ShardingSphere部分(上)
数据分片:按某个维度将存放在单一数据库中的数据分散存放到多个库或表中,提升性能瓶颈及可用性
有效手段:对关系型数据库分库分表:避免数据量超过可承受阈值产生查询瓶颈
分库:有效分散对数据库单点的访问量
分表:尽量将分布式事务转化为本地事务的可能
垂直拆分:按照业务拆分,纵向拆分:专库专用;无法真正解决单点瓶颈,可缓解数据量和访问量带来的问题
水平拆分:横向拆,通1/*个字段据某种规则将数据分散至*库或表中:据主键分片 偶数进0库/表 奇数进1库/表
理论上突破单机数据量处理的瓶颈,扩展相对自由,分库分表表中解决方案
SQL概念
绑定表:分片规则一致的主表和子表:t_order和t_order_item均按order_id分片,他们之间的关联查询不会笛卡尔积
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
绑定后,路由的sql应该是:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
t_order在FROM的最左侧,将以它为整个绑定表的主表。 所有路由计算只用主表的策略,t_order_item表的分片计算使用t_order的条件,绑定表之间的分区键要完全相同。广播表:all分片数据源都存在的表,结构和数据完全一致,量不大需要海量数据的表管理查询:字典表
逻辑索引:同库不许相同索引名的分表场景,需将不同表的索引名改写索引名+表,改写前索引名称成为逻辑索引
分片
分片键:水平拆的关键字段,无则执行全路由:性能差,支持多字段分片
分片算法:
通分片策略提炼各种场景,提供更高级的抽象,并提供接口
精确分片
PreciseShardingAlgorithm,处理使用单一键作为分片键的=与IN进行分片的场景?需配合StandardShardingStrategy使用
范围分片
RangeShardingAlgorithm,单一键作为分片键的BETWEEN AND进行分片,需配合StandardShardingStrategy使用
复合分片
ComplexKeysShardingAlgorithm,多键做为分片键进行分片,配合ComplexShardingStrategy使用
hint分片
HintShardingAlgorithm,使用Hint行分片,配合HintShardingStrategy使用
中间的这一大段就在我刚才点保存的时候 全没了,我保留着个网页开啥,csdn也是 token不过期的么
这部分是:内核剖析中的路由引擎还有改写引擎
下面多写页挽回不了什么,直接到执行引擎
执行引擎:自动化地平衡资源与执行效率
连接模式
为每个分片查询维持一个独立的数据库连接,更有效利用多线程
为每个分片维护独立的数据库连接,避免过早将查询结果加载到内存
为每个库连接开启独立线程,将I/O消耗并行处理
流式归并:
以结果集游标下移进行结果归并,不将结果全加载内存;
当无法保证每个分片查询有独立数据库连接时需要在复用该库连接取下一张分表查询结果前,将当前查询结果全加载至内存
内存限制模式
前提:shardingsphere不限制一次操作所消耗的数据库连接数
使用于OLAP,通放宽对数据库连接的限制提升系统吞吐量
连接限制模式
前提:shardingsphere严格控制对一次操作所耗费的数据库连接数量:与上相反
防止对一次请求数据库连接占用过多带来问题,使用于OLTP,OLTP通常带有分片键,路由到单一分片
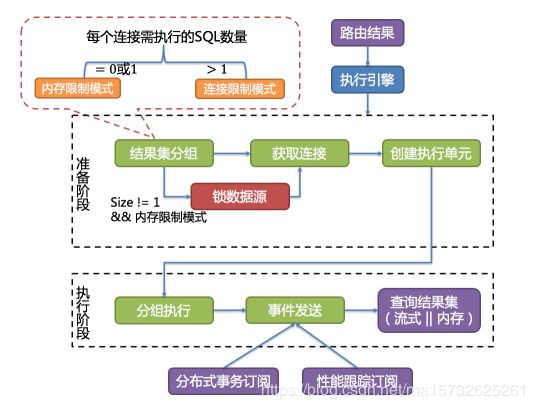
自动化执行引擎
将连接模式的选择粒度细化至每一次SQL的操作,据路由结果实时演算和权衡,自主采用恰当连接模式
准备阶段:准备执行的数据
