Object Detection: One-stage Detector DenseBox
继上一篇文章Object Detection : One-stage Detector YOLO,我们可以窥探到回归(regression)、端到端(end-to-end)思想在目标检测问题上的应用。下面开始单阶段目标检测器系列的第二篇,DenseBox。
YOLO -> DenseBox -> SSD -> YOLO v2 -> Retina -> YOLO v3 -> CornerNet -> CenterNet -> AlignDet
DenseBox: Unifying Landmark Localization with
End to End Object Detection
论文地址:1509.04874v3
1. 背景介绍
在卷积神经网络(CNN)兴起之前,大多模型是基于滑动窗口法(sliding-window based method)进行目标检测:首先提取图片不同尺寸(scales),不同位置(locations)的手工特征(handcrafted features);然后有些模型可能会做一些几何限制(geometric constraints),比如人的头、手臂、躯干、腿;最后用分类器(classifier)对这些特征进行分类。CNN兴起之后,人们使用全卷积网络(FCN)近似(approximate)滑动窗口法,这种方法使得模型能够端到端(end-to-end)训练,而且从零学习参数和特征提取(scratch)的方式大大提升了目标检测器的性能。

如上图,将输入的16x16x3的图片经过多层卷积操作(convolution),得到2x2x4的输出。整个过程相当于在原图上做14x14的窗口滑动,且步长为2,产生四个候选框(proposals), 输出的每个像素(pixel)对应于一个候选框。这就是全卷积网络近似滑动窗口法的过程描述。(ps:图中的FC不是全连接,依然是卷积操作)
不过,这样固定大小与步长的窗口是远远不够的 (可以了解一波overfeat)。对此YOLO就淘汰了滑动窗口法:它将原始图片分割成互不重合的网格单元(cell),每个网格单元负责检测落入其中的目标,通过卷积产生的特征图的各元素对应于原图的每个网格单元,然后用特征图各元素的值去定位中心(center)落在对应网格单元内的目标。这也不失为一种优雅的解决方式。
与YOLO相似,DenseBox也是全卷积网络,但仍遵循滑动窗口的特性(sliding window fashion)。它致力于小目标(small objects)以及遮挡检测(occlusion),比如人脸(human face),远处的汽车(far-away car)。
虽然两阶段模型在精度上较单阶段检测器有更大的优势,但由于R-CNN两阶段模型产生区域提议(proposals)分辨率较低(low resolution),同时缺乏上下文信息(context),直接或间接影响了分类的性能。所以DenseBox朝着小目标突破也是有一定的前瞻性的。
所以作者的贡献在于:(1) 设计全卷积网络实现小目标及遮挡目标的高精度检测;(2) 使用多任务训练(multi-task)进一步提升检测性能,也就是添加了标识点定位(landmark localization)任务分支。
2. 模型介绍
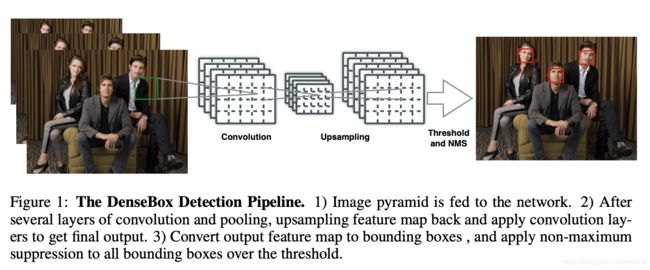
由上图可以了解到DenseBox的检测流程:首先是输入多个尺寸的同一张图片,即图像金字塔(image pyramid); 然后经过卷积&池化操作,再进行上采样,融合浅层与深层的特征再进行卷积操作,将得到的结果转化为检测框,并对检测框进行非极大值抑制(non-maximum supression, NMS),得到最终的结果。
2.1 模型的输入&输出
接下来定义一些符号。假如输入的图片大小为 m ∗ n ∗ 3 m*n*3 m∗n∗3, 则模型的最终输出是 m 4 ∗ m 4 ∗ 5 \frac{m}{4}*\frac{m}{4}*5 4m∗4m∗5,这意味着每4个像素点生成一个检测框,这样一来可以产生很密集的检测框,故命名为DenseBox。定义目标检测框的左上角(left top)和右下角(right bottom)为 p t = ( x t , y t ) p_t = (x_t, y_t) pt=(xt,yt), p b = ( x b , t b ) p_b = (x_b, t_b) pb=(xb,tb),最终输出的每个像素点 ( x i , y i ) (x_i, y_i) (xi,yi)描述了检测框的信息,用向量 t i ^ = { s ^ , d x t ^ = x i − x t , d y t ^ = y i − y t , d x b ^ = x i − x b , d y b ^ = y i − y b } i \hat{t_i} = \{\hat{s}, \hat{dx^t} = x_i - x_t, \hat{dy^t} = y_i-y_t, \hat{dx^b} = x_i - x_b, \hat{dy^b} = y_i - y_b\}_i ti^={s^,dxt^=xi−xt,dyt^=yi−yt,dxb^=xi−xb,dyb^=yi−yb}i表示,其中 s ^ \hat{s} s^是检测框中包含目标的置信度(confidence score), d x t ^ \hat{dx^t} dxt^, d y t ^ \hat{dy^t} dyt^, d x b ^ \hat{dx^b} dxb^, d y b ^ \hat{dy^b} dyb^预测的检测框相对于输出特征图各个位置的距离(原文链接1)。所以可以根据最终模型的输出,将其转化为检测框信息(confidence, xmin, ymin, xmax, ymax)。转化后得到的检测框肯定有冗余情况,所以需要对置信度超过设定阈值的检测框做非极大值抑制进行筛选,以得到最终的检测结果。
