Numpy入门
文章目录
- 1.NumPy数组
- 1.1 一维数组
- 1.2 二维数组
- 1.3 三维数组
- 1.4 四维及更高维
- 2.NumPy数组属性
- 2.1 NDArray结构图
- 2.2 NDArray属性总览
- 3.NumPy数组初始化
- 3.1设定数据类型
- 3.2 初始化由0或1填满的多维数组
- 3.3 使用linspace()生成等差数列
- 3.4 使用logspace生成等比数列
- 3.5 *arange功能(左闭右开)
- 4.数组的改变形状与维度
- 4.1 reshape
- 4.2 多维数组的快速遍历
- 5.逻辑运算
- 5.1常规逻辑运算
- 5.2 np.where(三元运算符)
- 6.数组的合并和分割
- 7. 数组的排序
- 8. NumPy数组的随机数
- 8.1 random.rand(d1,d2,d3...dn)
- 8.2 random.normal
- 8.3 random.randint(low , high ,(d1,d2,d3,...,dn) )
- 8.4 random.seed(n)
- 9.数组的统计
- 9.1 min(axis = 0/1)
- 9.2 max(axis = 0/1)
- 9.3 mean(axis=0/1)
- 9.4 sum(0/1)可以得到各列各行或者整个数组的总值
- 9.5 其他函数
- 10.数组的广播(broadcast)
- 10.1 m x n数组 与n x n 或m x m数组的运算
- 10.2 m x n数组与a x b的数组运算,a,b小于m,n
- 10.3 m x n数组与 n x m数组的运算
- 11.NumPy数组的科学计算
- 11.1数组与数组的运算
- 11.2数组与数的运算
- 11.3矩阵相乘
- 12.NumPy的引用与深复制
1.NumPy数组
NumPy是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list
structure)结构要高效的多。
NumPy(Numeric Python)提供了许多高级的数值编程工具。Numpy的一个重要特性是它的数组计算,是我们做数据分析必不可少的一个包。
导入python库使用关键字import,后面可以自定义库的简称,但是一般都将Numpy命名为np,pandas命名为pd。
1.1 一维数组
import numpy as np
# 通过Numpy创建数组并且命名为array
array = np.array([1,2,3,4])
print(array)
# 查看维数:数组名.ndim
print("Dimension is ",array.ndim)
[1 2 3 4]
Dimension is 1
1.2 二维数组
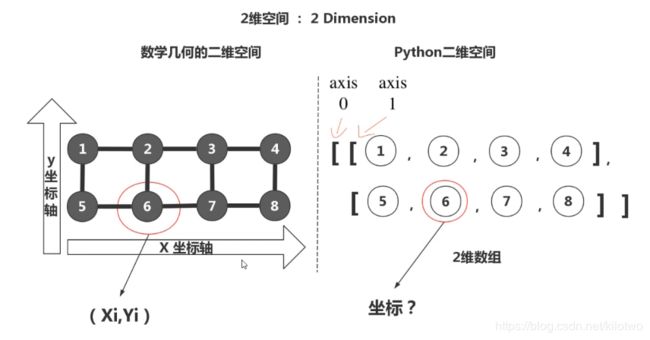
Numpy中的一维数组中包含多个单个元素,
而二维数组则包含很多一维数组中间用逗号隔开,再用方括号括起,
而三维数组则包含很多二维数组中间再用逗号隔开他们,用方括号括起,以此类推层层嵌套。
array2 = np.array([[1,2,3,4],
[2,3,4,5]] )
print(array2.ndim)
1.3 三维数组
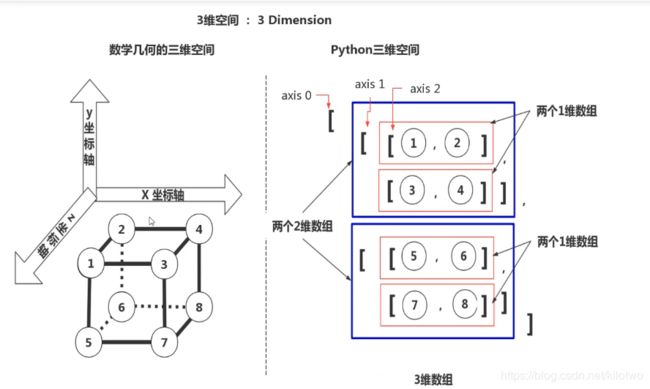
array3 = np.array([ [ [1,2],[3,4] ],
[ [5,6],[7,8] ] ] ) # 包含两个二维数组
print(array3.ndim)
1.4 四维及更高维
四维数组(4D array)可以理解为多个3D数组,放在一个新的数组中[[3D_array],[3D_array],[3D_array]]
更高维的以此类推
2.NumPy数组属性
2.1 NDArray结构图

2.2 NDArray属性总览

# 输出形状
array = np.array([[1,2,3,4],
[1,2,3,4],
[1,2,3,4]])
print(array.shape)
(3, 4)
# 输出维度
print(array.ndim)
2
# 输出数组大小
print(array.size)
12
# 输出每个元素大小
print(array.itemsize)
4
3.NumPy数组初始化
3.1设定数据类型
new_array = np.array([数组],dtype = np.int32/float/float16/float32)
#不指定数据类型
array11= np.array([1,2,3,4])
print(array11.dtype)
int32
#指定数据类型
array11= np.array([1,2,3,4],dtype=np.int64)
print(array11.dtype)
int64
当初始化时已经制定数据类型,如初始化时为整型,则后期赋值浮点型会自动转换成整型。
array11.fill(2.5)
array11
array([2, 2, 2, 2], dtype=int64)
可以使用astype转换数据类型
array11 = array11.astype('float')
array11.fill(2.5)
array11
array([2.5, 2.5, 2.5, 2.5])
3.2 初始化由0或1填满的多维数组
array_1 = np.zeros((3,3),dtype = np.int64)
array_1
array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]], dtype=int64)
