写在前面:2020年面试必备的Java后端进阶面试题总结了一份复习指南在Github上,内容详细,图文并茂,有需要学习的朋友可以Star一下!
GitHub地址:https://github.com/abel-max/Java-Study-Note/tree/master
前言
在当今软件开发中 Cloud Native 随着企业功能的日益完善逐渐被越来越多的公司所接受。这一变动往往不仅是技术选型的改变,而更多是在开发、运维,项目管理理念上的变化。比如之前我们在开发企业软件的时候会将前后端写在一个大型应用中,在团队组织上分为开发,运维,测试团队,架构师,且用 Waterfall 的方式管理整个项目交付。但在 Cloud Native 文化中这些已经被一组新的方法和技术栈(或者说是一种新的文化)所替代,比如:DevOps、持续交付(CI/CD)、微服务(MicroServices)、全栈开发、敏捷开发,领域驱动开发 (Domain Driven Development), 测试驱动开发 (Test Driven Development), Event Sourcing 等等。再配合上人工智能在业务中的嵌入使得我们的应用在商业上产生了更大的价值。
今天介绍的 Micronaut 属于微服务,后端技术。目前本人看好它以后大概率替代 Springboot 成为 JVM 语言中最流行的服务端框架!
本文将从基础的概念开始介绍 Mircornaut,并集成 Kafka Producer, Kafka Streams 和 GraphQL 写一个简单的后端 Web 应用,来展示如何利用它们完成 Event Sourcing 系统中数据历史存储和更新当前 View 功能的。读者可以以这个为小模板作为基础将其扩展成自己 Event Sourcing 系统中的一个 Micronaut MicroService 后端。
1 为什么使用 Micronaut?
经常有人问我,为什么我的文章都是围绕 NLP,Kafka,GraphQL, MicroService 展开的?我的理由很简单,这些技术的组合是我个人认为开发企业级微服务软件目前最好的技术搭配,其强大体现在如下方面:
- GraphQL 不同于 REST 服务,它使前端在访问后台接口变得更加灵活
- 架构上,将大型 Monolithic Application 按照其功能和领域拆分为小的微服务,降低了设计架构和业务逻辑上的复杂度,并且降低了服务间的耦合性
- 基于 Event Sourcing 的系统设计兼顾了 Data Driven Business 的主题,这些数据在 AI 时代会给我们的机器学习提供源源不断的动力
- AI 模型最终可以以微服务的形式部署上线 辅助业务
- 微服务应用大大提升了软件测试速度和部署周期,使工具与敏捷管理无缝衔接
- 有了 Cloud Native 的技术栈使我们可以将开发,运维通过 CI/CD 实现全流程高度自动化
- Kubernetes 配合 Kafka 和分布式数据库使后台可以水平扩容,并且使系统更加健壮,稳定
- 无痛在企业云和公有云之间迁移
- Micronaut 提供了大量开箱即用的云端功能,比如:AWS 的 Serverless
- 简单总结就是:数据驱动 + 小、快、灵、稳
可惜以 Java 为首的企业级框架在实际中通常都是小快灵的反例,比如 Springboot 应该说是 Java 生态圈最近几年最流行的框架,且 Spring Cloud 在这个基础上又对云服务做了进一步的扩展。虽然对比之前的 Spring 降低了很大复杂度,但 Springboot 底层还是多少延续了 Spring 框架过于冗余的弱点,即便做成微服务,但由于它内部反射机制的存在,使 build 时间、内存占用等指标与 Go,Node.js 相比显得笨重了很多。
与 Springboot(还内置了 Tomcat)不同,Micronaut 不但只是选择性提供了构建微服务应用程序所需的工具,同时针对启动速度和内存开销等方面做了进一步的优化。且在设计上延续了 Spring 依赖注入序等优良传统,还去掉了诸多 Spring 中冗余模块、耗内存的反射机制等,使应用的开发、测试、部署、运维变得更加高效、简洁。
本文会以 Springboot 程序员的视角,从零开始设计一个基于 Event Sourcing 的完整微服务项目。
2. 命令行工具配置
Micronaut 提供了强大的命令行工具来帮助我们建立项目,我个人使用的是 MacOS 系统,但其他 Unix like 的系统操作应该都是类似的。
首先下载安装 SDKMAN
$ curl -s https://get.sdkman.io | bash
$ source "$HOME/.sdkman/bin/sdkman-init.sh"检查下是否配置成功:
$ sdk
==== BROADCAST =================================================================
* 2020-04-16: Jbang 0.22.0.2 released on SDKMAN! See https://github.com/maxandersen/jbang/releases/tag/v0.22.0.2 #jbang
* 2020-04-15: Gradle 6.4-rc-1 released on SDKMAN! #gradle
* 2020-04-15: Kotlin 1.3.72 released on SDKMAN! #kotlin
================================================================================
Usage: sdk [candidate] [version]
sdk offline
commands:
install or i [version] [local-path]
uninstall or rm
list or ls [candidate]
use or u
default or d [version]
current or c [candidate]
upgrade or ug [candidate]
version or v
broadcast or b
help or h
offline [enable|disable]
selfupdate [force]
update
flush
candidate : the SDK to install: groovy, scala, grails, gradle, kotlin, etc.
