MongoDB Sharding Chunk分裂与迁移详解
【摘要】云数据库MongoDB版 基于飞天分布式系统和高性能存储,提供三节点副本集的高可用架构,容灾切换,故障迁移完全透明化。
MongoDB Sharding
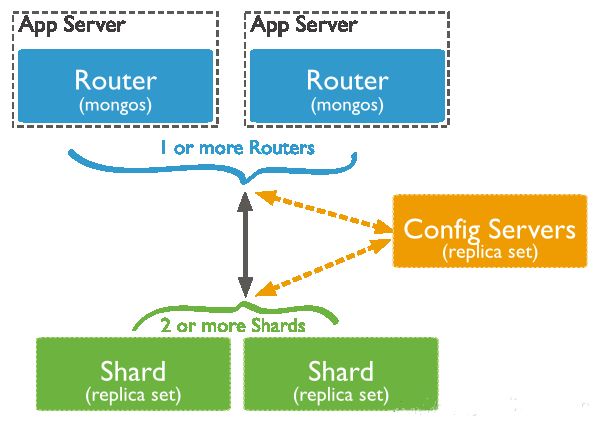
关于MongoDB Sharding的原理,如果不了解请先参考:
- 关于MongoDB Sharding,你应该知道的
- MongoDB Sharded Cluster架构原理
注:本文的内容基于MongoDB 3.2版本。
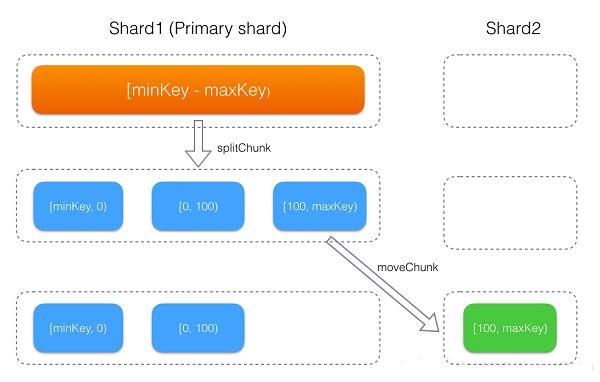
Primary Shard
使用MongoDB Sharding后,数据会以chunk为单位(默认64MB)根据shardKey分散到后端1或多个shard上。
每个database会有一个primary shard,在数据库创建时分配。
- database下启用分片(即调用
shardCollection命令)的集合,刚开始会生成一个[minKey, maxKey]的chunk,该chunk初始会存储在primary shard上,然后随着数据的写入,不断的发生chunk分裂及迁移,整个过程如下图所示。 - database下没有启用分片的集合,其所有数据都会存储到
primary shard。
何时触发Chunk分裂?
mongos上有个sharding.autoSplit的配置项,可用于控制是否自动触发chunk分裂,默认是开启的。如无专业人士指导,强烈建议不要关闭autoSplit,更好的方式是使用「预分片」的方式来提前分裂,后面会详细介绍。
MongoDB的自动chunk分裂只会发生在mongos写入数据时,当写入的数据超过一定量时,就会触发chunk的分裂,具体规则如下。
int ChunkManager::getCurrentDesiredChunkSize() const {
// split faster in early chunks helps spread out an initial load better
const int minChunkSize = 1 << 20; // 1 MBytes
int splitThreshold = Chunk::MaxChunkSize; // default 64MB
int nc = numChunks();
if (nc <= 1) {
return 1024;
} else if (nc < 3) {
return minChunkSize / 2;
} else if (nc < 10) {
splitThreshold = max(splitThreshold / 4, minChunkSize);
} else if (nc < 20) {
splitThreshold = max(splitThreshold / 2, minChunkSize);
}
return splitThreshold;
}
bool Chunk::splitIfShould(OperationContext* txn, long dataWritten) const {
dassert(ShouldAutoSplit);
LastError::Disabled d(&LastError::get(cc()));
try {
_dataWritten += dataWritten;
int splitThreshold = getManager()->getCurrentDesiredChunkSize();
if (_minIsInf() || _maxIsInf()) {
splitThreshold = (int)((double)splitThreshold * .9);
}
if (_dataWritten < splitThreshold / ChunkManager::SplitHeuristics::splitTestFactor)
return false;
if (!getManager()->_splitHeuristics._splitTickets.tryAcquire()) {
LOG(1) << "won't auto split because not enough tickets: " << getManager()->getns();
return false;
}
......
