caffe训练模型并预测图片类型
参考:http://www.cnblogs.com/denny402/tag/caffe/(徐其华)
http://blog.csdn.net/u010193446/article/details/53433631
目录: 1. 准备图像数据
2.创建清单
3.将图像数据转换为lmdb格式
4.计算均值
5.编写参数的配置文件及训练网络的配置文件
6.训练模型
7.用训练的模型预测图片的类别
1. 准备图像数据
训练数据:将图片按类别进行分类,并标记,例如准备两类图片,一类为福码图片249张,用1表示此类,一类为其他各式的图片249张,用0表示此类
测试数据:将图片按类别进行分类,并标记,例如准备两类图片,一类为福码图片61张,一类为其他各式的图片61张
在主文件夹下创建work_liuyan_2017/readpractice文件夹,训练图片保存在trainimage,测试图片保存在testimage
2. 创建清单
sudo vim work_liuyan_2017/readpractice create_list.sh
#/usr/bin/env sh
DATATRAIN=readpractice/
DATATEST=readpractice/
MY=readpractice
echo "create train.txt"
rm -f $MY/train.txt
for i in 0 1
do
find $DATATRAIN/trainimage -name $i*.png | cut -d '/' -f4-5 | sed "s/$/ $i/">>$MY/train.txt
done
echo "create test.txt"
rm -f $MY/test.txt
for i in 0 1
do
find $DATATEST/testimage -name $i*.png | cut -d '/' -f4-5 | sed "s/$/ $i/">>$MY/test.txt
done
echo "all done"运行此脚本
cd work_liuyan_2017
sudo sh readpractice/create_list.sh
若成功在work_liuyan_2017/readpractice下生成traintxt及test.txt,里面为图片的列表清单

3.将图像数据转换为lmdb格式
cd work_liuyan_2017
sudo vim readpractice/create_lmdb.sh
#!/usr/bin/env sh
MY=readpractice
echo "create train lmdb"
rm -rf $MY/img_train_lmdb
/home/liuyan/caffe-master/build/tools/convert_imageset \
--shuffle \
--resize_height=240 \
--resize_width=240 \
/home/liuyan/work_liuyan_2017/readpractice/trainimage/ \
$MY/train.txt \
$MY/img_train_lmdb
echo "create test lmdb"
rm -rf $MY/img_test_lmdb
/home/liuyan/caffe-master/build/tools/convert_imageset \
--shuffle \
--resize_height=240 \
--resize_width=240 \
/home/liuyan/work_liuyan_2017/readpractice/testimage/ \
$MY/test.txt \
$MY/img_test_lmdb
echo "all done"
cd work_liuyan_2017
sudo sh readpractice /create_lmdb.sh
生成 img_train_lmdb 和 img_test_lmdb文件
4. 计算均值
图片减去均值再训练,会提高训练速度和精度。因此,一般都会有这个操作。
caffe程序提供了一个计算均值的文件compute_image_mean.cpp,我们直接使用就可以了
sudo /home/liuyan/caffe-master/build/tools/compute_image_mean /home/liuyan/work_liuyan_2017/readpractice/img_train_lmdb /home/liuyan/work_liuyan_2017/readpractice/mean.binaryproto
5.编写参数的配置文件及训练网络的配置文件
编写参数的配置文件
cd worke_liuyan_2017
sudo vim readpractice/solver.prototxt
net: "/home/liuyan/work_liuyan_2017/readpractice/train_val.prototxt"
test_iter: 2
test_interval: 500
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100
display: 50
max_iter: 2000
momentum: 0.9
weight_decay: 0.0005
snapshot: 1000
snapshot_prefix: "/home/liuyan/work_liuyan_2017/readpractice/"
solver_mode: GPU编写训练网络的配置文件
首先:sudo cp /home/liuyan/caffe-master/models/bvlc_reference_caffenet/train_val.prototxt readpractice
其次:修改部分train_val.prototxt
开始的
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "readpractice/mean.binaryproto" #路径 注意cd到哪里了
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: true
# }
data_param {
source: "readpractice/img_train_lmdb"
batch_size: 127
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "readpractice/mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: false
# }
data_param {
source: "readpractice/img_test_lmdb"
batch_size: 61
backend: LMDB
}
}最后的:
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2 #原来为1000,训练为n类,就写>=n,训练的为2类,我就写了2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}6.训练模型
cd work_liuyan_2017
开始训练 sudo /home/liuyan/caffe-master/build/tools/caffe train -solver readpractice/solver.prototxt
模型会保存在
snapshot_prefix: "/home/liuyan/work_liuyan_2017/readpractice/"
这个路径中
训练结果:
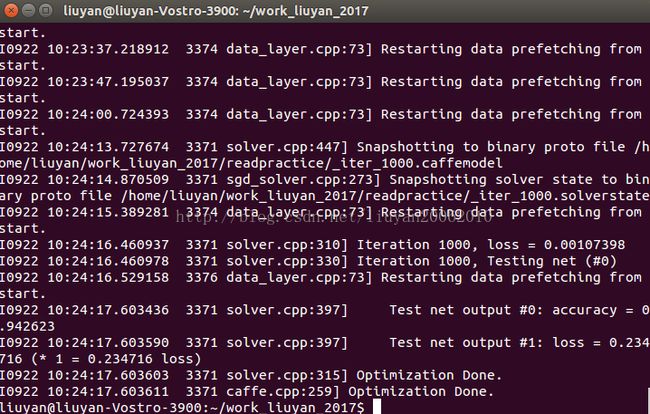
7.用训练的模型预测图片的类别
首先:
修改deploy.prototxt最后部分
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
inner_product_param {
num_output: 2 #输出类别为2类,保持一致
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
}其次:准备一张将要预测的图片,命名为2.png

然后:
创建labels.txt:
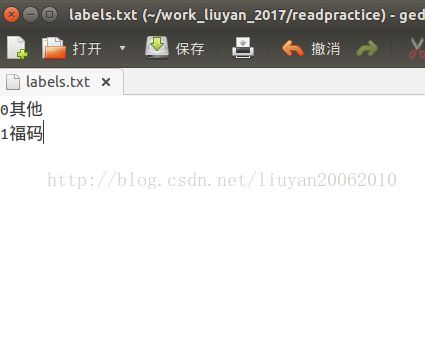
在终端输入:
sudo caffe-master/build/examples/cpp_classification/classification.bin \
> work_liuyan_2017/readpractice/deploy.prototxt \
> work_liuyan_2017/readpractice/_iter_1000.caffemodel \
> work_liuyan_2017/readpractice/mean.binaryproto \
>work_liuyan_2017/readpractice/labels.txt \
> work_liuyan_2017/readpractice/2.png
回车输出结果,最后的几行