use list command for comprehensive list of candidates
eg: $ sdk list
version : where optional, defaults to latest stable if not provided
eg: $ sdk install groovy
local-path : optional path to an existing local installation
eg: $ sdk install groovy 2.4.13-local /opt/groovy-2.4.13 安装 Micronaut CLI
$ sdk install micronaut
Downloading: micronaut 1.3.4
In progress...
########################################################################################################################################################################### 100,0%########################################################################################################################################################################### 100,0%
Installing: micronaut 1.3.4
Done installing!
Setting micronaut 1.3.4 as default.3 创建新项目
下面使用 Micronaut 命令行工具创建 Kotlin,Kafka Client,Kafka Streams 和 GraphQL 集成的项目。
$ mn create-app micronaut-kafka-graphql -f kafka-streams,graphql,kafka -l kotlin-f: 表示需要添加的依赖
-l: 语言设置
更详细的关于 create-app 选项可以通过输入 mn 后在交互式命令行下使用 help API 查看:
mn> help create-app
Usage: mn create-app [-hinvVx] [-b=BUILD-TOOL] [-l=LANG] [-p=PROFILE] [-f=FEATURE[,FEATURE...]]...
[NAME]
Creates an application
[NAME] The name of the application to create.
-b, --build=BUILD-TOOL Which build tool to configure. Possible values: gradle, maven.
-f, --features=FEATURE[,FEATURE...]
The features to use. Possible values: annotation-api, application,
asciidoctor, aws-api-gateway, aws-api-gateway-graal, cassandra,
config-consul, data-hibernate-jpa, data-jdbc, discovery-consul,
discovery-eureka, ehcache, elasticsearch, file-watch, flyway,
graal-native-image, graphql, hazelcast, hibernate-gorm, hibernate-jpa,
http-client, http-server, jdbc-dbcp, jdbc-hikari, jdbc-tomcat, jib,
jrebel, junit, kafka, kafka-streams, kotlintest, kubernetes,
liquibase, log4j2, logback, management, micrometer,
micrometer-appoptics, micrometer-atlas, micrometer-azure-monitor,
micrometer-cloudwatch, micrometer-datadog, micrometer-dynatrace,
micrometer-elastic, micrometer-ganglia, micrometer-graphite,
micrometer-humio, micrometer-influx, micrometer-jmx,
micrometer-kairos, micrometer-new-relic, micrometer-prometheus,
micrometer-signalfx, micrometer-stackdriver, micrometer-statsd,
micrometer-wavefront, mongo-gorm, mongo-reactive, neo4j-bolt,
neo4j-gorm, netflix-archaius, netflix-hystrix, netflix-ribbon,
picocli, postgres-reactive, rabbitmq, redis-lettuce, security-jwt,
security-session, spek, spock, springloaded, swagger-groovy,
swagger-java, swagger-kotlin, tracing-jaeger, tracing-zipkin,
vertx-mysql-client, vertx-pg-client
-h, --help Show this help message and exit.
-i, --inplace Create a service using the current directory
-l, --lang=LANG Which language to use. Possible values: java, groovy, kotlin.
-n, --plain-output Use plain text instead of ANSI colors and styles.
-p, --profile=PROFILE The profile to use. Possible values: base, cli, configuration,
federation, function, function-aws, function-aws-alexa, grpc, kafka,
profile, rabbitmq, service.
-v, --verbose Create verbose output.
-V, --version Print version information and exit.
