【python爬虫专项(21)】最简单的Selenium网络爬虫(以爬取豆瓣数据为例)
访问网页
通过以下代码打开任意网址(括号里输入网址)
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://xxx.com")
返回结果为WebDriver对象,网页测试窗口也进入对应网址
.current_url → 返回网页网址
.get_cookies() → 返回网页cookies
示例(代码运行在spyder中,打开百度和豆瓣都成功了)
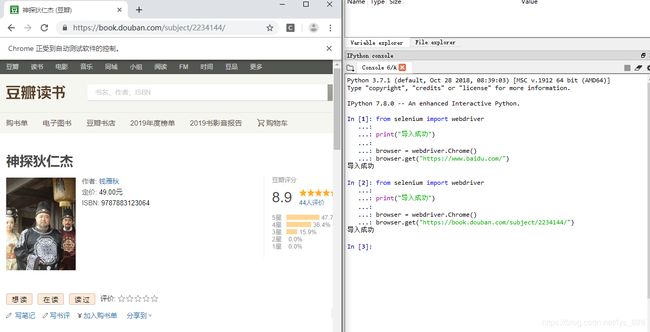
针对创建的brower对象,可以查看类型和调用其下面的一些方法及函数,如下

获取网页数据
采集页面数据:https://book.douban.com/subject/1043815/
步骤一、前期准备,配置好参数,确保浏览器可以正常打开,并导入相关库(time计时)
from selenium import webdriver
import time
start_time = time.time()
browser = webdriver.Chrome()
browser.get("https://book.douban.com/subject/1043815/")
运行结果是会弹出下面的界面:

步骤二、获取标题,对应的标签信息如下

通过查看标签信息可知标题在h1标签里面,因此实现标题获取的代码如下
title = browser.find_element_by_tag_name('h1').text
输出结果如下:
![]()
步骤三、获取书籍信息,对应的标签信息如下

发现书籍信息里面存在着id,因此可以通过下面的代码获取书籍信息
info = browser.find_element_by_id('info').text
输出结果如下:

步骤四、获取评分、其对应的标签信息如下

因为没有明显的可以使用的标签,这时候就可以用到最初介绍的方式,使用xpath进行数据的获取,只需要针对标签鼠标右键,在弹出的选项框里面选择copy,然后点击copy XPath,将内容再粘贴到下面的括号内,就可以实现路径的选择,获取评分的代码实现如下
score = browser.find_element_by_xpath('//*[@id="interest_sectl"]/div/div[2]/strong').text
输出的结果为:
![]()
步骤四、获取评论人数,其对应的标签信息如下
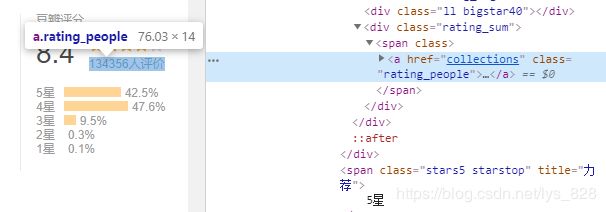
这里虽然存在a标签,但是一个网页里面a标签众多,这里也可以采用上面的方式,使用xpath获取信息,代码如下
comment = browser.find_element_by_xpath('//*[@id="interest_sectl"]/div/div[2]/div/div[2]/span/a').text
输出的结果为:
![]()
步骤五、将采集的数据存放至字典,并计算整个爬虫运行的时间
dic = {}
dic['书名'] = title
dic['其他信息'] = info.split('\n')
dic['评分'] = score
dic['评论人数'] = comment
print(dic)
end_time = time.time()
print("花费了{:.2f}秒".format(end_time-start_time))
输出的结果为:

可以看出通过Selenium爬取信息要比之前Beautiful配合requests来的简洁一些,但是有个缺点就是运行时间较长,这里爬取一页的数据就用了7.71s
代码示例
from selenium import webdriver
import time
start_time = time.time()
browser = webdriver.Chrome()
browser.get("https://book.douban.com/subject/1043815/")
title = browser.find_element_by_tag_name('h1').text
info = browser.find_element_by_id('info').text
score = browser.find_element_by_xpath('//*[@id="interest_sectl"]/div/div[2]/strong').text
comment = browser.find_element_by_xpath('//*[@id="interest_sectl"]/div/div[2]/div/div[2]/span/a').text
dic = {}
dic['书名'] = title
dic['其他信息'] = info.split('\n')
dic['评分'] = score
dic['评论人数'] = comment
print(dic)
end_time = time.time()
print("花费了{:.2f}秒".format(end_time-start_time))
输出的结果为:
{‘书名’: ‘骆驼祥子’, ‘其他信息’: [‘作者: 老舍’, ‘出版社: 人民文学出版社’, ‘出版年: 2000-3-1’, ‘页数: 224’, ‘定价: 12.00’, ‘装帧: 平装’, ‘ISBN: 9787020028115’], ‘评分’: ‘8.4’, ‘评论人数’: ‘134356人评价’}
花费了7.71秒