Camera直播视频数据的获取,及RTMP推流(一)
通过摄像头直播推流的场景中,需要先从摄像头获取去视频元数据,然后交给x264编码器(加入用的视频编码器是x264)编码,最后经RTMP封包后发送给服务器.
我们使用CameraX来获取摄像头数据,对于CameraX的使用,参考官方文档:
https://developer.android.google.cn/training/camerax
CameraX 是一个 Jetpack 支持库,旨在帮助您简化相机应用的开发工作。它提供一致且易于使用的 API 界面,适用于大多数 Android 设备,并可向后兼容至 Android 5.0(API 级别 21).
CameraX 引入了多个用例,
预览:在显示屏上显示图片
图片分析:无缝访问缓冲区以便在算法中使用,
图片拍摄:保存优质图片
一,
在直播这个应用中,主要关注的图片分析.简单列出CameraX使用的代码:
布局文件中使用TextureView显示预览效果:
在MainActivity中使用
CameraX.bindToLifecycle((LifecycleOwner) this, getPreview(), getAnalysis());
//Analysis和Priview中设置的分辨率可以不同,这说明分析图片和预览图片是可以分开应用的。
private ImageAnalysis getAnalysis() {
ImageAnalysisConfig analysisConfig = new ImageAnalysisConfig.Builder()
.setCallbackHandler(new Handler(handlerThread.getLooper()))
.setLensFacing(CameraX.LensFacing.BACK)
.setImageReaderMode(ImageAnalysis.ImageReaderMode.ACQUIRE_LATEST_IMAGE)
.setTargetResolution(new Size(480, 640))
.build();
ImageAnalysis imageAnalysis = new ImageAnalysis(analysisConfig);
imageAnalysis.setAnalyzer(this);
return imageAnalysis;
}
private Preview getPreview() {
//这里给出的分辨率,并不是最终的值,CameraX会根据设备的支持情况,设置一个最接近你给定参数的值。
PreviewConfig previewConfig= new PreviewConfig.Builder().
setTargetResolution(new Size(480, 640)).
setLensFacing(CameraX.LensFacing.BACK).build();
Preview preview = new Preview(previewConfig);
preview.setOnPreviewOutputUpdateListener(this);
return preview;
}二,粗略看下预览的实现,
这个纹理,就是摄像头采集到的一张图片,把这个纹理设置到TextureView,就可以预览出图像 ,SurfaceTexture对数据流的处理,并不是直接显示,而是转为GL的外部纹理, 因此可用于图像数据的二次处理(滤镜,美颜), Camera的预览数据,一种情况,可以变成纹理后交给GLSurfaceView直接显示,还有一种情况, 预览数据通过SurfaceTexture交给TextureView作为View Heirachy的一个硬件加速层来显示, CamerX的预览就是后一种情况.
TextureView可以把内容流直接投影到View中。 SurfaceTexture从图像流(Camera预览,视频解码,GL绘制)中获得帧数据,当调用UpdateTexImage时, 根据内容流最近的图像更新SurfaceTexture对应的纹理对象,然后就可以向操作普通纹理一样去操作它了。 TextureView不会在WMS中创建单独的窗口,而且必须在硬件加速窗口中,在它的draw方法中, 把SurfaceTexture中收到的图像数据作为纹理更新到对应的Hardwarelayer中。
SurfaceTexture,TextureView的详细介绍:https://www.cnblogs.com/wytiger/p/5693569.html
@Override
public void onUpdated(Preview.PreviewOutput output) {
SurfaceTexture surfaceTexture = output.getSurfaceTexture();
if (mTextureView.getSurfaceTexture() != surfaceTexture) {
if (mTextureView.isAvailable()) {
//这里的处理,避免切换摄像头时出错。
ViewGroup parent = (ViewGroup) mTextureView.getParent();
parent.removeView(mTextureView);
parent.addView(mTextureView, 0);
parent.requestLayout();
}
mTextureView.setSurfaceTexture(surfaceTexture);
}
}三,图像分析,
x264编码器需要的数据格式是I420, 通过Camera进行直播的过程,首先,从Camera获取数据,这个数据就是一个byte数组,然后把byte数据送去编码, 编码之后,按照rtmp的格式进行封包,把封包后的数据通过socket发送出去。 这里借助CameraX来获取图像数据,通过CameraX的图像分析接口得到的数据是ImageProxy, 通过ImageProxy可以得到我们想要的图像的byte数组。因为CameraX生成是YUV420-888的格式的图片,所以我们得 到的图像数据格式就是YUV格式的。我们要从YUV_420_888数据中提取出byte数组,交给x264去编码。
//这里可以得到图片的数据,宽高,格式,时间戳等,及旋转角度。
@Override
public void analyze(ImageProxy imageProxy, int rotationDegrees) {
Image image = imageProxy.getImage();
//这个数组的第0个元素保存的是Y数据,data[0].getBuffer();
//这个数组的第1个元素保存的是U数据,
//这个数组的第2个元素保存的是V数据,
//Image.Plane[] data = image.getPlanes();
byte[] dataI420 = ImageUtils.getBytes(imageProxy, rotationDegrees, mWidth, mHeight);
}从YUV420-888中提取byte[]数组.