-x, --stacktrace Show full stack trace when exceptions occur.项目创建成功之后在 Intellij 中打开:

图1:Micronaut 项目初始化截图
如图1 所示,命令行工具成功为我们生成了项目及 Gradle 配置,而且提供了部署应用的 Dockerfile 模板。
4 实现一个简易的 Event Sourcing 系统
在该项目设计的 Event Sourcing 系统中,Kafka 是最核心的组成部分,它具备着良好的高吞吐、高容错、分布式水平扩展能力,而且在此基础上保证数据零丢失。在系统设计上 Kafka 可以被看作成一个中央 Event Bus,一切业务逻辑的异步操作、微服务间的通讯都通过它中转。
为了方便做功能上的展示,我在这个项目中会着重实现几个业务中最常见的场景:
实现对前端服务提供 GraphQL Mutation 接口,这个接口负责接收写操作给后端
实现 Kafka Producer 用于将从 GraphQL 接口获得的数据写入 Kafka Broker
实现 Kafka Streams 将已经写入 Kafka 的数据做进行进一步 Transformation 操作,且通过 Kafka Streams 内置的 RocksDB 对当前数据更新,并提供查询的 View
实现 GraphQL Query 通过访问 View 获取最新的数据,并将结果返回给前端
假设,我们的需求是收集市场变化的信息:一方面我们希望在后台存储过去所有市场的历史变化,用于数据分析、统计;另一方面我们需要给前端查询只返回最新的市场信息。
我们简单定义一个 Kotlin 数据类,等同于 Java 的 Pojo 类来表示市场数据模型(在项目下建立 model 目录,并建立一个 Market 的数据类):
data class Market (
var marketId: String,
val currentStatus: String,
val country: String,
val zipcode: String,
val timestamp: Long = System.currentTimeMillis()
)4.1 GraphQL Mutation 增添数据接口定义
为了能使前端框架与我们后台建立联系,首先我们需要一个接口,该接口负责处理前端写数据的请求。对大数据,数据仓库有经验的同学都知道,在海量数据中我们是不会做行级 Update 操作的。所有写入的数据都会以 Append 的方式写入 Kafka,Kafka 的本质其实也就是分布式的日志文件系统,所以这些在 Event Sourcing 系统中增、删、查、改的操作体现在 GraphQL 或者 HTTP 层面上都可以归结成 POST 请求。在 GraphQL 中我们把除了查找之外的接口都定义成 Mutation。
首先我们在 model 文件夹下 定义一个类映射前端的 Request 输入,命名为:
MarketInput:
data class MarketInput (
val marketId: String,
val currentStatus: String,
val country: String,
val zipcode: String
)然后配置 Micronaut GraphQL 接口。在项目 resources 文件夹下建立 schema.graphqls 文件,并定义接口:
type Market {
marketId: ID!
currentStatus: String!
country: String!
zipcode: String!
timestamp: Long!
}
input MarketInput {
marketId: ID!
currentStatus: String!
country: String!
zipcode: String!
}
type Mutation {
createMarket(marketInput: MarketInput): Market
}
type Query {
allMarkets: [Market]
}
schema {
mutation: Mutation
query: Query
}这两个接口分别为:
createMarket 方法从前端接收 MarketInput 对象,并根据这个输入生成 Market 对象(给 MarketInput 打时间戳 -> 设计简单是为了方便项目展示,实际意义不大)、存入后端
allMarkets 方法返回当前所有市场信息(所以是个 Market 列表)
其他部分都是标准的 GraphQL 配置语法,这里不做详细解释。
4.2 实现 Kafka Producer
在我们配置 GraphQL 接口前,需要实现一个 Service 来完成写数据进 Kafka 的操作。在项目下建立 service 文件夹,并创建类 CreateMarketService,具体实现如下:
package micronaut.kafka.graphql.service
import io.micronaut.configuration.kafka.annotation.KafkaClient
import io.micronaut.configuration.kafka.annotation.KafkaKey
import io.micronaut.configuration.kafka.annotation.Topic
import micronaut.kafka.graphql.model.Market
@KafkaClient
interface CreateMarketService {
@Topic("markt-event-store")
fun createMarket(@KafkaKey id: String, market: Market)
}Micronaut 中 被@KafkaClient 修饰的接口在运行时会自动生成相应的 Producer 实现,@Topic 定义了接收 Producer 数据的 Kafka Topic。如果在方法参数中使用 @KafkaKey 修饰,那么这个参数被作为 Topic 的 Key对待。如果不做特殊配置 Micronaut 默认使用 JSON 序列化 Pojo 对象。
4.3 配置 GraphQL Mutation 接口
