数学基础(三):凸优化对偶理论(拉格朗日对偶函数,主对问题,强弱对偶问题)
数学基础系列博客是自己在学习了稀牛学院&网易云课堂联合举办的《人工智能数学基础》微专业后的课程笔记总结。怀着对授课讲师Jason博士无限的敬佩与感激之情,我在完整听了两遍课程之后,对这门进行了笔记整理。Jason博士用深入浅出的方式把数学知识真的是讲透彻了,我的笔记显然无法完整传达Jason博士的精彩授课内容,在此非常推荐每一个打算进入或了解AI的同学去学习这门课程!
一:一般优化问题
m i n m i z e f 0 ( x ) s u b j e c t t o f i ( x ) ≤ 0 f o r i = 1 , 2 , . . . m h i ( x ) = 0 f o r i = 1 , 2 , . . . p minmize\quad f_0(\mathbf{x})\\subject\ to\ f_i(\mathbf{x})\le0 \quad for\ i = 1,2,...m\\\quad \quad \quad \quad h_i(\mathbf{x}) = 0\quad for\ i=1,2,...p minmizef0(x)subject to fi(x)≤0for i=1,2,...mhi(x)=0for i=1,2,...p
问题的定义域 D = ( ⋂ i = 0 m dom f i ) ⋂ ( ⋂ i = 0 p dom h i ) \mathcal{D}=\left(\bigcap_{i=0}^{m} \operatorname{dom} f_{i}\right) \bigcap\left(\bigcap_{i=0}^{p} \operatorname{dom} h_{i}\right) D=(⋂i=0mdomfi)⋂(⋂i=0pdomhi).需要注意的是 :定义域与可行域是不同的。可行域是同时满足目标函数定义域和约束条件的x的集合。
二:拉格朗日函数
2.1 函数基本介绍
-
拉格朗日函数将目标函数和约束条件整合到了一起。
L ( x , λ , v ) = f 0 ( x ) + ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 p v i h i ( x ) L(\mathbf{x}, \lambda, v)=f_{0}(\mathbf{x})+\sum_{i=1}^{m} \lambda_{i} f_{i}(\mathbf{x})+\sum_{i=1}^{p} v_{i} h_{i}(\mathbf{x}) L(x,λ,v)=f0(x)+i=1∑mλifi(x)+i=1∑pvihi(x) -
主变量 : x \mathbf{x} x
-
对偶变量: λ ≥ 0 \lambda \ge0 λ≥0,即 λ = [ λ 1 , λ 2 , ⋯ λ m ] T ≥ 0 \lambda = [\lambda_1,\lambda_2,\cdots \lambda_m]^T\ge0 λ=[λ1,λ2,⋯λm]T≥0;而 v \mathbf{v} v可以大于等于0,也可以小于等于0.
-
意义解释:这其实是一种添加惩罚的方式。如果约束条件 f i ( x ) ≥ 0 f_i(\mathbf{x})\ge0 fi(x)≥0,那么就相当于加了一个正数( λ ≥ 0 \lambda \ge 0 λ≥0),使得拉格朗日函数变大,而我们的目标在于最小化该函数,因此就会强迫约束条件小于等于0。
2.2 函数的主问题分析
L ( x , λ , v ) = f 0 ( x ) + ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 p v i h i ( x ) L(\mathbf{x,\lambda, v})=f_{0}(\mathbf{x})+\sum_{i=1}^{m} \lambda_{i} f_{i}(\mathbf{x})+\sum_{i=1}^{p} v_{i} h_{i}(\mathbf{x}) L(x,λ,v)=f0(x)+i=1∑mλifi(x)+i=1∑pvihi(x)
-
主问题:
p ∗ = min x { max ( λ , v ) L ( x , λ , v ) ) } p^*=\min_\mathbf{x}\{\max_{\mathbf(\lambda,v)}L(\mathbf{x,\lambda,v}))\} p∗=xmin{(λ,v)maxL(x,λ,v))} -
主问题分析:我们的目标其实是 min x f 0 ( x ) \min_\mathbf{x}f_0(\mathbf{x}) minxf0(x),即我们要求函数 f 0 ( x ) f_0(\mathbf{x}) f0(x)的最小值,而不是 m a x L maxL maxL的最小值。那么原函数和 m a x L maxL maxL之间有什么关系呢?
