数据与广告系列十七:广告的排序与CTR预估(附Github示例代码)
作者·黄崇远
『数据虫巢』
全文共8030字
题图ssyer.com

“ 万年长青的CTR预估。”
本文将涉及广告的排序相关业务,以及CTR预估的模型发展,最后将给出XGB+LR的经典组合解决方案。
本文的示例项目,基于Kaggle上的开源CTR预估数据集,见Github地址(记得给start哈):
https://github.com/blogchong/data_and_advertisement


01
前言
在系列第16篇《数据与广告系列十六:广告与游戏》中,我们中断了机器学习广告应用场景的话题,今天我们继续第十五篇的节奏。
在之前我们了解了广告基础属性(性别)的预测,并通过他了解了用机器学习思路解决业务问题的基本流程;随后我们又通过广告中异常检测的话题,学习了CostSensitiveClassification以及Smote过采样等机器学习的知识;紧接着我们对基于标签组合的智能定向话题进行了了解,并结合场景了解和学习了FM算法;接着对于商业兴趣标签的建模构建进行了了解,顺带把XGboost这个神器给学习了。
今天,我们来了解广告领域中算法应用历史最悠久的CTR预估场景,一个广告系统可以没有商业兴趣标签,可以没有智能定向,甚至可以没有基础属性,但只要在效果广告领域范畴内,就少不了CTR的预估。
并且,CTR预估不止在广告领域,在推荐系统场景同样是核心的存在,大致逻辑上是很相似的,只不过场景业务上不一样,有时候优化的目标也有所差异。
02
CTR预估的作用
我们先来看下整个广告系统的大致架构图。
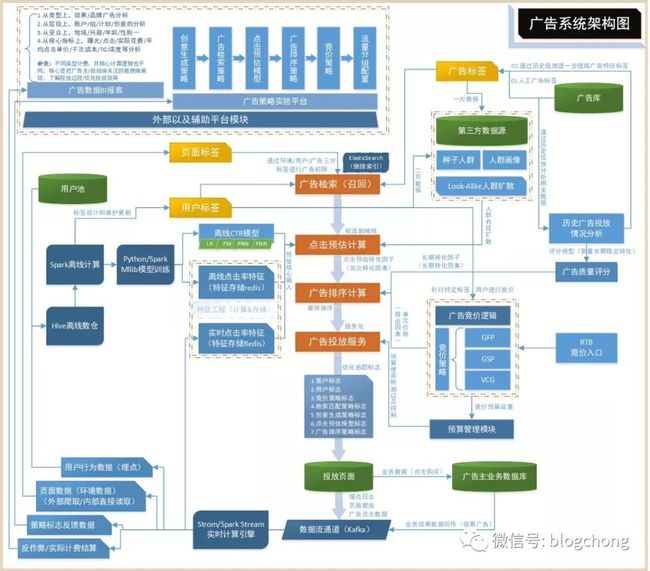
这张图在《数据与广告系列七:广告与推荐系统技术架构》出现过,不知道大家还是否记得,当时我们是按整体逻辑结构进行讲解的,这里我们不关心整体的逻辑架构,只关心CTR核心在哪个环节起作用。
如图所示,显然CTR预估阶段发生在召回之后,投放之前,很多广告系统会把预估跟排序看成一个阶段,其实无所谓,从底层逻辑的角度看,CTR预估模型是核心影响排序的因素,特别是一些相对初级的广告系统,其实最终核心影响排序的因素就是ctr+cpc出价,其他的诸如广告主质量评分,环境上下文评分都不怎么考虑。
当然,一些硬性策略性的控制还是会做的。比如基础的曝光频度控制,主题广告的适当加权,黑白名单的控制等等。
回到广告排序的问题,从一个User进来之后,需要根据一些过滤性策略,包括频控,黑白名单等条件,在剩余的广告池中,再根据广告的定向条件,进行召回匹配,拿到若干个待排序候选广告,形成一个广告列表。
然后广告列表走排序逻辑,最终根据排序的顺序,取第一个score最高的广告给当前user进行曝光。
在这里,我们假设只做最简单的排序计算考虑,其实就是CTR*CPC,而如果再乘以1000转换过来就是eCPM,即千次展示期望收益。
从这里我们可以看到,其实一个排序逻辑就是最终我们系统所期望的优化目标,即如果是CTR*CPC的计算方式,假设CTR预估又十分准确的情况下,这种机制其实是往平台收益目标去优化的。
道理逻辑很简单,假设抛出了其他因素情况下(定向符合,频控符合),哪个广告能给我带来更高的收益,我就把这次曝光机会给谁(广告)。
CPC每个广告给出来的都是明确的,价高价低一目了然,剩下来就是CTR预估的事了,预估的准确意味着你的平台收益更加的稳定,以及达到理论收益最大值。
所以,让CTR预估的更准就变成了广告系统最最最重要的事,毕竟都是真金白银呐。
但是,有个问题不知道大家有没有考虑过,我们一切以CTR*CPC为核心逻辑作为排序基准,来确定流量曝光给哪个广告,但对于广告主来说并不一定都是好事。
以前面几个我们认真了解过的业务领域比如《数据与广告系列八:广告与二类电商》《数据与广告系列九:本地化广告》《数据与广告系列十六:广告与游戏》来说,本地化广告看的表单填写,所以直接转化是有效表单,本质转化是最终到店的流量;对于二类电商来说,直接转化是有效填单,最终转化是卖了多少商品多少钱;对于游戏来说,直接转化是下载注册,最终转化是付费。
所以,不管怎么看Click都只是第一层的转化,对于平台来说,只要Click了,就收钱,收钱平台收益就高了,没毛病。但是对于广告主来说,Click了也屁用没有,实际上可怕的是部分领域里后端转化与前端转化(CTR)是成反比的,前端转化越高,后端转化越差,我的娘啊。
而对于广告系统来说,平衡多方利益(平台方收益,广告主转化,用户体验,详情参考《数据与广告系列五:广告生态的平衡与人群定向初探》)才能“长治久安”,所以当广告系统发展到了一定阶段,光看着ctr这块肉已经满足不了社会的和谐发展了。
这也就有oCPX动态优化广告的出现,这就是另外一个话题了,但核心打破的确实是传统的排序逻辑,并且可以预见的是,光一个ctr已经够麻烦了,再加入其他衡量因素,预测起来的难度就更大了。