在有了接口的定义和 Service 的实现后, 我们现在要做的就是把这两个部分衔接起来。
在项目目录下建立新目录 graphql,在这个目录下添加两个类:
工厂类 GraphQLFactory 用于注册所有 GraphQL 接口需要的 Query 和 Mutation:
package micronaut.kafka.graphql.graphql
import graphql.GraphQL
import graphql.schema.idl.RuntimeWiring
import graphql.schema.idl.SchemaGenerator
import graphql.schema.idl.SchemaParser
import graphql.schema.idl.TypeDefinitionRegistry
import io.micronaut.context.annotation.Bean
import io.micronaut.context.annotation.Factory
import io.micronaut.core.io.ResourceResolver
import java.io.BufferedReader
import java.io.InputStreamReader
import javax.inject.Singleton
@SuppressWarnings("Duplicates")
@Factory
class GraphQLFactory {
@Bean
@Singleton
fun graphQL(resourceResolver: ResourceResolver,
createMarketDataFetcher: CreateMarketDataFetcher): GraphQL {
val schemaParser = SchemaParser()
val schemaGenerator = SchemaGenerator()
val typeRegistry = TypeDefinitionRegistry()
typeRegistry.merge(schemaParser.parse(BufferedReader(InputStreamReader(
resourceResolver.getResourceAsStream("classpath:schema.graphqls").get()))))
val runtimeWiring = RuntimeWiring.newRuntimeWiring()
.type("Mutation") { typeWiring -> typeWiring
.dataFetcher("createMarket", createMarketDataFetcher)
}
.build()
val graphQLSchema = schemaGenerator.makeExecutableSchema(typeRegistry, runtimeWiring)
return GraphQL.newGraphQL(graphQLSchema).build()
}
}如代码所示,我们提供了这个工厂类,并提供了 Mutation 接口,且注册了 GraphQL 的方法 createMarket。
该类需要被 Factory 修饰, graphQl 方法被 Singleton 和 Bean 修饰,这样保证了在整个应用上只注册了唯一的一个 GraphQL 工厂。
在 graphql 文件夹下创建 MarketDataFetcher 实现类 CreateMarketDataFetcher:
package micronaut.kafka.graphql.graphql
import com.fasterxml.jackson.databind.ObjectMapper
import graphql.schema.DataFetcher
import graphql.schema.DataFetchingEnvironment
import micronaut.kafka.graphql.model.Market
import micronaut.kafka.graphql.model.MarketInput
import micronaut.kafka.graphql.service.CreateMarketService
import micronaut.kafka.graphql.service.CurrentMarketStore
import javax.inject.Singleton
@Singleton
@SuppressWarnings("Duplicates")
class CreateMarketDataFetcher(private val createMarketService: CreateMarketService,
private val objectMapper: ObjectMapper) : DataFetcher {
override fun get(env: DataFetchingEnvironment): Market {
val marketInput =
objectMapper.convertValue(env.getArgument("marketInput"), MarketInput::class.java)
val market = Market(
marketId = marketInput.marketId,
currentStatus = marketInput.currentStatus,
country = marketInput.country,
zipcode = marketInput.zipcode
)
createMarketService.createMarket(id = market.marketId, market = market)
return market
}
} 这个类必须继承 DataFetcher 且同样被 Singleton 修饰,且自动装配了我们之前定义的 CreateMarketService 和 ObjectMapper(用于序列,反序列化 JSON 数据)。