我们单独看max的部分:
max λ , v L ( x , λ , v ) = f 0 ( x ) + max λ , v ( ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 p v i h i ( x ) ) \max _{\lambda, v} L(\mathrm{x}, \lambda, v)=f_{0}(\mathrm{x})+\max _{\lambda, v}\left(\sum_{i=1}^{m} \lambda_{i} f_{i}(\mathrm{x})+\sum_{i=1}^{p} v_{i} h_{i}(\mathrm{x})\right) λ,vmaxL(x,λ,v)=f0(x)+λ,vmax(i=1∑mλifi(x)+i=1∑pvihi(x))
在这个函数中, λ \lambda λ和 v v v是变量。当x在可行域范围内时, f i ( x ) ≤ 0 , λ ≥ 0 f_i(\mathbf{x})\le0,\lambda \ge 0 fi(x)≤0,λ≥0,所以括号中第一项小于等于0;第二项中由于 h i ( x ) = 0 h_i(\mathbf{x})=0 hi(x)=0,所以第二项也为0。这样也就是说 max λ , v ( ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 p v i h i ( x ) ) \max _{\lambda, v}\left(\sum_{i=1}^{m} \lambda_{i} f_{i}(\mathrm{x})+\sum_{i=1}^{p} v_{i} h_{i}(\mathrm{x})\right) maxλ,v(∑i=1mλifi(x)+∑i=1pvihi(x))的值为0。所以最小化 m a x L maxL maxL和最小化目标函数是等效的。
2.3 函数的对偶问题分析
-
拉格朗日对偶函数
g ( λ , v ) = min x ∈ D L ( x , λ , v ) = min x ∈ D { f 0 ( x ) + ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 p v i h i ( x ) } g(\boldsymbol{\lambda}, \boldsymbol{v})=\min _{\mathbf{x} \in \mathcal{D}} L(\mathbf{x}, \boldsymbol{\lambda}, \boldsymbol{v})=\min _{\mathbf{x} \in \mathcal{D}}\left\{f_{0}(\mathbf{x})+\sum_{i=1}^{m} \lambda_{i} f_{i}(\mathbf{x})+\sum_{i=1}^{p} v_{i} h_{i}(\mathbf{x})\right\} g(λ,v)=x∈DminL(x,λ,v)=x∈Dmin{f0(x)+i=1∑mλifi(x)+i=1∑pvihi(x)}-
需要注意:这个对偶函数是定义在函数定义域上的,不是可行域。
-
回忆:逐点最大: f 1 , ⋯ , f m f_{1}, \cdots, f_{m} f1,⋯,fm凸,则 f ( x ) = max { f 1 ( x ) , ⋯ , f m ( x ) } f(\mathrm{x})=\max \left\{f_{1}(\mathrm{x}), \cdots, f_{m}(\mathrm{x})\right\} f(x)=max{f1(x),⋯,fm(x)} 凸。 f ( x , y ) f(\mathbf{x,y}) f(x,y)对于每个 y ∈ A \mathrm{y} \in \mathcal{A} y∈A凸,则 max y ∈ A f ( x , y ) \max _{y \in \mathcal{A}} f(x, y) maxy∈Af(x,y)凸。
-
g ( λ , v ) g(\boldsymbol{\lambda}, \boldsymbol{v}) g(λ,v)其实是关于 λ , v \lambda,v λ,v的仿射函数,所以是既凸且凹的函数。所以该函数的逐点下确界总是凹的。即 g ( λ , v ) g(\boldsymbol{\lambda}, \boldsymbol{v}) g(λ,v)是一个凹函数。
-
相当于,给定一个 x \mathbf{x} x,然后大括号里面有很多个仿射函数,这些仿射函数的逐点下确界是凹函数。
-
如果 x ~ \tilde{\mathbf{x}} x~是一个可行域中的点,则:
g ( λ , v ) = min x ∈ D L ( x , λ , v ) ≤ L ( x ~ , λ , v ) g(\boldsymbol{\lambda}, \boldsymbol{v})=\min _{\mathbf{x} \in \mathcal{D}} L(\mathbf{x}, \boldsymbol{\lambda}, \boldsymbol{v}) \leq L(\widetilde{\mathbf{x}}, \boldsymbol{\lambda}, \boldsymbol{v}) g(λ,v)=x∈DminL(x,λ,v)≤L(x ,λ,v)-
因为 g ( λ , v ) g(\boldsymbol{\lambda}, \boldsymbol{v}) g(λ,v)是拉格朗日函数在整个定义域上的的最小值,又因为可行域仅仅是定义域的一部分,所以它小于等于可行域中的任何一个函数值。
-
又因为
L ( x ~ , λ , v ) = f 0 ( x ~ ) + ∑ i = 1 m λ i f i ( x ~ ) + ∑ i = 1 p v i h i ( x ~ ) ≤ f 0 ( x ~ ) L(\widetilde{\mathbf{x}}, \boldsymbol{\lambda}, \boldsymbol{v})=f_{0}(\widetilde{\mathbf{x}})+\sum_{i=1}^{m} \lambda_{i} f_{i}(\widetilde{\mathbf{x}})+\sum_{i=1}^{p} v_{i} h_{i}(\widetilde{\mathbf{x}}) \leq f_{0}(\widetilde{\mathbf{x}}) L(x ,λ,v)=f0(x )+i=1∑mλifi(x )+i=1∑pvihi(x )≤f0(x )-
因为对于可行域中的点, f i ( x ~ ) ≤ 0 f_{i}(\widetilde{\mathbf{x}}) \le0 fi(x )≤0, h i ( x ~ ) = 0 h_{i}(\widetilde{\mathbf{x}}) =0 hi(x )=0.所以 L ( x ~ , λ , v ) ≤ f 0 ( x ~ ) L(\widetilde{\mathbf{x}}, \boldsymbol{\lambda}, \boldsymbol{v}) \le f_{0}(\widetilde{\mathbf{x}}) L(x ,λ,v)≤f0(x ).这也就是说 g ( λ , v ) ≤ f 0 ( x ~ ) g(\boldsymbol{\lambda}, \boldsymbol{v}) \le f_{0}(\widetilde{\mathbf{x}}) g(λ,v)≤f0(x ),即 g ( λ , v ) g(\boldsymbol{\lambda}, \boldsymbol{v}) g(λ,v)小于等于 f 0 ( x ) f_0(\mathbf{x}) f0(x)中任意一点的函数值,当然也就小于其最小值了,即 g ( λ , v ) ≤ f 0 ( x ∗ ) = p ∗ g(\boldsymbol{\lambda}, \boldsymbol{v}) \le f_{0}(\mathbf{x^*})=p^* g(λ,v)≤f0(x∗)=p∗。
-
从上边的分析中可以看出,对偶问题小于等于原问题最优解的下界。如果我们能够求出对偶问题的上界,那么就可以确定一个原问题的下界。接下来我们就想办法求对偶问题的上界,即最大值。
-
-
-
-
拉格朗日对偶问题:
maximize g ( λ , v ) subject to λ ≥ 0 \begin{array}{ll}{\text { maximize }} & {g(\lambda, v)} \\ {\text { subject to }} & {\lambda \geq 0}\end{array} maximize subject to g(λ,v)λ≥0 -
目标函数: max λ ≥ 0 , v min x ∈ D L ( x , λ , v ) \max _{\lambda \geq 0, \mathrm{v}} \min _{\mathrm{x} \in \mathcal{D}} L(\mathrm{x}, \lambda, v) maxλ≥0,vminx∈DL(x,λ,v)
-
这其实是一个凹函数在凸集上的最大化问题。是一个凸优化问题。设其最优值为 d ∗ d^* d∗,对应的极值点为 λ ∗ , v ∗ \lambda^*,v^* λ∗,v∗。