原文链接1: d x t ^ \hat{dx^t} dxt^, d y t ^ \hat{dy^t} dyt^, d x b ^ \hat{dx^b} dxb^, d y b ^ \hat{dy^b} dyb^ denote the distance between output pixel location with the boundary of target bounding box.
2.2 模型真值生成 (Ground Truth Generation)
DenseBox训练的输入并不是完整的图片,而是从原图中切割出来的包含人脸以及足够(sufficient)背景信息的图片块(patches),这是因为引入全图会导致卷积操作在背景上消耗过多的计算资源。
对此,训练数据是做过处理的。为了使模型对任意输入有更好的预测,需要在测试时需要采用图像金字塔作为输入,以弥补这种训练方式带来的“后遗症”。(原文链接2)
原文链接2: The RPN is trained on multi-scale objects while the DenseBox presented in this paper is trained on one scale with jitter-augmentation, which means our method need to evaluate feature at multiple scale.
作者觉得它的训练方式与分割的思想有点相似(a segmentation-like way),结合下图的可视化可能会更好理解一些。首先,将这些图片块缩放(resize)至240x240,人脸处于图片块的中间(center),高度(height)大约是50像素(pixels)。由于下采样的比例(ratio)是4,所以真值的规模是 60 ∗ 60 ∗ 5 60*60*5 60∗60∗5。其中,第一个channel是置信度的真值,正样本区域(positive labeled region)是一个半径(radius)为 r c r_c rc的实心圆(filled circle),该圆的半径与检测框的大小成比例,比例(scaling factor)为0.3,而圆心位于人脸检测框的中心,即圆内区域标注为正,圆外区域标注为负。这个实心圆的意义是:圆内像素的感受野(receptive field)包含一定大小、居中的目标。剩余的四通道则是检测框与输出各位置的距离,即五通道的像素点(5-channel pixel)代表一个检测框。
需要注意的是当多张人脸出现在一个图片块中时,与居中图片块的人脸(中心)相距一定范围(scale range)的其它人脸可以标注为正样本,该范围定义为0.8~1.25(与中心人脸检测框尺寸的倍数关系),在范围外的其它人脸定义为负样本(原文链接2)。
原文链接3: Note that if multiple faces occur in one patch, we keep those faces as positive if they fall in a scale range(e.g. 0.8 to 1.25 in our setting) relative to the face in patch center. Other faces are treated as negative samples/
2.3 模型设计 (Model Design)
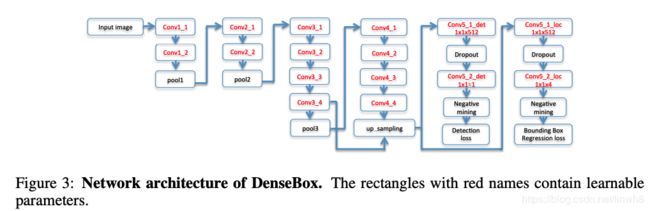
上图为DenseBox模型的简易设计。该模型一共有16个卷积层:前面的12个卷积层由ImageNet预训练的VGG-19进行初始化,主要进行特征提取;后面的4个卷积层使用xavier的初始化方式【补充1】 ,分为两组,一组用于分类,得到通道数为1的输出,将其作为分类的分数(class score map),另外一组用于检测框的回归,得到通道数为4的输出,将其作为预测边框的相对位置(relative position of bounding boxes)。这两组的最后一层1x1卷积扮演着全连接层(fully connected layer)的角色。
补充1:
神经网络中激活值的方差是逐层递减的,这导致反向传播中的梯度也逐层递减。要解决梯度消失,就要避免激活值方差的衰减,最理想的情况是,每层的输出值(激活值)保持高斯分布。(ps:所以后来也就有了Batch Normalization)
一般初始化:均值为0,方差为1的高斯分布