今天,我们不叉题,继续回到CTR预估的话题,到后面总是会遇到oCPX相关场景的。
03
CTR预估模型的发展
早期说到广告系统是最早将数据和机器学习进行规模化价值挖掘的,就是因为CTR预估很早就将机器学习的一些模型应用于实际的问题解决中了。
所以,其实他由于历史足够久远,久远到广告系统发展了多少年,CTR预估模型就发展了多少年。
早在2010年以前,机器学习发展有限,由于研究的深度以及硬件的发展原因,深度学习相关的领域尚未展露出应有的价值,所以还是传统机器学习的天下。而由于CTR的场景,包括广告和推荐系统,都有一个相对共同的特征,那就是特征高度稀疏,然后由于线上服务,系统对于模型的预测性能要求较高,且工业化场景对于性能要求需要稳定。
能满足这三个条件的传统机器学习算法并不多,线性的LR,由于模型足够简单,可解释性强,且对于高维稀疏特征同样可以应对,性能良好。所以就变成了LR通万法,广告CTR用他,推荐系统排序点击预估用他,人群的Lookalike也用他。
老好用了。
但是LR对于特征的挖掘要求很高,需要我们很好的理解特征,能找到好的特征,且对特征处理的好,模型的表现就相对较好,这严重限制了发展。
2010年,随着FM算法论文的产生,以及紧随其后的FM家族(FFM,FNN等),解决了特征之间特征组合的问题,并且通过数学解法(因子分解)来寻求特征与目标之间的隐藏关系,打破了之前LR模型中严谨的特征工程的难题。
然后一些集成学习的路子,解决了单模型带来的稳定性以及过拟合欠拟合的问题,一些诸如随机森林,GBDT等集成类的模型解决方案应用于CTR预估的场景中。
2016年,谷歌一篇论文指出,可以通过GBDT(Gradient Boost Desision Tree)来解决LR模型特征组合的问题,即使用GBDT或者类似的集成树模型训练,然后拟合好了之后,取每棵树的叶子节点作为新的特征,加入到原始特征之中,再灌入到LR模型中,效果会比纯粹的LR好(谷歌说的,不是我说的)。
这种思路其实跟上上一篇《数据与广告系列十四:智能定向&基于FM的标签组合推荐思路》是一样的,或者说那个思路是借鉴于类似的思想,先用模型拟合好,然后再利用模型的中间结果作为后续阶段的输入。
总之,这种基于模型联级的方案据说很好使,哪怕是当前深度学习大行其道的今天,依然还有很多广告系统把他当成一个稳定的baseline在使用。
然后到了2016年左右(刚好也是深度学习强势的时期),出现了好几个针对性的算法(又是谷歌,谷歌果然是广告界的带头大哥,带节奏带的很溜),包括Wide&Deep Learning,FNN。
他们都有一个特点就是,传统模型与深度模型的联姻,强强结合。比如WDL利用传统的wide模型(比如LR)来学习目标与特征之间强关系,再利用Deep Learning部分(例如MLP)来加强拟合的泛化能力。
而FNN,则跟FM有直接的关系,利用FM模型将特征进行Embedding表示,然后用这个特征来替代原始特征,二阶段使用MLP(多层感知机)来做最终的拟合模型,借用的是GBDT+LR的思路。
总之,整个CTR模型的发展史就是机器学习与深度学习的发展史,毕竟广告业务是目前世界上互联网最大的变现手段之一(广告/游戏/电商),所以,有钱的地方就有动力,太有道理了。
04
CTR预估:XGBoost+LR实操
PS:微信上看嵌入的代码不是很好看,建议这里只看逻辑脉络,具体的代码上Github上看。
整体而言,有能力上深度学习模型的,多少都会试一下深度学习的一些模型,深度学习的模型理论上具有更强的泛化能力,但同样门技术槛以及调优的难度都更大,实操起来并不一定会比传统模型好。
传统模型发展了足够多的年份,大家摸底摸得也比较透彻了,所以作为基准来说更加的稳定,更具有可控性,所以“残留”的传统模型也依然在生效中,并没有绝迹于江湖(广告/推荐场景)。
今天这篇,我们的实操部分,依然不会把手伸到深度学习领域,我们来学习集成的树模型与LR的模型联级解决方案,而集成模型这块,我们并没有使用传统的GDBT,而是使用我们之前也接触过的XGBoost,不同的配方,同样的效果(可以用GBDT,也可以用LightBGM,或者XGBoost)。
对于数据集,我们使用Kaggle上知名的CTR预估数据集:
https://www.kaggle.com/c/avazu-ctr-prediction。
但是这份数据集太大了,大到了我们自己的小机器无法跑起来,所以我就取了另外一份数据:
https://www.kaggle.com/sulabh4/ctr-prediction-dataset。
据观察,这份数据是从avazu数据集上截取下来的子集,只有二三十兆(999999条记录),或者直接上avazu上随机抽样一部分下来演练也是一样的。
kaggle上的字段说明:
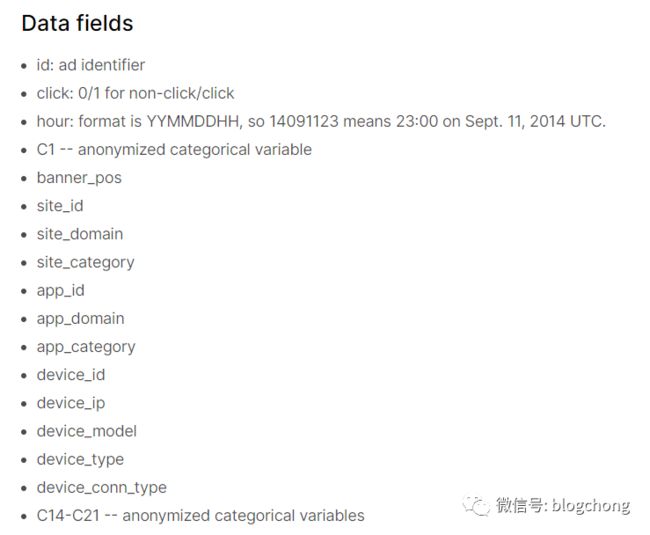
大部分字段通过命名就大概知道什么意思了,然后C系列的字段是数据公开方隐藏含义的类别字段,估计涉及到隐私问题,反正我们就当成正常的一个可用特征即可。
我们直接按click进行样本区分,分为正负样本,数据如下:
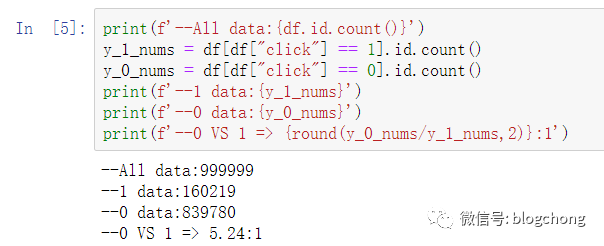
如果我们要做的严谨点,我们接下来做对应一些特征的转换,一些非int类型的转换为类别编码,或者更深入点做特征的分析。
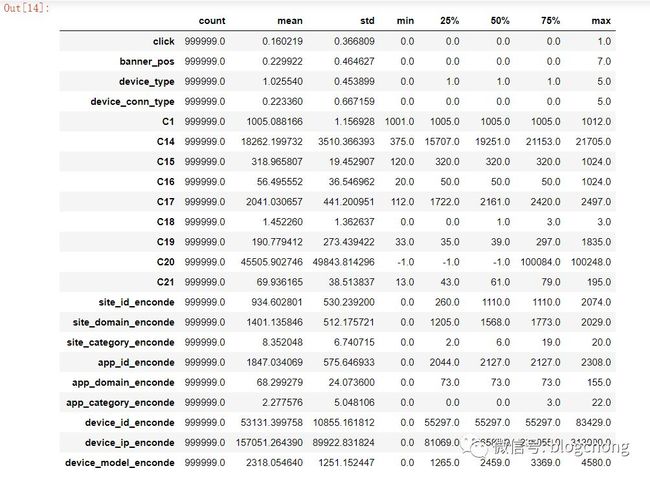
整体数据情况如下(注意数据类型):

将非数值类型的字段进行编码转换:
##接下来对特征进行处理,先将类别特征进行编码
#针对类型类的特征,先进行编码,编码之前构建字典
from sklearn import preprocessing
def label_encode(field,df):
dic = []
df_field = df[field]
list_field = df_field.tolist()
#构建field字典
for i in list_field:
if i not in dic:
dic.append(i)
label_field = preprocessing.LabelEncoder()
label_field.fit(dic)
df_field_enconde_tmp = label_field.transform(df_field)
df_field_enconde = pd.DataFrame(df_field_enconde_tmp, index=df.index, columns=[(field+'_enconde')])
return df_field_enconde
df_site_id_enconde = label_encode('site_id',df)
df_site_domain_enconde = label_encode('site_domain',df)
df_site_category_enconde = label_encode('site_category',df)
df_app_id_enconde = label_encode('app_id',df)
df_app_domain_enconde = label_encode('app_domain',df)
df_app_category_enconde = label_encode('app_category',df)
df_device_id_enconde = label_encode('device_id',df)
df_device_ip_enconde = label_encode('device_ip',df)
df_device_model_enconde = label_encode('device_model',df)
然后特征进行拼接,并作为中间结果保存下来:
pd_input = pd.concat([df[['click','banner_pos','device_type','device_conn_type'
,'C1','C14','C15','C16','C17','C18','C19','C20','C21']]
,df_site_id_enconde
,df_site_domain_enconde
,df_site_category_enconde
,df_app_id_enconde
,df_app_domain_enconde
,df_app_category_enconde
,df_device_id_enconde
,df_device_ip_enconde
,df_device_model_enconde], axis=1)
##处理过的数据保存下来
pd_input.to_csv('./out_put/encode_data.csv', header=True, index=True)
此时,我们第一阶段的特征简单处理结束了, 01_encode_data.ipynb文件的最终结果是拿到简单encode的数据。
接下来第二阶段进行数据集的划分,数据划分逻辑如下:
#对编码之后的数据进行分片
begin_time = time.time()
print(f'Begin Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(begin_time))}')
#将数据分为train/validata/testdata三部分
df_1 = df[df['click'] == 1]
df_0 = df[df['click'] == 0]
df_1_test =df_1.sample(frac=0.3, random_state=100)