-
从以上分析中我们就可以得出一个结论:不管原问题是不是一个凸优化问题,他的对偶问题一定是一个凸优化问题。 g ( λ ∗ , v ∗ ) = d ∗ ≤ p ∗ g(\mathbf{\lambda^*,v^*})=d^* \le p^* g(λ∗,v∗)=d∗≤p∗,即对偶问题的最大值小于等于原问题的最小值。
2.4 对偶问题的几何解释
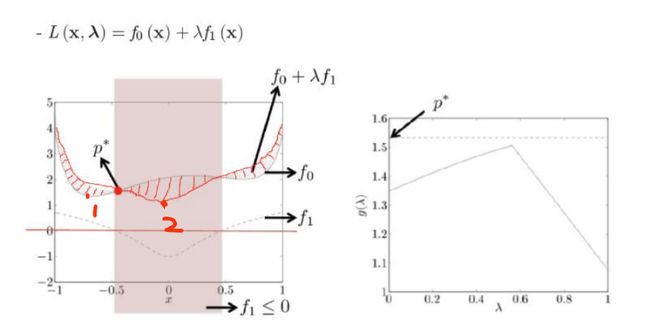
- 可行域为图中阴影部分;定义域为[-1,1]
- 原问题的最小值(即可行域中的最小值)在 p ∗ p^* p∗x处。
- 当 λ = 0 \lambda = 0 λ=0时, L ( x , λ ) = f 0 ( x ) L(\mathbf{x,\lambda})=f_0(\mathbf{x}) L(x,λ)=f0(x).函数在定义域上的最小值在1处,约为1.3。当 λ = 1 \lambda =1 λ=1时, L ( x , λ ) = f 0 ( x ) + f 1 ( x ) L(\mathbf{x,\lambda})=f_0(\mathbf{x})+f_1(\mathbf{x}) L(x,λ)=f0(x)+f1(x),此时函数的最小值在2处,约为0.8.当 λ \lambda λ在[0,1]之间变化时,对偶问题的最大值始终小于原函数的最小值(参考右边图)。
- 在整个定义域上,对偶问题的最大值小于等于原问题的最小值。
2.5 强弱对偶问题解释
-
弱对偶: d ∗ < p ∗ d^* <p^* d∗<p∗,无论原问题是不是凸优化问题,总成立
-
强对偶: d ∗ = p ∗ d^* = p^* d∗=p∗,
-
该条件通常不成立
-
但是对于凸优化问题通常成立
-
凸优化问题可以改写为:
m i n i m i z e f 0 ( x ) s u b j e c t t o f i ( x ) ≤ 0 f o r i = 1 , 2 , ⋯ m A x = b minimize \ f_0(\mathbf{x}) \\ subject\ to \ f_i(\mathbf{x}) \le 0\ for \ i =1,2,\cdots m \\ \mathbf{Ax=b} minimize f0(x)subject to fi(x)≤0 for i=1,2,⋯mAx=b -
slater条件:存在内点 x \mathbf{x} x。使得 f i ( x ) < 0 f o r i = 1 , 2 , ⋯ m f_i(\mathbf{x}) <0 \ for \ i =1,2,\cdots m fi(x)<0 for i=1,2,⋯m均成立。
-
-
说明:如果没有不等式约束,只有 A x = b \mathbf{Ax=b} Ax=b,那么一定是强对偶;如果存在不等式约束,那么满足slater条件时,是强对偶;但是需要注意的是:不满足slater条件,不代表一定不是强对偶问题。
2.6 从对偶问题解主问题
-
假定强对偶问题成立, ( x ∗ , λ ∗ , v ∗ ) \left(\mathrm{x}^{*}, \lambda^{*}, v^{*}\right) (x∗,λ∗,v∗)是主问题和对偶问题的最优解,那么
p ∗ = f 0 ( x ∗ ) = d ∗ = g ( λ ∗ , v ∗ ) = min x ( f 0 ( x ) + ∑ i = 1 m λ i ∗ f i ( x ) + ∑ i = 1 p v i ∗ h i ( x ) ) 最小值肯定小于等于任意一个x对应的函数值,因此 ≤ f 0 ( x ∗ ) + ∑ i = 1 m λ i ∗ f i ( x ∗ ) + ∑ i = 1 p v i ∗ h i ( x ∗ ) 因为x星肯定在函数的可行域内,因此后边两项均为非正值,因此 ≤ f 0 ( x ∗ ) \begin{aligned} p^{*}=f_{0}\left(\mathrm{x}^{*}\right) &=d^{*}=g\left(\lambda^{*}, v^{*}\right) \\ &=\min _\mathbf{x}\left(f_{0}(\mathrm{x})+\sum_{i=1}^{m} \lambda_{i}^{*} f_{i}(\mathrm{x})+\sum_{i=1}^{p} v_{i}^{*} h_{i}(\mathrm{x})\right) \\ & \text{最小值肯定小于等于任意一个x对应的函数值,因此} \\ & \leq