Xavier初始化:一般初始化后乘以rescale系数 1 / ( n ) 1/\sqrt(n) 1/(n),n为输入参数的个数
Kaiming初始化:一般初始化后乘以rescale系数 2 / ( n ) 2/\sqrt(n) 2/(n)
参考链接:一文搞懂深度网络初始化
从图中还可以观察到conv3_4与上采样后的conv4_4的特征融合(multi-level feature fusion),上采样采取的是双线性插值。浅层特征(low-level feature)或者局部特征(local feature)能够提供具有判别力的外貌特征(discriminative appearance part),而深层特征(high-level feature)或全局特征(global feature)或目标级特征(object-level feature)有更大的感受野,可以提供一些全局信息(global textures and context)。
2.4 多任务训练 (Multi-task Training)
DenseBox的简易设计有两个分支(sibling output branches)。第一个分支输出的是包含目标的置信度 y ^ \hat{y} y^,其对应的真值标签为 y ∗ ∈ { 0 , 1 } y^*\in\{0,1\} y∗∈{0,1},所以分类的损失函数(classification loss)可以定义为:
L c l s ( y ^ , y ∗ ) = ∣ ∣ y ^ − y ∗ ∣ ∣ 2 L_{cls}(\hat{y},y^*) = ||\hat{y}-y^*||^2 Lcls(y^,y∗)=∣∣y^−y∗∣∣2
作者在人脸以及车辆检测两个任务都采用了L2 损失,没有尝试铰链损失函数(hinge loss)【补充2】或交叉熵损失函数(cross entropy)。
补充2:
Hinge Loss是机器学习领域中的一种损失函数,可用于“最大间隔(max-margin)”分类,其最著名的应用是作为SVM的目标函数。
(1)在二分类的情况下,公式: L ( y ) = m a x ( 0 , 1 − t ⋅ y ) L(y) = max(0, 1-t·y) L(y)=max(0,1−t⋅y)。
其中,y是预测值(-1到1之间),t为目标值(1或 -1)。其含义为,y的值在 -1到1之间即可,并不鼓励 |y|>1,即让某个样本能够正确分类就可以了,不鼓励分类器过度自信,当样本与分割线的距离超过1时并不会有任何奖励。目的在于使分类器更专注于整体的分类误差。
(2)在多分类的情况下,采用变式: L ( y , y ′ ) = m a x ( 0 , m a r g i n − ( y − y ′ ) ) L(y, y') = max(0, margin-(y-y')) L(y,y′)=max(0,margin−(y−y′))。
其中,y是正确预测的得分,y′是错误预测的得分,两者的差值可用来表示两种预测结果的相似关系,margin是一个由自己指定的安全系数。我们希望正确预测的得分高于错误预测的得分,且高出一个边界值 margin,换句话说,y越高越好,y′ 越低越好,(y–y′)越大越好,(y′–y)越小越好,但二者得分之差最多为margin就足够了,差距更大并不会有任何奖励。这样设计的目的在于,对单个样本正确分类只要有margin的把握就足够了,更大的把握则不必要,过分注重单个样本的分类效果反而有可能使整体的分类效果变坏。分类器应该更加专注于整体的分类误差。
参考链接:理解Hinge Loss
第二个分支输出的检测框回归系数偏移 d ^ = ( d t x ^ , d t y ^ , d b x ^ , d b y ^ ) \hat{d} = (\hat{d_{tx}}, \hat{d_{ty}}, \hat{d_{bx}}, \hat{d_{by}}) d^=(dtx^,dty^,dbx^,dby^),其对应的真值标签为 d ∗ = ( d t x ∗ , d t y ∗ , d b x ∗ , d b y ∗ ) d^* = (d^*_{tx}, d^*_{ty}, d^*_{bx}, d^*_{by}) d∗=(dtx∗,dty∗,dbx∗,dby∗),所以检测框回归损失函数定义为:
L l o c ( d ^ , d ∗ ) = ∑ ∣ ∣ d i ^ − d i ∗ ∣ ∣ 2 i ∈ { t z , t y , b z , b y } L_{loc}(\hat{d}, d^*) = \sum{||\hat{d_i}-d^*_i||^2}_{i\in\{tz, ty, bz, by\}} Lloc(d^,d∗)=∑∣∣di^−di∗∣∣2i∈{tz,ty,bz,by}
(ps: 原论文这部分公式有点错误,我根据自己理解做了订正)
2.5 样本平衡 (Balance Sampling)
训练的过程中,如果在一个参数更新周期(mini-batch)中使用所有负样本(negative samples),它们很有可能会主导(dominate)梯度使预测的结果产生偏离(bias prediction)。还有,对于一些处于临界区域的样本(lying in the margin of positive and negative region),如果对这些样本进行惩罚(penalize),也很有可能会导致检测器的性能下降。若能平衡正负样本比例,充分挖掘临界样本,一定程度上是可以提升检测器的性能表现。
