Go语言学习 二十二 并发
本文最初发表在我的个人博客,查看原文,获得更好的阅读体验
并发是每个编程语言绕不开的一个话题,Go在并发编程方面提供了许多特性,帮助简化并发模型,如轻量级的线程goroutine,信道等,同样也提供了如sync.Mutex等的锁机制。
为实现对共享变量的正确访问,Go语言提供了一种特殊的控制方式,即将共享的值通过信道传递。信道是一种带有方向的管道,数据可以在其中流转。在任意一个的时间点,只有一个goroutine能够访问该值,既无需加锁,也无需同步。数据竞争从设计上就被杜绝了。这种思想,被总结为一句话:
不要通过共享内存来通信,而应通过通信来共享内存。
Go的并发处理方式源于Hoare的通信顺序处理(Communicating Sequential Processes, CSP)
一 并发处理
1.1 快速开始
在Go中,通过使用关键字go,可以快速创建一个goroutine,例如:
package main
import (
"fmt"
"time"
)
func main() {
go printWord("A") // 开启一个新的goroutine
printWord("C")
}
func printWord(s string) {
for i := 0; i < 5; i++ {
fmt.Println(s)
time.Sleep(500 * time.Millisecond)
}
}
上面一个例子中,在多核CPU系统中,会交替打印出字母"A"、“C”,在单核CPU中则稍有不同。
1.2 Goroutine
goroutine是一种轻量级的线程。它具有简单的模型:它与其它goroutine并发运行在同一地址空间,因此,访问共享的内存时必须进行同步(或者使用信道)。它的所有消耗几乎就只有栈空间的分配,而且栈最开始是非常小的,所以它们很廉价,仅在需要时才会随着堆空间的分配(和释放)而变化。
goroutine在多线程操作系统上可实现多路复用,因此若一个线程阻塞,比如说等待I/O,那么其它的线程会继续运行。goroutine的设计隐藏了线程创建和管理的诸多复杂性。
直接在函数或方法前添加go关键字即可在新的goroutine中调用它。当调用完成后,该goroutine也会安静地退出。(效果有点像Unix Shell中的&符号,它可以让命令在后台运行。)
有些地方将Goroutine翻译为
Go程,但这个词感觉并不怎么合适(也不好听),所以本文索性就将其称之为goroutine。
前面的示例中我们已经看到过:
func main() {
go printWord("A") // 开启一个新的goroutine
printWord("C")
}
func printWord(s string) {
for i := 0; i < 5; i++ {
fmt.Println(s)
time.Sleep(500 * time.Millisecond)
}
}
有时,为了简化程序,可以直接将函数定义为一个函数字面量(即匿名函数):
package main
import (
"fmt"
"time"
)
func main() {
s := "hello"
go func() { // 函数字面量,开启一个新的goroutine
for i := 0; i < 5; i++ {
fmt.Println(s+":", i)
time.Sleep(500 * time.Millisecond)
}
}()
// 等待主程序运行结束
time.Sleep(3000 * time.Millisecond)
}
这些示例都是一些简单的函数,要想体现出Go的精妙,还需要配合另一种数据类型,即信道。
二 信道
信道(channel)是一种重要的数据类型,既可以用作信号量,也可以用于数据传递,其结果值充当了对底层数据结构的引用。信道具有方向,可选的信道操作符<-指定了通道的方向,发送或接收。如果没有给出方向,则它是双向的,信道可以通过分配或显式转换来限制只发送或接收。信道的零值是nil,尝试往未初始化的信道或已关闭的信道发送或接收值都会导致运行时恐慌。
chan<- float64 // 单向信道,只能用于发送float64的值
<-chan int // 单向信道,只能用于接收int值
<-运算符与最左边的chan关联:
chan<- chan int // 同 chan<- (chan int)
chan<- <-chan int // 同 chan<- (<-chan int)
<-chan <-chan int // 同 <-chan (<-chan int)
chan (<-chan int)
“箭头”就是数据流的方向。
2.1 无缓冲信道
和映射一样,在使用前需要先使用make初始化:
// 创建一个可用于发送和接收字符串类型的信道
c := make(chan string)
重新看一下本文开头的例子,如果我们只保留一个goroutine中的打印,会怎么样:
package main
import (
"fmt"
"time"
)
func main() {