f_{0}\left(\mathrm{x}^{*}\right)+\sum_{i=1}^{m} \lambda_{i}^{*} f_{i}\left(\mathrm{x}^{*}\right)+\sum_{i=1}^{p} v_{i}^{*} h_{i}\left(\mathrm{x}^{*}\right) \\ & \text{因为x星肯定在函数的可行域内,因此后边两项均为非正值,因此} \\ & \leq f_{0}\left(\mathrm{x}^{*}\right) \end{aligned} p∗=f0(x∗)=d∗=g(λ∗,v∗)=xmin(f0(x)+i=1∑mλi∗fi(x)+i=1∑pvi∗hi(x))最小值肯定小于等于任意一个x对应的函数值,因此≤f0(x∗)+i=1∑mλi∗fi(x∗)+i=1∑pvi∗hi(x∗)因为x星肯定在函数的可行域内,因此后边两项均为非正值,因此≤f0(x∗) -
观察上式首尾两项,可得 f 0 ( x ∗ ) ≤ f 0 ( x ∗ ) f_{0}(\mathrm{x}^{*}) \le f_{0}(\mathrm{x}^{*}) f0(x∗)≤f0(x∗),因此小于等于号可变为等号。因此也就可以得到:
- 结论1: λ i ∗ f i ( x ∗ ) = 0 \lambda_{i}^{*} f_{i}\left(\mathrm{x}^{*}\right)=0 λi∗fi(x∗)=0
- 结论2: L ( x , λ ∗ , v ∗ ) L\left(\mathrm{x}, \lambda^{*}, v^{*}\right) L(x,λ∗,v∗)关于 x ∗ \mathbf{x^*} x∗处取极小值,有 ∇ x L ( x ∗ , λ ∗ , v ∗ ) = 0 \nabla_{\mathrm{x}} L\left(\mathrm{x}^{*}, \lambda^{*}, v^{*}\right)=0 ∇xL(x∗,λ∗,v∗)=0
- g ( λ ∗ , v ∗ ) = L ( x ∗ , λ ∗ , v ∗ ) g\left(\lambda^{*}, v^{*}\right)=L\left(\mathrm{x}^{*}, \lambda^{*}, v^{*}\right) g(λ∗,v∗)=L(x∗,λ∗,v∗);对偶函数的最优解就在拉格朗日函数取极值的时候
- g ( λ ∗ , v ∗ ) = min x L ( x , λ ∗ , v ∗ ) g\left(\lambda^{*}, v^{*}\right)=\min _{x} L\left(\mathrm{x}, \lambda^{*}, v^{*}\right) g(λ∗,v∗)=minxL(x,λ∗,v∗)
2.7 KKT条件
-
凸优化问题:
m i n m i z e f 0 ( x ) s u b j e c t t o f i ( x ) ≤ 0 f o r i = 1 , 2 , . . . m h i ( x ) = 0 f o r i = 1 , 2 , . . . p minmize\quad f_0(\mathbf{x})\\subject\ to\ f_i(\mathbf{x})\le0 \quad for\ i = 1,2,...m\\\quad \quad \quad \quad h_i(\mathbf{x}) = 0\quad for\ i=1,2,...p minmizef0(x)subject to fi(x)≤0for i=1,2,...mhi(x)=0for i=1,2,...p -
拉格朗日函数
L ( x , λ , v ) = f 0 ( x ) + ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 p v i h i ( x ) L(\mathrm{x}, \lambda, v)=f_{0}(\mathrm{x})+\sum_{i=1}^{m} \lambda_{i} f_{i}(\mathrm{x})+\sum_{i=1}^{p} v_{i} h_{i}(\mathrm{x}) L(x,λ,v)=f0(x)+i=1∑mλifi(x)+i=1∑pvihi(x) -
凸优化问题强对偶成立的充要条件:
- f i ( x ∗ ) ≤ 0 , i = 1 , ⋯ , m ( ∇ λ L ( x ∗ , λ , v ) ≤ 0 ) f_{i}\left(\mathrm{x}^{*}\right) \leq 0, i=1, \cdots, m\left(\nabla_{\lambda} L\left(\mathrm{x}^{*}, \lambda, v\right) \leq 0\right) fi(x∗)≤0,i=1,⋯,m(∇λL(x∗,λ,v)≤0)
