配置Hadoop上的编程环境,测试样例运行
前置准备:
Hadoop运行成功
『 Hadoop』从零安装第六弹 -
http://www.jianshu.com/p/96ed8b7886d2安装Linux版本的eclipse
eclipse-jee-mars-2-linux-gtk-x86_64.tar.gz
在Linux下用tar命令解压即可,参考之前Hadoop解压安装将eclipse的hadoop插件拷到eclipse安装目录下的plugin文件夹内
hadoop-eclipse-plugin-2.6.0.jar
好现在开始我们的Hadoop编程之旅!
-
启动hadoop服务
$ start-all.sh 等价于 $start-dfs.sh 和 $start-yarn.sh

-
设置hadoop安装路径

-
把右上角的小象调出来
-
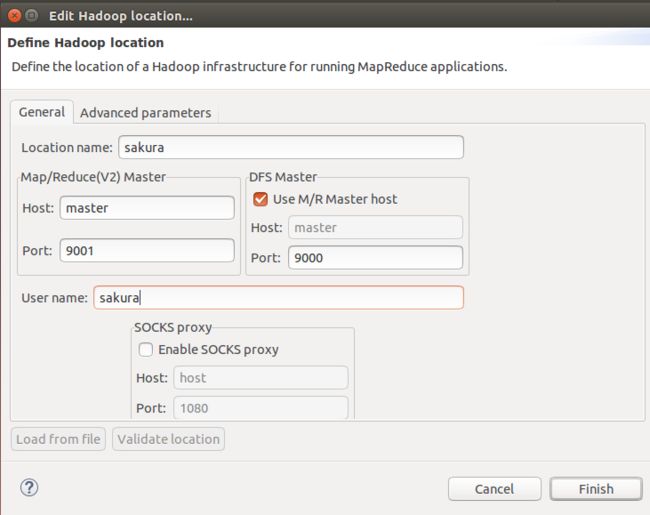
手动配置Hadoop 新建或编辑Hadoop location
-
成功显示hdfs里的文件

然后就可以new 一个MapReduce项目了,开车咯
样例程序运行
通过给定的uri打开HFDS里的指定文件,输出到控制台
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class ReadFromFileSystemAPI {
public static void main(String[] args) throws Exception{
//文件地址
String uri = "hdfs://master:9000/input/words.txt";
//读取配置文件
Configuration conf = new Configuration();
//获取文件系统对象fs
FileSystem fs = FileSystem.get(URI.create(uri), conf);
//第二种获取文件系统的方法
//FileSystem fs = FileSystem.newInstance(URI.create(uri), conf);
//创建输入流
InputStream in = null;
try{
//调用打开方法打开文件并输出到控制台
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
}finally{
IOUtils.closeStream(in);
}
}
}
控制台输出

拷贝Linux上的指定文件夹到HDFS的指定目录
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
String uri = "hdfs://master:9000/";
FileSystem hdfs=FileSystem.get(URI.create(uri),conf);
//本地文件
Path src =new Path("/home/sakura/outout");
//HDFS文件
Path dst =new Path("/");
//文件系统调用copy方法
hdfs.copyFromLocalFile(src, dst);
//i do not why it is not hdfs://master:9000
System.out.println("Upload to"+conf.get("fs.defaultFS"));
//获取hdfs里的文件目录
FileStatus files[]=hdfs.listStatus(dst);
//循环输出hdfs里的文件名
for(FileStatus file:files){
System.out.println(file.getPath());
}
}
}
控制台输出

导航栏增加了 outout 文件夹

第一个 MapReduce 单词计数WordCount
统计/home/sakura/workspace/WordCountProject 目录下的
input文件夹内的单词出现次数
并输出到同目录下的newout文件夹内
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one); }
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "192.168.19.131:9001");
String[] ars=new String[]{"input","newout"};
String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
输出结果

先大概试着理解MapReduce程序的流程。通常分为三个类,一个启动类包含着Map和Reduce;一个Map类,负责Map工作;一个Reduce类,负责Reduce工作。
MapReduce程序的详细分析,之后让我来娓娓道来,这次主要任务是跑跑程序,跟着敲一敲,看看环境啥的有没有搭好。
读取文件内容
通过DSDataInputStream读取指定文件内容,并依照一定的偏移量(6)读取输出
此例子没有主类,需要JUnit Test运行
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.log4j.Logger;
import org.apache.log4j.PropertyConfigurator;
import org.junit.Before;
import org.junit.Test;
public class TestFSDataInputStream {
private FileSystem fs = null;
private FSDataInputStream in = null;
private String uri = "hdfs://master:9000/input/words.txt";
private Logger log = Logger.getLogger(TestFSDataInputStream.class);
static{
PropertyConfigurator.configure("conf/log4j.properties");
}
@Before
public void setUp() throws Exception {
Configuration conf = new Configuration();
fs = FileSystem.get(URI.create(uri), conf);
}
@Test
public void test() throws Exception{
try{
in = fs.open(new Path(uri));
log.info("文件内容:");
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(6);
Long pos = in.getPos();
log.info("当前偏移量:"+pos);
log.info("读取内容:");
IOUtils.copyBytes(in, System.out, 4096, false);
byte[] bytes = new byte[10];
int num = in.read(7, bytes, 0, 10);
log.info("从偏移量7读取10个字节到bytes,共读取"+num+"字节");
log.info("读取内容:"+(new String(bytes)));
//以下代码会抛出EOFException
// in.readFully(6, bytes);
// in.readFully(6, bytes, 0, 10);
}finally{
IOUtils.closeStream(in);
}
}
}
通过creat() 将指定文件写入HDFS指定目录
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
import org.apache.log4j.PropertyConfigurator;
import org.junit.Test;
public class WriteByCreate {
static{
//PropertyConfigurator.configure("conf/log4j.properties");
}
@Test
public void createTest() throws Exception {
String localSrc = "/home/sakura/outout/newboy.txt";
String dst = "hdfs://master:9000/output/newboy.txt";
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
OutputStream out = null;
try{
//调用create方法创建文件
out = fs.create(new Path(dst),
new Progressable() {
public void progress() {
System.out.print(".");
}
});
//Log.info("write start!");
IOUtils.copyBytes(in, out, 4096, true);
System.out.println();
//Log.info("write end!");
}finally{
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}
输出结果

总结
这次我们试着跑了几个简单的Hadoop例子,测试环境,体验了Hadoop上编程的感觉。代码不算很难,但需要有点Java基础,如果大家在代码上遇到理解问题,欢迎留言提问噢!
PS:最近在弄一个豆瓣电影推荐的小小项目,用到了MapReduce来分析数据,哈哈,拭目以待吧!!