对于临界样本,论文中并不考虑去挖掘它的价值,而是通过设定一个忽视灰域(Ignoring Gray Zone),位于该区域的样本损失的权重(loss weight)应当设置为0。区域的标识实用 f i g n f_{ign} fign实现。对于输出空间中(output coordinate space)带有负标签的像素点,如果在以该像素点为圆心,半径为 r n e a r = 2 r_{near}=2 rnear=2的区域内包含带有正标签的像素,则标记为需要忽视的负样本,记 f i g n = 1 f_{ign} = 1 fign=1。
对于负样本中的难例(hard negative examples),论文进行了充分的挖掘,这样做可以得到预测更为鲁棒,噪声更少(原文链接3)。论文使用的是在线(online)的难例挖掘:在前传阶段,对负样本的损失按照降序排列,取前1%作为难例(hard-negative)。在训练的过程中,作者保留了所有正样本,并保持正负样本比例为1:1,而且,负样本中,难例样本占到一半,剩余一半的从非难例样本中随机选出。为实现方便,对被选择的样本进行标识,记 f s e l = 1 f_{sel}=1 fsel=1。
原文链接4: After negative mining, the badly predicted samples are very likely to be selected, so that gradient descent learning on those samples leads more robust prediction with less noise.
作者对以上两种方式(忽视灰域、难例挖掘)进一步封装,使用Mask来决定确定损失权重是否为0:
M ( t i ^ ) = { 0 f i g n i = 1 or f s e l i = 1 1 otherwise M(\hat{t_i}) = \begin{cases} 0& f_{ign}^i = 1 \text{ or } f_{sel}^i = 1\\ 1&\text{otherwise} \end{cases} M(ti^)={01figni=1 or fseli=1otherwise
结合该Mask,可以得到多任务损失函数(multi-task loss):
L d e t ( θ ) = ∑ i ( M ( t i ^ ) L c l s ( y i ^ , y i ∗ ) + λ l o c [ y i ∗ > 0 ] M ( t i ^ ) L l o c ( d i ^ , d i ∗ ) ) L_{det}(\theta) = \sum_i(M(\hat{t_i})L_{cls}(\hat{y_i}, {y_i}^*)+\lambda_{loc}[{y_i}^* > 0] M(\hat{t_i})L_{loc}(\hat{d_i}, {d_i}^*)) Ldet(θ)=i∑(M(ti^)Lcls(yi^,yi∗)+λloc[yi∗>0]M(ti^)Lloc(di^,di∗))
其中, θ \theta θ是网络参数, [ y i ∗ ] > 0 [{y_i}^*]>0 [yi∗]>0是艾佛森括号函数(Iverson bracket function), λ l o c \lambda_{loc} λloc是用于平衡分类与回归的损失,实验中设置为3。作者在实验中将 d ∗ d^* d∗通过除以标准目标高度(50/4)进行规范化(normalize)。
在训练的过程中,论文还用了其它骚操作(tricks)。论文中定义正样本图片块(positive patch)为包含一定尺度的居中目标,该图像块中负样本围绕着正样本。为了充分利用数据集中的负样本,论文采用了随机截取(random crop)的方式,从训练图片中随机截取图片块并缩放到于正样本图片块同样尺寸并加入到模型训练中。这两种类型的样本比例是1:1。不仅如此,作者对每一个输入的图像块做随机抖动(jitter),即左右反转(left-right flip),平移25像素点(transition shift of 25 pixels),尺度变化(scale deformation from [0.8, 1.25])。
训练细节:作者采用小批量随机梯度下降(mini-batch SGD)训练,批量大小(batch size)设置为10。损失与输出梯度都需要除以参与贡献的像素点数量(原文链接4)。全局学习率(learning rate)从0.001开始,然后每隔10000次迭代以0.1倍的速度衰减。动量(momentum)设置为0.9,权重衰减因子(weight decay factor)设置为0.0005。
原文链接5: The loss and output gradients must be scaled by the number of contributing pixels, so that both loss and output gradients are comparable.
