python pandas 如何去掉/保留数据集中的重复行?
摘要:本文主要是关于如何把去掉数据集中的重复行,也就是去重的工作。
应用场景:
假如我们有如下的一个数据集,6行4列。

此时,我们3个想法。
第一个想法:把所有重复的行去掉
第二个想法:只保留第一次出现的重复行
第三个想法:保留最后一次出现的重复行
这三个想法都可以用pandas中自带一个方法实现。 DataFrame.drop_duplicates()
具体实现如下:
import pandas as pd
newdata=pd.DataFrame([[1,1,1,1],[1,1,1,1],[2,1,4,3],[5,6,7,9],[5,4,2,1],[2,1,4,9]],columns=['A','B','C','D'])newdata.drop_duplicates(subset=['A','B','C','D'],keep=False)上面这一句代码就是把所有重复的行去掉,subset这个参数后面我会提到,keep这个参数就是选择我们前面三个想法中的哪一个?
当keep=False时,就是去掉所有的重复行
当keep=‘first'时,就是保留第一次出现的重复行
当keep='last'时就是保留最后一次出现的重复行。(注意,这里的参数是字符串)

可以看到,第0行和第1行都被去掉了。
newdata.drop_duplicates(subset=['A','B','C','D'],keep='first')
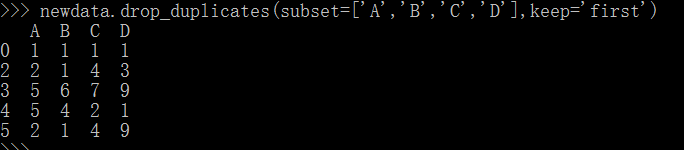
可以看到,第1行被去掉,保留了第0行。当keep='last'时这里就不演示了。
------------------------------------------------------------------------------
下面讲一下subset这个参数。
在上面的场景中,我们对重复的定义是:在某一行,若A、B、C、D这四列如果都相同的话就是重复。
但是有时候,我们重复并不需要所有列都相同,我们只需要其中的某几列相同就可以当作重复。因此subset这个参数就是来设置这个的。
举个栗子,还是上面这个数据集,如果我们想把A列和B列中元素相同的行去掉,只保留第一次出现的行,要怎么做?
很简单,
newdata.drop_duplicates(subset=['A','B'],keep='first')
从结果上我们可以看到,第0行和第1行由于A列B列相同,而且选择保留第一次出现的行,所以第1行被去掉。
第2行和第5行的A列B列相同,保留第一次出现的行,所以第5行被去掉。