df_0_test =df_0.sample(frac=0.3, random_state=100)
df_1_other = df_1[~df_1.index.isin(df_1_test.index)]
df_0_other = df_0[~df_0.index.isin(df_0_test.index)]
df_1_vali = df_1_other.sample(frac=0.2, random_state=100)
df_0_vali = df_0_other.sample(frac=0.2, random_state=100)
df_1_train = df_1_other[~df_1_other.index.isin(df_1_vali.index)]
df_0_train = df_0_other[~df_0_other.index.isin(df_0_vali.index)]
#合并1/0
df_train = pd.concat([df_1_train,df_0_train], ignore_index=True)
df_vali = pd.concat([df_1_vali,df_0_vali], ignore_index=True)
df_test = pd.concat([df_1_test,df_0_test], ignore_index=True)
print(f'--split data : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))}')
nums_train = df_train['click'].count()
nums_vali = df_vali['click'].count()
nums_test = df_test['click'].count()
print(f'--split rate train VS vali VS test: {nums_train}:{nums_vali}:{nums_test}')
df_train.to_csv('./out_put/encode_data_train.csv')
df_vali.to_csv('./out_put/encode_data_vali.csv')
df_test.to_csv('./out_put/encode_data_test.csv')
end_time = time.time()
print(f'End Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(end_time))}')
数据划分比例:
--split rate train VS vali VS test: 559999:140000:300000
第三阶段,进行xgboost的训练,并保存叶子节点的onehot特征,如下为进行xgboost的拟合:
##进行xgboost拟合
begin_time = time.time()
print(f'Begin Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(begin_time))}')
##受限于机器的资源,这里就不做gridsearch调参了,直接凑合着来(按最小资源消耗来设置参数)
model = XGBClassifier(learning_rate=0.1
,n_estimators=10
,max_depth=3
,scale_pos_weight=1
,min_child_weight=1
,gamma=0
,subsample=1
,colsample_bylevel=1
,objective='binary:logistic'
,n_jobs=4
,seed=100)
eval_set = [(x_vali, y_vali)]
model.fit(x_train, y_train, eval_metric="auc" , eval_set=eval_set, early_stopping_rounds=10)
end_time = time.time()
print(f'End Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(end_time))}')
这里受限于我那小小的阿里云主机,所以只能按树最少,层级最小的方式去跑了,不然跑不动,穷。
结果打印:
Begin Time : 2020-02-01 19:19:05
[0] validation_0-auc:0.663951
Will train until validation_0-auc hasn't improved in 10 rounds.
[1] validation_0-auc:0.669895