- h i ( x ∗ ) = 0 , i = 1 , ⋯ , p ( ∇ v L ( x ∗ , λ , v ) = 0 ) h_{i}\left(\mathrm{x}^{*}\right)=0, i=1, \cdots, p\left(\nabla_{\mathrm{v}} L\left(\mathrm{x}^{*}, \lambda, v\right)=0\right) hi(x∗)=0,i=1,⋯,p(∇vL(x∗,λ,v)=0)
- λ i ∗ ≥ 0 , i = 1 , ⋯ , m \lambda_{i}^{*} \geq 0, i=1, \cdots, m λi∗≥0,i=1,⋯,m
- λ i ∗ f i ( x ∗ ) = 0 , i = 1 , ⋯ , m \lambda_{i}^{*} f_{i}\left(\mathrm{x}^{*}\right)=0, i=1, \cdots, m λi∗fi(x∗)=0,i=1,⋯,m
- ∇ f 0 ( x ∗ ) + ∑ i λ i ∗ ∇ f i ( x ∗ ) + ∑ i v i ∗ ∇ h i ( x ∗ ) = 0 ( ∇ x L ( x ∗ , λ ∗ , v ∗ ) = 0 ) \nabla f_{0}\left(\mathrm{x}^{*}\right)+\sum_{i} \lambda_{i}^{*} \nabla f_{i}\left(\mathrm{x}^{*}\right)+\sum_{i} v_{i}^{*} \nabla h_{i}\left(\mathrm{x}^{*}\right)=0\left(\nabla_{\mathrm{x}} L\left(\mathrm{x}^{*}, \lambda^{*}, v^{*}\right)=0\right) ∇f0(x∗)+∑iλi∗∇fi(x∗)+∑ivi∗∇hi(x∗)=0(∇xL(x∗,λ∗,v∗)=0)
-
KKT问题的几何解释(知乎解释):https://www.zhihu.com/question/58584814/answer/159863739.
2.8 主对问题思考
-
主问题:
p ∗ = min x ( max λ ≥ 0 , v L ( x , λ , v ) ) p^{*}=\min _{\mathbf{x}}\left(\max _{\lambda \geq 0, v} L(\mathbf{x}, \boldsymbol{\lambda}, \boldsymbol{v})\right) p∗=xmin(λ≥0,vmaxL(x,λ,v)) -
对偶问题
d ∗ = max λ ≥ 0 , v ( min x L ( x , λ , v ) ) d^{*}=\max _{\lambda \geq 0, \mathrm{v}}\left(\min _{\mathbf{x}} L(\mathbf{x}, \boldsymbol{\lambda}, \boldsymbol{v})\right) d∗=λ≥0,vmax(xminL(x,λ,v)) -
主对关系(强对偶成立时,max和min可以互换,即可以取等号)
max λ ≥ 0 , v ( min x L ( x , λ , v ) ) ≤ min x ( max λ ≥ 0 , v L ( x , λ , v ) ) \max _{\lambda \geq 0, \mathrm{v}}\left(\min _{\mathbf{x}} L(\mathbf{x}, \boldsymbol{\lambda}, \boldsymbol{v})\right) \leq \min _{\mathbf{x}}\left(\max _{\boldsymbol{\lambda} \geq \mathbf{0}, \boldsymbol{v}} L(\mathbf{x}, \boldsymbol{\lambda}, \boldsymbol{v})\right) λ≥0,vmax(xminL(x,λ,v))≤xmin(λ≥0,vmaxL(x,λ,v))
三:具体计算案例
3.1最小二范数问题
- 求解下列问题
p ∗ = min x ∥ x ∥ 2 2 s.t. A x = b \begin{array}{c}{p^{*}=\min _{\mathbf{x}}\|\mathbf{x}\|_{2}^{2}} \\ {\text { s.t. } \mathbf{A x}=\mathbf{b}}\end{array} p∗=minx∥x∥22 s.t. Ax=b