go printWord("A") // 开启一个新的goroutine
}
func printWord(s string) {
for i := 0; i < 5; i++ {
fmt.Println(s)
time.Sleep(500 * time.Millisecond)
}
}
结果发现,这次什么也没有输出。
为什么?一方面,新开启的goroutine不会阻塞当前的main函数,另一方面,一旦main函数执行完毕,整个程序也就结束,所以上面那个goroutine还没来得及打印,主程序就已经结束了。除了用time.Sleep函数让main函数等待一段时间,我们还可以借助信道来更优雅的实现:
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan bool)
go printWord("A", c) // 开启一个新的goroutine
<-c // 等待打印完毕,丢弃传递过来的值
}
func printWord(s string, c chan bool) {
for i := 0; i < 5; i++ {
fmt.Println(s)
time.Sleep(500 * time.Millisecond)
}
c <- true // 发送信号,告知执行完毕
}
默认情况下,信道的发送和接收操作在另一端准备好之前都会阻塞。这使得goroutine可以在没有显式的锁或竞态变量的情况下进行同步。这样,一旦打印任务执行完毕,就会告知主函数,主函数收到通知,就会立即往下执行。
除了将信道用作信号量,也可以用于传输数据:
package main
import (
"fmt"
"time"
)
func main() {
info := make(chan string) // 用于传输数据的信道
go send(info)
for w := range info {
w := w // 注意这里变量w的特殊用法
go func() {
time.Sleep(600 * time.Millisecond)
fmt.Println(w)
// fmt.Println(&w)
}()
}
time.Sleep(1000 * time.Millisecond)
}
// 模拟发送信息
func send(info chan string) {
word := [...]string{"A", "B", "C", "D", "E", "F"}
for _, s := range word {
info <- s // 将数据放入信道
}
close(info) // 传输完毕关闭
}
输出:
E
B
A
C
F
D
这里特别要注意上述第13行代码:
w := w
该循环变量在每次迭代时会被重用,因此变量w会在所有的goroutine间共享,为了避免这种情况,我们使用同名的变量重新获取了一份该变量的值,就好像我们在局部把原来的变量屏蔽了一样。你可以试着将第13行代码注释掉看一下效果。这种用法虽然看起来很奇怪,但这是Go的惯用语法。
注释掉后会打印出相同的结果:
F F F F F F可以使用
go vet命令来检查这种问题:$ go vet hello.go # command-line-arguments ./hello.go:16:16: loop variable w captured by func literal
针对这个问题,另外一种写法同样有效:
package main
import (
"fmt"
"time"
)
func main() {
info := make(chan string) // 用于传输数据
go send(info)
for w := range info {
go func(w string) {
time.Sleep(600 * time.Millisecond)
fmt.Println(w)
// fmt.Println(&w)
}(w) // 作为实参传入
}
time.Sleep(1000 * time.Millisecond)
}
// 模拟发送信息
func send(info chan string) {
word := [...]string{"A", "B", "C", "D", "E", "F"}
for _, s := range word {
info <- s // 将数据放入信道
}
close(info) // 传输完毕关闭
}
注意代码第14、18行与之前代码的区别。
最后需要注意的是,这种无缓冲的信道由于两端需要同时就绪才能工作,所以只在一个main函数中是无法工作的:
package main
import (
"fmt"
)
func main() {
c := make(chan bool)
c <- true
fmt.Println(<-c)
}
原因是第9行和第10行发生了死锁,两端都在等待对方准备就绪,运行结果会报错:
fatal error: all goroutines are asleep - deadlock!