[2] validation_0-auc:0.670909
[3] validation_0-auc:0.671622
[4] validation_0-auc:0.673234
[5] validation_0-auc:0.675165
[6] validation_0-auc:0.675224
[7] validation_0-auc:0.682689
[8] validation_0-auc:0.684437
[9] validation_0-auc:0.687103
End Time : 2020-02-01 19:19:11
并不能算一个非常好的效果,这个结果是非常丢脸的,随便加大树的数量和调大树层级,auc轻松上0.75,为了能让后面的onehot叶子组合特征跑起来可谓是费尽心机啊,这里不管了,假设这个model就已经是最优xgboost的拟合模型了。
对叶子组合特征进行编码,并且分别保留onehot编码特征和与原始特征拼接之后的df:
#我们来拿到xgb的叶子节点的特征
##进行xgboost拟合
begin_time = time.time()
print(f'Begin Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(begin_time))}')
##apply函数返回的是叶子索引
x_train_leaves = model.apply(x_train).astype(np.int32)
x_test_leaves = model.apply(x_test).astype(np.int32)
#使用nunpy的concatenate来拼接数组,并生成全局的onehot,单一使用train的可能会漏掉编码,test验证的时候出问题
x_leaves = np.concatenate((x_train_leaves,x_test_leaves), axis=0)
print(f'Transform xgb leaves shape: {x_leaves.shape}')
xgb_onehotcoder = OneHotEncoder()
xgb_onehotcoder.fit(x_leaves)
x_train_lr = xgb_onehotcoder.transform(x_train_leaves).toarray()
x_test_lr = xgb_onehotcoder.transform(x_test_leaves).toarray()
print(f'Transform xgb x_train_lr shape: {x_train_lr.shape}')
print(f'Transform xgb x_test_lr shape: {x_test_lr.shape}')
##进行one特征与原始特征的拼接
x_train_lr2 = np.hstack((x_train_lr, x_train.values))
x_test_lr2 = np.hstack((x_test_lr, x_test.values))
print(f'Transform xgb x_train_lr2 shape: {x_train_lr2.shape}')
print(f'Transform xgb x_test_lr2 shape: {x_test_lr2.shape}')
end_time = time.time()
print(f'End Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(end_time))}')
我们可以看到特征情况如下:
Transform xgb leaves shape: (859999, 10)
Transform xgb x_train_lr shape: (559999, 80)
Transform xgb x_test_lr shape: (300000, 80)
Transform xgb x_train_lr2 shape: (559999, 101)
Transform xgb x_test_lr2 shape: (300000, 101)
这意味着,我们通过xgb的组合特征,额外增加了80个特征,我们继续分别将这些特征灌入到LR中进行train:
###灌入到LR中
begin_time = time.time()
print(f'Begin Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(begin_time))}')
lr_model = LogisticRegression()
lr_model.fit(x_train_lr, y_train)
lr_model2 = LogisticRegression()