分析一下问题:首先目标函数是一个二范数,可以看作 x T I x \mathbf{x^TIx} xTIx,其中 I \mathbf{I} I为正定矩阵。所以是一个凸函数。另外,约束条件为等式约束,是超平面的集合,是凸集。因此问题是一个凸优化问题。
解法:
-
写出拉格朗日函数:
L ( x , v ) = x T x + v T ( A x − b ) L(\mathrm{x}, \mathrm{v})=\mathrm{x}^{T} \mathrm{x}+\mathrm{v}^{T}(\mathrm{Ax}-\mathrm{b}) L(x,v)=xTx+vT(Ax−b) -
写出对偶函数:
g ( v ) = min x L ( x , v ) g(\mathbf{v})=\min _{\mathbf{x}} L(\mathbf{x}, \mathbf{v}) g(v)=xminL(x,v)
则:
∇ x L ( x , v ) = 0 ⇒ 2 x + A T v = 0 ⇒ x ∗ ( v ) = − 1 2 A T v g ( v ) = L ( x ∗ ( v ) , v ) = − 1 4 v T ( A A T ) v − v T b \begin{array}{l}{\nabla_{\mathbf{x}} L(\mathbf{x}, \mathbf{v})=\mathbf{0} \Rightarrow 2 \mathbf{x}+\mathbf{A}^{T} \mathbf{v}=\mathbf{0} \Rightarrow \mathbf{x}^{*}(\mathbf{v})=-\frac{1}{2} \mathbf{A}^{T} \mathbf{v}} \\ {g(\mathbf{v})=L\left(\mathbf{x}^{*}(\mathbf{v}), \mathbf{v}\right)=-\frac{1}{4} \mathbf{v}^{T}\left(\mathbf{A} \mathbf{A}^{T}\right) \mathbf{v}-\mathbf{v}^{T} \mathbf{b}}\end{array} ∇xL(x,v)=0⇒2x+ATv=0⇒x∗(v)=−21ATvg(v)=L(x∗(v),v)=−41vT(AAT)v−vTb
g(v)是一个凹函数
- 对偶问题:
d ∗ = max v − 1 4 v T ( A A T ) v − v T b d^{*}=\max _{\mathbf{v}}-\frac{1}{4} \mathbf{v}^{T}\left(\mathbf{A} \mathbf{A}^{T}\right) \mathbf{v}-\mathbf{v}^{T} \mathbf{b} d∗=vmax−41vT(AAT)v−vTb
可求得:
v ∗ = − 2 ( A A T ) − 1 b d ∗ = b T ( A A T ) − 1 b \begin{aligned} \mathbf{v} * &=-2\left(\mathbf{A} \mathbf{A}^{T}\right)^{-1} \mathbf{b} \\ d^{*} &=\mathbf{b}^{T}\left(\mathbf{A} \mathbf{A}^{T}\right)^{-1} \mathbf{b} \end{aligned} v∗d∗=−2(AAT)−1b=bT(AAT)−1b
由于 p ∗ = d ∗ p^*=d^* p∗=d∗,则
x ∗ = x ∗ ( v ∗ ) = A T ( A A T ) − 1 b \mathbf{x}^{*}=\mathbf{x}^{*}\left(\mathbf{v}^{*}\right)=\mathbf{A}^{T}\left(\mathbf{A} \mathbf{A}^{T}\right)^{-1} \mathbf{b} x∗=x∗(v∗)=AT(AAT)−1b
p ∗ ≥ − 1 4 v T ( A A T ) v − v T b for all v p^{*} \geq-\frac{1}{4} \mathbf{v}^{T}\left(\mathbf{A} \mathbf{A}^{T}\right) \mathbf{v}-\mathbf{v}^{T} \mathbf{b} \quad \text { for all } \mathbf{v} p∗≥−41vT(AAT)v−vTb for all v
四:参考资料
- https://www.zhihu.com/question/58584814/answer/159863739
- 网易云课堂《人工智能数学基础》