有的循环都是回边),在字节码中遇到控制流向后跳转的指令就称为“回边”。
方法调用计数器流程图
回边计数器流程图
什么场景使用?
方法内联
方法内联就是把被调用方函数代码"复制"到调用方函数中,来减少因函数调用开销的技术。
例子
private int add4(int x1, int x2, int x3, int x4) {
return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}
JVM优化后
private int add4(int x1, int x2, int x3, int x4) {
return x1 + x2 + x3 + x4;
}
一个方法内联流程:
首先会有个栈,存储目前所有活跃的方法,以及它们的本地变量和参数
当一个新的方法被调用了,一个新的栈帧会被加到栈顶,分配的本地变量和参数会存储在这个栈帧
跳到目标方法代码执行
方法返回的时候,本地方法和参数会被销毁,栈顶被移除
返回原来地址执行
函数调用频繁这个时间和空间开销会相对变得很大,降低了程序的性能。
如何判断JVM是否进行了优化?
-XX:+PrintCompilation
当JIT编译发生时打印出来
-XX:+UnlockDiagnosticVMOptions
-XX:+PrintInlining
打印内联的方法
热点方法的内联优化建议
更小的方法体
尽量使用final、private、static修饰符
优化参数
JVM会自动的识别热点方法,并对它们使用方法内联优化。那么一段代码需要执行多少次才会触发JIT优化呢?通常这个值由-XX:CompileThreshold参数进行设置:
1、使用client编译器时,默认为1500;
2、使用server编译器时,默认为10000;
但是一个方法就算被JVM标注成为热点方法,JVM仍然不一定会对它做方法内联优化。其中有个比较常见的原因分为两种情况。
1.方法是经常执行的,默认情况下,方法大小小于325字节的都会进行内联(可以通过** -XX:MaxFreqInlineSize=N**来设置这个大小)
2.方法不是经常执行的,默认情况下,方法大小小于35字节才会进行内联(可以通过** -XX:MaxInlineSize=N **来设置这个大小)
通过增加这个大小,以便更多的方法可以进行内联;除非显著提升性能,否则不推荐修改这个参数。
-XX:CompileThreshold如果不做处置,方法调用计数器是一个相对执行频率,超过一定时间限制未能达到提交JIT,这个方法调用计数器就会减少一半,被称为方法调用计数器热度衰减。这个时间限制被称为半衰减周期。
-XX:-UseCounterDecay 来关闭热度衰减。
-XX:CounterHalfLifeTime 参数设置半衰减周期 单位秒。
上述是标准编译,还有一个叫做OSR(On Stack Replacement)栈上替换的编译,
如main方法,只执行一次,远远达不到阈值,但是方法体中执行了多次循环,
OSR编译就是只编译该循环代码,然后将其替换,下次循环时就执行编译好的代码,不过触发OSR编译也需要一个阈值,可以通过以下公式得到。
-XX:CompileThreshold = 10000
调用计数器,即方法被调用的次数
-XX:OnStackReplacePercentage = 140
回边计数器,即方法中循环执行部分代码的执行次数,OnStackReplacePercentage
-XX:InterpreterProfilePercentage = 33
InterpreterProfilePercentage,默认为33。
OSR trigger = (CompileThreshold * (OnStackReplacePercentage - InterpreterProfilePercentage)) / 100 = 10700
其中trigger即为OSR编译的阈值。
1.getter方法优化,-XX:UseFastAccessorMethods
方法1:
private void getA(){
getB()
}
方法2:
private void getB(){
system.out.print("getB");
}
如果配置了getter方法的优化参数,JVM在编译的时候会编译成如下形式
private void getA(){
system.out.print("getB");
}
2.关闭偏向锁优化
偏向锁的概念:一把锁被使用之后不主动释放,保留给当前的使用者,预判等下一个进程来获取的时候再释放出来,
-XX:-UseBiasedLocking
3.指针压缩
-XX:+UseCompressedOops
new一个空对象在32为系统中占用内存大小是8byte(对象头,在堆中)+4byte(对象的引用地址,在栈中)=12byte;
new一个空对象在64为系统中占用内存大小是16byte(对象头,在堆中)+8byte(对象的引用地址,在栈中)=24byte;
可想而知同一个对象在64位系统中占的内存加大一半了,不仅消耗运行内存,而且GC回收时挺耗cpu的。
jvm的属性-XX:+UseCompressedOops在JDK 1.6和之后的版本都默认开启了,所以jvm开启了压缩之后64为系统的对象也只占用12byte。
基本功 | Java即时编译器原理解析及实践 - 美团技术团队