YUV420这类格式的图像,4个Y分量共用一组UV分量,根据颜色数据的存储顺序不同,又分了几种不同格式,这些格式实际存储的信息是一样的,如:4*4的图片,在YUV420下,任何格式都是16个Y值,4个U值,4个V值,区别只是Y,U,V的排列顺序不同.YUV420是一类颜色格式的集合,并不能完全确定颜色数据的存储顺序.
CameraX的应用中,YUV三个分量的数据分别保存在imageProxy.getPlanes()对应的数组中.
YUV420中,Y数据长度为: width*height , 而U、V都为:width / 2 * height / 2。
planes[0]一定是Y,planes[1]一定是U,planes[2]一定是V。且对于plane [0],Y分量数据一定是连续存储的,中间不会有U或V数据穿插,也就是说一定能够一次性得到所有Y分量的值.
但是对于UV数据,可能存在以下两种情况:
1. planes[1] = {UUUU...},planes[2] = {VVVV...};
2. planes[1] = {UVUV...},planes[2] = {VUVU...}。
具体UV的排列顺序是那种情况,需要根据int pixelStride = plane.getPixelStride();来判断:
pixelStride 为1:表示无间隔取值,即为上面的第一种情况
pixelStride 为 2: 表示需要间隔一个数据取值,即为上面的第二种情况
但是,考虑到Camera有不同的分辨率,所以在YUV数据存储时有字节对齐的想象,就要考虑占位符的问题. 因为涉及补位的问题,要去考虑行步长planes[0].getRowStride()。 当Camera的分辨率不同时,补位数据的长度就会不一样,planes[0].getRowStride()行步长也就会不一样。
首先分析Y数据, RowStride表示行步长,Y数据对应的行步长可能为:
1. 等于 imageProxy.getWidth() ;
2. 大于imageProxy.getWidth() ;
以4x4的I420为例,其数据可以看为:
rowStride等于width的情况,直接通过 planes[0].getBuffer() 获得Y数据没有问题
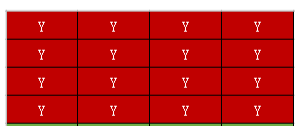
rowStride大于width的情况,此时读取数据时就要跳过尾部的占位符,不然可能会报指针越界异常.
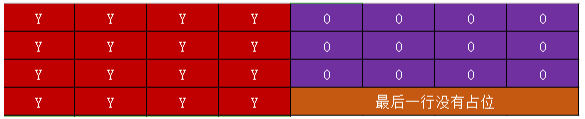
然后看UV数据,对于U与V数据,对应的行步长可能为:
1. 等于Width;
2. 大于Width;
3. 等于Width/2;
4. 大于Width/2
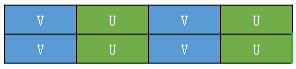
在RowStride等于width时,并且pixelStride==2,表示UV交叉存放,如图planes[1],此时在获取U数据时,只获取偶数位置的数据,奇数位置的数据丢弃.只从planes[1]中取U数据,

同理,我们只从planes[2]中取V数据,获取偶数位置的数据,奇数位置的数据丢弃.
当RowStride大于width时,planes[1],同样要跳过尾部的占位符,注意最后一行没有占位符,不需要跳过.

当RowStride大于width时,planes[2],同样要跳过尾部的占位符,注意最后一行没有占位符,不需要跳过.