为了能让这个类通过工厂注册 GraphQL 接口,我们需要自己实现 get 方法。因为这个类生成的对象是为 Mutation 中的 createMarket(inputMarket: InputMarket) 提供实现的,所以我们需要先获取 inputMarket 这个参数。DataFetchingEnvironment 提供了方便的方式,通过 getArgument 方法我们即可获得这个传进来的参数。如果是 primitive 数据类型的参数,那它可以直接解析出来,但如果像我们的情况,传入参数是一个数据对象,用 getArgument 会得到一个 JSON 格式的字符串,类自动装载的 ObjectMapper 就是方便我们用来解析它的,语法见代码。
在获得了 InputMarket 的对象后,我们就可以通过这一输入信息创建 Market 对象,并通过 createMarketService(之前实现的 Kafka Producer)写入数据进 Kafka Topic,并将返回 market 对象给前端作为 Response。
4.4 配置 Kafka Streams
Kafka 之所以能成为当今最强大的中间件,很大一部分原因是出于它对各种流式处理提供了丰富的流式处理 API 比如 Kafka Streams ,利用这些 API 我们可以轻松地完成对实时数据各种变换,Join,窗口操作,聚合函数等复杂操作,也可以用 Kafka Streams 自带的 RocksDB 通过 Statestore 对前端查询提供 View。
在 service 文件夹下建立 MarketStream 类,具体实现如下:
package micronaut.kafka.graphql.service
import com.fasterxml.jackson.databind.ObjectMapper
import io.micronaut.configuration.kafka.serde.JsonSerde
import io.micronaut.configuration.kafka.streams.ConfiguredStreamBuilder
import io.micronaut.context.annotation.Factory
import micronaut.kafka.graphql.model.Market
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.Serdes
import org.apache.kafka.streams.StreamsConfig
import org.apache.kafka.streams.kstream.*
import org.apache.kafka.streams.state.Stores
import javax.inject.Named
import javax.inject.Singleton
const val MARKET_EVENT_TOPIC = "market-event-store"
const val CURRENT_MARKET_STORE = "current-market-store"
const val MARKET_APP_ID = "market-stream"
@Factory
class MarketStream {
@Singleton
@Named(MARKET_APP_ID)
fun buildMarketStream(builder: ConfiguredStreamBuilder, objectMapper: ObjectMapper): KStream? {
val marketStore = Stores.inMemoryKeyValueStore(CURRENT_MARKET_STORE)
builder.configuration[StreamsConfig.PROCESSING_GUARANTEE_CONFIG] = StreamsConfig.EXACTLY_ONCE
builder.configuration[ConsumerConfig.AUTO_OFFSET_RESET_CONFIG] = "earliest"
builder.configuration[ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG] = true
val stream = builder.stream(MARKET_EVENT_TOPIC,
Consumed.with(Serdes.String(), JsonSerde(objectMapper, Market::class.java)))
stream.groupBy(
{ _, value -> value.country },
Grouped.with(
Serdes.String(),
JsonSerde(objectMapper, Market::class.java)))
.reduce(
{value1, value2 ->
if(value1.timestamp <= value2.timestamp) {
return@reduce value2
} else {
return@reduce value1
}
},
Materialized
.`as`(marketStore)
.withKeySerde(Serdes.String())
.withValueSerde(JsonSerde(objectMapper, Market::class.java))
)
.toStream()
.print(Printed.toSysOut())
return stream
}
} Micronaut Kafka Streams 的实现与 native 的 Streams API 一模一样,只是用 Factory(返回 KStream 对象)修饰了一下。
这段代码大概实现的目的是,当我得到相同 marketId 的对象后,通过对比 timestamp 的大小,判断哪条数据是最新的,并且将最新数据储存在 Statestore 中(为了代码方便我只往 store 中写和更新数据,不包括删除指定数据)。
聚合操作后可以通过 Materialized 将聚合操作结果写入 Statestore 中。
4.5 提供 Statestore 访问
Streams 只是对 Statestore 进行写的操作,我们还需要一个接口用来将写进的数据读出来。所以继续在 service 文件夹下,建立一个新类 CurrentMarketStore,实现如下:
package micronaut.kafka.graphql.service
import io.micronaut.configuration.kafka.streams.InteractiveQueryService
import micronaut.kafka.graphql.model.Market
import org.apache.kafka.streams.state.QueryableStoreTypes
import javax.inject.Singleton
@Singleton
class CurrentMarketStore(private val interactiveQueryService: InteractiveQueryService) {
fun getAllMarkets(): List {
val marketStore = interactiveQueryService
.getQueryableStore(CURRENT_MARKET_STORE, QueryableStoreTypes.keyValueStore())
return marketStore
.map { kvStore -> kvStore.all().asSequence().map { v -> v.value }.toList() }
.orElse( emptyList())
}
} 这个类下的方法将 Statestore 中所有的数据都以 List
4.6 创建 GraphQL Query 读取数据
在 schema.graphqls 文件中添加一个新的 Query 方法:
type Query {
allMarkets: [Market]
}
在 graphql 下的 MarketDataFetchers 中,添加新类:
@Singleton
@SuppressWarnings("Duplicates")
class AllMarketDataFetcher(private val currentMarketStore: CurrentMarketStore) : DataFetcher> {
override fun get(env: DataFetchingEnvironment): List {
return currentMarketStore.getAllMarkets()
}
} 这个类与之前的 Mutation 很像,不同的只是这次不需要传递参数,且自动装配上面讲过的 CurrentMarketStore,通过调用 getAllMarkets() 方法获得全部 Statestore 中的 Market 对象。
最后再将这个新的 DataFetcher 的对象注册在 GraphQL Factory 中。
这个类最终是这样的:
package micronaut.kafka.graphql.graphql
import graphql.GraphQL
import graphql.schema.idl.RuntimeWiring
import graphql.schema.idl.SchemaGenerator
import graphql.schema.idl.SchemaParser
import graphql.schema.idl.TypeDefinitionRegistry
import io.micronaut.context.annotation.Bean
import io.micronaut.context.annotation.Factory
import io.micronaut.core.io.ResourceResolver
import java.io.BufferedReader
import java.io.InputStreamReader
import javax.inject.Singleton
@SuppressWarnings("Duplicates")
@Factory
class GraphQLFactory {
@Bean
@Singleton
fun graphQL(resourceResolver: ResourceResolver,
createMarketDataFetcher: CreateMarketDataFetcher,
allMarketDataFetcher: AllMarketDataFetcher ): GraphQL {
val schemaParser = SchemaParser()
val schemaGenerator = SchemaGenerator()
val typeRegistry = TypeDefinitionRegistry()
typeRegistry.merge(schemaParser.parse(BufferedReader(InputStreamReader(
resourceResolver.getResourceAsStream("classpath:schema.graphqls").get()))))
val runtimeWiring = RuntimeWiring.newRuntimeWiring()
.type("Mutation") { typeWiring -> typeWiring
.dataFetcher("createMarket", createMarketDataFetcher)
}
.type("Query") { typeWiring -> typeWiring
.dataFetcher("allMarkets", allMarketDataFetcher)
}
.build()
val graphQLSchema = schemaGenerator.makeExecutableSchema(typeRegistry, runtimeWiring)
return GraphQL.newGraphQL(graphQLSchema).build()
}
}如代码所示, 新的 Query 方法 allMarkets 现在也被注册在 GraphQL 的对象上,这样我们的程序的代码部分就算完成了。
5 完整流程展示
为了看下效果,我们将整个 Event Sourcing 流程从数据输入,Kafka 存储、数据状态更新, 到读出 完整的操作一遍。在本地运行代码时,除了我们写好的程序外,还需要安装一个本地的 Kafka Cluster。关于本地 Kafka 安装,最简单的途径是从 Confluent(Apache Kafka 的商业版)官网拉一个 Docker 镜像下来。如果不习惯用 Docker 也可以自己手动配置一个,具体见官方文档。