无缓冲信道在通信时会同步交换数据,它能确保(两个goroutine的)计算处于确定状态。
信道遵循FIFO原则。
2.2 带缓冲的信道
若提供了一个可选的整型参数,它就会为该信道设置缓冲区大小。默认值是零,表示不带缓冲的或同步的信道。
c1 := make(chan int) // 整型的无缓冲信道
c2 := make(chan int, 0) // 整型的无缓冲信道
c3 := make(chan *os.File, 100) // 指向文件指针的带缓冲信道
仅当信道的缓冲区填满后,向其发送数据时才会阻塞。当缓冲区为空时,接受方会阻塞。
以下示例展示了一个带有缓冲区的信道:
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan string, 3)
go printWord("A", c) // 开启一个新的goroutine
for i := 0; i < 5; i++ {
fmt.Println(<-c)
time.Sleep(600 * time.Millisecond)
}
fmt.Println("打印完毕")
}
func printWord(s string, c chan string) {
for i := 0; i < 5; i++ {
c <- s
time.Sleep(300 * time.Millisecond)
}
fmt.Println("发送完毕")
}
我们可以看出发送的速度明显要快于打印的速度。这种特性还可被用作信号量,例如限制请求的吞吐量等。
2.3 信道的迭代和关闭
发送者可通过内置函数close关闭一个信道来表示没有需要发送的值了。接收者可以通过逗号ok语法来测试信道是否被关闭:若没有值可以接收且信道已被关闭,那么在执行完v, ok := <-ch之后ok会被设置为false。
循环 for i := range c 会不断从信道接收值,直到它被关闭(不关闭会引发panic)。
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan string, 3)
go printWord("A", c) // 开启一个新的goroutine
for s := range c {
fmt.Println(s)
time.Sleep(600 * time.Millisecond)
}
fmt.Println("打印完毕")
}
func printWord(s string, c chan string) {
for i := 0; i < 5; i++ {
c <- s
time.Sleep(300 * time.Millisecond)
}
close(c) // 发送完毕,关闭信道
fmt.Println("发送完毕")
}
注意:只有发送者才能关闭信道,而接收者不能。向一个已经关闭的信道发送数据会引发程序恐慌(panic)。另外,信道与文件不同,通常情况下无需关闭它们。只有在必须告诉接收者不再有需要发送的值时才有必要关闭,例如终止一个
for-range循环。
三 select语句
select语句是Go中另一个重要特性。与switch语法类似,不过全都是关于通信操作的。它可以使一个goroutine等待多个通信操作。select会阻塞到某个分支可以继续执行为止,这时就会执行该分支。当多个分支都准备好时会随机选择一个执行。
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan string, 3)
c2 := make(chan string, 3)
go printWord("A", c1) // 开启一个新的goroutine
go printWord("B", c2) // 开启一个新的goroutine
for i := 0; i < 5; i++ {
select {
case s1 := <-c1:
fmt.Println(s1)
case s2 := <-c2:
fmt.Println(s2)
}
}
fmt.Println("打印完毕")
}
func printWord(s string, c chan string) {
for {
c <- s
time.Sleep(300 * time.Millisecond)
}
}
3.1 default分支
当select中的其它分支都没有准备好时,default分支就会执行。
为了在尝试发送或者接收时不发生阻塞,可使用 default 分支:
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan string, 3)
c2 := make(chan string, 3)
go printWord("A", c1) // 开启一个新的goroutine
go printWord("B", c2) // 开启一个新的goroutine
for i := 0; i < 5; i++ {
select {
case s1 := <-c1:
fmt.Println(s1)
case s2 := <-c2:
fmt.Println(s2)
default:
fmt.Println("waiting..")
time.Sleep(300 * time.Millisecond)
}
}
fmt.Println("打印完毕")
}
func printWord(s string, c chan string) {
for {
c <- s
time.Sleep(300 * time.Millisecond)
}
}
四 其他同步机制
4.1 互斥锁
信道让goroutine之间的通信变有趣且强大,但有时我们可能只想保证安全的访问一个共享变量,Go同样也提供了传统的锁机制方案。标准库中提供了一个互斥锁类型:
sync.Mutex
该类型实现了sync.Locker接口:
type Locker interface {
Lock()
Unlock()
}
Mutex的零值是一个解锁状态的互斥锁,无需特殊初始化。
Mutex一旦使用,不能再将其复制使用。我们可以在一段代码前调用其Lock()方法,在代码后调用其Unlock()方法,来保证该段代码的互斥执行。该互斥锁不与特定的goroutine绑定,我们可以在一个goroutine中进行锁定,并在另一个goroutine中进行解锁。当然我们也可以用defer语句来保证互斥锁一定会被解锁.
我们看一下经典的卖火车票的例子在Go中是如何实现的。
以下是未进行同步的代码示例:
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
ticket := 10
go sell(&ticket, "售票员1")
go sell(&ticket, "售票员2")
sell(&ticket, "售票员3")
time.Sleep(1000 * time.Millisecond)
fmt.Println("停止售票!!!")