}chunkSize为默认64MB是,分裂阈值如下
| 集合chunk数量 | 分裂阈值 |
|---|---|
| 1 | 1024B |
| [1, 3) | 0.5MB |
| [3, 10) | 16MB |
| [10, 20) | 32MB |
| [20, max) | 64MB |
写入数据时,当chunk上写入的数据量,超过分裂阈值时,就会触发chunk的分裂,chunk分裂后,当出现各个shard上chunk分布不均衡时,就会触发chunk迁移。
何时触发Chunk迁移?
默认情况下,MongoDB会开启balancer,在各个shard间迁移chunk来让各个shard间负载均衡。用户也可以手动的调用moveChunk命令在shard之间迁移数据。
Balancer 在工作时,会根据shard tag、集合的 chunk 数量、shard 间 chunk 数量差值来决定是否需要迁移。
(1)根据shard tag迁移
MongoBD sharding支持shard tag特性,用户可以给shard打上标签,然后给集合的某个range打上标签,MongoDB会通过balancer的数据迁移来保证「拥有tag的range会分配到具有相同tag的shard上」。
(2)根据shard间chunk数量迁移
int threshold = 8;
if (balancedLastTime || distribution.totalChunks() < 20)
threshold = 2;
else if (distribution.totalChunks() < 80)
threshold = 4;| 集合 chunk 数量 | 迁移阈值 |
|---|---|
| [1, 20) | 2 |
| [20, 80) | 4 |
| [80, max) | 8 |
针对所有启用分片的集合,如果「拥有最多数量chunk的shard」与「拥有最少数量chunk的shard」的差值超过某个阈值,就会触发chunk迁移; 有了这个机制,当用户调用addShard添加新的shard,或者各个shard上数据写入不均衡时,balancer就会自动来均衡数据。
(3)removeShard触发迁移
还有一种情况会触发迁移,当用户调用removeShard命令从集群里移除shard时,Balancer也会自动将这个shard负责的chunk迁移到其他节点,因removeShard过程比较复杂,这里先不做介绍,后续专门分析下removeShard的实现。
chunkSize对分裂及迁移的影响
MongoDB默认的chunkSize为64MB,如无特殊需求,建议保持默认值;chunkSize会直接影响到chunk分裂、迁移的行为。
- chunkSize越小,chunk分裂及迁移越多,数据分布越均衡;反之,chunkSize越大,chunk分裂及迁移会更少,但可能导致数据分布不均。
- chunkSize太小,容易出现jumbo chunk(即shardKey 的某个取值出现频率很高,这些文档只能放到一个chunk里,无法再分裂)而无法迁移;chunkSize越大,则可能出现chunk内文档数太多(chunk内文档数不能超过 250000)而无法迁移。
- chunk自动分裂只会在数据写入时触发,所以如果将chunkSize改小,系统需要一定的时间来将chunk分裂到指定的大小。
- chunk只会分裂,不会合并,所以即使将chunkSize改大,现有的chunk数量不会减少,但chunk大小会随着写入不断增长,直到达到目标大小。
如何减小分裂及迁移的影响?
MongoDB sharding运行过程中,自动的chunk分裂及迁移如果对服务产生了影响,可以考虑一下如下措施。
(1)预分片提前分裂
在使用shardCollection对集合进行分片时,如果使用hash分片,可以对集合进行「预分片」,直接创建出指定数量的chunk,并打散分布到后端的各个shard。
指定numInitialChunks参数在shardCollection指定初始化的分片数量,该值不能超过8192。
Optional. Specifies the number of chunks to create initially when sharding an empty collection with a hashed shard key. MongoDB will then create and balance chunks across the cluster. The numInitialChunks must be less than 8192 per shard. If the collection is not empty, numInitialChunks has no effect.如果使用range分片,因为shardKey的取值不确定,预分片意义不大,很容易出现部分chunk为空的情况,所以range分片只支持hash分片。
(2)合理配置balancer
MonogDB的balancer能支持非常灵活的配置策略来适应各种需求。
- Balancer能动态的开启、关闭
- Blancer能针对指定的集合来开启、关闭
- Balancer支持配置时间窗口,只在制定的时间段内进行迁移
参考资料
- Aliyun MongoDB sharding
- Manage Sharded Cluster Balancer
- shardCollection command
- Migration Thresholds
- shard tag
作者:张友东,花名林青,阿里云数据库组技术专家,主要关注分布式存储、NoSQL数据库等技术领域,目前主要参与MongoDB云数据库的研发,致力于让开发者用上最好的MongoDB云服务。