## 2.初始化由1填满的多维数组
array_1 = np.ones((3,3),dtype = np.int64)
array_1
array([[1, 1, 1],
[1, 1, 1],
[1, 1, 1]], dtype=int64)
3.3 使用linspace()生成等差数列
np.linspace(起始值,终止值,个数)
line_array = np.linspace(0,10,10)
print(line_array)
[ 0. 1.11111111 2.22222222 3.33333333 4.44444444 5.55555556
6.66666667 7.77777778 8.88888889 10. ]
3.4 使用logspace生成等比数列
np.logspace(起始值,终止值,元素个数,endpoint = True,base = 10.0 , dtype =None)
默认情况下,起始值和结束值都是10的幂
默认True,10与float64
log_array = np.logspace(0,2,3,dtype=np.int64)
log_array
array([ 1, 10, 100], dtype=int64)
3.5 *arange功能(左闭右开)
arange是NumPy中使用较多的功能,在使用arange时,需要设置起始值,终止值,与步长,能够生成一个左闭右开的有序列表
np.arange(起始值,终止值,步长)
如下生成一个数组,从0开始,到20截止,中间步长为1
arrayOfarange = np.arange(0,20,5)
arrayOfarange
array([ 0, 5, 10, 15])
切片索引也是左闭右开
4.数组的改变形状与维度
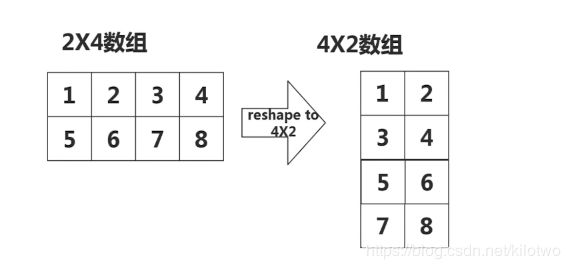
4.1 reshape
改变形状:
新数组 = 要改变的数组名.reshape((x,y),order = ‘C’)
-
order = C 为行优先
-
order = F 为列优先
re_array = np.ones((2,4),dtype=np.int64)
re_array
array([[1, 1, 1, 1],
[1, 1, 1, 1]], dtype=int64)
rep_array = re_array.reshape((4,2))
rep_array
re_array.shape
(2, 4)
rep_array
array([[1, 1],
[1, 1],
[1, 1],
[1, 1]], dtype=int64)
4.2 多维数组的快速遍历
array3 = np.array([ [ [1,2],[3,4] ],
[ [5,6],[7,8] ] ] ) # 包含两个二维数组
print(array3.ndim)
for n in array3.flat:
print(n)
3
1
2
3
4
5
6
7
8
5.逻辑运算
5.1常规逻辑运算
stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))
stock_change
array([[ 1.56755435, 1.51633518, 1.35391271, 0.41984581, 0.08355203,
-0.10978758, -0.1718201 , 0.13372917, 0.7765958 , 1.45259541],
[ 0.24472112, -0.00462843, 1.13946376, 0.78859057, -1.32903171,
-0.5893417 , 0.615821 , -1.68240751, -0.49376617, 1.23106709],
[-0.32672613, -1.29729904, 0.27913385, 0.77965684, -0.46751052,
0.24634306, -1.68133797, 0.25845272, 0.83956537, -1.11231473],
[ 1.95620293, -1.2113412 , 1.73172836, 0.68146402, 1.57395519,
-1.32142387, 1.11239472, 1.60146494, 0.97923844, -0.00871739],
[-0.67554891, 0.19734193, 0.13317942, 1.99546366, 0.08060337,
-1.0668129 , 0.47089379, 0.16065532, -0.6997608 , -0.83662309],
[ 1.63479698, 0.00974187, -0.38133478, -0.62319296, 0.88710292,
-0.55449674, 1.36123836, -0.59970827, -1.34812108, 0.51935608],
[-0.50858814, 0.28142075, 1.11593424, -1.85560872, 0.59084758,
0.44920587, -1.27364014, -0.73616598, 3.08182332, -0.91862632],
[-0.73433662, -0.95873172, 0.51115305, 0.1674397 , 0.20340613,
1.44133033, 0.48118756, 0.885181 , 0.12022261, 0.59991483]])
# 逻辑判断, 如果涨跌幅大于0.5就标记为True 否则为False
stock_change > 0.5
