AsicBoost——比特币挖矿捷径
参考自更全资料
AsicBoost is a method to speed up Bitcoin mining by a factor of approximately 20%. AsicBoost is an algorithmic optimization and therefore applicable to all types of mining hardware.
SHA 256

SHA 256先把数据分成64字节的chunk单元,然后经过Expander Function得到Message Schedule,然后经过Compressor得到最终的hash摘要。
比特币的double SHA 256
比特币区块头结构
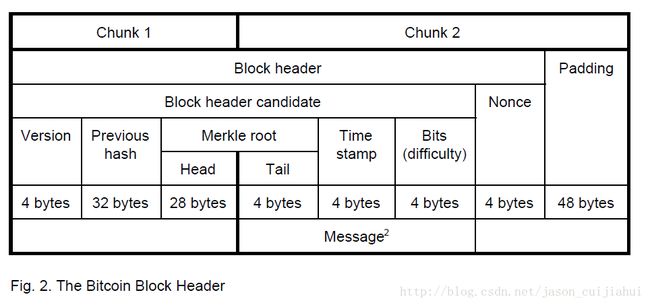
比特币的double SHA 256概述
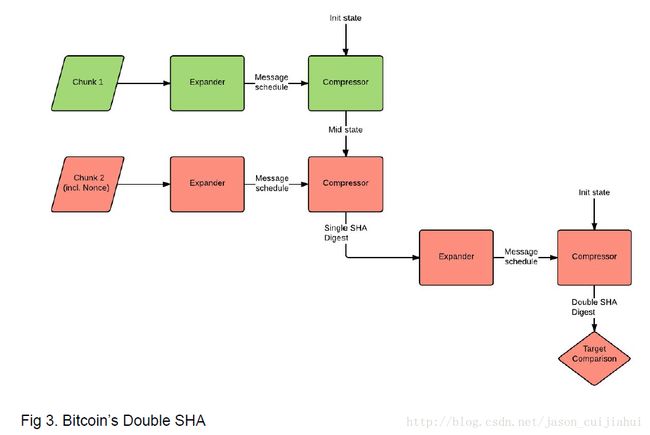
根据区块头的字段进一步细化
注意:
- 关于Mid state指的是SHA 256(0)后得到的H0,更多挖矿算法和详细内容
- Mid state以及Message统称为 Work item
- The components shown in red lie in the inner loop and update at high frequency.
- The components shown in green lie in the outer loop and update less frequently.
- All Bitcoin mining ASICs process only the inner loop internally. The work items are precomputed and passed to the ASIC from outside.
关于Work items
Each work item is constructed from a new block header candidate which in turn is constructed from a new Merkle root .
Since the Merkle root spans both chunks of the block header, updating the Merkle root affects both components of the work item: Midstate (depending on chunk 1) and Message (depending on chunk 2).
Therefore, it is usually not the case that different work items share either of the two components. This is the reason why the information in Message Schedule 1 cannot be reused across the processing of multiple work items.
AsicBoost
什么是Colliding Work Items?
AsicBoost achieves its performance gain by highly reusing Message Schedule 1 across multiple work items.
In order to do so, AsicBoost generates many block header candidates that all share a common Message part.
We speak of block header candidates as colliding if they collide in the Message part, or, in other words, if they differ from each other only in chunk 1.
The work items derived from colliding block header candidates all share a common Message component and differ only in the Mid state component. We speak of work items as colliding if they collide in the Message component.
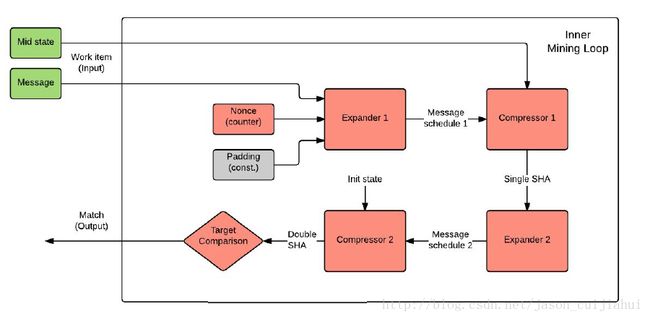
AsicBoost算法流程
A set of colliding block headers allows AsicBoos t to swap the inner and outer mining loops as shown below. The Message is constant throughout the processing of the entire set of colliding block headers.

- AsicBoost’s inner loop iterates over the Mid states of all colliding block headers.
- The Nonce is now updated in the outer loop rather than the inner loop.
- Message schedule 1 is updated less frequently and its information is reused across multiple Mid states.
AsicBoost对挖矿效率的提高
The AsicBoost method eliminates the Expander 1 function from the inner loop, leaving only Compressor 1, Expander 2 and Compressor 2 to be processed at high frequency.
Since each of the four functions have similar complexity, up to one quarter of the total computational work can be saved by this approach.
The exact gain depends on the size of the set of colliding work items.
Suppose the Expander 1 takes x percent of the computational work of the four functions combined. Having n colliding work items then gives a total gain of x (n − 1)/n percent.
说明:
本来大小为n的colliding集合要算n次Message schedule1,并执行Expander 1,而现在集合的Message schedule1相同,执行一次Expander 1即可,所以提高的效率为1-1/n,最后在乘上Expander 1所占的比例x即可。
如何构建colliding block header candidates
方法1 Merkle root collisions
One way is to calculate many merkle roots at random and filter them based on their last 4 bytes until sufficiently many are found that collide in their last 4 bytes.
There are a number of tradeoffs to be considered when filtering for collisions. The optimal process depends on the targeted value for n and the number and speed of the hashing cores to be served.
There are several methods to calculate merkle tree roots that are more efficient than changing the coinbase field.
One method is based on permuting the order of transactions inside the block, or, in other words, permuting the leafs of the merkle tree.
其它方法(不该Merkle Root看chunk 1有什么地方可以改的)
Another, more efficient way to produce colliding block headers is by using bits inside Chunk 1 but outside the merkle root that are free for the miner to choose.
This does not require finding any merkle root collisions. Instead, one merkle root is chosen and fixed. The free bits are then updated in a loop and the respective Mid states are computed from Chunk 1. Each Mid state obtained in this way gives a new colliding work item, so that this method is extremely efficient.
疑惑
- 据说算法鼓励挖空区块,这点我看不出所以然,欢迎讨论(个人认为并不会)
- 隔离见证版本后堵住了这个漏洞,是怎么堵住的,欢迎讨论和补充资料