python数据分析与挖掘实战 第六章 拓展思考
企业偷漏税识别模型
- 1、数据探索
- 偷漏税企业分布
首先生成data
import pandas as pd
inputfile = r'E:\Download\百度云\图书配套数据、代码\chapter6\拓展思考\tax.xls'
data = pd.read_excel(inputfile,index_col=0)通过以下代码获得各类销售模式中异常比率:
t = pd.DataFrame(data.groupby([data['销售模式'],data['输出']]).size()).unstack()[0]
t['异常比率']=t['异常']/t.sum(axis=1)
t.sort_values('异常比率',ascending=False)可以得出如下结果:
| 销售模式 | 异常 | 正常 | 异常比率 |
|---|---|---|---|
| 二级及二级以下代理商 | 13 | 3 | 0.812500 |
| 一级代理商 | 14 | 6 | 0.700000 |
| 其它 | 3 | 2 | 0.600000 |
| 多品牌经营店 | 3 | 4 | 0.428571 |
| 4S店 | 20 | 56 | 0.263158 |
做个图看看:
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.bar(range(len(t.index)),t['异常比率'],tick_label=t.index)
plt.xticks(rotation=90)
plt.show()
- 2 模型构建
再看看表,发现好像我也没有什么可以做的了,那么不如直接把整个表塞进模型里面进行训练吧。
先对表中的文字进行处理,全部变成值类型。
data['输出']=data['输出'].replace('正常',1)
data['输出']=data['输出'].replace('异常',0)
for m,n in enumerate(set(data['销售类型'])):
data['销售类型'] = data['销售类型'].replace(n, m+1)
for m,n in enumerate(set(data['销售模式'])):
data['销售模式'] = data['销售模式'].replace(n, m+1)好了,现在我们的表变成这样的了。

现在按照老办法创建一下训练集和测试集。
from random import shuffle
data=data.as_matrix()
shuffle(data)
p=0.8
train=data[:int(len(data)*p),:]
test = data[int(len(data)*p):,:]- 开始做LM神经网络模型:
from keras.models import Sequential
from keras.layers.core import Dense, Activation
net = Sequential()
net.add(Dense(input_dim=14, units=10))
net.add(Activation('relu'))
net.add(Dense(input_dim=10, units=1))
net.add(Activation('sigmoid'))
net.compile(loss="binary_crossentropy", optimizer='adam', metrics=['accuracy'])
hist = net.fit(train[:, :14], train[:, 14], epochs=1000, batch_size=1)
net.save_weights('E:\\ch06model.h5')好了,用模型来预测一下结果吧!
predict_result = net.predict_classes(train[:, :14]).reshape(len(train)) # 用训练集预测下
predict_result_test = net.predict_classes(test[:, :14]).reshape(len(test)) # 用测试集预测下然后也用混淆矩阵来看下结果吧,代码还是和书上一样的。
cm_plot(train[:, 14], predict_result).show()
cm_plot(test[:, 14], predict_result_test).show()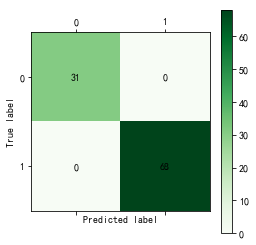
训练集的判定正确率居然是100%。
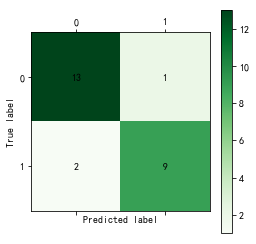
测试集的判定正确率22/25,88%,看起来好像也不错。
- 那么,再来做CART模型看看
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier() # 建立模型
tree.fit(train[:, :14], train[:, 14]) # 训练模型感觉决策树实在比神经网络用起来方便好多啊,训练速度也很快。
好了,也做两个混淆矩阵看下
cm_plot(train[:, 14], tree.predict(train[:,:14])).show()
cm_plot(test[:, 14], tree.predict(test[:,:14])).show()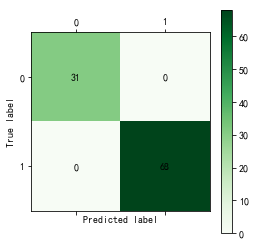
训练集依然还是100%的正确率。
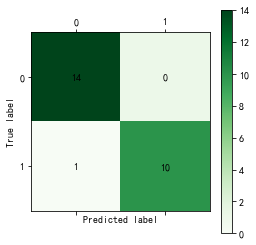
测试集更加可怕,居然24/25, 96%的正确率。
- 那么做一个ROC评价对比一下。
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
# LM模型
predict_result_test = net.predict(test[:, :14]).reshape(len(test))
fpr1, tpr1, thresholds1 = roc_curve(test[:, 14], predict_result_test, pos_label=1)
plt.plot(fpr1, tpr1, linewidth=2, label='ROC OF LM')
# CART模型
predict_result_test = tree.predict_proba(test[:, :14])[:, 1]
fpr, tpr, thresholds = roc_curve(test[:, 14], predict_result_test, pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label='ROC OF CART')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.ylim(0, 1.05)
plt.xlim(0, 1.05)
plt.legend(loc=4)
plt.show()
看看这结果,这次是CART模型好一些。
但实际上这个结果我另外跑过一次,那一次是LM模型的效果相对好一些。毕竟无论是训练集还是测试集的数量都太少了,其实不是太准确的。
如果你跑出来的结果和我的不一样,那也并不奇怪。