array([[ True, True, True, False, False, False, False, False, True,
True],
[False, False, True, True, False, False, True, False, False,
True],
[False, False, False, True, False, False, False, False, True,
False],
[ True, False, True, True, True, False, True, True, True,
False],
[False, False, False, True, False, False, False, False, False,
False],
[ True, False, False, False, True, False, True, False, False,
True],
[False, False, True, False, True, False, False, False, True,
False],
[False, False, True, False, False, True, False, True, False,
True]])
stock_change[stock_change > 0.5] = 1.1
stock_change
array([[ 1.1 , 1.1 , 1.1 , 0.41984581, 0.08355203,
-0.10978758, -0.1718201 , 0.13372917, 1.1 , 1.1 ],
[ 0.24472112, -0.00462843, 1.1 , 1.1 , -1.32903171,
-0.5893417 , 1.1 , -1.68240751, -0.49376617, 1.1 ],
[-0.32672613, -1.29729904, 0.27913385, 1.1 , -0.46751052,
0.24634306, -1.68133797, 0.25845272, 1.1 , -1.11231473],
[ 1.1 , -1.2113412 , 1.1 , 1.1 , 1.1 ,
-1.32142387, 1.1 , 1.1 , 1.1 , -0.00871739],
[-0.67554891, 0.19734193, 0.13317942, 1.1 , 0.08060337,
-1.0668129 , 0.47089379, 0.16065532, -0.6997608 , -0.83662309],
[ 1.1 , 0.00974187, -0.38133478, -0.62319296, 1.1 ,
-0.55449674, 1.1 , -0.59970827, -1.34812108, 1.1 ],
[-0.50858814, 0.28142075, 1.1 , -1.85560872, 1.1 ,
0.44920587, -1.27364014, -0.73616598, 1.1 , -0.91862632],
[-0.73433662, -0.95873172, 1.1 , 0.1674397 , 0.20340613,
1.1 , 0.48118756, 1.1 , 0.12022261, 1.1 ]])
# 判断第一天stock_change[0:2, 0:5]是否全是上涨的
stock_change[0:2, 0:5] > 0
array([[ True, True, True, True, True],
[ True, False, True, True, False]])
np.all(stock_change[0:2, 0:5] > 0)
False
# 判断前5只股票这段期间是否有上涨的
np.any(stock_change[:5, :] > 0)
True
5.2 np.where(三元运算符)
# 判断前四个股票前四天的涨跌幅 大于0的置为1,否则为0
temp = stock_change[:4, :4]
temp
array([[ 1.1 , 1.1 , 1.1 , 0.41984581],
[ 0.24472112, -0.00462843, 1.1 , 1.1 ],
[-0.32672613, -1.29729904, 0.27913385, 1.1 ],
[ 1.1 , -1.2113412 , 1.1 , 1.1 ]])
np.where(temp > 0, 1, 0) # 返回一个新数组
array([[1, 1, 1, 1],
[1, 0, 1, 1],
[0, 0, 1, 1],
[1, 0, 1, 1]])
# 判断前四个股票前四天的涨跌幅 大于0.5并且小于1的,换为1,否则为0
# 判断前四个股票前四天的涨跌幅 大于0.5或者小于-0.5的,换为1,否则为0
# (temp > 0.5) and (temp < 1)
np.logical_and(temp > 0.5, temp < 1)
array([[False, False, False, False],
[False, False, False, False],
[False, False, False, False],
[False, False, False, False]])
np.where(np.logical_and(temp > 0.5, temp < 1),1,0)
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]])
np.where(np.logical_or(temp > 0.5, temp < -0.5), 11, 3)