当RowStride等于Width/2,就是pixelStride==1,表示UV没有交叉存放,都是单独存放的,如:planes[1]

当RowStride等于Width/2,就是pixelStride==1,表示UV没有交叉存放,都是单独存放的,如planes[2]
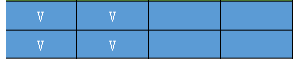
当RowStride大于Width/2,就是pixelStride==1,表示UV没有交叉存放,都是单独存放的,但是有占位符,此时,需要跳过占位符,如planes[1]

当RowStride大于Width/2,就是pixelStride==1,表示UV没有交叉存放,都是单独存放的,但是有占位符,此时,需要跳过占位符,,如planes[2]

有了上面的分析,再看代码实现,相信就不难理解了:
下面的函数是从ImageProxy中提取I420字节数组:
public static byte[] getBytes(ImageProxy imageProxy, int rotationDegrees, int mWidth, int mHeight) {
//获取图像格式
int format = imageProxy.getFormat();
//根据CameraX的官方文档,CameraX返回的数据格式:YUV_420_888
if (format != ImageFormat.YUV_420_888) {
//异常处理,如果有厂商修改了CameraX返回的数据格式。
}
//I420的数据格式,4个Y共用一组UV,其中Y数据的大小是width * height,
// U V数据的大小都是 (width/2) * (height/2)
//这个数组的第0个元素保存的是Y数据,data[0].getBuffer(); Y分量数据时连续存储的,
//这个数组的第1个元素保存的是U数据,U V分量可能出现交叉存储,
//这个数组的第2个元素保存的是V数据,
//如果按照上面的方式,简单的获取到Y U V分量的字节数组,然后拼接到一起,在多数情况下可能是正常的,
// 但是不能兼容多种camera分辨率,因为涉及补位的问题,要去考虑行步长planes[0].getRowStride()。
// 当Camera的分辨率不同时,补位数据的长度就会不一样,planes[0].getRowStride()行步长也就会不一样。
ImageProxy.PlaneProxy[] planes = imageProxy.getPlanes();
//一个YUV420数据,需要的字节大小,
int size = imageProxy.getWidth() * imageProxy.getHeight() * 3/ 2;
if (null == yuvI420 || yuvI420.capacity() < size) {
yuvI420 = ByteBuffer.allocate(size);
}
yuvI420.position(0);
//获取Y数据,getPixelStride 在Y分量下,总是1,表示Y数据时连续存放的。
int pixelStride = planes[0].getPixelStride();
ByteBuffer yBuffer = planes[0].getBuffer();
//行步长,表示一行的最大宽度,可能等于imageProxy.getWidth(),
// 也可能大于imageProxy.getWidth(),比如有补位的情况。
int rowStride = planes[0].getRowStride();
//这个字节数组表示,在读取Y分量数据时,跳过补位的部分,因为这些补位的部分没有实际数据,只是为了字节对齐,
// 如果没有补位 rowStride 等于 imageProxy.getWidth(),这就是一个空数组,否则,数组的长度就刚好是要跳过的长度。
byte[] skipRow = new byte[rowStride - imageProxy.getWidth()];
//这个数组,表示了这一行真实有效的数据。
byte[] row = new byte[imageProxy.getWidth()];
//循环读取每一行
for (int i = 0; i < imageProxy.getHeight(); i++) {
yBuffer.get(row);
//每一行有效的数据拼接起来就是Y数据。
yuvI420.put(row);
//因为最后一行,没有无效的补位数据,不需要跳过,不是最后一行,才需要跳过无效的占位数据。
if (i < imageProxy.getHeight() - 1) {
yBuffer.get(skipRow);
}
}
// 获取U V数据
// Y分量数据时连续存储的,U V分量可能出现交叉存储,
pixelStride = planes[1].getPixelStride();
// 如果pixelStride值为1,表示UV是分别存储的,planes[1] ={UUUU},planes[2]={VVVV},
// 这个情况还是比较容易获取的,
// 如果pixelStride 为2,表示UV是交叉存储的,planes[1] ={UVUV},planes[2]={VUVU},
// 这个情况,要获取UV,就要拿一个,丢一个,交替取出,同时,也需要考虑跳过无效的补位数据。
for (int i =0; i< 3; i++) {
ImageProxy.PlaneProxy planeProxy = planes[i];
int uvPixelStride = planeProxy.getPixelStride();
//如果U V是交错存放,行步长就等于imageProxy.getWidth(),同时要考虑有占位数据,会大于imageProxy.getWidth()