2.6 使用关键点定位改进模型 (Refine with Landmark Localization)

从上图可以清晰的看到,作者将关键点定位的引入用在了两个方面:(1) 加入了关键点定位新分支,使用多任务训练的方式优化模型;(2)融合分类任务的分数(classification score map)与关键点定位任务的输出 (landmark localization maps/ heatmaps)进行卷积挖掘(具体原因见原文链接5),进一步改进检测结果。以上仅需通过简单的堆叠卷积层实现(原文链接6)。
原文链接6: An appropriate solution could be using high-level spatial model to learn the constraints of landmark confidence and bounding box score, to further increase the performance of detections.
原文链接7: In our implementation, we use convolutions with ReLU activation to approximate the spatial model.
如果有N个关键点,关键点定位分支就输出N个响应图(response map),响应图上的每个像素 ( x i , y i ) (x_i, y_i) (xi,yi)代表关键点在该位置的置信度。该任务的真值产生类似于检测任务:对于第i个实例第k个关键点 l i k l_i^k lik,其真值对应到第k个响应图,正标签区域是一个半径 r l r_l rl为1的实心圆,圆心的感受野包含该关键点。该实心圆的半径要相对小,否则会影响准确率(accuracy)。该任务也采用了L2损失函数,同时采用了上文提到的难例挖掘以及忽视灰域。
加入关键点定位任务后,损失函数如下:
L f u l l ( θ ) = λ d e t L d e t ( θ ) + λ l m L l m ( θ ) + L r f ( θ ) L_{full}(\theta) = \lambda_{det}L_{det}(\theta)+\lambda_{lm}L_{lm}(\theta)+L_{rf}(\theta) Lfull(θ)=λdetLdet(θ)+λlmLlm(θ)+Lrf(θ)
其中, L d e t L_{det} Ldet为前文的损失函数, L l m L_{lm} Llm为关键点定位损失函数, L r f L_{rf} Lrf为改进分支(refine branch)的损失函数, λ d e t \lambda_{det} λdet与 λ l m \lambda_{lm} λlm用于平衡着三个任务的损失,在实验中分别赋值为1,0.5。

3. 实验部分
作者没有在主流的通用目标检测数据集上验证模型的性能,而是在MALF(Multi-Attribute Labelled Faces) 与 KITTI car detection 数据集上进行验证。
KITTI car detection的验证度量(evaluation metric)与通用目标检测任务不同,KITTI要求与真阳性(True Positive)有70%的交叠,而其它任务一般只要求50%。所以在非极大值抑制阈值设置上,KITTI任务设置为0.75,MALF上设置为0.5。
具体实验设计细节见原论文,这里就不再说了~

从实验可以看出,DenseBoxEnsemble > DenseBoxLandmark > DenseBoxNoLandmark,且DenseBoxEnsemble达到了SOTA(state-of-the-art)。DenseBoxEnsemble整合了10个来自不同batch的DenseBoxLandmark。

由上图结果发现,加入关键点标注任务在KITTI上与MALF相比并没有得到太大的性能增益,这可能是因为对于汽车的关键点标注不够,导致该分支的增益有限。
4. 总结
DenseBox在人脸与汽车的检测上取得了很好的性能,然而其最大的局限在于速度,尤其是输入图像金字塔这个操作非常耗时。作者称后续DenseBox2解决了这个问题,我找个时间再分享一下它们的后续工作!