array([[11, 11, 11, 3],
[ 3, 3, 11, 11],
[ 3, 11, 3, 11],
[11, 11, 11, 11]])
6.数组的合并和分割
num_1 = np.arange(1,9,1).reshape(2,4)
num_1
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
num_2 = np.arange(9,17,1).reshape(2,4)
num_2
array([[ 9, 10, 11, 12],
[13, 14, 15, 16]])
# 垂直方向合并
ver_array = np.vstack((num_1,num_2))
ver_array
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
#水平方向合并
hor_array = np.hstack((num_1,num_2))
hor_array
array([[ 1, 2, 3, 4, 9, 10, 11, 12],
[ 5, 6, 7, 8, 13, 14, 15, 16]])
# 水平分割
horsplit_array =np.hsplit(hor_array,2)
horsplit_array
[array([[1, 2, 3, 4],
[5, 6, 7, 8]]), array([[ 9, 10, 11, 12],
[13, 14, 15, 16]])]
horsplit_array[0]
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
# 垂直分割
versp_array = np.vsplit(ver_array,2)
versp_array
[array([[1, 2, 3, 4],
[5, 6, 7, 8]]), array([[ 9, 10, 11, 12],
[13, 14, 15, 16]])]
7. 数组的排序
参数:
- array:数组
- axis:轴
- kind:算法 默认为快速排序 另有选择排序和堆排序
- order:可以设置按照某个属性排序
a = np.sort([54,34,123,12,5,675])
a
array([ 5, 12, 34, 54, 123, 675])
8. NumPy数组的随机数
8.1 random.rand(d1,d2,d3…dn)
生成[0,1)分布均匀的浮点数,括号内参数设定维度
random = np.random.rand()
random
0.9574730047126411
# 二维随机数
random2 = np.random.rand(2,2)
random2
array([[0.45037993, 0.42111107],
[0.17791289, 0.54974932]])
8.2 random.normal
生成正态分布随机数
# 正态分布
data2 = np.random.normal(loc=1.75, scale=0.1, size=1000000)
data2
array([1.52524365, 1.77203004, 1.83555655, ..., 1.67529443, 1.64605781,
1.7188181 ])
import matplotlib.pyplot as plt
plt.figure()
plt.hist(data2,1000)
plt.show()
8.3 random.randint(low , high ,(d1,d2,d3,…,dn) )
如果参数是10,size = 10 意味着随机数值的区间在[0,10),数组是一维数组,有10个元素
a1 = np.random.randint(10,size =10)
print(a1)
[3 2 0 7 5 4 1 2 8 2]
如果参数是5和10,size = 10 意味着随机数值的区间在[5,10),数组是一维数组,有10个元素
a2 = np.random.randint(5,10,size =10)
print(a2)
[9 8 6 5 9 8 7 5 8 8]
8.4 random.seed(n)
设定一个种子,种子相同生成随机数相同
np.random.seed(10)
print(np.random.random(10))
[0.77132064 0.02075195 0.63364823 0.74880388 0.49850701 0.22479665
0.19806286 0.76053071 0.16911084 0.08833981]
np.random.seed(1)
print(np.random.random(10))
[4.17022005e-01 7.20324493e-01 1.14374817e-04 3.02332573e-01
1.46755891e-01 9.23385948e-02 1.86260211e-01 3.45560727e-01
3.96767474e-01 5.38816734e-01]
9.数组的统计
9.1 min(axis = 0/1)
可以分别得到各列各行的最小值如果不设置,则得到整个数组最小值
print(np.min(a1))
0
a3 = np.random.rand(4,4)
a3
array([[0.02738759, 0.67046751, 0.4173048 , 0.55868983],
[0.14038694, 0.19810149, 0.80074457, 0.96826158],
