分布式系统的一致性协议之 Zookeeper一致性协议ZAB简述
zookeeper是使用ZAB协议作为数据一致性的算法,ZAB全称:原子消息广播协议。
ZAB可以说是在Paxos算法基础上进行了扩展改造:
1、ZAB协议设计了支持崩溃恢复,可以保证在Leader进程崩溃的时候重新选举出Leader并且保证数据的完整性
2、zookeeper使用单一主进程Leader用于处理客户端所有事物请求,写只能由Leader处理,写过程会阻塞读进程
3、采用ZAB协议将服务器状态以事务形式广播到所有follower上
4、由于事物间可能存在着依赖关系,ZAB协议保证Leader广播的变更序列被顺序的处理
ZAB分为恢复阶段和广播阶段,用于处理不同状态。
广播阶段
zookeeper在处理事务(写)时,采用优化的2PC协议(多数派):
在ZooKeeper中所有的事务请求都由一个主服务器也就是Leader来处理,其他服务器为Follower,Leader将客户端的事务请求转换为事务Proposal,并且将Proposal分发给集群中其他所有的Follower,然后Leader等待Follwer反馈,当有过半数(>=N/2+1) 的Follower反馈信息后,Leader将再次向集群内Follower广播Commit信息,Commit为将之前的Proposal提交。
崩溃恢复阶段
当Leader宕机时,先进入选举阶段,再进入恢复阶段:
选举是通过follower的ZXID选出的,最大的ZXID会认为是最新的,拥有最大ZXID的Follower会被选举为新Leader.
恢复包括discovery和sync两个场景,discovery是follower节点向准Leader发送上一周期(epoch)信息,与Leader互相校验epoch进度,确定后通过sync场景进行数据同步,由Leader发起同步指令,最终保持集群数据的一致性。
ZAB协议中存在着三种状态,每个节点都属于以下三种中的一种:
1、Looking:系统刚启动或Leader崩溃后正处于选举状态
2、Following:Follower节点所处的状态,Follower与Leader处于数据同步阶段时的状态
3、Leading:Leader节点所处的状态:当前集群中有一个Leader为主进程。
ZooKeeper启动时所有节点初始状态为Looking,这时集群会尝试选举出一个Leader节点,选举出的Leader节点切换为Leading状态;当节点发现集群中已经选举出Leader则该节点会切换到Following状态,然后和Leader节点保持同步;当Follower节点与Leader失去联系时Follower节点则会切换到Looking状态,开始新一轮选举;在ZooKeeper的整个生命周期中每个节点都会在Looking、Following、Leading状态间不断转换;
epoch是什么?
ZAB协议中使用ZXID作为事务编号,ZXID为64位数字,低32位为一个递增的计数器,每一个客户端的一个事务请求时Leader产生新的事务后该计数器都会加1,高32位为Leader周期epoch编号,当新选举出一个Leader节点时Leader会取出本地日志中最大事务Proposal的ZXID解析出对应的epoch把该值加1作为新的epoch,将低32位从0开始生成新的ZXID;ZAB使用epoch来区分不同的Leader周期;(zookeeper是以此来保证事务的顺序一致性)。
广播(Broadcast)流程
客户端提交事务请求时Leader节点为每一个请求生成一个事务Proposal,将其发送给集群中所有的Follower节点,收到过半Follower的反馈后开始对事务进行提交,ZAB协议使用了原子广播协议;在ZAB协议中只需要得到过半的Follower节点反馈Ack就可以对事务进行提交,这也导致了Leader几点崩溃后可能会出现数据不一致的情况,ZAB使用了崩溃恢复来处理数字不一致问题;消息广播使用了TCP协议进行通讯所有保证了接受和发送事务的顺序性。广播消息时Leader节点为每个事务Proposal分配一个全局递增的ZXID(事务ID),每个事务Proposal都按照ZXID顺序来处理;
zookeeper是如何选取主leader的?