lr_model2.fit(x_train_lr2, y_train)
joblib.dump(lr_model, './model/lr_model.pkl')
joblib.dump(lr_model2, './model/lr_model2.pkl')
end_time = time.time()
print(f'End Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(end_time))}')
对比三组效果,分别是单独的XGB模型,XGB的叶子特征独立LR模型,特征拼接的LR模型,先构建效果函数:
##效果输出函数
def func_print_score(x_data,y_data,data_type,model_x):
y_pred = model_x.predict(x_data)
print(f'==============({data_type})===================')
confusion = metrics.confusion_matrix(y_data, y_pred)
print(confusion)
print('------------------------')
auc = metrics.roc_auc_score(y_data,y_pred)
print(f'AUC: {auc}')
print('------------------------')
accuracy = metrics.accuracy_score(y_data,y_pred)
print(f'Accuracy: {accuracy}')
print('------------------------')
aupr = metrics.average_precision_score(y_data, y_pred)
print(f'AUPR: {aupr}')
print('------------------------')
report = metrics.classification_report(y_data, y_pred)
print(report)
print('=============================================')
分别输出混淆矩阵,AUC,Accuracy,AUPR(AUC有效面积,衡量不均衡分类时非常好用),以及分类报告,输出结果如下:
==============(testdata-xgb)===================
[[248629 3305]
[ 44416 3650]]
------------------------
AUC: 0.5314093688885991
------------------------
Accuracy: 0.84093
------------------------
AUPR: 0.18790537837217178
------------------------
precision recall f1-score support
0 0.85 0.99 0.91 251934
1 0.52 0.08 0.13 48066
avg / total 0.80 0.84 0.79 300000
=============================================
==============(testdata-xgb-lr)===================
[[247447 4487]
[ 43073 4993]]
------------------------
AUC: 0.5430338904724129
------------------------
Accuracy: 0.8414666666666667
------------------------
AUPR: 0.19828793875544898
------------------------
precision recall f1-score support
0 0.85 0.98 0.91 251934
1 0.53 0.10 0.17 48066
avg / total 0.80 0.84 0.79 300000
=============================================
==============(testdata-xgb-lr2)===================
[[251376 558]
[ 47867 199]]
------------------------
AUC: 0.5009626374208841
------------------------
Accuracy: 0.8385833333333333