[0.31342418, 0.69232262, 0.87638915, 0.89460666],
[0.08504421, 0.03905478, 0.16983042, 0.8781425 ]])
# 0是各列最小值
np.min(a3,0)
array([0.02738759, 0.03905478, 0.16983042, 0.55868983])
# 1是各行最小值
np.min(a3,1)
array([0.02738759, 0.14038694, 0.31342418, 0.03905478])
9.2 max(axis = 0/1)
可以分别得到各列各行的最大值,如果不设置,则得到整个数组最大值
9.3 mean(axis=0/1)
可以分别得到各列各行的均值,如果不设置,则得到整个数组的均值
np.mean(a3)
0.4831349270930837
np.mean(a3,0)
array([0.14156073, 0.3999866 , 0.56606724, 0.82492514])
9.4 sum(0/1)可以得到各列各行或者整个数组的总值
用法同上
9.5 其他函数
- abs绝对值
- exp求指数
- median中位数
- cumsum累计值
- 其他内置函数总结
https://blog.csdn.net/nihaoxiaocui/article/details/51992860#commentBox
10.数组的广播(broadcast)
当两个不同形状的数组进行运算时会发出广播机制
10.1 m x n数组 与n x n 或m x m数组的运算
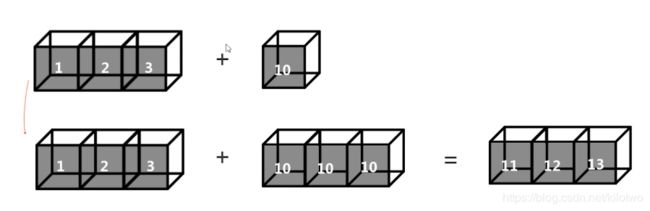
a1 = np.array([1,2,3])
a2 = np.array([10])
a1+a2
array([11, 12, 13])
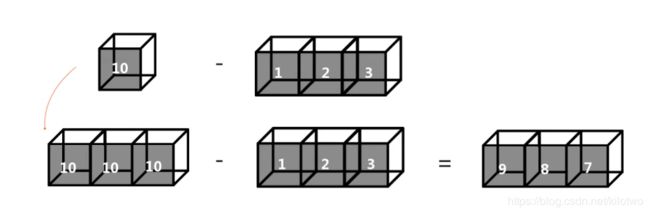
a3 = np.array([10])
a4 = np.array([1,2,3])
a3-a4
array([9, 8, 7])
10.2 m x n数组与a x b的数组运算,a,b小于m,n
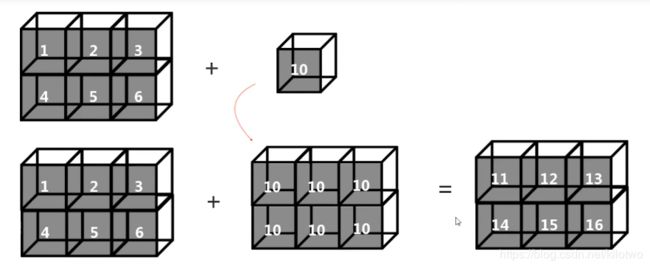
a5 = np.array([[1,2,3],[4,5,6]])
a6 = np.array([10])
a5+a6
array([[11, 12, 13],
[14, 15, 16]])
10.3 m x n数组与 n x m数组的运算
生成一个2x1的数组和1x3数组,行以行最多的扩展,列以列最多的扩展

a_21 = np.array([[10],[10]])
a_12 = np.array([1,2])
a_21 + a_12
array([[11, 12],
[11, 12]])
11.NumPy数组的科学计算

11.1数组与数组的运算
sum_array1 = np.arange(10).reshape(2,5)
sum_array1
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
sum_array2 = np.arange(11,21).reshape(2,5)
sum_array2
array([[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]])
sum_array1+sum_array2
array([[11, 13, 15, 17, 19],
[21, 23, 25, 27, 29]])
11.2数组与数的运算
sum_array1 +1
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10]])
11.3矩阵相乘
m x n 与 n x L
sum_array3 = sum_array2.reshape(5,2)
sum_array3
array([[11, 12],
[13, 14],
[15, 16],
[17, 18],
[19, 20]])
# 两种点乘方法
sum_array1.dot(sum_array3)
np.dot(sum_array1,sum_array3)
12.NumPy的引用与深复制
首先使用arange生成有序数列
num1 = np.arange(10)
num1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
此时实用b来引用num1数组
b = num1
b
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
当改变b中元素时,发现复制的原数组也会改变
b[1] = 666
print(b is num1)
num1
输出True说明引用的b就是原数组num1
True
array([ 0, 666, 2, 3, 4, 5, 6, 7, 8, 9])
此时使用深复制copy
# c = np.copy(num1)
c = num1.copy()
c
array([ 0, 666, 2, 3, 4, 5, 6, 7, 8, 9])
深拷贝为重新创建不会改变原来数组
# 深拷贝为重新创建不会改变原来数组
c[2:5]=777
print(c is num1)
print(c)
num1
输出False也说明c已经是新的数组不再是简单的引用,不是num1原数组了
False
[ 0 666 777 777 777 5 6 7 8 9]
array([ 0, 666, 2, 3, 4, 5, 6, 7, 8, 9])