// 如果U V是分离存放,行步长就等于imageProxy.getWidth() /2,同时要考虑有占位数据,会大于imageProxy.getWidth()/2
int uvRowStride = planeProxy.getRowStride();
ByteBuffer uvBuffer = planeProxy.getBuffer();
//一行一行的处理,uvWidth表示了有效数据的长度。
int uvWidth = imageProxy.getWidth() / 2;
int uvHeight = imageProxy.getHeight() / 2;
for (int j = 0; j< uvHeight; j++) {
//每次处理一行中的一个字节。
for (int k =0; k < uvRowStride; k++) {
//跳过最后一行没有占位的数据,
if (j == uvHeight -1) {
//UV没有混合在一起,
if (uvPixelStride == 1) {
//大于有效数据后,跳出内层循环(k < uvRowStride),不用关心最后的占位数据了。
// 因为最后一行没有占位数据。
if (k >= uvWidth) {
break;
}
} else if (uvPixelStride == 2) {
//UV没有混合在一起,大于有效数据后,跳出内层循环(k < uvRowStride),
// 不用关心最后的占位数据了。
// 因为最后一行没有占位数据。注意这里的有效数据的宽度是imageProxy.getWidth()。
//这里为什么要减1呢?因为在UV混合模式下,常规情况是UVUV,但是可能存在UVU的情况,
// 就是最后的V是没有的,如果不在这里 减1,在接下来get时,会报越界异常。
if (k >= imageProxy.getWidth() -1) {
break;
}
}
}
//对每一个字节,分别取出U数据,V数据。
byte bt =uvBuffer.get();
//uvPixelStride == 1表示U V没有混合在一起
if (uvPixelStride == 1) {
//k < uvWidth表示是在有效范围内的字节。
if (k < uvWidth) {
yuvI420.put(bt);
}
} else if (uvPixelStride == 2) {
//uvPixelStride == 2 表示U V混合在一起。只取偶数位小标的数据,才是U / V数据,
// 奇数位,占位符数据都丢弃,同时这里的有效数据长度是imageProxy.getWidth(),
// 而不是imageProxy.getWidth() /2,
if (k < imageProxy.getWidth() && (k % 2 == 0)){
yuvI420.put(bt);
}
}
}
}
}
//全部读取到YUV数据,以I420格式存储的字节数组。
byte[] result = yuvI420.array();
//Camera 角度的旋转处理。分别以顺时针旋转Y, U ,V。
if (rotationDegrees == 90 || rotationDegrees == 270) {
result = rotation(result, imageProxy.getWidth(), imageProxy.getHeight(), rotationDegrees);
}
return result;
}
在获取到摄像头数据的byte数组后,还要考虑角度旋转,借助libyuv实现角度的顺时针旋转
extern "C"
JNIEXPORT jbyteArray JNICALL
Java_com_test_cameraxlive_ImageUtils_rotation(JNIEnv *env, jclass clazz, jbyteArray data_,
jint width, jint height, jint degree) {
jbyte *data = env->GetByteArrayElements(data_, 0);
uint8_t *src = reinterpret_cast(data);
int ySize = width * height;
int uSize = (width >>1) * (height >>1);
//Y U V总的数据大小
int size = (ySize * 3) >> 1;
uint8_t dst[size];
//原始数据的Y数据,U数据,V数据
uint8_t *src_y = src;
uint8_t *src_u = src + ySize;
uint8_t *src_v = src + ySize + uSize;
//旋转后的Y数据,U数据,V数据。
uint8_t *dst_y = dst;
uint8_t *dst_u = dst + ySize;
uint8_t *dst_v = dst +ySize + uSize;
libyuv::I420Rotate(src_y, width,
src_u, width>>1,
src_v, width>>1,
dst_y, height,
dst_u, height>>1,
dst_v, height>>1,
width, height, static_cast(degree));
jbyteArray result = env->NewByteArray(size);
env->SetByteArrayRegion(result, 0, size, reinterpret_cast(dst));
env->ReleaseByteArrayElements(data_, data, 0);
return result;
} 到这里,就完成了摄像头数据的byte[]数组的提取.