------------------------
AUPR: 0.16064502596303487
------------------------
precision recall f1-score support
0 0.84 1.00 0.91 251934
1 0.26 0.00 0.01 48066
avg / total 0.75 0.84 0.77 300000
=============================================
结果数据惨不忍睹,我们将PR曲线打印出来,代码如下:
##测试数据的PR曲线
probas_xgb = model.predict_proba(x_test)
probas_lr = lr_model.predict_proba(x_test_lr)
probas_lr2 = lr_model2.predict_proba(x_test_lr2)
##precision_recall_curve函数
precision_xgb,recall_xgb, thresholds_xgb = metrics.precision_recall_curve(y_test, probas_xgb[:,1])
precision_lr,recall_lr, thresholds_lr = metrics.precision_recall_curve(y_test, probas_lr[:,1])
precision_lr2,recall_lr2, thresholds_lr2 = metrics.precision_recall_curve(y_test, probas_lr2[:,1])
plt.figure(figsize=(8,6))
plt.plot(recall_xgb, precision_xgb, label = 'xgb', alpha = 0.8, color = 'red')
plt.plot(recall_lr, precision_lr, label = 'xgg-lr', alpha = 0.8, color = 'blue')
plt.plot(recall_lr2, precision_lr2, label = 'xgb-lr2', alpha = 0.8, color = 'green')
plt.plot([0,1],[0,1],'k--')
#图例打印
plt.legend(bbox_to_anchor=(1.05, 0), loc = 3, borderaxespad = 1)
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('Recall Rate')
plt.ylabel('Precision Rate')
plt.title('PR Curve')
最后的PR曲线,更惨不忍睹,曲线太秀了,辣眼睛:
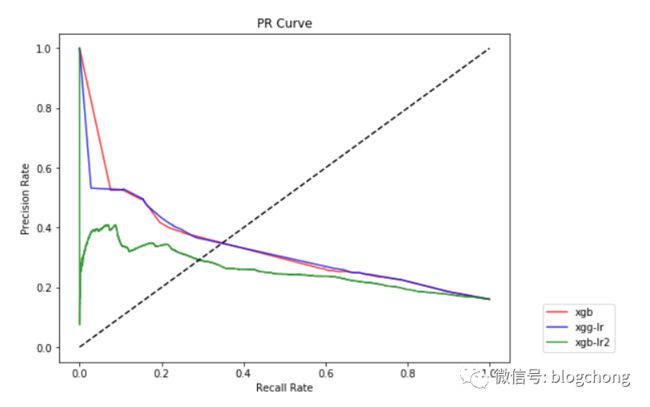
从PR曲线的角度看,还不如纯粹的XGB模型效果好,但这个曲线并不能代表任何东西,因为我们所以的流程都是奔着能跑通,以及流程走通为主要目的,如果大家看github上的源码,会发现存在大量的临时gc回收等动作,没办法,我的阿里云试验机子内存以及核太小,只能先把流程跑通再说。
以上所有示例代码,以及项目,代码都放在了Github上(记得给start哈):
https://github.com/blogchong/data_and_advertisement
总之,大概的流程逻辑如上了。
05
总结
CTR预估不管是过去,还是未来都是重中之中,这里给出的示例是XGB+LR的组合方案,也算业界一个典型的Baseline方案,熟悉基准方案对于理解CTR预估还是有一定帮助的。
况且对于一些初入广告领域的朋友来说,也是一个不错的练手项目。
而且这里是CTR预估,其实底层核心都是对于目标的拟合,底层方案是可以互通的,比如后面可能涉及到oCPX,以及其他类似的领域。绕来绕去,最后发现了其实业务场景映射下来,很多底层技术都是互通的,而上层的业务更多关注于样本以及特征的构建。
先不说这么多,下个阶段,我们可能将脱离常规的机器学习技术方案了,是的,题目都已经想好了,就叫《广告的召回与LookAlike,万物皆可Embedding》。
参考文献
【01】看了很多资料,大过年的,实在没有精力整理了,改天补上。

文章都看完了,还不点个赞来个赏~
OTHER相关系列文章(数据与广告系列)
《数据与广告系列十一:从性别预测的CASE开始手撕机器学习代码》
《数据与广告系列十二:接上一篇,见习算法工程师教程》
《数据与广告系列十三:广告中的异常预测问题》
《数据与广告系列十四:智能定向&基于FM的标签组合推荐思路》
《数据与广告系列十五:商业兴趣标签建模&XGboost调优实战》
