SpringBatch学习
什么是SpringBatch
Spring Batch 是一个轻量级的、完善的批处理框架(并不是调度框架,需要配合Quartz等框架,实现定时任务),旨在帮助企业建立健壮、高效的批处理应用。
Spring Batch 提供了大量可重用的组件,包括了日志、追踪、事务、任务作业统计、任务重启、跳过、重复、资源管理。对于大数据量和高性能的批处理任务,Spring Batch 同样提供了高级功能和特性来支持,比如分区功能、远程功能。总之,通过 Spring Batch 能够支持简单的、复杂的和大数据量的批处理作业。
运行第一个SpringBatch
package com.lion.springbatch.configuration;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.annotation.Order;
@Configuration
@Order(2)
@EnableBatchProcessing
public class FirstConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;// 创建Job任务
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job getJob() {
return jobBuilderFactory.get("firstJob").start(step()).build();
}
@Bean
public Step step() {
return stepBuilderFactory.get("firstStep").tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
System.out.println("step ~~");
return RepeatStatus.FINISHED;
}
}).build();
}
}
pom文件
这里我引入了h2嵌入式数据库,当然我们也可以用MYSQL等。
org.springframework.boot
spring-boot-starter-batch
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.springframework.batch
spring-batch-test
test
com.h2database
h2
runtime
运行截图
![]()
概念
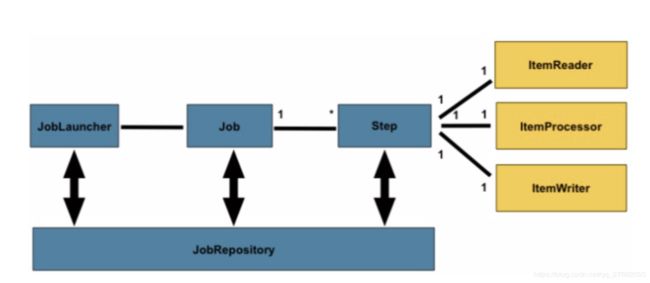
通过JobLauncher来启动SpringBatch,每一个任务是一个Job,每个任务先执行什么在执行什么工作就是step干的事情(tasklet和chunk),每一个Step对应一个ItemReader、ItemProcessor和ItemWriter。JobRepository是用来保存任务运行过程中的相关信息,任务出错了,那肯定要记录下来,不然怎么重新执行呢?对吧。
SpringBatch涉及到的数据库表
- job_instance表
从字面意思来看是job运行的一个实例。运行n次相同的job只产生1个JobInstance。
JobInstance = Job + JobParameters - job_execution表
每一次job执行,它会生成一条记录,记录job运行开始及结束时间,并且有成功或失败的记录。 - job_execution_jobParameters表
每个JobInstance可以带有参数,JobInstance 如果有带参数则只能运行一次。(需要注意),那么我们只有一个参数是一个固定的文件路径,那么可以使用JobParametersIncrementer接口,来获取每一个jobParameter。 - job_execution_context表
上下文表,可以让job之间共享一些数据。 - step_execution表
每次step触发后就会产生一个stepExecution,step不像job,是没有stepinstance的。 - step_execution_context表
让step之间共享一些数据。
相关概念
flow与step
什么是step?
每一个Step对象都封装了批处理作业的一个独立的阶段。 每一个Job本质上都是由一个或多个步骤组成。
什么flow?
Job,Flow创建及应用
flow是一个Step的集合,他规定了Step与Step之间的转换关系;
创建Flow可以达到复用的效果,让其在不同的Job之间进行复用;
使用FlowBuilder去创建一个Flow,他和Job类似,使用start(),next()以及end()来运行flow;
chunk与tasklet
什么是tasklet?
takslet意味着在step中执行单个任务,job有多个step按一定顺序组成,每个步骤应该执行一个具体任务。
什么是chunk?
基于数据块(一部分数据)执行。也就是说,其不是一次读、处理和写所有行,而是一次仅读、处理、写固定数量记录。然后重复循环执行直到读不到数据为止。
itemReader与itemWriter区别
itemReader是一个数据一个数据的读。
itemWriter是一批一批的输出。是在chunk方法中指定的数量。
多线程执行Job任务
(1)使用split方法,传入一个线程池。SplitBuilder只有一个add方法,加入flow对象。
举例说明:
(1)首先定义两个Flow,在每个Flow中定义一些Step,每一个Step将自身的名字以及当前运行的线程打印出来;
(2)创建一个Job使用Spilt异步的启动两个Flow;
(3)运行Job,查看结果(job里的两个flow,分别在不同线程中执行);
@Bean
public Job splitDemoJob() {
return jobBuilderFactory.get("splitDemoJob").start(splitDempFlow1())
.split(new SimpleAsyncTaskExecutor())
.add(splitDempFlow2()).end().build();
}
@Bean
public Step splitDemoStep1() {
return stepBuilderFactory.get("splitDemoStep1").tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
System.out.println("splitDemoStep1 ~~");