接下来通过x264库完成编码:
H264的基础知识,参考:https://blog.csdn.net/qq_29350001/article/details/78226286
使用X264编码的流程:
1,设置 x264_param_t编码器参数,通过 x264_encoder_open 创建一个 x264_t *codec编码器
2,通过 x264_picture_alloc为编码器的输入数据 x264_picture_t pic_in 申请内存,
3,通过 x264_encoder_encode完成编码,
创建编码器的代码:
void VideoChannel::openCodec(int width, int height, int fps, int bitrate) {
//编码器的参数,以延迟最低为目标配置。
x264_param_t param;
//第二,三个参数来自这两个数组:x264_preset_names[],x264_tune_names[] ,表示编码速度,和质量控制,
// zerolatency,无延迟编码,主要用于实时通讯
x264_param_default_preset(¶m, "ultrafast", "zerolatency");
//指定编码规格,base_line 3.2 ,无B帧(双向参考帧),数据量小,但是解码速度慢。
param.i_level_idc = 32;
//输入数据格式
param.i_csp = X264_CSP_I420;
//宽高,
param.i_width = width;
param.i_height = height;
//指定无B帧
param.i_bframe = 0;
//表示码率控制,CQP(恒定质量),CRF(恒定码率),ABR(平均码率)
param.rc.i_rc_method = X264_RC_ABR;
//码率,单位kbps,
param.rc.i_bitrate = bitrate / 1000;
//最大码率,
param.rc.i_vbv_max_bitrate = (bitrate / 1000) * 1.2;
//帧率
param.i_fps_num = fps;
param.i_fps_den = 1;
//打开log输出,查看编码过程的日志,这里是指定日志的回调。
//param.pf_log = x264_log_default2;
//关键帧间隔,
param.i_keyint_max = fps * 2;
//是否复制sps和pps放在每个关键帧的前面 该参数设置是让每个关键帧(I帧)都附带sps/pps。
param.b_repeat_headers = 1;
//不使用并行编码。zerolatency场景下设置param.rc.i_lookahead=0;
// 那么编码器来一帧编码一帧,无并行、无延时
param.i_threads = 1;
param.rc.i_lookahead = 0;
x264_param_apply_profile(¶m, "baseline");
codec = x264_encoder_open(¶m);
ySize = width * height;
uSize = (width >> 1) * (height >> 1);
this->width = width;
this->height = height;
}编码数据的实现:
void VideoChannel::encode(uint8_t *data) {
//要编码的输入数据
x264_picture_t pic_in;
//为输入数据,申请内存,指定格式,宽高,
x264_picture_alloc(&pic_in, X264_CSP_I420, width, height);
//把I420数据中YUV塞到pic_in结构体中
pic_in.img.plane[0] = data;
pic_in.img.plane[1] = data + ySize;
pic_in.img.plane[2] = data + ySize + uSize;
//这个pts每次编码时需要增加,编码器把它当做图像的序号。
pic_in.i_pts = i_pts++;
//也可以从pic_out中拿到编码后的数据,我们这里是从pp_nal中获取。
x264_picture_t pic_out;
//二级指针,保存编码后的数据
x264_nal_t *pp_nal;
//编码后的数组有几个元素
int pi_nal;
int error = x264_encoder_encode(codec, &pp_nal, &pi_nal, &pic_in, &pic_out);
if (error <=0) {
return;
}
int spslen;
int ppslen;
uint8_t *sps;
uint8_t *pps;
//拿到编码后的数据
for (int i = 0; i < pi_nal; ++i) {
//开始码之后的第一个字节的低5位,表示了NAL的类型,7(sps)或者 8(pps),
int type = pp_nal[i].i_type;
//对应帧的数据,