当leader崩溃或者leader失去大多数的follower,这时zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
1、Zookeeper选主流程(basic paxos)
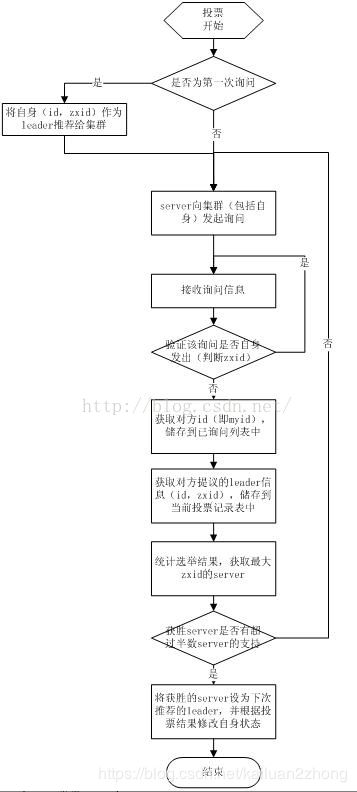
(1)选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
(2)选举线程首先向所有Server发起一次询问(包括自己);
(3)选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
(4)收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
(5)线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。 通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1. 每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。
2、Zookeeper选主流程(fast paxos)
fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和 zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。

Zookeeper同步流程
选完Leader以后,zk就进入状态同步过程。
1、Leader等待server连接;
2、Follower连接leader,将最大的zxid发送给leader;
3、Leader根据follower的zxid确定同步点;
4、完成同步后通知follower 已经成为uptodate状态;
5、Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。
zk节点宕机如何处理?
Zookeeper本身也是集群,推荐配置不少于3个服务器。Zookeeper自身也要保证当一个节点宕机时,其他节点会继续提供服务。
如果是一个Follower宕机,还有2台服务器提供访问,因为Zookeeper上的数据是有多个副本的,数据并不会丢失;
如果是一个Leader宕机,Zookeeper会选举出新的Leader。
ZK集群的机制是只要超过半数的节点正常,集群就能正常提供服务。只有在ZK节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。
所以:
3个节点的cluster可以挂掉1个节点(leader可以得到2票>1.5)
2个节点的cluster就不能挂掉任何1个节点了(leader可以得到1票<=1)
zookeeper负载均衡和nginx负载均衡区别
zk的负载均衡是可以调控,nginx只是能调权重,其他需要可控的都需要自己写插件;但是nginx的吞吐量比zk大很多,应该说按业务选择用哪种方式。
zookeeper watch机制
Watch机制官方声明:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
Zookeeper机制的特点:
1、一次性触发数据发生改变时,一个watcher event会被发送到client,但是client只会收到一次这样的信息。
2、watcher event异步发送watcher的通知事件从server发送到client是异步的,这就存在一个问题,不同的客户端和服务器之间通过socket进行通信,由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于Zookeeper本身提供了ordering guarantee,即客户端监听事件后,才会感知它所监视znode发生了变化。所以我们使用Zookeeper不能期望能够监控到节点每次的变化。Zookeeper只能保证最终的一致性,而无法保证强一致性。
3、数据监视Zookeeper有数据监视和子数据监视getdata() and exists()设置数据监视,getchildren()设置了子节点监视。
4、注册watcher getData、exists、getChildren
5、触发watcher create、delete、setData
6、setData()会触发znode上设置的data watch(如果set成功的话)。一个成功的create() 操作会触发被创建的znode上的数据watch,以及其父节点上的child watch。而一个成功的delete()操作将会同时触发一个znode的data watch和child watch(因为这样就没有子节点了),同时也会触发其父节点的child watch。
7、当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失。
8、Watch是轻量级的,其实就是本地JVM的Callback,服务器端只是存了是否有设置了Watcher的布尔类型。
Zookeeper数据复制
Zookeeper作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
1、容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
2、提高系统的扩展能力 :把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
3、提高性能:让客户端本地访问就近的节点,提高用户访问速度。
从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
1、写主(WriteMaster) :对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下客户端需要对读与写进行区别,俗称读写分离;
2、写任意(Write Any):对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角色与变化透明。
对zookeeper来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立observer的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
参考:
ZooKeeper之ZAB协议 - 推酷
https://www.tuicool.com/articles/IfQR3u3
Paxos-->Fast Paxos-->Zookeeper分析 - Kuzury - CSDN博客
https://blog.csdn.net/u010039929/article/details/70171672
zookeeper面试题 - 个人文章 - SegmentFault 思否
https://segmentfault.com/a/1190000014479433