实现内化连接模式概念的关键,执行引擎据maxConnectionSizePerQuery,结合当前路由结果,选择恰当连接模式
- sql路由结果按数据源名称分组
- 通下面公式,获每个库实例在maxConnectionSizePerQuery容许范围内,各连接需要执行的sql路由结果组,计算本次请求最优连接模式

避免死锁的出现:获取数据库连接进行同步处理,创建执行单元时,原子方式一次性获取本次sql请求所需的全部数据库连接
- 避免 锁定一次性 只需 获取1个库连接 ,1次连接 不会有两个请求互相等待的场景,大部分OLTP使用分片键路由至唯一数据节点,使得系统变为完全无锁的状态,提升并发效率,读写分离也在次范畴
- 仅针对 内存限制模式 进行资源锁定,连接限制模式时,all查询结果集将在装至内存后释放库连接资源
执行阶段
执行sql,分组执行和归并结果集
分组执行:上一阶段生成的执行单元分组下发至底层并发执行引擎,针对执行过程中每个关键步骤发送事件
执行引擎仅关注事件的发送,不关心事件的订阅者
通过执行准备阶段获取连接模式,生成内存归并结果集或流式归并结果集,并将其传递至结果归并引擎
归并引擎
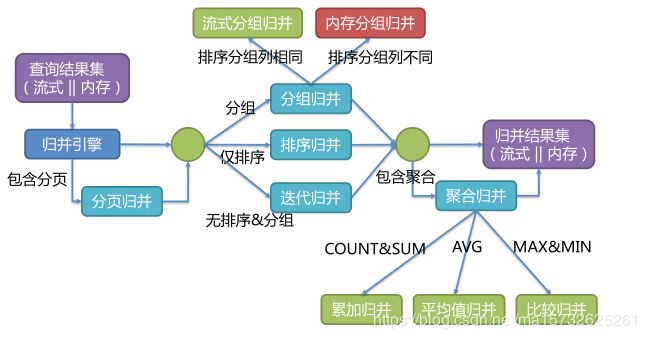
结果归并:将各个数据节点获取的多数据结果集,组合成一个结果集并正确的返回至请求客户端
分类
功能上分为 遍历/排序/分组/分页/聚合:组合非互斥
结构上:流式归并,内存归并,装饰者归并:流式与内存互斥,装饰可在流式及内存归并进一步处理
归并:库中逐条返回结果集,不需将all数据一次性load内存,结果归并时沿用库返回结果集的方式归并:减内存消耗
流式:每次从结果集获取的数据,能通过逐条获取方式返回正确的单条数据,契合库原生的返回结果集方式
遍历,排序,流式分组
内存:将结果集all数据遍历存储在内存中,再通过统一分组,排序,聚合等再将其封装为逐条访问数据结果集
装饰者:all结果集归并进行统一功能增强:分页,聚合
遍历归并:最简单
多个结果集合并为单向链表,遍历完链表中当前数据后,将链表元素后移一位,继续遍历
排序归并
sql存在order by,每个结果集自身有序,只需要将集当前游标指向的数据值进行排序:多个有序数组排序
对排序查询进行归并时,将每个结果集当前数据值比较(java comparable)并放入优先队列,每次获取下一条数据:将队列顶端结果集游标下移,据新游标重新进入优先级排序队列找到自己位置:每次next仅获取唯一正确的一条数据

分组归并
流式分组归并:SQL排序项与分组项字段及排序类型(ASC或DESC)须一致,否只能通过内存归并才能保证其数据的正确性。
- 它会一次性的将多个数据结果集中的分组项相同的数据全数取出。
- 它需要根据聚合函数的类型进行聚合计算。
内存分组归并:将所有的结果集数据加载至内存中进行分组和聚合
排序语句缺失,shardingsphere通过sql改写,自动增加与分组项一致的排序项,转内存为流式
聚合归并
在之前介绍的归并类上追加的归并能力,装饰者模式:比较 / 累加 /求平均值
比较:比较每个同组结果集数据,返回max或min值
累加:sum count ,将每个结果集数据累加
求平均值:avg ,通过sql 改写的 sum和count进行计算
分页归并
装饰者模式,将无需获取的数据过滤掉;结果集next方法将无需取出的数据跳过
limit不能通过索引查询数据,如果可以保证ID连续性,通过ID分页较好
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/sharding/
https://github.com/alibaba/otter/wiki/Otter%E8%B0%83%E5%BA%A6%E6%A8%A1%E5%9E%8B