uint8_t *p_payload = pp_nal[i].p_payload;
//对应帧数据的长度,其中SPS,PPS不属于帧的范畴。
int i_payload = pp_nal[i].i_payload;
if (type == NAL_SPS) {
//得到SPS,不能直接发送出去,而是要等到跟PPS,组成一个RTMP_packet一起发送给服务器,
// 所以这里先把sps保存下来
//H264的数据中,每个NAL之间是由00 00 00 01或者 00 00 01来分割,在00 00 00 01后面跟着就是
// 这一帧的类型,
spslen = i_payload - 4; //去掉间隔 00 00 00 01
sps = (uint8_t *)alloca(spslen);//在栈上申请内存,不用手动释放。
memcpy(sps, p_payload +4, spslen);
} else if (type == NAL_PPS) {
ppslen = i_payload -4;//去掉间隔 00 00 00 01
pps = (uint8_t *) alloca(ppslen);//在栈上申请内存,不用手动释放。
memcpy(pps, p_payload +4, ppslen);
//sps,pps后面接着肯定是I帧,所以在发送I帧之前,先把sps,pps发送出去。
sendVideoConfig(sps, pps, spslen, ppslen);
} else {
//发送正常的数据帧,包括关键帧,普通帧。
sendFrame(type, p_payload, i_payload);
}
}
}编码完成后,通过RTMP发送到服务器,除了正常的数据帧,还有AVC序列头信息。
对RTMP视频的封包,参考flv的格式文档:

对视频数据封包,只需关注数据区部分,前面的11个字节,不用考虑。
视频数据部分,分关键帧,非关键帧,
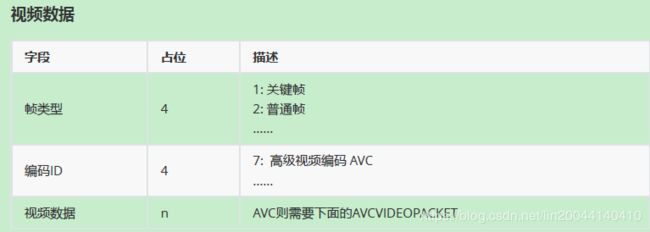
视频数据中0x17:其中 1表示关键帧,7 表示 高级视频编码AVC,对于普通帧则是0x27。
AVCVIDEOPACKET的格式定义:

如果类型是0,表示接下来这一段数据时AVC序列头,如果是0,表示接下来一段数据是视频帧(关键帧,非关键帧都是0)。
AVC序列头格式定义:
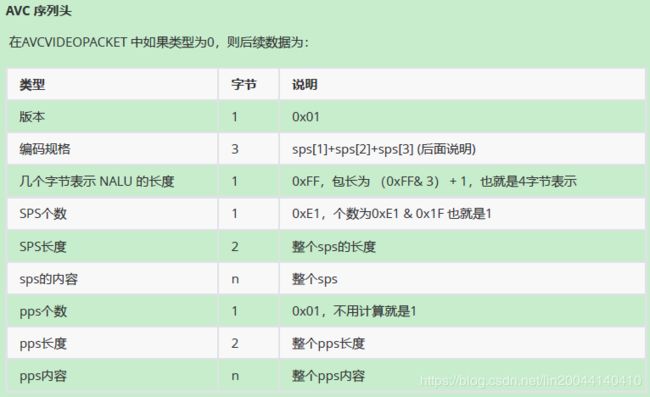
SPS,PPS是在编码H264视频数据时,放在关键帧前面的信息,指导解码器如何参考这个关键帧解码出B帧,P帧的内容。
通常情况,RTMP封包的视频结构体:
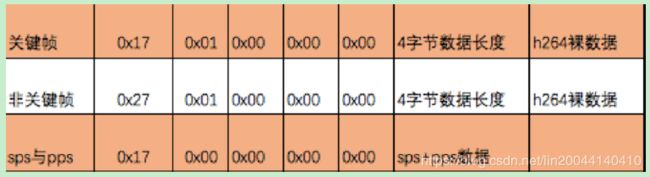
所以,对视频帧(关键帧,非关键帧)的RTMPPacket的字节大小是 5 + 4 + 裸数据。
对于SPS,PPS的RTMPPacket的字节大小是 5+ 8 +3+ spslen + ppslen,其中 8 +3 是AVC序列头定义的长度。
AVC序列头定义的 8 + 3 个字节具体定义:

依据上面的分析,再来看下面的封包代码,应该很容易理解了:
视频配置信息的封包发送,在发送I帧之前,要先发送SPS ,PPS,
void VideoChannel::sendVideoConfig(uint8_t *sps, uint8_t *pps, int spslen, int ppslen) {
//把SPS,PPS封装成一个RTMPPacket发送出去,要发送的这个数据的总大小,除了spslen,ppslen,还有AVC序列头的长度,
//AVC序列头的长度,根据结构体定位是5+ 8 +3 ,所以总的数据包大小是5+ 8 +3+ spslen + ppslen
int bodySize = 13 + spslen + 3 + ppslen;
RTMPPacket *packet = new RTMPPacket;
RTMPPacket_Alloc(packet, bodySize);
//往rtmppacket中装入数据
int index = 0;
packet->m_body[index++] = 0x17; //固定头
packet->m_body[index++] = 0x00;//类型,
//composition time 0x000000
packet->m_body[index++] = 0x00;
packet->m_body[index++] = 0x00;
packet->m_body[index++] = 0x00;
//版本
packet->m_body[index++] = 0x01;
//编码规格
packet->m_body[index++] = sps[1];
packet->m_body[index++] = sps[2];
packet->m_body[index++] = sps[3];
packet->m_body[index++] = 0xFF;
//整个sps
packet->m_body[index++] = 0xE1;
//sps长度,2个字节
packet->m_body[index++] = (spslen >> 8) & 0xFF;