return RepeatStatus.FINISHED;
}
}).build();
}
@Bean
public Step splitDemoStep2() {
return stepBuilderFactory.get("splitDemoStep2").tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
System.out.println("splitDemoStep2 ~~");
return RepeatStatus.FINISHED;
}
}).build();
}
@Bean
public Step splitDemoStep3() {
return stepBuilderFactory.get("splitDemoStep3").tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
System.out.println("splitDemoStep3 ~~");
return RepeatStatus.FINISHED;
}
}).build();
}
@Bean
public Flow splitDempFlow1() {
return new FlowBuilder("splitDempFlow1").start(splitDemoStep1()).build();
}
@Bean
public Flow splitDempFlow2() {
return new FlowBuilder("splitDempFlow2").start(splitDemoStep2())
.next(splitDemoStep3()).build();
}
监听器
1.Listener:控制Job执行的一种方式
2.可以通过接口或者注解实现监听器
3.在spring-batch中提供各个级别的监听器接口,从job级别到item级别都有
(1)JobExecutionListener(before…,after…);
(2)StepExecutionListener(before…,after…);
(3)ChunkListener(before…,after…);
(4)ItemReaderListener;ItemWriterListener;ItemProcessListener(before…,after…,error…);
注解方式
注解方式
public class MyChunkListener {
@BeforeChunk
public void beforeChunk(ChunkContext context) {
System.out.println(context.getStepContext().getStepName()+"chunk before running.....");
}
@AfterChunk
public void afterChunk(ChunkContext context) {
System.out.println(context.getStepContext().getStepName()+"chunk after running.....");
}
}
接口方式
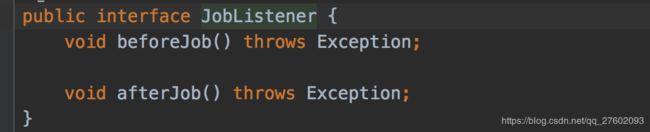
public class MyJobListener implements JobExecutionListener{
@Override
public void beforeJob(JobExecution jobExecution) {
System.out.println(jobExecution.getJobInstance().getJobName()+"before running......");
}
@Override
public void afterJob(JobExecution jobExecution) {
System.out.println(jobExecution.getJobInstance().getJobName()+"before running......");
}
}
具体使用:Job listener
ItemSteamReader
该接口可以用来处理任务异常,并重新执行。

ItemSteamReader继承了ItemStream接口和ItemReader接口。
ItemReader接口只有一个read方法,而ItemStream有open、update、close方法。
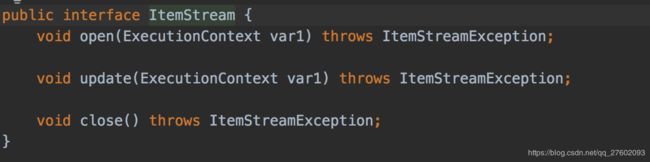
open方法是在step任务开始前执行的,我们可以再次之前从ExecutionContext中取出我们上一次执行的任务位置,继续往下执行。
update方法是在每次完成一个Chunk任务后进行调用的方法,可以记录我们完成了多少任务,目前进度在哪里。
close方法是在任务结束后调用的。
ItemReader的异常处理与重启
如果在ItemReader调用read方法过程中出现异常,那么在重启后ItemReader只能重新从第一条数据开始读取,这主要是因为我们并不知道第几行的时候出现异常,所以我们可以实现update方法和open方法。open方法可以在开始是判断ExecutionContext是否存在某个参数,如果不存在那么从头开始读,如果存在从指定位置开始读。而update方法需要每次任务处理完记录当前完成的位置,保存进ExecutionContext,如果chunk设置的太大,也不会读取过多的处理过的数据。
ItemProcessor
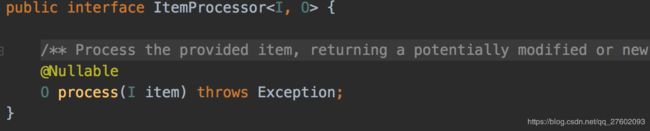
ItemProcessor可以用于处理业务逻辑、验证、过滤等功能。没啥说的。
错误处理

可以通过execute方法的ChunkContext来达到保存状态。
//返回的是一个map对象
chunkContext.getStepContext().getStepExecutionContext();
错误重试
当发生异常时我们可以进行retry重试,并设置重试的次数。这样就不会立即停止任务了。
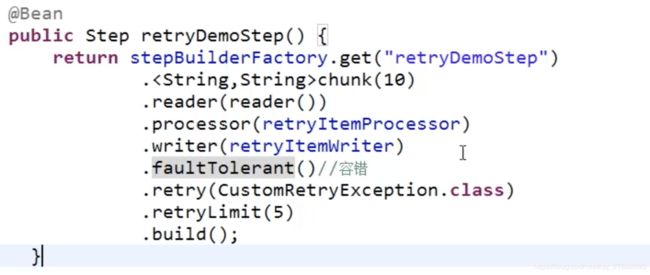
错误跳过
当出现错误我们也可以进行跳过,如果可以的话。
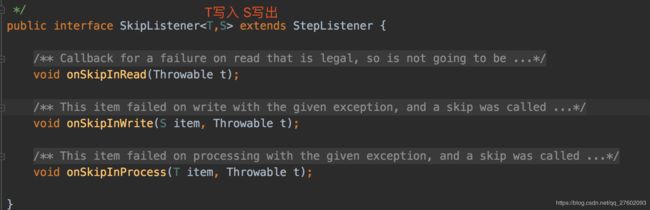
skip函数指定跳过哪个异常。
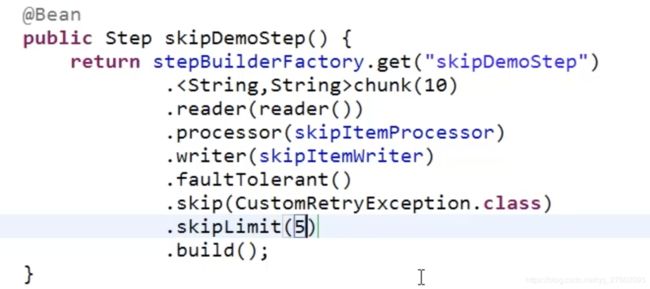
错误跳过监听器
我们可以通过listener方法加入错误跳过监听器。该监听器需要自己实现SkipListener接口。