假设你配置好了本地了 Confluent,首先启动 Zookeeper 和 Kafka Broker(不包括 Confluent 其他服务):
$ confluent start kafka在 Zookeeper 和 Kafka 启动之后,需要我们先手动创建一个 ”market-event-store“ Topic 用于储存历史数据(创建新的 Topic 也可以用 Kafka AdminClient 完成,但生产环境中我个人不推荐这种做法),由于我们只有一个节点所以将 replication-factor 设为 1:
$ kafka-topics --create --zookeeper localhost:2181 --topic market-event-store --partitions 10 --replication-factor 1
GraphQL 自带 Web 工具,可以在 application.yml 文件中添加:
graphql:
graphiql:
enabled: true然后用 gradle run 启动后台程序(你会惊讶地发现,启动变得多么快!)。
后台启动好之后可以通过 http://localhost:8080/graphiql 写 GraphQL 语句与后台交互。我们先从 mutation 开始,创建一个新的 Market 对象:
mutation {
createMarket(marketInput: {
marketId: "id-1", currentStatus: "closed", country: "china", zipcode:"130000"
}) {
marketId
currentStatus
country
zipcode
timestamp
}
}成功后会返回:
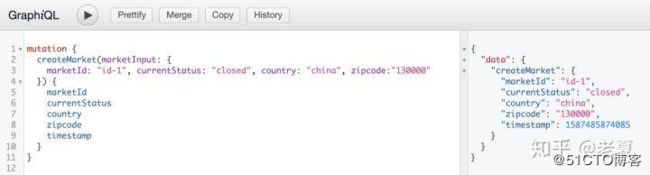
然后在输入一个新的 Market 这次设置 marketId 为 id-2,之后得到:

然后我们用 getAllMarkets 查询一下当前状态:
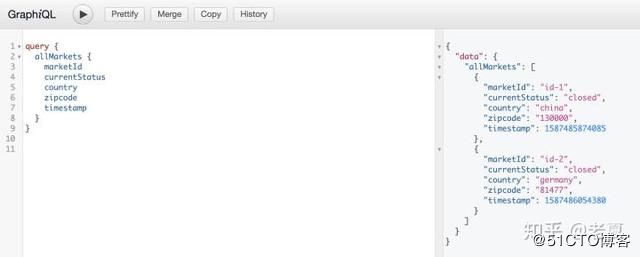
可以看到我们有两条数据,且 currentStatus 状态都为 closed。下面我们将 marketId 为 id-1 的数据 currentStatus 改为 open:

再通过查询看下当前 Statestore 状态:

发现,依然返回两条数据,但是其中一条 marketId 为 ”id-1“ 的数据 currentStatus 改为了 open。刚好达到了我们更新 Statestore 的效果。
最后再检查一下是否所有数据变动都被成功捕获到 Kafka 后台,在命令行输入:
$ kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic market-event-store
命令行输出:
{"marketId":"id-1","currentStatus":"closed","country":"china","zipcode":"130000","timestamp":1587549158784}
{"marketId":"id-2","currentStatus":"closed","country":"germany","zipcode":"81477","timestamp":1587549166942}
{"marketId":"id-1","currentStatus":"open","country":"china","zipcode":"130000","timestamp":1587549177136}可以观察到,marketId 为 id-1 的数据在历史数据中一共出现了两次,也符合我们之前的需求。
6 总结
从代码可以看出,Micronaut 整体实现起来的思路和 Springboot 是十分相像的,Micronaut 延续了依赖注入和类似于 Bean 的概念,而且在此基础上加强了对 Cloud Native 的支持,比如 AWS Serverless 支持,Docker 部署,health check, metrics,distributed tracking 等。
在服务端开发时,我刻意从 Java 改为了 Kotlin,但同时会在 Kotlin 中引用一些经典的 Java 生态的库,二者无缝衔接使开发更加轻松、欢乐。代码中目前缺少测试,这块知识涉及到的内容比较广,希望以后可以慢慢补全。
在数据无损地录入 Kafka 之后,可以借助 Kafka Connect 这类工具导入进企业的数据仓库或者 Hadoop 这种分布式系统支撑的 Data Lake 中,再在这个基础上对数据仓库建模(这部分也可以用 Kafka Streams 操作),这样就可以为机器学习提供高质量的数据。同时这种 ELT(区别于ETL)的流式数据处理方式也使得整个数据仓库能更加高效,低延时地做实时历史数据统计,为企业提供更多商业价值。
Event Sourcing 系统的另一大受益者是 NLP 领域的知识图谱。其实知识图谱的搭建本质上就是一个图数据库建模的过程,但这个图数据库的数据状态要想产生更大的价值是需要定期更新的。通过 Kafka Streams 支撑的 Event Sourcing 系统使我们可以实时地更新图谱中各个节点间的状态、关系,并结合机器学习,图算法和分布式流式处理做更花式的操作。
性能方面,如果碰到高并发的业务场景可以通过 Kubernetes 轻松给 Kafka Streams 扩容,或者提供更高效的分布式数据库给后台提供访问,如果有需要,完全可以将这个项目中的 写(Producer),数据 Transformation和读 做进一步的微服务拆分,不需要 Web 服务的地方就去掉 Netty Server。
本文没有涉及到异步操作,测试开发,监控,部署,运维,安全等话题,希望日后能有机会做适当补充。有些领域比如“安全“也不在我个人技术栈范围之内,而且部署方式在每个公司都不太一样,最多只能做基本介绍。
来源:知乎——https://zhuanlan.zhihu.com/p/133594611