packet->m_body[index++] = spslen & 0xFF;
memcpy(&packet->m_body[index], sps, spslen);
index += spslen;
//装入pps
packet->m_body[index++] = 0x01;
//长度,同样占两个字节。
packet->m_body[index++] = (ppslen >> 8) & 0xFF;
packet->m_body[index++] = ppslen & 0xFF;
memcpy(&packet->m_body[index], pps, ppslen);
//设置RTMPPacket的参数
packet->m_packetType = RTMP_PACKET_TYPE_VIDEO;
packet->m_nBodySize = bodySize;
packet->m_headerType = RTMP_PACKET_SIZE_MEDIUM;
//时间戳,解码器端将根据这个时间戳来播放视频,这里sps,pps不是图像帧,所以不需要时间戳。
packet->m_nTimeStamp = 0;
//使用相对时间
packet->m_hasAbsTimestamp = 0;
//这个通道的值没有特别要求,但是不能跟rtmp.c中使用的相同。
packet->m_nChannel = 0x10;
//在使用完packet,要释放。
callback(packet);
}
视频 关键帧,普通帧的封包发送:
void VideoChannel::sendFrame(int type, uint8_t *p_payload, int i_payload) {
//关键帧,普通帧的发送
//去掉间隔符号,当间隔符是0x00 0x00 0x00 0x01,有4个字节,
if (p_payload[2] == 0x00) {
i_payload -= 4;
p_payload += 4;
} else if (p_payload[2] == 0x01) {
//当间隔符是0x00 0x00 0x01,有3个字节,
i_payload -= 3;
p_payload += 3;
}
//往RTMPPacket中装入数据
RTMPPacket *packet = new RTMPPacket;
//对于关键帧,非关键帧,根据RTMPPacket的结构定义,仅有第一个字节0x17(关键帧), 0x27的区别,
// 总数据的大小是5 + 4(数据长度)+裸数据
int bodySize = 9 + i_payload;
RTMPPacket_Alloc(packet, bodySize);
RTMPPacket_Reset(packet);
//非关键帧,0x27
packet->m_body[0] = 0x27;
//如果是关键帧,0x17
if (type == NAL_SLICE_IDR) {
packet->m_body[0] = 0x17;
}
//关键帧,非关键帧的类型都是0x01, sps,pps的类型是0x00
packet->m_body[1] = 0x01;
//时间戳,
packet->m_body[2] = 0x00;
packet->m_body[3] = 0x00;
packet->m_body[4] = 0x00;
//数据长度,占4个字节,相当于把int转成4个字节的byte数组
packet->m_body[5] = (i_payload >> 24) & 0xFF;//先取高位1个字节,
packet->m_body[6] = (i_payload >> 16) & 0xFF;
packet->m_body[7] = (i_payload >> 8) & 0xFF;
packet->m_body[8] = i_payload & 0xFF; //最后去低8位。
//填入裸数据
memcpy(&packet->m_body[9], p_payload, i_payload);
//设置RTMPPacket的参数
packet->m_hasAbsTimestamp = 0;
packet->m_nBodySize = bodySize;
packet->m_packetType = RTMP_PACKET_TYPE_VIDEO;
packet->m_nChannel = 0x10;
packet->m_headerType = RTMP_PACKET_SIZE_LARGE;
//在使用完packet,要释放。
callback(packet);
}如果在X264编码过程中需要调试,可以通过指定日志回调,来查看编码过程:
//打开log输出,查看编码过程的日志,这里是指定日志的回调。
//param.pf_log = x264_log_default2;
//打印x264编码的异常输出。得到整个编码的过程日志。
void x264_log_default2(void *, int i_level, const char *psz, va_list list) {
__android_log_vprint(ANDROID_LOG_ERROR, "X264", psz, list);
}