}
func sell(ticket *int, name string) {
for {
// 以下操作不是原子操作
if *ticket <= 0 {
fmt.Printf("%v说:票卖完了\n", name)
break
}
time.Sleep(time.Duration(rand.Intn(1e3)) * time.Millisecond)
*ticket--
fmt.Printf("%v说:还剩%v张票。\n", name, *ticket)
}
}
上边的例子中,第22-28行代码没有进行同步,不是一个原子操作,所以执行结果达不到我们的预期,会出现卖出负票的情况:
售票员3说:还剩9张票。
售票员3说:还剩8张票。
售票员3说:还剩7张票。
售票员3说:还剩6张票。
售票员2说:还剩5张票。
售票员1说:还剩4张票。
售票员3说:还剩3张票。
售票员3说:还剩2张票。
售票员1说:还剩1张票。
售票员2说:还剩0张票。
售票员2说:票卖完了
售票员1说:还剩-1张票。
售票员1说:票卖完了
售票员3说:还剩-2张票。
售票员3说:票卖完了
停止售票!!!
加锁解决:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var m sync.Mutex
func main() {
ticket := 10
go sell(&ticket, "售票员1")
go sell(&ticket, "售票员2")
sell(&ticket, "售票员3")
time.Sleep(1000 * time.Millisecond)
fmt.Println("停止售票!!!")
}
func sell(ticket *int, name string) {
for {
m.Lock() // 卖票前加锁同步
if *ticket <= 0 {
fmt.Printf("%v说:票卖完了\n", name)
defer m.Unlock() // 全部卖完记得解锁
break
}
time.Sleep(time.Duration(rand.Intn(1e3)) * time.Millisecond)
*ticket--
fmt.Printf("%v说:还剩%v张票。\n", name, *ticket)
m.Unlock() // 每卖完一张解锁
}
}
结果输出:
售票员3说:还剩9张票。
售票员3说:还剩8张票。
售票员1说:还剩7张票。
售票员2说:还剩6张票。
售票员3说:还剩5张票。
售票员1说:还剩4张票。
售票员2说:还剩3张票。
售票员3说:还剩2张票。
售票员1说:还剩1张票。
售票员2说:还剩0张票。
售票员3说:票卖完了
售票员1说:票卖完了
售票员2说:票卖完了
停止售票!!!
我们看到,这次恰到好处的卖完了所有票。
4.1.1 RWMutex
sync包中还有一些其他锁,比如读写锁RWMutex,它是一个基于Mutex的互斥锁,区别在于RWMutex允许持有多个读锁,但只能有一个写锁。同样,RWMutex的零值是一个未加锁的互斥锁。且一旦用过也是不能再次复制使用。其方法如下:
func (rw *RWMutex) Lock()
func (rw *RWMutex) RLock()
func (rw *RWMutex) RLocker() Locker
func (rw *RWMutex) RUnlock()
func (rw *RWMutex) Unlock()
4.2 Once
Once类型可以保证被调用的函数只执行一次。它只有一个方法:
func (o *Once) Do(f func())
其中f只有在第一次被调用时有效。该特性通常用于只能执行一次的初始化中。
package main
import (
"fmt"
"sync"
)
func main() {
var once sync.Once
c := make(chan int)
for i := 0; i < 5; i++ {
i := i
go func() {
once.Do(info)
fmt.Printf("第%v次调用info()\n", i)
c <- 1
}()
}
for i := 0; i < 5; i++ {
<-c
}
}
func info() {
fmt.Println("====But the info() func Only executes once on the first call.")
}
输出如下:
====But the info() func Only executes once on the first call.
第4次调用info()
第0次调用info()
第1次调用info()
第2次调用info()
第3次调用info()
4.3 WaitGroup
WaitGroup会等待一批goroutine执行完成。主goroutine在使用前先调用其Add方法设置要等待的goroutine数;然后每个goroutine运行并在运行完后调用其Done函数告知执行完毕;同时,主goroutine中可以调用Wait函数来等待所有其他goroutine执行完成,在此之前,Wait函数会一直阻塞。
在Java中,java.util.concurrent.CountDownLatch具有类似的功能。
WaitGroup方法如下:
// 向WaitGroup的计数器中增加delta个计数。在计数器变为0之前,Wait函数一直阻塞.
// 当计数器为0时(例如刚初始化,)此函数必须在Wait函数调用前调用。
// delta可以为负,但可能会导致运行时恐慌。
func (wg *WaitGroup) Add(delta int)
// 每次调用会使计数器减1
func (wg *WaitGroup) Done()
// 在计数器变为0之前一直阻塞
func (wg *WaitGroup) Wait()
WaitGroup 可以复用于多个独立的等待事件,前提是之前所有的等待必须都已返回。
在前面卖火车票的例子中,main函数最后一行代码如下:
time.Sleep(1000 * time.Millisecond)
我们加入这行代码的原因是让主函数等待尽可能长的时间,以便其他goroutine能顺利执行完毕。但是这种操作显然不够优雅,因为我们不知道其他goroutine到底什么时候执行完毕,只能猜测。现在我们借助WaitGroup来做这件事情了:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var m sync.Mutex
var wg sync.WaitGroup
func main() {
ticket := 10
wg.Add(3) // 设置需要等待几个goroutine。
go sell(&ticket, "售票员1")
go sell(&ticket, "售票员2")
sell(&ticket, "售票员3")
wg.Wait() // 开始等待
fmt.Println("停止售票!!!")
}
func sell(ticket *int, name string) {
defer wg.Done() // 任务完成时,通知主goroutine
for {
m.Lock() // 卖票前加锁同步
if *ticket <= 0 {
fmt.Printf("%v说:票卖完了\n", name)
defer m.Unlock() // 全部卖完记得解锁
break
}
time.Sleep(time.Duration(rand.Intn(1e3)) * time.Millisecond)
*ticket--
fmt.Printf("%v说:还剩%v张票。\n", name, *ticket)
m.Unlock() // 每卖完一张解锁
}
}
现在,一旦某个卖票的goroutine执行完毕,就会立即通知主goroutine,当主goroutine等待所有goroutine完成任务时,能立即发现。
五 指定可用的CPU核心数
Go语言提供了一些函数,可以让我们精确的控制程序所使用的CPU资源,例如,函数runtime.NumCPU可以返回机器上可用的硬件CPU核数:
var cpus = runtime.NumCPU()
另外,还有一个函数runtime.GOMAXPROCS,可以获取或设置Go程序可以同时运行的用户指定的CPU核心数。它默认等于runtime.NumCPU的值,但是可以通过设置同名的shell环境变量或用一个正数参数调用该函数来覆盖它。用0调用该函数则可以查询当前值。因此,如果我们尊重用户的资源请求,我们应该这么写:
var cpus = runtime.GOMAXPROCS(0)
尝试修改并运行以下示例:
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
runtime.GOMAXPROCS(1) // 将该值修改为2看一下结果有什么不同
go printWord("A") // 开启一个新的goroutine
printWord("C")
}
func printWord(s string) {
for i := 0; i < 5; i++ {
fmt.Println(s)
time.Sleep(500 * time.Millisecond)
}
}
注意不要混淆并发和并行的概念:并发是用可独立执行的组件构造程序的方法,而并行则是为了效率在多CPU上平行地进行计算。尽管Go的并发特性能够让某些问题更易构造成并行计算,但Go仍然是种并发而非并行的语言,且Go的模型并不适合所有的并行问题。一张图简单描述并发与并行的区别:
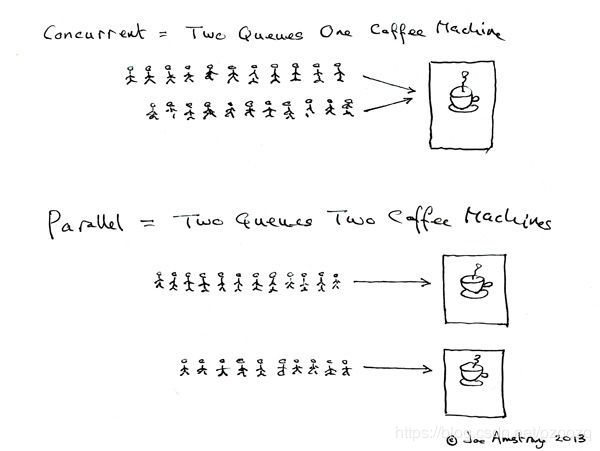
(图 By Erlang 之父 Joe Armstrong)
关于并发和并行区别的详细讨论,见此博文和该幻灯片。
参考:
https://golang.org/doc/effective_go.html#concurrency
https://golang.org/pkg/sync/
https://golang.org/ref/spec#Select_statements
https://golang.org/ref/spec#Channel_types